一文介绍Doris
文章目录
- 一、架构介绍
-
- 1.名词解释
- 2.FE(Frontend)
- 3.BE(Backend)
- 4.元数据结构
- 二、存储介绍
-
- 1.DataPage
- 2.Footer信息
- 3.index pages
- 三、索引介绍
-
- 1.Ordinal Index(一级索引)
- 2.Short Key Index 索引
- 3.ZoneMap Index 索引
- 4.BloomFilter索引
- 5.Bitmap Index 索引
- 6.索引的查询流程
- 四、读写过程
-
- 1.写入
- 2.读取
- 参考资料
Apache Doris 是一个基于 MPP 架构的高性能、实时的分析型数据库,以极速易用的特点被人们所熟知,仅需亚秒级响应时间即可返回海量数据下的查询结果,不仅可以支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。基于此,Apache Doris 能够较好的满足报表分析、即席查询、统一数仓构建、数据湖联邦查询加速等使用场景,用户可以在此之上构建用户行为分析、AB 实验平台、日志检索分析、用户画像分析、订单分析等应用。
MPP (Massively Parallel Processing),即大规模并行处理。简单来说,MPP是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果(与Hadoop相似)。
一、架构介绍
Doris整体架构如下图所示,Doris 架构非常简单,只有两类进程
- Frontend(FE),即 Doris 的前端节点,主要负责用户请求的接入、查询解析规划、元数据的管理、节点管理相关工作。
- Backend(BE),即 Doris 的后端节点,主要负责数据存储、查询计划的执行。

- 以数据存储的角度来看,FE 存储、维护集群元数据;BE 存储物理数据。
- 以查询处理的角度来看, FE 节点接收、解析查询请求,规划查询计划,调度查询执行,返回查询结果;BE 节点依据 FE生成的物理计划,分布式地执行查询。
1.名词解释
- Tablet:Tablet是一张表实际的物理存储单元,一张表按照分区和分桶后在BE构成分布式存储层中以Tablet为单位进行存储,每个Tablet包括元信息及若干个连续的RowSet。
- Rowset:Rowset是Tablet中一次数据变更的数据集合,数据变更包括了数据导入、删除、更新等。Rowset按版本信息进行记录。每次变更会生成一个版本。
- Version:由Start、End两个属性构成,维护数据变更的记录信息。通常用来表示Rowset的版本范围,在一次新导入后生成一个Start,End相等的Rowset,在Compaction后生成一个带范围的Rowset版本。
- Segment:表示Rowset中的数据分段。多个Segment构成一个Rowset。
- Compaction:连续版本的Rowset合并的过程成称为Compaction,合并过程中会对数据进行压缩操作。
- bdbje:Oracle Berkeley DB Java Edition。 Doris 使用 bdbje 完成元数据操作日志的持久化、FE 高可用等功能。
2.FE(Frontend)
FE 包含三种角色
- leader跟follower,主要是用来达到元数据的高可用,保证单节点宕机的情况下,元数据能够实时地在线恢复,而不影响整个服务。
- observer只是用来扩展查询节点,就是说如果在发现集群压力非常大的情况下,需要去扩展整个查询的能力,那么可以加observer的节点。observer不参与任何的写入,只参与读取。
FE的职责(基于内存,类似HDFS NN)
- 管理元数据, 执行SQL DDL命令, 用Catalog记录库, 表, 分区, tablet副本等信息。
- FE高可用部署, 使用复制协议选主和主从同步元数据, 所有的元数据修改操作, 由FE leader节点完成,FE follower节点可执行读操作。 元数据的读写满足顺序一致性。 FE的节点数目采用2n+1, 可容忍n个节点故障。 当FE leader故障时, 从现有的follower节点重新选主, 完成故障切换。
- FE的SQL layer对用户提交的SQL进行解析, 分析, 改写, 语义分析和关系代数优化, 生产逻辑执行计划。
- FE的Planner负载把逻辑计划转化为可分布式执行的物理计划, 分发给一组BE。
- FE监督BE, 管理BE的上下线, 根据BE的存活和健康状态, 维持tablet副本的数量。
- FE协调数据导入, 保证数据导入的一致性。
3.BE(Backend)
BE的职责
- BE管理tablet副本, tablet是table经过分区分桶形成的子表, 采用列式存储。
- BE受FE指导, 创建或删除子表。
- BE接收FE分发的物理执行计划并指定BE coordinator节点, 在BE coordinator的调度下, 与其他BE worker共同协作完成执行。
- BE读本地的列存储引擎, 获取数据, 通过索引和谓词下沉快速过滤数据。
- BE后台执行compact任务, 减少查询时的读放大。
- 数据导入时, 由FE指定BE coordinator, 将数据以fanout的形式写入到tablet多副本所在的BE上。
4.元数据结构
Doris 的元数据是全内存的。每个 FE 内存中,都维护一个完整的元数据镜像

如上图,Doris 的元数据主要存储4类数据:
- 用户数据信息。包括数据库、表的 Schema、分片信息等。
- 各类作业信息。如导入作业,Clone 作业、SchemaChange 作业等。
- 用户及权限信息。
- 集群及节点信息。
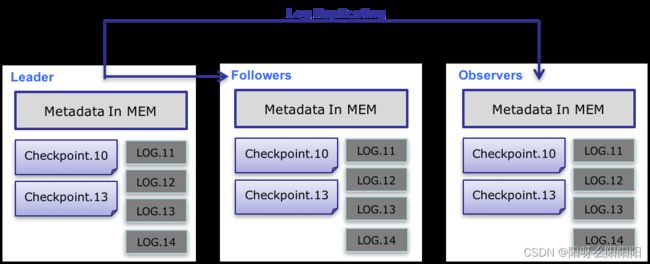
元数据的数据流具体过程如下:
- 只有 leader FE 可以对元数据进行写操作。写操作在修改 leader 的内存后,会序列化为一条log,按照 key-value 的形式写入 bdbje。其中 key 为连续的整型,作为 log id,value 即为序列化后的操作日志。
- 日志写入 bdbje 后,bdbje 会根据策略(写多数/全写),将日志复制到其他 non-leader 的 FE 节点。non-leader FE 节点通过对日志回放,修改自身的元数据内存镜像,完成与 leader 节点的元数据同步。
- leader 节点的日志条数达到阈值(默认 10w 条)并且满足checkpoint线程执行周期(默认六十秒)。checkpoint 会读取已有的 image 文件,和其之后的日志,重新在内存中回放出一份新的元数据镜像副本。然后将该副本写入到磁盘,形成一个新的 image。之所以是重新生成一份镜像副本,而不是将已有镜像写成 image,主要是考虑写 image 加读锁期间,会阻塞写操作。所以每次 checkpoint 会占用双倍内存空间。
- image 文件生成后,leader 节点会通知其他 non-leader 节点新的 image 已生成。non-leader 主动通过 http 拉取最新的 image 文件,来更换本地的旧文件。
- bdbje 中的日志,在 image 做完后,会定期删除旧的日志。
二、存储介绍
Segment整体的文件格式分为数据区域,索引区域和footer三个部分,如下图所示:
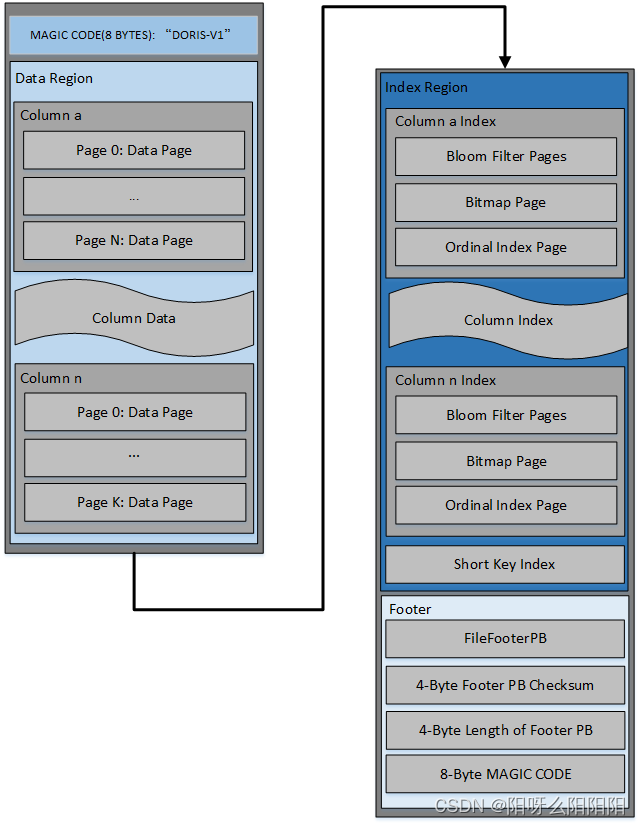
文件包括:
- 文件开始是8个字节的magic code,用于识别文件格式和版本
- Data Region:用于存储各个列的数据信息,这里的数据是按需分page加载的
- Index Region: doris中将各个列的index数据统一存储在Index Region,这里的数据会按照列粒度进行加载,所以跟列的数据信息分开存储
- Footer信息
- FileFooterPB:定义文件的元数据信息
- 4个字节的footer pb内容的checksum
- 4个字节的FileFooterPB消息长度,用于读取FileFooterPB
- 8个字节的MAGIC CODE,之所以在末位存储,是方便不同的场景进行文件类型的识别
1.DataPage
DataPage分为两种:nullable和non-nullable的data page。
nullable的data page内容包括:
+----------------+
| value count |
|----------------|
| first row id |
|----------------|
| bitmap length |
|----------------|
| null bitmap |
|----------------|
| data |
|----------------|
| checksum |
+----------------+
non-nullable data page结构如下:
|----------------|
| value count |
|----------------|
| first row id |
|----------------|
| data |
|----------------|
| checksum |
+----------------+
其中各个字段含义如下:
- value count:表示page中的行数
- first row id:page中第一行的行号
- bitmap length:表示接下来bitmap的字节数
- null bitmap:表示null信息的bitmap
- data
- 存储经过encoding和compress之后的数据
- 需要在数据的头部信息中写入:is_compressed
- 各种不同编码的data需要在头部信息写入一些字段信息,以实现数据的解析
- TODO:添加各种encoding的header信息
- checksum:存储page粒度的校验和,包括page的header和之后的实际数据
2.Footer信息

SegmentFooterPB采用了PB格式进行存储,主要包含了列的meta信息、索引的meta信息,Segment的short key索引信息、总行数。
message ColumnPB {
required int32 unique_id = 1; // 这里使用column id, 不使用column name是因为计划支持修改列名
optional string name = 2; // 列的名字, 当name为__DORIS_DELETE_SIGN__, 表示该列为隐藏的删除列
required string type = 3; // 列类型
optional bool is_key = 4; // 是否是主键列
optional string aggregation = 5; // 聚合方式
optional bool is_nullable = 6; // 是否有null
optional bytes default_value = 7; // 默认值
optional int32 precision = 8; // 精度
optional int32 frac = 9;
optional int32 length = 10; // 长度
optional int32 index_length = 11; // 索引长度
optional bool is_bf_column = 12; // 是否有bf词典
optional bool has_bitmap_index = 15 [default=false]; // 是否有bitmap索引
}
// page偏移
message PagePointerPB {
required uint64 offset; // page在文件中的偏移
required uint32 length; // page的大小
}
message MetadataPairPB {
optional string key = 1;
optional bytes value = 2;
}
message ColumnMetaPB {
optional ColumnMessage encoding; // 编码方式
optional PagePointerPB dict_page // 词典page
repeated PagePointerPB bloom_filter_pages; // bloom filter词典信息
optional PagePointerPB ordinal_index_page; // 行号索引数据
optional PagePointerPB page_zone_map_page; // page级别统计信息索引数据
optional PagePointerPB bitmap_index_page; // bitmap索引数据
optional uint64 data_footprint; // 列中索引的大小
optional uint64 index_footprint; // 列中数据的大小
optional uint64 raw_data_footprint; // 原始列数据大小
optional CompressKind compress_kind; // 列的压缩方式
optional ZoneMapPB column_zone_map; //文件级别的过滤条件
repeated MetadataPairPB column_meta_datas;
}
message SegmentFooterPB {
optional uint32 version = 2 [default = 1]; // 用于版本兼容和升级使用
repeated ColumnPB schema = 5; // 列Schema
optional uint64 num_values = 4; // 文件中保存的行数
optional uint64 index_footprint = 7; // 索引大小
optional uint64 data_footprint = 8; // 数据大小
optional uint64 raw_data_footprint = 8; // 原始数据大小
optional CompressKind compress_kind = 9 [default = COMPRESS_LZO]; // 压缩方式
repeated ColumnMetaPB column_metas = 10; // 列元数据
optional PagePointerPB key_index_page; // short key索引page
}
3.index pages
- Ordinal Index Page
- 针对每个列,都会按照page粒度,建立行号的稀疏索引。内容为这个page的起始行的行号到这个block的指针(包括offset和length)
- Short Key Index page
- 我们会每隔N行(可配置)生成一个short key的稀疏索引,索引的内容为:short key->行号(ordinal)
- Bloom Filter Pages
- 针对每个bloom filter列,会在page的粒度相应的生成一个bloom filter的page,保存在bloom filter pages区域
三、索引介绍
1.Ordinal Index(一级索引)
Ordinal Index 索引提供了通过行号来查找 Column Data Page 数据页的物理地址。Ordinal Index 能够将按列存储数据按行对齐,可以理解为一级索引。其他索引查找数据时,都要通过 Ordinal Index 查找数据 Page 的位置。因此,这里先介绍 Ordinal Index 索引。
在一个 segment 中,数据始终按照 key(AGGREGATE KEY、UNIQ KEY 和 DUPLICATE KEY)排序顺序进行存储,即 key 的排序决定了数据存储的物理结构。确定了列数据的物理结构顺序,在写入数据时,Column Data Page 是由 Ordinal index 进行管理,Ordinal index 记录了每个 Column Data Page 的位置 offset、大小 size 和第一个数据项行号信息,即 Ordinal。这样每个列具有按行信息进行快速扫描的能力。Ordinal index 采用的稀疏索引结构,就像是一本书目录,记录了每个章节对应的页码。
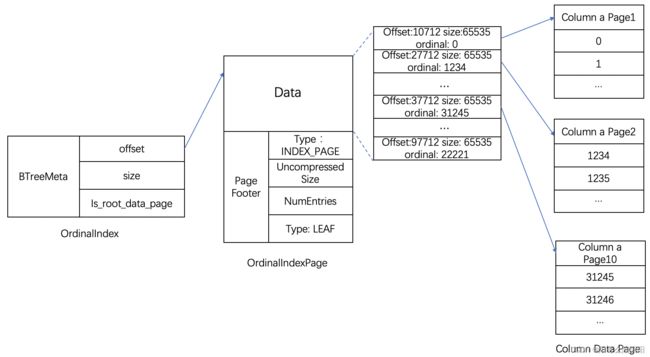
- 数据刷写时,会为每一个Data Page生成一条Ordinal索引项
2.Short Key Index 索引
Short Key Index 前缀索引,是在 key(AGGREGATE KEY、UNIQ KEY 和 DUPLICATE KEY)排序的基础上,实现的一种根据给定前缀列,快速查询数据的索引方式。这里 Short Key Index 索引也采用了稀疏索引结构,在数据写入过程中,每隔一定行数,会生成一个索引项。这个行数为索引粒度默认为 1024 行,可配置。该过程如下图所示:
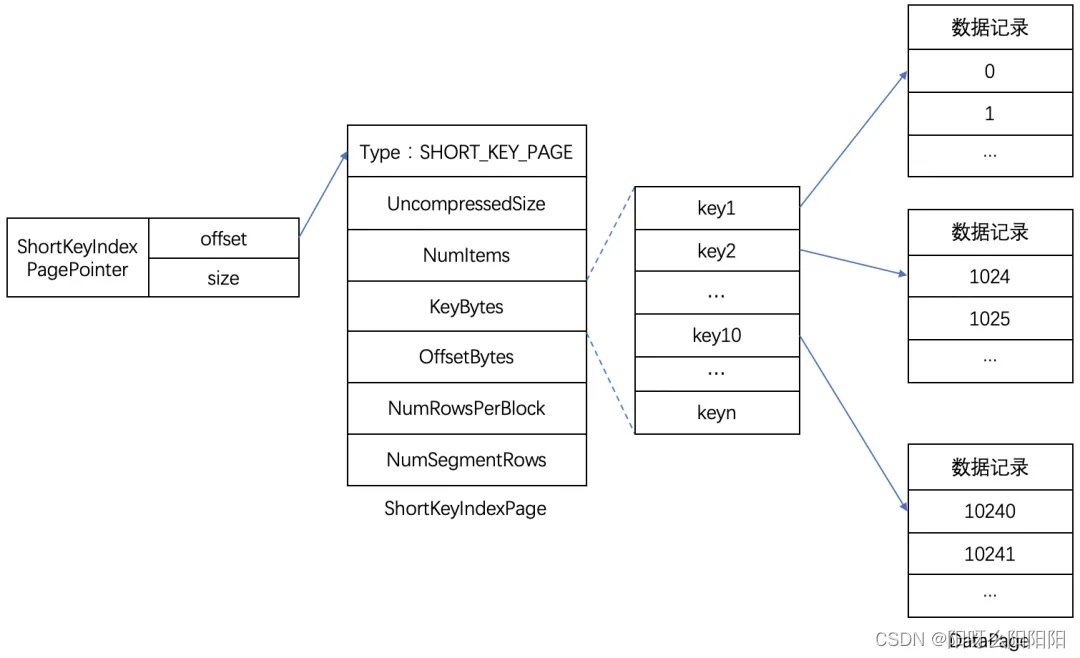
- 索引生成规则:Short Key Index 采用了前 36 个字节,作为这行数据的前缀索引。当遇到 VARCHAR 类型时,前缀索引会直接截断。
3.ZoneMap Index 索引
在 SegmentFootPB 结构中,每一列索引元数据 ColumnIndexMeta 中存放了当前列的 ZoneMapIndex 索引数据信息。ZoneMapIndex 有两个部分,SegmentZoneMap 和 PageZoneMaps。SegmentZoneMap 存放了当前 Segment 全局的 ZoneMap 索引信息,PageZoneMaps 存放了每个 Data Page 的 ZoneMap 索引信息。
PageZoneMaps 对应了索引数据存放的 Page 信息 IndexedColumnMeta 结构,目前实现上没有进行压缩,编码方式也为 Plain。IndexedColumnMeta 中的 OrdinalIndexPage 指向索引数据 root page 的偏移和大小,这里同样做了优化二级 Page 优化,当仅有一个 DataPage 时,OrdinalIndexMeta 直接指向这个 DataPage;有多个 DataPage 时,OrdinalIndexMeta 先指向 OrdinalIndexPage,OrdinalIndexPage 是一个二级 Page 结构,里面的数据项为索引数据 DataPage 的地址偏移 offset,大小 Size 和 ordinal 信息。

- 索引生成规则:Doris 默认为 key 列开启 ZoneMap 索引;当表的模型为 DUPULCATE 时,会所有字段开启 ZoneMap 索引。在列数据写入 Page 时,自动对数据进行比较,不断维护当前 Segment 的 ZoneMap 和当前 Page 的 ZoneMap 索引信息。
- 索引更新:
- 数据刷写时,会给每一个Data Page创建一条Zone Map索引项。向Data Page中每添加一条数据,都会更新Data Page的Zone Map索引项。
- 如果添加的数据是null,则将Zone Map索引项的has null标志设置为true,否则,将Zone Map索引项的has not null标志设置为true。
- 如果添加的数据小于Zone Map索引项的min value,则使用当前数据更新min value;如果添加的数据大于Zone Map索引项的max value,则使用当前数据更新max value。
4.BloomFilter索引
BloomFilterIndex 信息存放了生产的 Hash 策略、Hash 算法和 BloomFilter 过对应的数据 Page 信息。Hash 算法采用了 HASH_MURMUR3,Hash 策略采用了 BlockSplitBloomFilter 分块实现策略,期望的误判率 fpp 默认配置为 0.05。

- 索引生成规则:BloomFilter 按 Page 粒度生成,在数据写入一个完整的 Page 时,Doris 会根据 Hash 策略同时生成这个 Page 的 BloomFilter 索引数据。目前 bloom 过滤器不支持 tinyint/hll/float/double 类型,其他类型均已支持。使用时需要在 PROPERTIES 中指定 bloom_filter_columns 要使用 BloomFilter 索引的字段。
- 索引更新:数据刷写时,会给每一个Data Page创建一条Bloom Filter索引项。Apache Doris采用了基于Block的Bloom Filter算法。每一个Data Page对应的Bloom Filter索引数据会被划分为多个Block,每个Block的数据长度为BYTES_PER_BLOCK(默认为32字节,共256bit),Block中的每一个Bit位会被初始化为0。向Data Page中写入数据时,每一个不同的取值value都会将一个Block中的BITS_SET_PER_BLOCK(默认值为8)个Bit置位为1
5.Bitmap Index 索引
为了加速数据查询,Apache Doris支持用户为某些字段添加Bitmap索引。Bitmap索引由两部分组成:
- 有序字典:有序保存一列中所有的不同取值。
- 字典值的Roaring位图:保存有序字典中每一个取值的Roaring位图,表示字典值在列中的行号。
例如:如图6所示,一列数据为[x, x, y, y, y, z, y, x, z,
x],一共包含10行,则该列数据的Bitmap索引的有序字典为{x, y, z}, x、y、z对应的位图分别为:x的位图: [0, 1, 7, 9] ( [1,1,0,0,0,0,0,1,0,1,0,0…] )
y的位图: [2, 3, 4, 6]
z的位图: [5, 8]
- 索引生成规则:BitMap 创建时需要通过 CREATE INDEX 进行创建。Bitmap 的索引是整个 Segment 中的 Column 字段的索引,而不是为每个 Page 单独生成一份。在写入数据时,会维护一个 map 结构记录下每个字典值对应的行号,并采用 Roaring 位图对 rowid 进行编码。主要结构如下:

- 索引更新:数据刷写时,会给用户指定的列创建Bitmap索引。向列中每添加一个值,都会更新当前列的Bitmap索引。从Bitmap索引的有序字典中查找添加的值是否已经存在,如果本次添加的值在Bitmap索引的有序字典中已经存在,则直接更新该字典值对应的Roaring位图,如果本次添加的值在Bitmap索引的有序字典中不存在,则将该值添加到有序字典,并为该字典值创建Roaring位图。当然,NULL值也会有单独的Roaring位图。
6.索引的查询流程
在查询一个 Segment 中的数据时,根据执行的查询条件,会对首先根据字段加索引的情况对数据进行过滤。然后在进行读取数据,整体的查询流程如下:
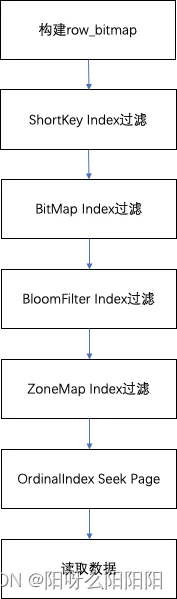
- 首先,会按照 Segment 的行数构建一个 row_bitmap,表示记录那些数据需要进行读取,没有使用任何索引的情况下,需要读取所有数据。
- 当查询条件中按前缀索引规则使用到了 key 时,会先进行 ShortKey Index 的过滤,可以在 ShortKey Index 中匹配到的 ordinal 行号范围,合入到 row_bitmap 中。
- 当查询条件中列字段存在 BitMap Index 索引时,会按照 BitMap 索引直接查出符合条件的 ordinal 行号,与 row_bitmap 求交过滤。这里的过滤是精确的,之后去掉该查询条件,这个字段就不会再进行后面索引的过滤。
- 当查询条件中列字段存在 BloomFilter 索引并且条件为等值(eq,in,is)时,会按 BloomFilter 索引过滤,这里会走完所有索引,过滤每一个 Page 的 BloomFilter,找出查询条件能命中的所有 Page。将索引信息中的 ordinal 行号范围与 row_bitmap 求交过滤。
- 当查询条件中列字段存在 ZoneMap 索引时,会按 ZoneMap 索引过滤,这里同样会走完所有索引,找出查询条件能与 ZoneMap 有交集的所有 Page。将索引信息中的 ordinal 行号范围与 row_bitmap 求交过滤。
- 生成好 row_bitmap 之后,批量通过每个 Column 的 OrdinalIndex 找到到具体的 Data Page。
- 批量读取每一列的 Column Data Page 的数据。在读取时,对于有 null 值的 page,根据 null 值位图判断当前行是否是 null,如果为 null 进行直接填充即可。
四、读写过程
1.写入
大体的写入流程如下:
- 写入magic
- 根据schema信息,生成对应的ColumnWriter,每个ColumnWriter按照不同的类型,获取对应的encoding信息(可配置),根据encoding,生成对应的encoder
- 调用encoder->add(value)进行数据写入,每隔K行,生成一个short key index entry,并且,如果当前的page满足一定条件(大小超过1M或者行数为K),就生成一个新的page,缓存在内存中。
- 不断的循环步骤3,直到数据写入完成。将各个列的数据依序刷入文件中
- 生成FileFooterPB信息,写入文件中。

相关的问题:
- short key的索引如何生成?
- 现在还是按照每隔多少行生成一个short key的稀疏索引,保持每隔1024行生成一个short的稀疏索引,具体的内容是:short key -> ordinal
- ordinal索引里面应该存什么?
- 存储page的第一个ordinal到page pointer的映射信息
2.读取
- 读取文件的magic,判断文件类型和版本
- 读取FileFooterPB,进行checksum校验
- 按照需要的列,读取short key索引和对应列的数据ordinal索引信息
- 使用start key和end key,通过short key索引定位到要读取的行号,然后通过ordinal索引确定需要读取的row ranges, 同时需要通过统计信息、bitmap索引等过滤需要读取的row ranges
- 然后按照row ranges通过ordinal索引读取行的数据
参考资料
1.https://doris.apache.org/zh-CN/community/design/metadata-design
2.https://blog.csdn.net/qq_43141726/article/details/120607561
3.https://xie.infoq.cn/article/4f7d09d6185fb3055d4e7e51c
4.https://www.modb.pro/db/427508