2019-Photo_Cropping_via_Deep_Reinforcement_Learning论文笔记
2019-Photo_Cropping_via_Deep_Reinforcement_Learning论文笔记
- 摘要
- 1 简介
-
- 现有裁剪方法的介绍和不足
- 本文提出的裁剪方法(DLRL)
- 2 相关工作
-
- 主流的两类自动图像裁剪方法
- 滑动窗口裁剪方法的优化
- DLRL模型的特点和优势
- 3 我们的方法
-
- DLRL方法的整体网络结构和原理介绍
- Action Space
- 深度学习部分
- 奖励和代理
- 基于强化学习的裁剪
- 4 实验
-
- 评估指标
-
- IoU
- α-recall
- Disp
- 实验结果及分析
- 与其他方法进行比较
-
- 裁剪精度评价
- 对时间效率的评估
- 5 结论
摘要
图像自动裁剪旨在改变图像的构图,以提高图像的美学质量。它可以为图像编辑工作者提供专业的建议,并节省时间。现有的自动图像裁剪方法大多是基于美学特征或突出特征等特定特征。这些方法采用滑动窗口机制生成大量的候选裁剪结果,然后根据这些特定特征选择最终结果。它非常耗时,只能产生有限的高宽比的裁剪结果。面对这些情况,提出了一种DLRL(深度学习框架结合强化学习)框架,该框架只使用图像的基本特征进行裁剪,而不产生大量的候选窗口。此外,逐步裁剪更符合人们使用photoshop或其他软件的图像裁剪过程。实验表明,该方法可以节省大量的时间,提高裁剪效率。该方法在开放的Flickr裁剪数据集和CUHK图像裁剪数据集上取得了最先进的性能。
1 简介
图像裁剪是图像编辑中最常见和最重要的任务,旨在从构图不良的图像中提取构图良好的区域,以提高图像的审美质量。一种优秀的自动图像裁剪算法可以为图像编辑工作者提供专业的建议,节省大量的时间。
现有裁剪方法的介绍和不足
目前图像自动裁剪领域已经提出了许多新的裁剪方法。大多数都是基于特定特征采取滑动窗口机制来生成大量候选裁剪窗口。

如Fig.1.所示。这些方法一般可分为以下三个步骤:
- 使用滑动窗口法在输入图像上提取大量的候选结果
- 提取每个候选结果的特定特征,如美学特征或显著特征
- 根据提取特征的评价,从这些候选结果中选择最好的结果作为最终输出
这类滑动窗口裁剪法在性能上表现其实还不错,但是由于该机制的限制,无法产生任意长宽比的裁剪结果。另外,由于每次都生成大量的候选裁剪窗口,在时间复杂度和空间复杂度上的表现都是糟糕的。而且这类方法对硬件的要求很高,也不符合人们通常的裁剪过程。
本文提出的裁剪方法(DLRL)
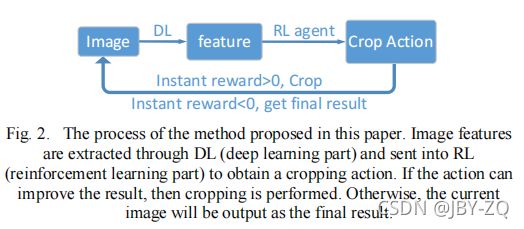
基于上述研究,并受人们裁剪过程的启发,我们提出了一个DLRL(深度学习框架结合强化学习)框架。如Fig.2.所示,该方法首先提取了与人们浏览图像的过程相对应的图像的总体基本特征。然后在整个图像的基础上逐步调整裁剪区域,直到结果无法改进为止。通过上述过程,该方法将不会产生大量的候选结果,并且可以通过使用较少的训练数据来获得令人满意的性能。特别是本文提出的方法平均可以在5步内完成裁剪,效率非常高。
2 相关工作
主流的两类自动图像裁剪方法
自动图像裁剪方法主要有两种类型:
- 基于注意力的方法
- 基于注意的方法的目标是在原始图像中找到视觉上最突出的区域。这些方法通常根据注意得分或对象的显著性来选择裁剪窗口。这些方法通常适用于去除图像中不重要的内容,有时由于缺乏对图像的美学考虑,而无法产生视觉上令人愉悦的结果。
- 基于美学的方法
- 美学图像裁剪方法旨在从原始图像中找到最令人满意的裁剪窗口。由于这些方法以美学质量作为标准,因此它们使用的是几乎与美学质量评估相同的特征。
滑动窗口裁剪方法的优化
W.Wang等人在依赖滑动窗口机制裁剪的方法上做了优化,首先选择一个初始裁剪窗口,并在初始裁剪窗口周围随机生成候选裁剪窗口,从而缩小了滑动窗口的范围。但它们并没有打破上述滑动窗口方法的局限性。滑动窗口方法的使用限制了任意大小的裁剪结果。而且,裁剪窗口的数量仍然处在相当多的水准,而事实上人们不会在图像上随机裁剪大量的候选结果,然后从所有这些候选结果中选择一个令人满意的结果。这并不符合人们的裁剪过程和逻辑。
DLRL模型的特点和优势
本文提出了一种自动图像裁剪的DLRL模型。由于强化学习的特点,该方法逐步进行裁剪,符合人们裁剪的过程,而且DLRL不需要产生大量的候选结果。理论上,可以产生任意长宽比的裁剪结果。该方法仅利用了图像的基本特征,取得了令人满意的裁剪性能。
3 我们的方法
DLRL方法的整体网络结构和原理介绍

DLRL方法逐步提高了裁剪结果,符合人们裁剪图像的决策过程,整体网络结构如Fig.3.所示。正如Fig.3.所示,
- 输入图像I(t)是经过t步裁剪后的图像结果,其中t表示裁剪步数。DL部分(深度学习部分)是用来提取I(t)的特征的,然后特征作为s(t)发送到代理(agent)。
- 根据挑选决策(selection policy)和Q table,agent会选出一个裁剪动作A,如果裁剪动作A的reward大于0,裁剪动作A将会被执行,这样就得到了I(t+1),然后重复上述过程。
- 否则,结束图像裁剪。
在逐步裁剪的过程中,代理会与环境(图像)进行交互。根据当前环境的状态(特性),代理从裁剪动作空间中选择适当的操作。在训练期间,执行行动的奖励将被记录下来,以便下次代理可以选择更好的行动。重复此过程,并将得到最佳的结果。
Action Space
裁剪动作空间中有13个动作,可分为三类:
- 缩放动作
- 位置转换动作
- 长宽比转换动作

裁剪窗口的大小、位置和形状可以分别按这三类进行调整,相应的裁剪动作数量分别为5、4和4。如Fig.4.所示。
深度学习部分
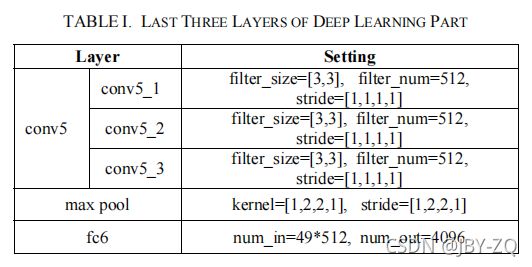
本文提出的方法是基于裁剪图像的基本特征,因此特征的提取对裁剪结果具有重要意义。DL部分的原型是VGGNet。我们都知道,VGGNet本身用于分类,不适合裁剪任务。而VGGNet的训练数据则极其复杂。因此,我们在Flickr裁剪数据集(FCD)上对VGGNet的fc6层进行了微调,并保留了conv1-conv5层的原始设置。网络结构如下表1所示。
奖励和代理
DLRL中使用的代理包括四个全连接层,这些层的输出大小为4096、4096、512、13。在接收到DL提取的特征后,代理评估每个操作,然后根据策略Ω选择一个裁剪操作。采用贪婪算法确定了策略Ω。ϵ-贪婪算法以ϵ的概率随机选择裁剪动作,选择裁剪动作得分最高的动作,概率为1−ϵ。动作得分Q(S(t),A)是通过选择动作A获得的预期累积奖励。它使用γ-discount累积奖励进行计算,公式为:

其中r(t)为裁剪t步后当前裁剪窗口与GT窗口的重叠度,常用的裁剪评价度量IoU表示。具体计算公式见式(3)。R(S(t),A)是通过选择动作A获得的即时奖励,它测量了步骤t的改进。
![]()
在训练过程中,代理总是选择动作得分最高的动作,这意味着selection policy中的ϵ=0。重复裁剪过程,直到R(S(t),A)≤0。换句话说,当裁剪结果无法改进时,裁剪就结束了。
基于强化学习的裁剪
DL网络将输入图像I(t)的基本特征提取为当前状态s(t),并将其发送给代理。代理根据Q表从操作空间中选择一个裁剪操作A。如果使用即时奖励R(S(t),A)>0,则将执行该操作。然后将裁剪后的图像作为I(t+1)输入到DL网络。重复此过程。如果R(S(t),A)≤0,则不执行裁剪操作,并且裁剪结束。最终的裁剪结果是当时DL网络的输入,即I(t-1)。
我们使用附录中[12]的双q学习方法在Flickr裁剪数据集上训练DLRL。训练图像总数1299张,批大小4张。学习率的初始值设置为10-5,最小值设置为10-8。学习率每5000次迭代下降一次,下降了0.96次。即时奖励的最大值设置为0.5,最小值设置为-0.5。累积奖励用γ=0.95计算。
4 实验
我们在Flickr裁剪数据集(FCD)和CUHK图像裁剪数据集(CUHK-ICD)上测试了DLRL。FCD包含332张测试图像,每个图像都有一个裁剪注释。CUHK-ICD包含950张测试图像,每个图像都有三个裁剪注释。并且,在训练中没有出现任何测试数据。
评估指标
采用了三个常见的自动图像裁剪评价指标,包括:
- 平均交叉过联合(IoU)
- α-recall
- 平均边界位移(Disp)
IoU
IoU测量裁剪结果与GT裁剪窗口之间的重叠程度。平均IoU的计算方法如下:
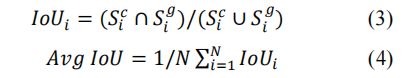
其中,S(c,i)为图像i裁剪后的区域,S(g,i)为图像i的地面真实裁剪窗口的区域。N是图像的总数。
α-recall
α-recall衡量良好裁剪结果在所有裁剪结果中的比例,可以反映一般裁剪水平。本文所采用的计算方法如下:

其中,IoUi的定义与公式(3)相同。
Disp
Disp测量裁剪窗口的每一边与GT裁剪窗口之间的平均距离。平均Disp的计算方法如下:
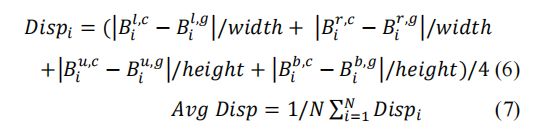
其中{l,r,u,b}分别对应左、右、上、下。
![]()
表示图像i的裁剪窗口的左边值
![]()
表示GT裁剪窗口的左边值,以此类推。注意,x方向和y方向的边界距离分别由图像的宽度和高度归一化。
实验结果及分析
- vgg微调的实验
比较VGGNet和VGG_finetune在FCD和CUHK-ICD上以及添加强化学习之前和之后。我们在FCD上用50次迭代训练VGGNet,输出4个对应于裁剪窗口的4个坐标。并从50次迭代中选择最优模型作为baseline VGG。如上所述,VGG_finetune 是在 FCD 训练集上用 10次迭代 对 fc6 层进行微调后的最佳模型。
结果如下:表2为CUHK-ICD上的测试结果,表3为FCD上的测试结果。从实验结果中可以看出,VGGNet本身并不适合裁剪任务,经过微调后的结果显著增加。RL的加入也显著地提高了裁剪质量。

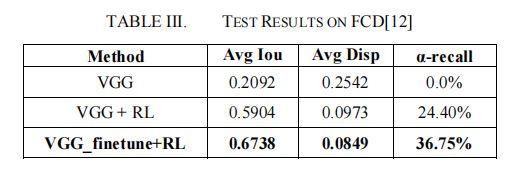
- 损失实验
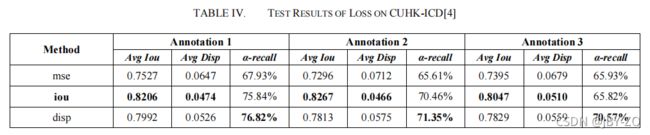
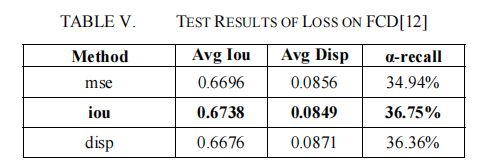
我们对CUHK-ICD和FCD进行了损失的比较实验,结果如表4和表5所示。损失是指公式(2)中r(t)的组成。Iou和disp分别对应于公式(4)和公式(7)。Mse的计算方法如下:
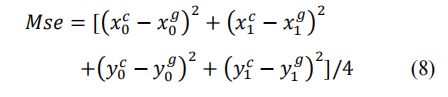
其中,
![]()
表示裁剪窗口的坐标,
![]()
表示GT裁剪窗口的坐标。
根据实验结果,选择iou计算r(t)的裁剪效果最好。因此,在最终模型中用iou计算r(t)。
与其他方法进行比较
裁剪精度评价
为了评价DLRL的裁剪精度,我们在FCD和CUHK-ICD上进行了实验。为进行比较而选择的裁剪方法涵盖了所有常见的自动图像裁剪方法。
- EDN是一种基于注意的裁剪方法。它通过最大限度地提高保留部分和丢弃部分之间的显著性分数的差异来选择最终的裁剪窗口。[12]中给出的最优结果被选来进行比较结果。
- MNACNN和RankSVM+FCD都是基于美学的裁剪方法。[7]中给出的结果被选来进行比较。
- VFN+SW是一种基于美学的裁剪方法。通过滑动窗口法产生大量的候选裁剪结果,并通过美学评价选择最佳的结果。比较结果选自原论文。
- ABP+AA是一种基于美学和显著性的综合评价方法,并选择了原文中的最佳结果进行比较结果。
- A2RL是一种基于美学的裁剪方法。利用视图查找网络(VFN)进行美学评价,并通过强化学习逐步进行裁剪。比较采用原文中给出的最佳结果。
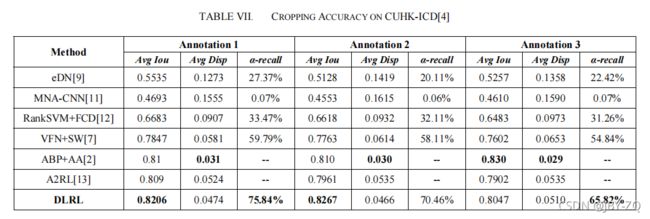
具体的实验结果如下:表6为FCD的结果,表7为CUHK-ICD的结果。从试验结果中可以看出,该方法的裁剪质量令人满意。裁剪结果不仅更接近GT,而且良好的裁剪结果在整体裁剪结果中所占的比例也较高。

对时间效率的评估
我们用两个指标来测试在FCD上的裁剪效率:平均裁剪时间(平均时间)和平均裁剪步骤(平均步骤),它们用于测量平均切割单个图像所需的时间和步骤。同时,保留了IoU和Disp的结果来说明裁剪质量。测试实验在一个NVIDIA GeForce GTX1080Ti GPU上进行,使用Intel®核心™i7-6800kCPU。由于A2RL[13]也是基于强化学习的,所以我们选择A2RL进行比较。在实验中,A2RL[13]的裁剪步骤上限设置为20,与[13]的原始设置相同。VFN+SW[7]使用了[7]中的所有原始设置,我们将生成的候选裁剪程序的数量视为裁剪步骤。实验结果如表8所示。
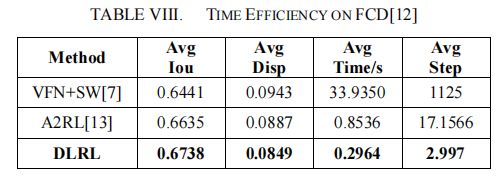
从表8可以看出,我们发现,生成1125个候选裁剪的VFN+SW[7]仍然不如我们的方法,这意味着表6中给出的VFN+SW[7]的结果需要超过1125个候选裁剪和33秒才能比DLRL多不到1%。根据实验结果和分析,该方法在图像自动裁剪方面性能最好。可在5步内完成裁剪,具有效率和质量。
5 结论
本文提出了一种用于自动图像裁剪的DLRL框架(深度学习结合强化学习的框架)。该方法根据图像的基本特征,一步一步地进行裁剪,符合人们裁剪模式。而且它不需要产生大量的候选结果。实验结果表明,DLRL不仅提高了图像裁剪效率,而且取得了良好的裁剪效果。