【轩说Pytorch】用GPU训练模型
文章目录
- 原理图
- 把模型和数据放在cuda上
- 多GPU做数据并行
-
- 注意事项
- 多卡并行运算时涉及到的模型保存问题
-
- 朴素:单卡保存,单卡加载
- 加载时:加载单卡数据,转多卡模型
- 保存时:多卡训练模型,转单卡保存
- 多卡保存,多卡加载
- PyTorch查看模型和数据是否在GPU上
本文借鉴了一些其他博客,已标注。仅作学习使用。
原理图
这里参考了(32条消息) pytorch分布式训练(一):torch.nn.DataParallel_Tai Fook的博客-CSDN博客
将模型和数据推入output_device(也就是0号)gpu上。
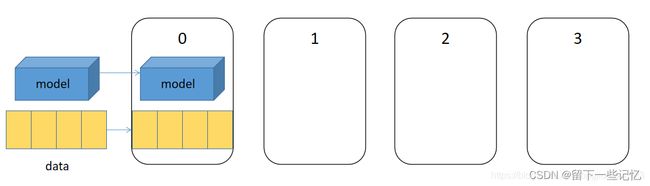
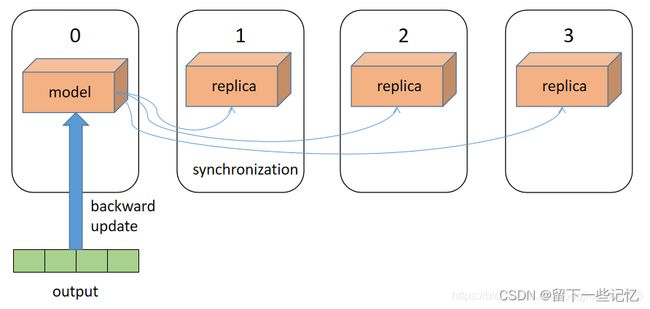
0号gpu将当前模型在其他几个gpu上进行复制,同步模型的parameter、buffer和modules等;将当前batch尽可能平均的分为len(device)=4份,分别推给每一个设备,并开启多线程分别在每个设备上进行前向传播,得到各自的结果,最后将各自的结果全部汇总在一起,拷贝回0号gpu。

在0号gpu进行反向传播和模型的参数更新,并将结果同步给其他几个gpu,即完成了一个batch的训练。
把模型和数据放在cuda上
# solution: 0
device = 'gpu'
model = model.to(device)
data = data.to(device)
# solution: 1,在后面加入.cuda()
model = model.cuda()
data = data.cuda()
# solution: 2
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)
data = data.to(device)
多GPU做数据并行
这部分参考了Pytorch的nn.DataParallel - 知乎 (zhihu.com)

net=torch.nn.DataParallel(model)
这时,默认所有存在的显卡都会被使用。
如果我们机子中有很多显卡(例如我们有八张显卡),但我们只想使用0、1、2号显卡,那么我们可以:
net=torch.nn.DataParallel(model,device_ids=[0,1,2])
Parameters 参数:
-
module即表示你定义的模型;
-
device_ids表示你训练的device;
-
output_device这个参数表示输出结果的device;
而这最后一个参数output_device一般情况下是省略不写的,那么默认就是在device_ids[0],也就是第一块卡上,也就解释了为什么第一块卡的显存会占用的比其他卡要更多一些。
注意事项
The parallelized module must have its parameters and buffers on device_ids[0] before running this DataParallel module.
场景假设:服务器是八卡的服务器,刚好前面序号是0的卡被别人占用着,于是你只能用其他的卡来,比如你用2和3号卡,如果你直接指定device_ids=[2, 3]的话会出现模型初始化错误
所以注意假如写了如下代码:
net=torch.nn.DataParallel(model,device_ids=[2,3])
那么由于之前写了:
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)
data = data.to(device)
这里显然,我们的模型和数据都是在cuda:0上的,但是数据并行是在2卡和3卡上的,且要求里必须在并行计算前,模型和数据是放在device_ids[0]=“cuda:2"上的。于是会报错。不建议在这里修改device=torch.device(“cuda:0” if torch.cuda.is_available() else “cpu”) 这行语句来改为"cuda:2”,因为torch.cuda.is_available()只能返回True和FALSE,如果想看有几个gpu,还需要torch.cuda.device_count()。并且很有可能后续代码也要跟着改。
这里建议通过设定可见的物理设备号来限制卡号,后面的代码就不需要改了,只要在开头限制一下就行,方便维护代码。正确代码如下所示:
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"# 按照PCI_BUS_ID顺序从0开始排列GPU设备
os.environ["CUDA_VISIBLE_DEVICES"] = "2, 3"#指定物理GPU号为2,3号为可见设备,且被分配为逻辑号0,1
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)
data = data.to(device)
net=torch.nn.DataParallel(model,device_ids=[0,1])
当你添加前两行代码后,那么device_ids[0]默认的就是第2号卡,你的模型也会初始化在第2号卡上了,而不会占用第0号卡了。这里简单说一下设置上面两行代码后,那么对这个程序而言可见的只有2和3号卡,和其他的卡没有关系,这是物理上的号卡,逻辑上来说其实是对应0和1号卡 ,即device_ids[0]等于0,也就是逻辑上的第0张GPU,物理上对应的就是第2号卡,device_ids[1]等于1,逻辑上对应的是第1张卡,物理上对应的就是第3号卡。
多卡并行运算时涉及到的模型保存问题
这部分参考了(32条消息) pytorch 使用DataParallel 单机多卡和单卡保存和加载模型时遇到的问题_多卡训练的模型不能直接加载_我是一颗棒棒糖的博客-CSDN博客
那么使用nn.DataParallel后,事实上DataParallel也是一个Pytorch的nn.Module。此时的net是一个多卡并行的net,可以通过net.module来获取单卡版本的net 那么你的模型和优化器都需要使用.module来得到实际的模型和优化器,如下:
朴素:单卡保存,单卡加载
保存:
states = {
'state_dict_encoder': encoder.state_dict(),
'state_dict_decoder': decoder.state_dict(),
}
torch.save(states, fname)
加载:
#先初始化模型,因为保存时只保存了模型参数,没有保存模型整个结构
encoder = Encoder()
decoder = Decoder()
#然后加载参数
checkpoint = torch.load(model_path) #model_path是你保存的模型文件的位置
encoder_state_dict=checkpoint['state_dict_encoder']
decoder_state_dict=checkpoint['state_dict_decoder']
encoder.load_state_dict(encoder_state_dict)
decoder.load_state_dict(decoder_state_dict)
加载时:加载单卡数据,转多卡模型
在加载后面加入并行处理
#先初始化模型,因为保存时只保存了模型参数,没有保存模型整个结构
encoder = Encoder()
decoder = Decoder()
#然后加载参数
checkpoint = torch.load(model_path) #model_path是你保存的模型文件的位置
encoder_state_dict=checkpoint['state_dict_encoder']
decoder_state_dict=checkpoint['state_dict_decoder']
encoder.load_state_dict(encoder_state_dict)
decoder.load_state_dict(decoder_state_dict)
#并行处理模型
encoder = nn.DataParallel(encoder)
decoder = nn.DataParallel(decoder)
保存时:多卡训练模型,转单卡保存
在保存 时改为
states = {
'state_dict_encoder': encoder.module.state_dict(),
'state_dict_decoder': decoder.module.state_dict(),
}
torch.save(states, fname)
多卡保存,多卡加载
保存:
states = {
'state_dict_encoder': encoder.state_dict(),
'state_dict_decoder': decoder.state_dict(),
}
torch.save(states, fname)
加载:
#先初始化模型,因为保存时只保存了模型参数,没有保存模型整个结构
encoder = Encoder()
decoder = Decoder()
#并行处理模型
encoder = nn.DataParallel(encoder)
decoder = nn.DataParallel(decoder)
#然后加载参数
checkpoint = torch.load(model_path) #model_path是你保存的模型文件的位置
encoder_state_dict=checkpoint['state_dict_encoder']
decoder_state_dict=checkpoint['state_dict_decoder']
encoder.load_state_dict(encoder_state_dict)
decoder.load_state_dict(decoder_state_dict)
PyTorch查看模型和数据是否在GPU上
import torch
import torch.nn as nn
# ----------- 判断模型是在CPU还是GPU上 ----------------------
model = nn.LSTM(input_size=10, hidden_size=4, num_layers=1, batch_first=True)
print(next(model.parameters()).device) # 输出:cpu
model = model.cuda()
print(next(model.parameters()).device) # 输出:cuda:0
model = model.cpu()
print(next(model.parameters()).device) # 输出:cpuu
# ----------- 判断数据是在CPU还是GPU上 ----------------------
data = torch.ones([2, 3])
print(data.device) # 输出:cpu
data = data.cuda()
print(data.device) # 输出:cuda:0
data = data.cpu()
print(data.device) # 输出:cpu