【CUDA编程】学习笔记(二) GPU硬件架构
一、CPU与GPU的链接模型
在计算机的硬件架构中,CPU与GPU有多种链接模式,下面介绍几种典型的架构
北桥
多CPU(SMP)

多CPU(NUMA)

多CPU(NUMA)多总线

具有集成PCI Express的多CPU

集成GPU

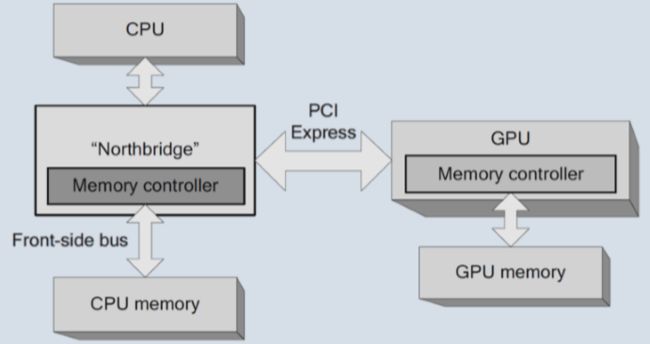
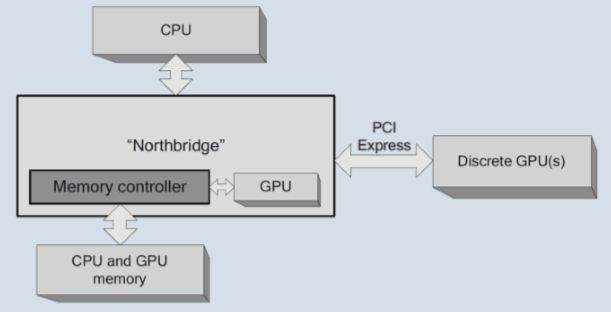
集成GPU与独立GPU
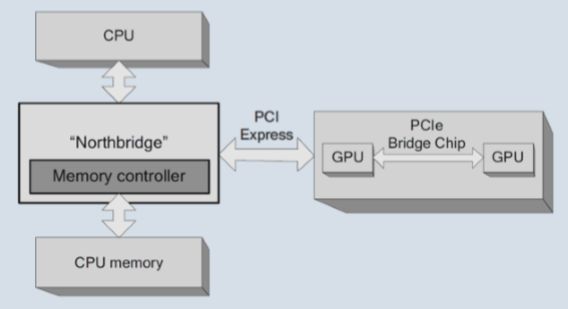
多个插槽中的GPU

多GPU板
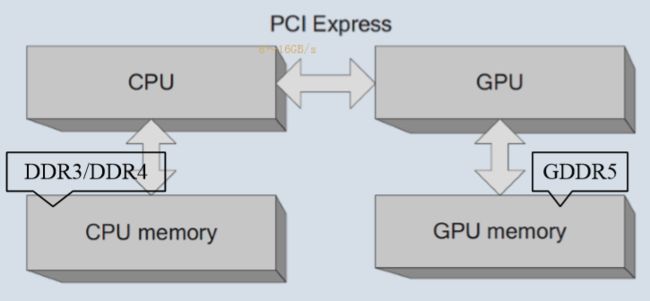
简化了CPU / GPU架构
二、开普勒架构
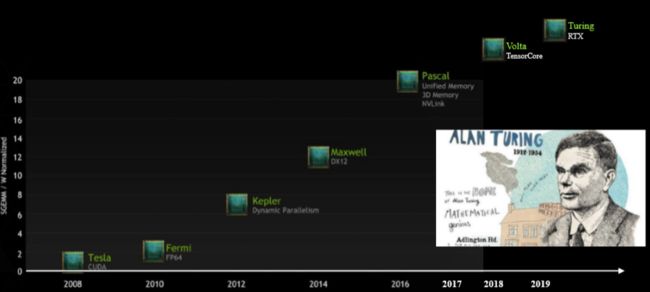
下面这张图是各代GPU架构的迭代顺序,目前最新的架构是Turing
开普勒微架构

以GTX 680为例
✓ Codenamed “GK104”
✓ 3.54 billion transistors
✓ 8 SMX
✓ 1536 CUDA Cores
✓ 3090 GFLOPs
✓ 192GB/s Memory BW
✓ TSMC’s 28nm manu.
✓ TDP 195W
开普勒SMX处理器
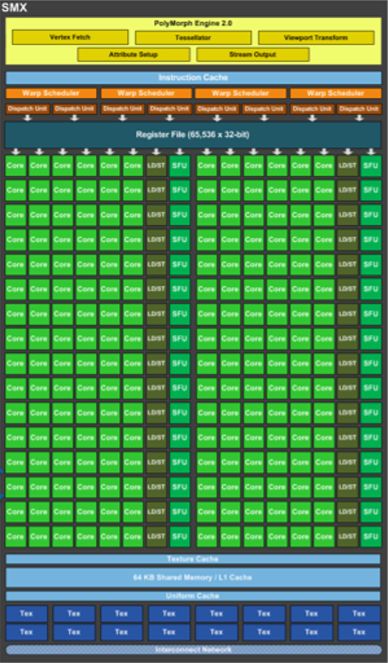
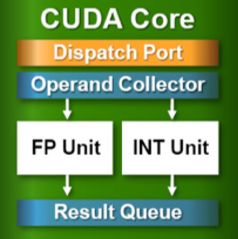
每个SMX (GK104)的参数如下:
✓ 192 CUDA Cores
✓ Runs at graphics clock
✓ 32 LD/ST units
✓ 32 SFU
✓ 64KB shared mem/L1 Cache
✓ 64K Registers
✓ 4 Warp Schedulers
Quad-Warp调度程序
一个Warp等于32个并行线程
每个warp调度程序能够在每个时钟每个warp发送两条指令
每个warp允许每个循环两个独立的指令
开普勒
●消费级显卡 (GeForce):
✓ GTX650 Ti: 768 cores, 1/2GB
✓ GTX660 Ti: 1344 cores, 2GB
✓ GTX680: 1536 cores, 2/4GB
✓ GTX690: 2×1536 cores, 2×2GB
✓ GTX 780: 2304 cores, 3GB
✓ GTX TITAN: 2688 cores, 6GB
●HPC cards (Tesla):
✓ K10 module: 2×1536 cores, 2×4GB
✓ K20 card: 2496 cores, 5GB
✓ K20X module: 2688 cores, 6GB
✓ K40 card:2880 cores, 12GB
✓ K80 module:4992 cores, 24GB

三、费米架构

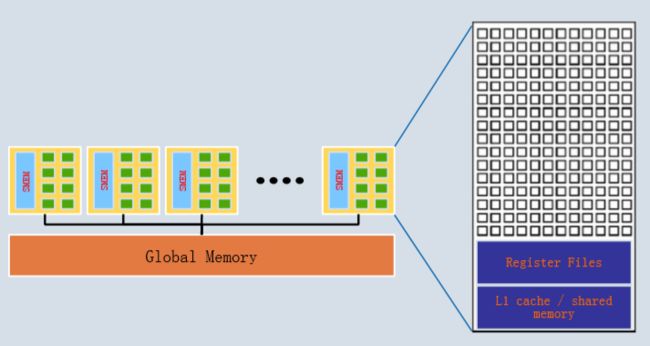
费米架构SM的参数
✓ 32 cores and 32k registers
✓ 64KB of shared memory / L1 cache
✓ 8KB cache for constants
✓ up to 1536 threads per SM
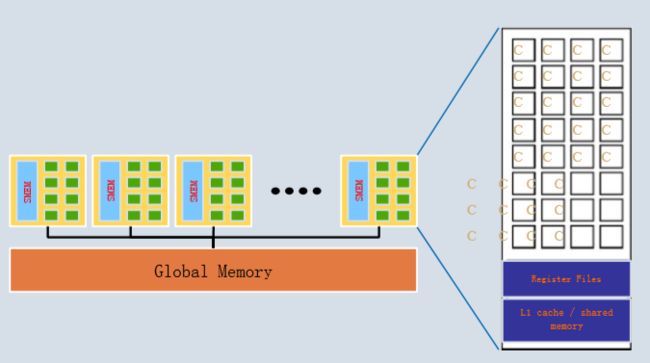
四、较新的架构
麦克斯韦微架构
以GTX 980为例
✓ Codenamed “GM204”
✓ 5.2 billion transistors
✓ 16 SMX
✓ 2048 CUDA Cores
✓ 4612 GFLOPs
✓ 224GB/s Memory BW
✓ TSMC’s 28nm manu.
✓ TDP 165W
✓ L2 Cache 2MB (GTX680 512KB)

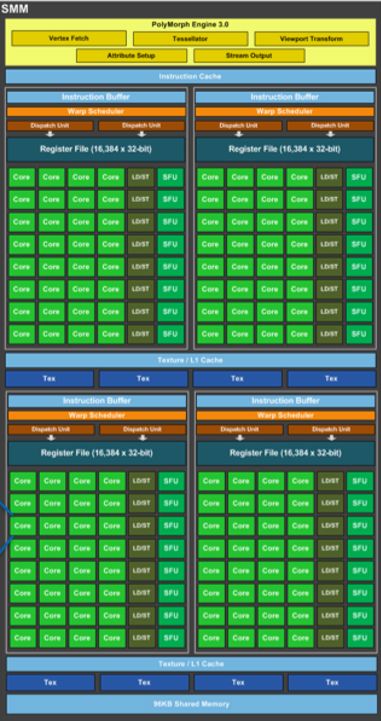
SMM (GM204)
✓ 128 CUDA Cores
✓ 96KB shared mem/L1 Cache
✓ L1 Cache is Shared with texture cache
✓ 64K Registers
✓ 4 Warp Schedulers
帕斯卡微架构
以Tesla P100为例:
✓ Codenamed “GP100”
✓ 15.3 billion transistors
✓ 56 of 60 SMs
✓ 3584 CUDA Cores
✓ 5.3 TF double precision/10.6 TFLOPs/21.2TF half precision
✓ 16 GB HBM2
✓ 720GB/s Memory BW
✓ TSMC’s 16nm manu.
✓ TDP 300W
✓ L2 Cache 4MB (GTX680 512KB)
✓ register 14336KB
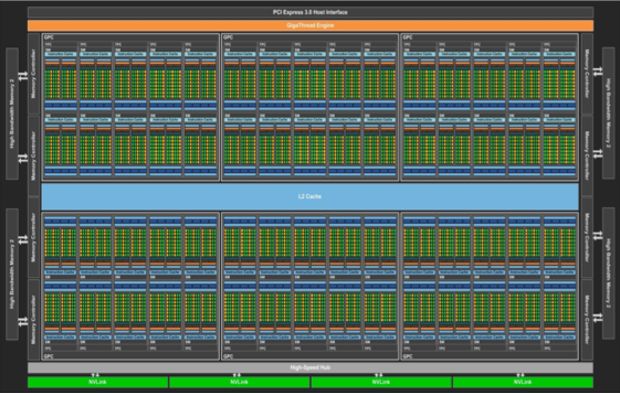
SMX (GP100)

VOLTA架构

图灵微架构
以GTX 2080 Ti (Founders Edition)为例
✓ Codenamed “TU102”
✓ 18.6 billion transistors
✓ 68 of 72 SMs
✓ 4352 of 4608 CUDA Cores
✓ 14.2 TFLOPs/28.5TF half precision
✓ 113.8 Tensor TFLOPS
✓ 16 GB HBM2
✓ 616 GB/s Memory BW
✓ TSMC’s 12nm manu.
✓ TDP 260W
✓ L2 Cache 5.5MB (GTX680 512KB)
✓ register 17408KB

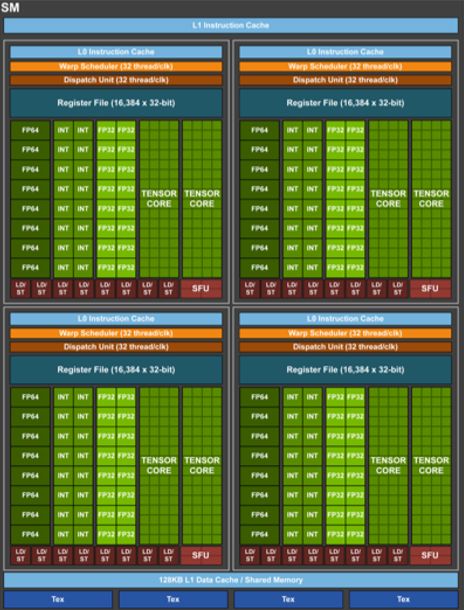
SMX (TU102)
✓ 64 FP32 Cores and 64 INT32 Cores
✓ 8 mixed-precision Turing Tensor Cores
✓ 96KB shared mem
✓ 256KB Registers
✓ 4 Warp Schedulers
