TensorFlow1.x 笔记
文章目录
- 一、 概述
- 二、环境安装
- 三、快速入门
-
-
- 1、计算模型-计算图
- 2、数据模型-张量
- 3、运行模型-会话
- 4、tensorflow编程步骤
- 5、TensorFlow编程基础
- 6、Tensorflow 可视化
- 7、实例 拟合一元二次函数
-
- 四、深层神经网络
-
-
- 1、深度学习与深层神经网络
- 2、损失函数
- 3、优化算法
- 4、实例 MNIST
- 5、tensorflow游乐场
-
- 五、tensorflow模型持久化
-
-
- 1、模型保存
- 2、模型的加载
- 3、convert_variables_to_constants 函数
- 4、通过tensorboard查看meta模型文件的Graph
- 5、通过tensorboard查看pb文件(包括模型结构与变量参数值)的Graph
- 6、查看pb文件每层节点张量名称
- 7、meta模型文件转PB模型文件
-
- 六、卷积神经网络
-
-
- 1、图像识别经典数据集介绍
- 2、卷积神经网络介绍
- 3、经典卷积神经网络模型
- 4、迁移学习
- 5、基于inception-V3迁移学习实例
- 6、图像数据预处理
-
- 七、TensorFlow计算加速
-
-
- 1、tensorflow使用GPU
- 3、并行训练
- 4、TensorFlow分布式训练
-
一、 概述
TensorFlow 谷歌提供的一个实现机器学习和构建深层神经网络的开源框架。
二、环境安装
pip install tensorflow
三、快速入门
1、计算模型-计算图
2、数据模型-张量
3、运行模型-会话
4、tensorflow编程步骤
-
分析实际问题,建立抽象模型,确定网络结构
-
根据网络结构定义输入输出节点
# 通过占位符定义输入(Nx1矩阵) X = tf.placeholder(tf.float32,shape=[None,1]) # 通过占位符定义输出期望(Nx1矩阵) Y = tf.placeholder(tf.float32,shape=[None,1]) -
定义运算(网络层运算)
def add_layer(input,in_size,out_size,active_function): # input 输入矩阵 # in_size 输入矩阵列大小 # out_size 输出矩阵列大小 # active_function 激活函数 weighs = tf.Variable(tf.random_normal([in_size,out_size])) bais = tf.Variable(tf.zeros([1,out_size])) # 激励输入 z_i = tf.matmul(input,weighs) + bais return active_function(z_i)
-
定义损失函数
# OUT 为输出节点数据 loss = tf.reduce_mean(tf.reduce_sum(tf.square(OUT-Y))) -
定学习参数
# 定义学习速率,参数越大训练收敛速度快,但可能会在最优解两侧来回震荡。需根据实际情况调整 leanring = 0.0001 -
定义优化器
# 使用梯度下降算法,对目标函数(loss)最小化 train_step = tf.train.GradientDescentOptimizer(leanring).minimize(loss) -
初始化TensorFlow中变量
init = tf.global_variables_initializer() -
训练模型
# R T 为准备好的训练集数据,R表示输入,T表示期望输出 with tf.Session() as sess: sess.run(init) for i in range(10000): sess.run(train_step, feed_dict={X: R, Y: T}) if i % 100== 0: # 打印损失值 e = sess.run(loss, feed_dict={X: R, Y: T}) print(e)
5、TensorFlow编程基础
-
运行环境(Session会话的使用)
import tensorflow as tf hi = tf.constant('hi') session = tf.Session() print(tf.run(session)) # 需调用close方法释放资源 session.close() # TensorFlow2中 # tf.compat.v1.disable_eager_execution() # session = tf.compat.v1.Session() ''' with 结构方式自动释放资源 ''' import tensorflow as tf hi = tf.constant('hi') with tf.Session() as sess: print(tf.run(sess)) -
占位符placeholder
import tensorflow as tf a = tf.placeholder(tf.float16) b = tf.placeholder(tf.float16) c = tf.add(a,b) with tf.Session() as sess: print(sess.run(c,feed_dict={a:1,b,2})) -
指定设备运算
import tensorflow as tf a = tf.placeholder(tf.float16) b = tf.placeholder(tf.float16) c = tf.add(a,b) with tf.Session() as sess: with tf.device('/gpu:0'): print(sess.run(c,feed_dict={a:1,b,2})) -
模型的保存与载入
# 保存 tensorflow2完整实例 import tensorflow as tf tf.compat.v1.disable_eager_execution() x = tf.compat.v1.placeholder(dtype=tf.float32,shape=[1,1]) k = tf.compat.v1.Variable([[5.0]]) y = tf.matmul(k,x) init = tf.compat.v1.global_variables_initializer() saver = tf.compat.v1.train.Saver() with tf.compat.v1.Session() as sess: sess.run(init) d = sess.run(y,feed_dict={x:[[5.0]]}) print(d) saver.save(sess=sess, save_path='test.cpkt') #---------------------------------------------------- # 载入 saver = tf.train.Saver() saver.restore(session,'model/test.cpkt') # 使用模型 print(session.run(y,feed_dict={X:12})) -
tensorflow数据模型(张量)
数据引用,描述了数据计算方式、数据形状、数据类型。
-
规约聚合算子
tf.reduce_XXX(mean、sum、prod、max、min、any、all)
-
大数据加载
import tensorflow as tf tf.compat.v1.disable_eager_execution() file_names = ['img/A.png', 'img/B.png', 'img/C.png'] # 对file_names copy num_epochs份,shuffle是否打乱顺序 # file_name_queue仅是一个描述文件名的队列 file_name_queue = tf.compat.v1.train.string_input_producer(file_names, shuffle=True, num_epochs=2) reader = tf.compat.v1.WholeFileReader() file_name, file_data = reader.read(file_name_queue) with tf.compat.v1.Session() as sess: sess.run(tf.compat.v1.global_variables_initializer()) sess.run(tf.compat.v1.local_variables_initializer()) # 调用该方法才能填充文件队列 thread = tf.compat.v1.train.start_queue_runners(sess=sess) try: while True: print(sess.run(file_data)) except Exception as e: print(e)
6、Tensorflow 可视化
-
安装
pip install tensorboard
-
使用
import tensorflow as tf tf.compat.v1.disable_eager_execution() x = tf.compat.v1.placeholder(dtype=tf.float32,shape=[1,1]) # 记录x tf.compat.v1.summary.scalar("x",tf.reduce_mean(x)) k = tf.compat.v1.Variable([[5.0]]) y = tf.matmul(k,x) # 记录y tf.compat.v1.summary.scalar("y",tf.reduce_mean(y)) init = tf.compat.v1.global_variables_initializer() with tf.compat.v1.Session() as sess: sess.run(init) # 合并所有的 summary summary_op = tf.compat.v1.summary.merge_all() # 创建 summary_writer summary_writer = tf.compat.v1.summary.FileWriter('tensorboard/',sess.graph) for i in range(100): d = sess.run(y,feed_dict={x:[[i]]}) # 生成summary summary_str = sess.run(summary_op,feed_dict={x:[[i]]}) # 写summary summary_writer.add_summary(summary_str,i) print(d)# log 所在目录下执行 tensorboard --logdir ./
7、实例 拟合一元二次函数
-
问题描述
准备两个集合 x={…},y={…} ,使得满足
y = 0.2 x 2 − x + 1 y=0.2x^2-x+1 y=0.2x2−x+1
通过tensorflow构建一个简单的神经网络,使用x、y集合数据(训练集)训练这个神经网络,使得最后训练出的神经网络模型满足以上公式。 -
确定网络结构
定义四层:输入层:三个神经元,每个神经元仅一个输入,三个输入端均为x,输入层不计算,各权值w=1。1x3权值矩阵
隐藏层1:四个神经元,每个神经元三个输入。3x4 权值矩阵
隐藏层2:四个神经元,每个神经元四个输入。4x4权值矩阵
输出层:一个神经元,四个输入。 4x1权值矩阵每层权值矩阵形状确定:N个神经元,每个神经元有M个输入,则该层的权值矩阵为MxN,偏差向量为1xN
-
准备训练集数据
# -20~20范围生成2000个等间隔数据 x = np.linspace(-20,20,2000) y = 0.2*(x*x)-x+1 # 根据网络结构,输入层有三个神经元,所以训练集数据X需copy三份,组成一个Nx3的矩阵 # 沿着col方向,横轴方向拼接 2000x3 x = np.hstack((x.reshape(2000,1),x.reshape(2000,1),x.reshape(2000,1))) # y变换为nummpy数组,2000x1 y = np.array(y).reshape(2000,1) # 数据归一化 x = (x-np.min(x))/(np.max(x)-np.min(x)) y = (y-np.min(y))/(np.max(y)-np.min(y)) -
定义输入输出节点
# 通过占位符定义输入 X_nn = tf.compat.v1.placeholder(tf.float32,shape=[None,3]) # 通过占位符定义输出期望 Y_nn = tf.compat.v1.placeholder(tf.float32,shape=[None,1]) -
定义运算
def add_layer(input,in_size,out_size,active_function): # input 输入矩阵 # in_size 输入矩阵列大小 # out_size 输出矩阵列大小 # active_function 激活函数 weighs = tf.Variable(tf.compat.v1.random_normal([in_size,out_size])) bais = tf.Variable(tf.compat.v1.zeros([1,out_size])) # 激励输入 z_i = tf.matmul(input,weighs) + bais return active_function(z_i) -
定义激活函数
# 定义激活函数 def sigmoid(x): return tf.nn.sigmoid(x) -
前向传播
# 隐藏层1 out_h1 = add_layer(X_nn,3,4,sigmoid) # 隐藏层2 out_h2 = add_layer(out_h1,4,4,sigmoid) # 输出层 out = add_layer(out_h2,4,1,sigmoid) -
定义损失函数
loss = tf.reduce_mean(tf.reduce_sum(tf.square(out-Y_nn))) -
定义学习速率
lean = 0.001 -
定义优化器
train_step = tf.compat.v1.train.GradientDescentOptimizer(lean).minimize(loss) -
初始化变量
init = tf.global_variables_initializer() -
训练模型
with tf.compat.v1.Session() as sess: sess.run(init) for i in range(50000): sess.run(train_step, feed_dict={X_nn: x, Y_nn: y}) # 每100step打印一次损失值 if i % 1000 == 0: print("loss=",sess.run(loss,feed_dict={X_nn: x, Y_nn: y})) -
验证模型
# 生成测试集 def create_test_dataSet(): # -20~20范围生成1500个等间隔数据 x = np.linspace(-20, 20, 1500) y = 0.2 * (x * x) - x + 1 # 沿着col方向,横轴方向拼接 2000x3 x = np.hstack((x.reshape(1500, 1), x.reshape(1500, 1), x.reshape(1500, 1))) y = np.array(y).reshape(1500,1) # 最值归一化 x = (x-np.min(x))/(np.max(x)-np.min(x)) y = (y-np.min(y))/(np.max(y)-np.min(y)) return x,y # 验证 x_test,y_label = create_test_dataSet() y_real = sess.run(out,feed_dict={X_nn: x_test}) plt.rcParams['font.sans-serif']=['SimHei'] #显示中文标签 plt.rcParams['axes.unicode_minus']=False plt.plot(x_test,y_label) plt.plot(x_test,y_real,'r',label = "预测曲线") plt.legend() plt.grid() plt.show()
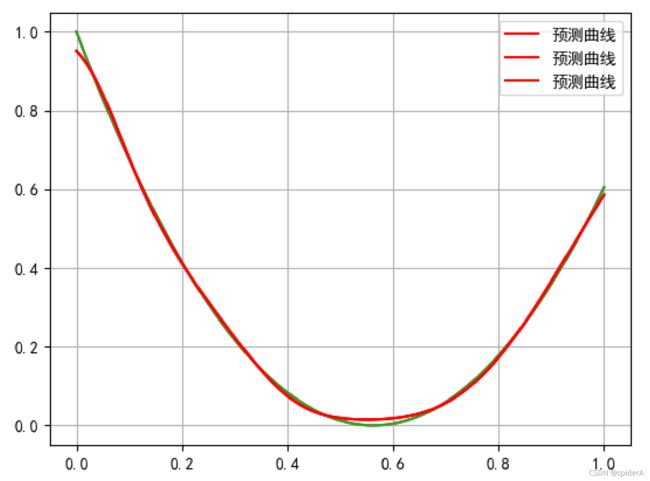
- 训练过程可视化
# 记录loss
tf.compat.v1.summary
.scalar("loss",loss)
# 合并所有的 summary
summary_op = tf.compat.v1.summary.merge_all()
# 创建 summary_writer
summary_writer = tf.compat.v1.summary.FileWriter('tensorboard/',sess.graph)
# 生成summary
summary_str = sess.run(summary_op,feed_dict={X_nn: x, Y_nn: y})
# 写summary
summary_writer.add_summary(summary_str,i)
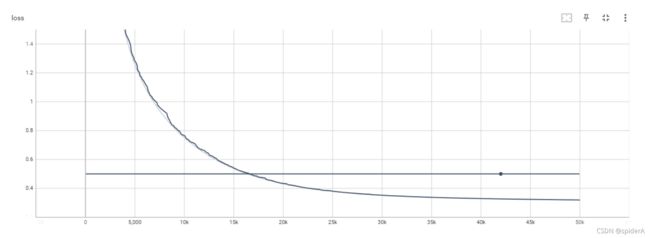
-
完整代码
import tensorflow as tf import numpy as np import matplotlib.pyplot as plt tf.compat.v1.disable_eager_execution() # 定义层的运算 def add_layer(input, in_size, out_size, active_function): # input 输入矩阵 # in_size 输入矩阵列大小 # out_size 输出矩阵列大小 # active_function 激活函数 weighs = tf.Variable(tf.compat.v1.random_normal([in_size, out_size])) bais = tf.Variable(tf.compat.v1.zeros([1, out_size])) # 激励输入 z_i = tf.matmul(input, weighs) + bais return active_function(z_i) # -20~20范围生成2000个等间隔数据 x = np.linspace(-20, 20, 2000) y = 0.2 * (x * x) - x + 1 # 沿着col方向,横轴方向拼接 2000x3 x = np.hstack((x.reshape(2000, 1), x.reshape(2000, 1), x.reshape(2000, 1))) y = np.array(y).reshape(2000, 1) # 最值归一化 x = (x - np.min(x)) / (np.max(x) - np.min(x)) y = (y - np.min(y)) / (np.max(y) - np.min(y)) # 通过占位符定义输入 X_nn = tf.compat.v1.placeholder(tf.float32, shape=[None, 3]) # 通过占位符定义输出期望 Y_nn = tf.compat.v1.placeholder(tf.float32, shape=[None, 1]) # 前向传播 # 隐藏层1 out_h1 = add_layer(X_nn, 3, 4, tf.nn.sigmoid) # 隐藏层2 out_h2 = add_layer(out_h1, 4, 4, tf.nn.sigmoid) # 输出层 out = add_layer(out_h2, 4, 1, tf.nn.sigmoid) # 定义损失函数 loss = tf.reduce_mean(tf.reduce_sum(tf.square(out - Y_nn))) # 记录loss tf.compat.v1.summary.scalar("loss",loss) # 定义学习速率 lean = 0.001 # 使用梯度下降算法 train_step = tf.compat.v1.train.GradientDescentOptimizer(lean).minimize(loss) # 初始化变量 init = tf.compat.v1.global_variables_initializer() def create_test_dataSet(): # -20~20范围生成1500个等间隔数据 x = np.linspace(-20, 20, 1500) y = 0.2 * (x * x) - x + 1 # 沿着col方向,横轴方向拼接 1500x3 x = np.hstack((x.reshape(1500, 1), x.reshape(1500, 1), x.reshape(1500, 1))) y = np.array(y).reshape(1500, 1) # 最值归一化 x = (x - np.min(x)) / (np.max(x) - np.min(x)) y = (y - np.min(y)) / (np.max(y) - np.min(y)) return x, y with tf.compat.v1.Session() as sess: sess.run(init) # 合并所有的 summary summary_op = tf.compat.v1.summary.merge_all() # 创建 summary_writer summary_writer = tf.compat.v1.summary.FileWriter('tensorboard/',sess.graph) for i in range(50000): sess.run(train_step, feed_dict={X_nn: x, Y_nn: y}) # 生成summary summary_str = sess.run(summary_op,feed_dict={X_nn: x, Y_nn: y}) # 写summary summary_writer.add_summary(summary_str,i) # 每100step打印一次损失值 if i % 1000 == 0: print("loss=", sess.run(loss, feed_dict={X_nn: x, Y_nn: y})) # test x_test, y_label = create_test_dataSet() y_real = sess.run(out, feed_dict={X_nn: x_test}) plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文标签 plt.rcParams['axes.unicode_minus'] = False plt.plot(x_test, y_label) plt.plot(x_test, y_real, 'r', label="预测曲线") plt.legend() plt.grid() plt.show()
四、深层神经网络
1、深度学习与深层神经网络
-
深度学习
多层非线性变换,解决复杂建模
深层神经网络是实现深度学习的技术
-
线性模型的局限性
输入与输出是线性关系。无法处理复杂问题(不能用直线或高维中平面划分)
线性模型只能处理线性可分问题。
-
浅层网络局限性
仅有一层的神经网络,无法解决异或问题。
-
激活函数去线性化
输入与权值加权求和后,在经过某一函数(激活函数)变换后输出。

常用激活函数
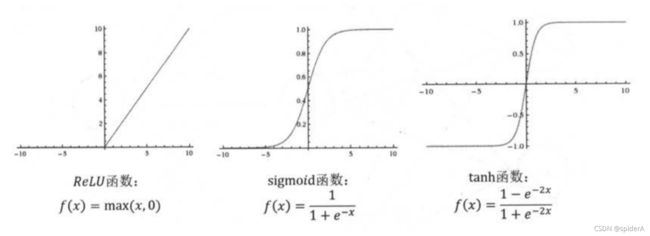
-
带隐藏层网络(深层神经网络)解决异或问题
隐藏层神经元可提取输入数据高层特征。
2、损失函数
-
损失函数是网络模型训练优化的目标,是模型输出与期望偏差关于网络参数的一个函数。不同问题选取的损失函数也不一样。
-
分类问题的损失函数
分类问题是模型完成对输入样本划分为某一类别的问题。如图片内容识别。
两分类问题,可设置一个输出节点,节点输出为一个标量,当值大于某个阈值判定为L1类,反之判定为L2类。
对于N分类问题,一般常规做法是,定义N个输出节点,对于每一个样例,神经网络可以得到的一个 n 维数组作为输出结果。数组中
的每一个维度(也就是每一个输出节点)对应一个类别。在理想情况下,如果一个样本属于类别 k, 那么这个类别所对应的输出节点的
输出值应该为 1 , 而其他节点的输出都为 0。以识别数字 1为例,神经网络模型的输出结果越接近**[0,1,0,0,0,0,0,0,0,0](可看成是数**
**字为1的一个概率分布)**越好。那么如何判断一个输出向量和期望的向量有多接近呢?交叉熵(cross entropy)是常用的评判方
法之一。交叉熵刻画了两个概率分布之间的距离, 它是分类问题中使用 比较广的一种损失函数。
令实际输出为y,期望为y_ ,则交叉熵表示为:
l o s s = ∑ y _ l o g y loss=\sum y\_logy loss=∑y_logyloss = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y, le-10, 1.0)))loss 值越小,表示y与y_越接近。
以上实际y与期望y_均看成了是一个概率分布,所以需要将神经网络前向传播结果变成一个概率分布。
softmax回归
softmax在分类模型的最后一层,用于将输出转换成概率分布
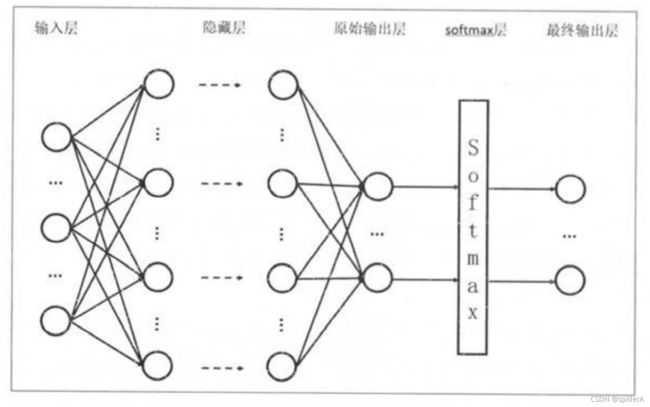
假设输出有N个节点,原始输出为y1,y2, y3…yn,则经过softmax回归后输出为:
y ( i ) = s o f t m a x ( y ) = e y i ∑ i = 1 n e y i y(i) = softmax(y) = \frac {e^{y^i}} {\sum_{i=1}^n e^{y^i}} y(i)=softmax(y)=∑i=1neyieyi
# 直接回归后算交叉熵
loss = tf.nn.softmax_cross_entropy_with_logits(labels=y_,logits=y)
-
回归问题的损失函数
回归问题是对输入值的预测,一般只有一个节点输出。回归问题中损失函数一般采用均方误差。
m s e ( y , y _ ) = ∑ i = 1 n ( y i − y _ i ) 2 n mse(y,y\_) =\frac{\sum_{i=1}^n (y^i-y\_^i)^2} {n} mse(y,y_)=n∑i=1n(yi−y_i)2loss = tf.reduce_mean(tf.square(y_-y))
3、优化算法
-
梯度下降
梯度下降算法用于寻找一个最优的解使得损失函数最小化。
设损失函数为 J(θ) ,θ表示网络中参数(w、b),为寻找一个θ参数使得J(θ)取极小值,梯度算法的思想是随着每一轮的迭代,不断调整参数θ,调整方式是新的θ等于旧的θ减去一个系数乘以 J(θ)在旧 θ处的导数。
θ n + 1 = θ n − η ∂ J ( θ n ) ∂ θ n \theta_{n+1} = \theta_{n} - \eta \frac {\partial J(\theta_{n})} {\partial \theta_{n}} θn+1=θn−η∂θn∂J(θn)train_step = tf.train.GradientDescentOptimizer(0.001) .minimize(loss)公式中η为学习速率,可以认为是更新参数θ快慢的一个参数。
由公式可以看出梯度下降算法并不能完全保证J(θ)到达最小值,如果θ处于局部的一个谷点(局部极小值)时,梯度项为0,此时参数θ将不会得到调整。只有当损失函数为凸函数时才能保证到达全局最优解。神经网络的优化过程可以分为两个阶段:
第一个阶段先通过前向传播 算法计算得到预测值,井将预测值和真实值做对比得出两者之间的差距。
第二个阶段通过反向传播算法计算损失函数对每一个参数的梯度,再根据梯度和学习率使用梯度下降算法更新每一个参数 -
随机梯度下降
损失函数J(θ)表示的是在所有训练集数据上的损失和,在每一轮迭代时,会计算所有训练样本的损失,当训海量数据时,会比较耗时,为了加速训练,可以在每一轮迭代中随机抽取一个固定batch大小的数据进行训练。
batch_size = 100 # 每次读取一小部分数据作为当前的训练数据来执行反向传播算法。 x = tf.placeholder(tf.float32, shape=(batch size,2)) y = tf.placeholder(tf.float32 , shape=(batch_size,1)) # 定义神经网络结构和优化算法。 。。。。。。 train_step = tf. train.GradientDescentOptimizer(0.001) .minimize(loss) # 训练神经网络。 with tf.Session() as sess : #参数初始化。 。。。。。。 for i in range(STEPS): #准备 batch size 个训练数据。 一般将所有训练数据随机打乱之后再选取可以得到好的优化效果。 current_X, current_Y = read_batch_train(batch_size) sess.run(train_step, feed_dict={x : current_X,y: current_Y}) -
学习速率的设定
学习速率用于控制网络参数的更新速度,值大了,算法收敛速度快,但是容易发生震荡(loss值在某两个值之间来回变动),值小了收敛速度慢,加长了模型训练时间。
一般情况是希望在训练初期使用较大的学习速率,加速模型训练,在训练后期使用较小的学习速率,对模型参数进行微调,使其能够找到最优的解。
global_step= tf.Variable(O) # 通过 exponential_decay 函数生成学习率。 # 初始速率0.1,后面每训练100次后在学习速率基础上乘以0.96 learning_rate = tf.train.exponential_decay( 0.1, global_step, 100, 0.96, staircase=True) # 使用指数农减的学习惑。在 minimize 函数中传入 global_step 将自动更新 # global_step 参数,从而使得学习率也得到相应更新。 learning_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step) -
过拟合问题
当 一个模型过为复杂之后,它可以很好地“记忆”每一个训练数据中随机噪音的部分而忘记 了要去“学习”训练数据中通用的趋势
可以直观地想象一个包含 n 个变量和 n 个等式的方程组, 当方程不冲突时,这个方程组是可以通过数学的方法来求解的。
解决过拟合的基本思想是限制网络的参数,使得他不能任意拟合训练数据中的随机噪声。限制网络参数的方法是在原损失函数中再加一个刻画网络复杂度的项,R(W),W表示网络参数
l o s s = J ( θ ) + λ R ( w ) loss = J(\theta) + \lambda R(w) loss=J(θ)+λR(w)
λ为一个系数,表示引入R(W)的权重。
这样在对loss进行优化时,将同时优化两部分,前面提到需要限制网络的参数的大小,所有一般R(W)函数可选取以下方式:
R ( w ) = ∑ ∣ w ∣ ( L 1 正 则 化 ) 或 R ( w ) = ∑ ∣ w ∣ 2 ( L 2 正 则 化 ) R(w) =\sum |w|(L1正则化)\quad \quad 或\quad \quad R(w) =\sum |w|^2 (L2正则化) R(w)=∑∣w∣(L1正则化)或R(w)=∑∣w∣2(L2正则化)
使用L1正则化后,会使网络参数变得稀疏(较多的参数w会变成0,这样可以达到特征选取的作用),L2正则化会使部分网络参数w变得很小。两则原理上都差不多。都是限制了w参数。
weights = tf.constant([[(1.0, -2.0), (-3.0,4.0)]])
with tf . Session() as sess:
# 输出为(|1.0|+|-2.0|+|-3.0|+|4.0|)*0.5=5。其中0.5为正则化项的权重。
sess.run(tf.contrib.layers.l1_regularizer(0.5).(weights))
# 输出为(1.0^2+(-2)^2+(-3)^2+4.0^2 )/2×0.5=7.5。
# TensorFlow会将正则化损失值除以2使得求导得到的结果更加简洁
sess.run(tf.contrib.layers.l2_regularizer(0.5).(weights))
一般情况下网络的前向传播部分与定义损失函数是分开的,不在一个函数中,可使用tensorflow提供的集合来解决这个问题。
def add_layer(input, in_size, out_size, active_function):
# input 输入矩阵
# in_size 输入矩阵列大小
# out_size 输出矩阵列大小
# active_function 激活函数
weighs = tf.Variable(tf.compat.v1.random_normal([in_size, out_size]))
# 定义L2正则化(定义刻画网络复杂度的损失函数)
r_loss = tf.contrib.layers.12_regularizer(0.5)(weighs)
# 加入集合,losses是集合的名字,第二个参数是要加入这个集合的内容。
tf.add_to_collection('losses', r_loss)
bais = tf.Variable(tf.compat.v1.zeros([1, out_size]))
# 激励输入
z_i = tf.matmul(input, weighs) + bais
return active_function(z_i)
# 定义模型在训练数据集上的损失函数
mes_loss = tf.reduce_mean(tf.reduce_sum(tf.square(out - Y_nn)))
# 将均方误差损失函数加入损失集合。
tf.add_to_collection ('losses', mes_loss)
# 总损失函数
loss = tf.add_n(tf.get_collection ('losses'))
-
滑动平均模型
网络结构参数会根据每轮的迭代进行更新,每一次调整的幅度与学习速率和当前迭代下损失函数梯度大小有关。训练过程中遇到loss函数变化剧烈的点时,梯度会有一个突变,相应网络参数θ也会突变,每一步参数θ的变动都会影响到最终的参数θ,通过实验发现当人为抑制这些突变后,最终网络参数θ对应的模型对测试数据集上的表现会比不抑制网参数θ的模型表现要好一些。
抑制参数突变算法思想是让当前参数的取值与上一次参数取值有关。
θ n = k θ n + ( 1 − k ) θ n − 1 ( 0 < k < 1 ) \theta_{n} = k\theta_n+ (1- k)\theta_{n-1} \quad\quad (0
k为衰减系数,当K值越小,抑制效果越明显模型训练时,一般不会使用滑动平均后的值来进行前向传播,仅在进行测试时使用滑动平均的网络参数来验证效果。所以模型在训练过程中既需要通过反向传播方式更新网络参数,还需要记录网络参数滑动平均后的值,即需要一个与实际网络参数平行的影子变量来记录滑动平均后值(不希望滑动平均后的值改变原有的值)
对上个式子稍作调整
θ ′ = k θ ′ + ( 1 − k ) θ ( 0 < k < 1 ) \theta^{'} = k \theta^{'}+ (1- k)\theta \quad\quad (0
每个原变量(θ)将对应一个影子变量(θ’),用来存储滑动平均后值。这样滑动平均后的值将不会影响原始的变量。TensorFlow 中提供了 tf.train.ExponentialMovingAverage 来实现滑动平均模型。
# 定义变量V v = tf.Variable(0, dtype=tf.float32) # 定义一个模拟迭代轮数的变量step,trainable=False表示该变量不会被滑动平均 step = tf.Variable(0, dtype=tf.float32,trainable=False) # 初始化滑动平均类 # 衰减系数k根据step动态变化,k = min{0.99,(1+step)/(10+step)} ema = tf.train.ExponentialMovingAverage(0.99,step) # 定义滑动平均操作,每次执行这个操作时变量都会更新 averages_op = ema.apply(v) with tf.Session() assess: # 初始化所有变量。 init_op= tf.global_variables_initializer() sess.run(init_op) # 通过 ema.average(v)获取滑动平均之后变量的值。 sess.run(averages_op) sess.run([v,ema.average(v)]) # [0.0,0.0] # 更新v的值 sess.run(tf.assign(v,5)) sess.run(averages_op) # 滑动平均后的值为:0*k+(1-k)*5 = 5*(1-min{0.99,1/10=0.1}) = 5*0.9 = 4.5 sess.run([v,ema.average(v)]) # [5.0,4.5]
4、实例 MNIST
-
MNIST数据集
下载地址: http://yann.lecun.com/exdb/mnist
MNIST是一个手写数字0~9的数据集,包含6W张图片训练集,1W张图片测试集,图片均为28x28的灰度图片。

-
完整代码
import numpy as np import tensorflow as tf import tensorflow.python.keras.datasets.mnist as mnist from keras.utils import np_utils tf.compat.v1.disable_eager_execution() # 定义mnist数据加载初始化 def data_init(): (x_train, y_train), (x_test, y_test) = mnist.load_data("E://python//tensorflow_study//MNIST_data//mnist.npz") x_train = np.reshape(x_train, (60000, 784)) x_test = np.reshape(x_test, (10000, 784)) x_train = (x_train - 255) / 255 x_test = (x_test - 255) / 255 # one-hot y_train = np_utils.to_categorical(y_train, 10) y_test = np_utils.to_categorical(y_test, 10) # 5.5W训练集 x_train_np = np.array(x_train[5000:], dtype='float32') # 5.5W训练集对应标签 y_train_np = np.array(y_train[5000:], dtype='float32') # 5K验证集 x_validate_np = np.array(x_train[0:5000], dtype='float32') # 5K验证集对应标签 y_validate_np = np.array(y_train[0:5000], dtype='float32') # 1W测试集 x_test_np = np.array(x_test[:], dtype='float32') # 1W测试集对应标签 y_test_np = np.array(y_test, dtype='float32') return {"x_train": x_train_np, "y_train": y_train_np} \ , {"x_validate": x_validate_np, "y_validate": y_validate_np} \ , {"x_test": x_test_np, "y_test": y_test_np} def getRandomIndex(n, x): # 索引范围为[0, n),随机选x个不重复,注意replace=False不重复 index = np.random.choice(np.arange(n), size=x, replace=False) return index # 随机获取数据 def train_data_batch_set(input_data_feed): batch = 500 index = getRandomIndex(55000, batch) return input_data_feed["x_train"][index], input_data_feed["y_train"][index] # 定义层函数 def add_layer(input, in_size, out_size, active_function): # input 输入矩阵 # in_size 输入矩阵列大小 # out_size 输出矩阵列大小 # active_function 激活函数 weighs = tf.Variable(tf.compat.v1.random_normal([in_size, out_size])) # 定义L2正则化(刻画网络复杂度的损失函数,解决过拟合问题) regularizers_L2 = tf.keras.regularizers.l2(0.00005) weighs_loss = regularizers_L2(x=weighs) # 加入集合,losses是集合的名字,第二个参数是要加入这个集合的内容。 tf.compat.v1.add_to_collection('losses', weighs_loss) bais = tf.Variable(tf.compat.v1.random_normal([1, out_size])) # 激励输入 z_i = tf.matmul(input, weighs) + bais return active_function(z_i) # 定义前向传播 def inference(input_tensor): # 第一层输入NX784形状输入,输出为NX500 out_1 = add_layer(input=input_tensor, in_size=784, out_size=500, active_function=tf.nn.relu6) # 第二层输入为NX500,输出为NX10 out_2 = add_layer(input=out_1, in_size=500, out_size=10, active_function=tf.nn.relu6) return out_2 # 定义模型训练过程 def train(): global_step = tf.Variable(0) TRAINING_STEPS = 10000 x = tf.compat.v1.placeholder(tf.float32, [None, 784]) y_ = tf.compat.v1.placeholder(tf.float32, [None, 10]) # 计算当前参数在神经网络上的结果 y = inference(x) # 使用交叉熵作为刻画顶训值和真实值之间差距的损失函数。 # 这里使用了 tf.softmax_cross_entropy_with_logits。 # 这个函数的第一个参数是经网络不包括 softmax 层的前向传播结果, # 第二个是训练数据的正确答案。 eross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=y, labels=y_) # 计算所有当前batch上的所有交叉熵平均值 cross_entropy_mean = tf.reduce_mean(eross_entropy) # 将交叉熵损失函数加入损失集合。 tf.compat.v1.add_to_collection('losses', cross_entropy_mean) # 总损失函数 loss = tf.add_n(tf.compat.v1.get_collection('losses')) # 记录loss tf.compat.v1.summary.scalar("loss", loss) # 初始速率0.1,后面每训练100次后在学习速率基础上乘以0.96 learning_rate = tf.compat.v1.train.exponential_decay(0.9, global_step, 5000, 0.9, staircase=True) # 使用tf.train.GradientDescentOptimizer 优化算法来优化损失函数。 train_step = tf.compat.v1.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step) # 检验。 # tf.argmax(y, 1) 计算每一个样例的预测答案。其中y是一个 batch_size*10 的二维数组, # 每一行表示一个样例的前向传播结果。 # tf.argmax 的第二个参数"l”表示选取最大值的操作仅在第一个维度中进行,也就是说,只在每一行选取最大值对应的下标。 # 于是得到的结果是一个长度为 batch_size 的一维数组,这个一维数组中的值就表示了每一个样例对应的数字识别结果。 # tf.equal 判断两个张量的每一维是否相等,如果相等返回 True,否则返回 False。 correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)) # 这个运算首先将一个布尔型的数值转换为实数型,然后计算平均值。这个平均值就是模型在这一组数据上的正确率。 accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) # 初始化会话并开始训练过程。 init_var = tf.compat.v1.global_variables_initializer() with tf.compat.v1.Session() as sess: sess.run(init_var) # 合并所有的 summary summary_op = tf.compat.v1.summary.merge_all() # 创建 summary_writer summary_writer = tf.compat.v1.summary.FileWriter('tensorboard/', sess.graph) train_feed, validate_feed, test_feed = data_init() for i in range(TRAINING_STEPS): train_batch_x, train_batch_y = train_data_batch_set(train_feed) sess.run(train_step, feed_dict={x: train_batch_x, y_: train_batch_y}) if i % 100 == 0: # loss loss_val = sess.run(loss, feed_dict={x: train_feed["x_train"], y_: train_feed["y_train"]}) # 一般在神经网络的训练过程中会通过验证数据来大致判断停止的条件和评判训练的效果。 validate_acc = sess.run(accuracy, feed_dict={x: validate_feed["x_validate"], y_: validate_feed["y_validate"]}) print("After %d training step(s) , accuracy=%f , loss=%f" % (i, validate_acc, loss_val)) # print("After %d training step(s) , loss=%f" % (i, loss_val)) # # 生成summary # summary_str = sess.run(summary_op, feed_dict={x: train_feed["x_train"], y_: train_feed["y_train"]}) # # 写summary # summary_writer.add_summary(summary_str, i) def main(): train() if __name__ == '__main__': main() -
结果
After 9200 training step(s) , accuracy=0.940800 , loss=4.287310 After 9300 training step(s) , accuracy=0.942200 , loss=4.206303 After 9400 training step(s) , accuracy=0.943200 , loss=4.146769 After 9500 training step(s) , accuracy=0.944800 , loss=4.074558 After 9600 training step(s) , accuracy=0.943600 , loss=4.015702 After 9700 training step(s) , accuracy=0.941600 , loss=3.950650 After 9800 training step(s) , accuracy=0.941000 , loss=3.894753 After 9900 training step(s) , accuracy=0.942600 , loss=3.831594
5、tensorflow游乐场
TensorFlow 游乐场 ( http://playground.tensorflow.org) 是一个通过网页浏览器就可以训练的简单神经网络并实现 了可视化训练过程的工具。
五、tensorflow模型持久化
1、模型保存
import tensorflow as tf
# 声明两个变量并计算它们的和。
v1 = tf.Variable(tf.constant(1.0,shape=[1]),name="v1")
v2 = tf.Variable(tf.constant(2.0, shape=[1]) , name="v2")
result = v1+v2
init_op= tf.global_variables_initializer()
# 声明 tf.train.Saver 类用于保存模型。
saver= tf.train.Saver()
with tf.Session() as sess:
sess.run(init_op)
# 将模型保存到/path/to/model/model.ckpt 文件。
saver.save(sess,"/path/to/model/model.ckpt")
TensorFlow 会将计算图的结构和图上参数取值分开保存
文件目录下会出现三个文件:
model.ckpt.meta: 保存了TensorFlow 计算图的结构
model.ckpt:保存了 TensorFlow 程序中每一个变量的取值
checkpoint:保存了一个目录下所有的模型文件列表
2、模型的加载
import tensorflow as tf
# 使用和保存模型代码中一样的方式来声明变量。
v1 = tf.Variable(tf.constant(1.0,shape=[1]),name="v1")
v2 = tf.Variable(tf.constant(2.0, shape=[1]) , name="v2")
result = v1+v2
saver = tf.train.Saver()
with tf.Session() as sess :
# 这里不需要初始化变量,变量的值来至于模型
# 加载己经保存的模型,并通过已经保存的模型中变量的值来计算加法。
saver.restore(sess,"/path/to/model/model.ckpt")
print(sess.run(result))
以上代码定义了计算图,然后加载模型将保存的变量值赋值给v1、v2在计算。
如果不希望重复定义计算图可以采用以下方式加载模型
import tensorflow as tf
# 直接加载持久化图
saver = tf.train.import_meta_graph("/path/to/model/model.ckpt/model.ckpt.meta")
with tf.Session() as sess :
saver.restore(sess, "/path/to/model/model.ckpt")
# 通过张量的名称来获取张量。
print(sess.run(tf.get_default_graph().get_tensor_by_name("add:0"))
# 输出[3.]
以上代码通过变量名称来获取值。
3、convert_variables_to_constants 函数
tf.train.Saver 会保存运行 TensorFlow 程序所需要的全部信息,然而有时并不需要 某些信息。比如在测试或者离线预测时,只需要知道如何从神经网络的输入层经过前向传 播计算得到输出层即可,而不需要类似于变量初始化、模型保存等辅助节点的信息。convert_variables_to_constants函数可以将计算图中的变量及其取值通过常量的方式保存。
import tensorflow as tf
from tensorflow.python.framework import graph_util
vl = tf.Variable(tf.constant(1.0, shape=[1]), name="vl")
v2 = tf.Variable(tf.constant(2.0, shape=[1]), name="v2")
result = vl + v2
init_op = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init_op)
# 保存当前计算图的GraphDef部分,
# 只需要这一部分就可以完成从输入层到输出层的计算过程。
graph_def = tf.get_default_graph().as_graph_def()
# 将图中的变量及其取值转化为常量,
# 同时将图中不必要的节点去掉。
# 如果只关心程序中定义的某些计算时,和这些计算无关的节点就没有必要导出并保存了。
# 在下面一行代码中最后一个参数[’add']给出了需要保存的节点名称。
# add节点是上面定义的两个变量相加的操作。注意这里给出的是计算节点的名称,所以没有后面的:0
output_graph_def = graph_util.convert_variables_to_constants(sess, graph_def, ['add'])
# 将导出的模型存入文件。
with tf.gfile.GFile("/path/to/model/combined_model.pb", "wb") as f:
f.write(output_graph_def.SerializeToString())
通过以下方式直接计算结果
import tensorflow as tf
from tensorflow.python.platform import gfile
with tf.Session() as sess:
model_filename = "/path/to/model/combined_model.pb"
# 读取保仔的模型文件,并将文件解析成对应的 GraphDef_Protocol_Buffer。
with gfile.FastGFile(model_filename, "rb") as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
# 将graph_def 中保存的图加载到当前的图中。
# return_elements=["add :0"]给出了返回张量的名称。在保存的时候给出的是计算节点的名称,所以为“add”。
# 在加载的时候给出是张量的名称,所以是“ add : O”。
result = tf.import_graph_def(graph_def, return_elements=["add:0"])
# 输出[3.O]
print(sess.run(result))
4、通过tensorboard查看meta模型文件的Graph
import tensorflow as tf
from tensorflow.python.platform import gfile
graph = tf.get_default_graph()
graphdef = graph.as_graph_def()
_ = tf.train.import_meta_graph("model.ckpt.meta")
summary_write = tf.summary.FileWriter("./" , graph)
# 启用tensorboard
5、通过tensorboard查看pb文件(包括模型结构与变量参数值)的Graph
import tensorflow as tf
from tensorflow.python.platform import gfile
graph = tf.get_default_graph()
graphdef = graph.as_graph_def()
graphdef.ParseFromString(gfile.FastGFile("./log/mtcnn.pb", "rb").read())
_ = tf.import_graph_def(graphdef, name="")
summary_write = tf.summary.FileWriter("./log" , graph)
6、查看pb文件每层节点张量名称
import os, sys
from tensorflow.python.platform import gfile
import tensorflow as tf
def get_all_layernames(pb_file_path):
sess = tf.Session()
with gfile.FastGFile(pb_file_path, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
sess.graph.as_default()
tf.import_graph_def(graph_def, name='')
tensor_name_list = [tensor.name for tensor in tf.get_default_graph().as_graph_def().node]
for tensor_name in tensor_name_list:
print(tensor_name)
7、meta模型文件转PB模型文件
参考convert_variables_to_constants函数
六、卷积神经网络
1、图像识别经典数据集介绍
-
MNIST
下载地址: http://yann.lecun.com/exdb/mnist
MNIST是一个手写数字0~9的数据集,包含6W张图片训练集,1W张图片测试集,每张图片仅包含一个目标数字,且均在正中央。图片均为28x28的灰度图片。
-
CIFAR-10
https://www.cs.toronto.edu/~kriz/ cifar.html
10 个不同种类的 60000 张图,数据集中每一张图片为32X32彩色图片且只包含一个种类的物体。
-
ILSVRC2012
http://www.image-net.org/challenges/LSVRC
1000 个类别的 120 万张图片,其中 每张图片属于且只属于一个类别,图片是从网上爬取的,所以每张图片大小不一致。
2、卷积神经网络介绍
-
全连接神经网络与卷积神经网络结构区别
全连接神经网络:每相邻两层之间的节点都有边相连。
卷积神经网络:相邻两 层之间只有部分节点相连
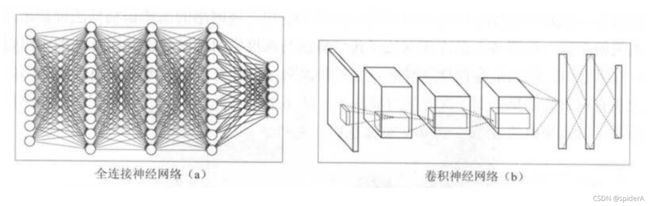
使用全连接神经网络处理图像的最大问题在于全连接层的参数太多。参数增多除了导致计算速度减慢,还很容易导致过拟合问题。
- 卷积神经网络常用结构

卷积层:
过滤器( 卷积核): 将当前层神经网络上的一个子节点矩阵转化为下一层神经网络上的一个单位节点矩阵。
卷积运算:张量A(M,N,C) ,卷积核K(3,3,C),A与K的卷积运算为3X3XC的矩阵在mxnxc矩阵上从左至右从上至下滑动做加权求和,若张量A为某一层网络输出,则C称为节点矩阵深度,3x3XC称为过滤器尺寸,如果有N个卷积核,则N称为过滤器深度(过滤器深度也是下一个输出的节点矩阵深度)
# 通过 tf.get_variable的方式创建过滤器的权重变量和偏置项变量。
# 卷积层的参数只与过滤器尺寸、过滤器深度(过滤器个数)以及当前层节点矩阵的深度有关
# 所以这里声明的参数变量是一个四维矩阵
# 前面两个维度代表了过滤器的尺寸,第三个维度表示当前层节点矩阵深度,第四个维度表示过滤器的深度
filter_weight = tf.get_variable("weights", [5, 5, 3, 16], initializer=tf.truncated_normal_initializer(stddev=0.1))
# 16为过滤器的深度,也是神经网络中下一层节点矩阵的深度。
biases = tf.get_variable("biases", [16], initializer=tf.constant_initializer(0.1))
# tf.nn.conv2d 提供了一个非常方便的函数来实现卷积层前向传播的算法。
# 第一个参数为当前层的节点矩阵。注意这个矩阵是一个四维矩阵,比如在输入层, 如input[0, :, :, :]表示第一张图片
# 第二个参数提供了卷积层的权重,
# 第三个参数为不同维度上的步长。虽然第三个参数提供的是一个长度为4的数组,但是第一维和最后一维的数字要求一定是1。
# 第四个参数是填充(padding)的方法, 其中SAME表示添加全0填充“VALID”表示不添加
conv = tf.nn.conv2d(input, filter_weight, strides=[1,2,2,1], padding="SAME")
# tf.nn.bias_add 提供了一个方便的函数给每一个节点加上偏置项。
# 偏置项有16个数(因为过滤器深度为 16 ),而输出conv(MXN)中每一个元素都需要加上偏置项。
z_out=tf.nn.bias_add(conv, biases)
# 将计算结果通过过 ReLU 激活函数完成非线性化。
y_out = tf.nn.relu(z_out)
池化层(下采样)
池化层主要用于减小矩阵的长和宽,从而减少最后全连 接层中的参数。使用池化层既可以加快计算速度也有防止过拟合问题的作用。
池化层前向传播的过程也是通过移动一个类似过滤器 的结构完成的。不过池化层过滤器中的计算不是节点的加权和,而是采用更加简单的最大值或者平均值运算。使用最大值操作的池化层被称之为最大池化层( max pooling), 这是被 使用得最多的池化层结构。使用平均值操作的池化层被称之为平均池化层( average pooling)。其他池化层在实践中使用的比较少。
卷积层和池化层 中过滤器移动的方式是相似的,唯一的区别在于卷积层使用的过滤器是横跨整个深度的,而池化层使用的过滤器只影响一个深度上的节点。所以池化层的过滤器除了在长和宽两个维度移动,它还需要在深度这个维度移动。
# tf.nn.max_pool 实现了最大池化层的前向传播过程,
# 它的参数和tf.nn.conv2d 函数类似。
# ksize 提供了过滤器的尺(第一维度与最后维度必须是1)、strides 提供了步长信息(第一维度与最后维度必须是1), padding 提供填充方式。
pool = tf.nn.max_pool(y_out, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding="SAME")
-
卷积层/池化层输入与输出矩阵维度关系
输入节点矩阵input(b, i, j, k) 过滤器p个filter(j,k),滑动步长strides=[1,a,b,1],输出矩阵out(b, i, j, k)
padding=“SAME”
o u t i 、 j = i n i 、 j / s t r i d e a 、 b o u t k = p out_{i、j} = in_{i、j}/stride_{a、b} \quad\quad out_{k} = p outi、j=ini、j/stridea、boutk=p
padding=“VALID”
o u t i 、 j = ( i n i 、 j − f i l t e r i 、 j + 1 ) / s t r i d e a 、 b o u t k = p out_{i、j} = (in_{i、j} - filter_{i、j}+1)/stride_{a、b} \quad\quad out_{k} = p outi、j=(ini、j−filteri、j+1)/stridea、boutk=p以上除法向上取整
3、经典卷积神经网络模型
- LeNet-5 模型
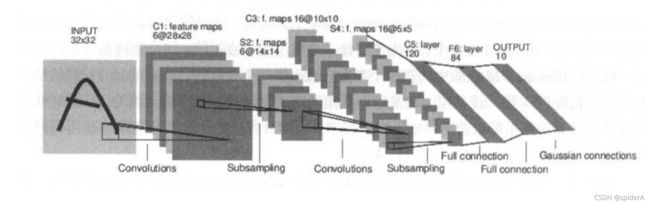
LeNet-5总共7层,后2层为全连接层,前5层为卷积池化层。
卷积神经网络的架构设计原则:
用于图片分类问题的卷积神经网络架构: 输入层→(卷积层+→池化层?)+→全连接层+
“卷积层+”:表示一层或者多层卷积层,大部分卷积神经网络中一般最多连续使用三层卷积层。
“池化层?”:表示没有或者一层池化层。池化层虽然可以起到减少参数防止过拟合问题,但是在部分论文中也发现可以直接通过调整卷积层步长来完成。 所以有些卷积神经网络中没有地化层。
“全连接层+”:卷积神经网络在输出之 前一般会经过 l~2 个全连接层。
-
Inception-v3模型
代替人工确定卷积层中的过滤器类型或者确定是否需要创建卷积层和池化层,即:不需要人为决定使用哪个过滤器,是否需要池化层等,由网络自行决定这些参数,可以给网络添加所有可能值,将输出连接起来,网络自己学习它需要什么样的参数。
在卷积层中使用多个不同尺寸的过滤器(卷积核),与输入节点矩阵进行卷积运算,当每种卷积运算的填充方式为全零填充,且步长相同时,不同尺寸的过滤器与输入节点矩阵卷积运算后具有相同的长宽,最后将多个过滤器运算得到矩阵堆叠到一起组成最终的输出矩阵。
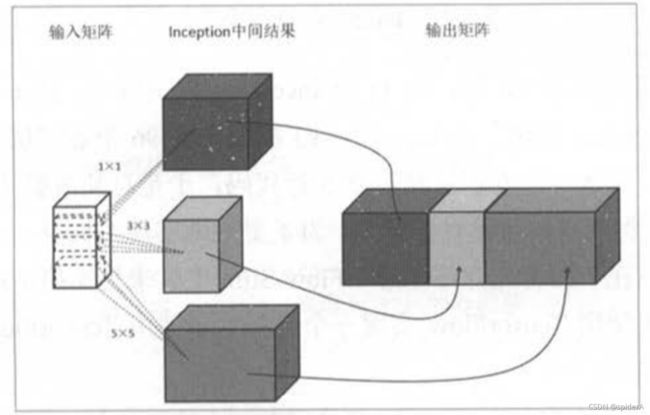
Inception架构的主要思想是找出如何用密集成分来近似最优的局部稀疏结。
1 . 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
2 . 之所以卷积核大小采用1x1、3x3和5x5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定padding = 0、1、2,采用same卷积可以得到相同维度的特征,然后这些特征直接拼接在一起;
-
基于LeNet-5模型的MNIST识别实例
import numpy as np import tensorflow as tf import tensorflow.python.keras.datasets.mnist as mnist from keras.utils import np_utils tf.compat.v1.disable_eager_execution() batch_size = 500 TRAINING_STEPS = 1000 # 定义mnist数据加载初始化 def data_init(): (x_train, y_train), (x_test, y_test) = mnist.load_data("E://python//tensorflow_study//MNIST_data//mnist.npz") x_train = np.reshape(x_train, (60000, 28,28,1)) x_test = np.reshape(x_test, (10000, 28,28,1)) x_train = (x_train - 255) / 255 x_test = (x_test - 255) / 255 # one-hot y_train = np_utils.to_categorical(y_train, 10) y_test = np_utils.to_categorical(y_test, 10) # 5.5W训练集 x_train_np = np.array(x_train[5000:], dtype='float32') # 5.5W训练集对应标签 y_train_np = np.array(y_train[5000:], dtype='float32') # 5K验证集 x_validate_np = np.array(x_train[0:5000], dtype='float32') # 5K验证集对应标签 y_validate_np = np.array(y_train[0:5000], dtype='float32') # 1W测试集 x_test_np = np.array(x_test[:], dtype='float32') # 1W测试集对应标签 y_test_np = np.array(y_test, dtype='float32') return {"x_train": x_train_np, "y_train": y_train_np} \ , {"x_validate": x_validate_np, "y_validate": y_validate_np} \ , {"x_test": x_test_np, "y_test": y_test_np} def getRandomIndex(n, x): # 索引范围为[0, n),随机选x个不重复,注意replace=False不重复 index = np.random.choice(np.arange(n), size=x, replace=False) return index # 随机获取数据 def train_data_batch_set(input_data_feed): index = getRandomIndex(55000, batch_size) return input_data_feed["x_train"][index], input_data_feed["y_train"][index] # 随机获取数据 def validate_data_batch_set(input_data_feed): index = getRandomIndex(5000, batch_size) return input_data_feed["x_validate"][index], input_data_feed["y_validate"][index] # 定义全连接层函数 def add_layer(input, in_size, out_size, active_function): # input 输入矩阵 # in_size 输入矩阵列大小 # out_size 输出矩阵列大小 # active_function 激活函数 weighs = tf.Variable(tf.compat.v1.random_normal([in_size, out_size])) # 定义L2正则化(定义刻画网络复杂度的损失函数,解决过拟合问题) regularizers_L2 = tf.keras.regularizers.l2(0.00005) weighs_loss = regularizers_L2(x=weighs) # 加入集合,losses是集合的名字,第二个参数是要加入这个集合的内容。 tf.compat.v1.add_to_collection('losses', weighs_loss) bais = tf.Variable(tf.compat.v1.random_normal([1, out_size])) # 激励输入 z_i = tf.matmul(input, weighs) + bais return active_function(z_i) # 定义卷积层函数 def add_cnn_layer(input, filter_shape, strides_shape, padding, active_function): # input 输入矩阵(四维张量,(b,i,j,c)) # filter_shape 过滤器参数四位向量 filter_shape[0:1] 过滤器尺寸,filter_shape[2] input矩阵深度(对应C) # filter_shape[3] 过滤器个数 # strides_shape 四维向量,卷积步长第1、4维必须是1 # padding 填充方式,SAME表示添加全0填充“VALID”表示不添加 # active_function 激活函数 filter_weight = tf.Variable(tf.compat.v1.random_normal(filter_shape)) # 定义L2正则化(定义刻画网络复杂度的损失函数,解决过拟合问题) regularizers_L2 = tf.keras.regularizers.l2(0.00005) weighs_loss = regularizers_L2(x=filter_weight) # 加入集合,losses是集合的名字,第二个参数是要加入这个集合的内容。 tf.compat.v1.add_to_collection('losses', weighs_loss) # [filter_shape[3]为过滤器的深度,也是神经网络中下一层节点矩阵的深度。 biases = tf.Variable(tf.compat.v1.random_normal([filter_shape[3]])) # tf.nn.conv2d 提供了一个非常方便的函数来实现卷积层前向传播的算法。 # 第一个参数为当前层的节点矩阵。注意这个矩阵是一个四维矩阵,比如在输入层, 如input[0, :, :, :]表示第一张图片 # 第二个参数提供了卷积层的权重, # 第三个参数为不同维度上的步长。虽然第三个参数提供的是一个长度为4的数组,但是第一维和最后一维的数字要求一定是1。 # 第四个参数是填充(padding)的方法, 其中SAME表示添加全0填充“VALID”表示不添加 conv = tf.nn.conv2d(input, filter_weight, strides=strides_shape, padding=padding) # tf.nn.bias_add 提供了一个方便的函数给每一个节点加上偏置项。 z_out = tf.nn.bias_add(conv, biases) # 将计算结果通过激活函数完成非线性化。 return active_function(z_out) # 定义池化层函数 def add_pool_layer(input, pool_shape, strides_shape, padding): # input 输入矩阵(四维张量,(b,i,j,c)) # pool_shape 池化过滤器参数,四维向量 pool_shape[1:2] 过滤器尺寸 # pool_shape[0]、pool_shape[3] 必须是1 # strides_shape 四维向量,卷积步长第1、4维必须是1 # padding 填充方式,SAME表示添加全0填充“VALID”表示不添加 # tf.nn.max_pool 实现了最大池化层的前向传播过程, # 它的参数和tf.nn.conv2d 函数类似。 # ksize 提供了过滤器的尺(第一维度与最后维度必须是1)、strides 提供了步长信息(第一维度与最后维度必须是1), padding 提供填充方式。 return tf.nn.max_pool(input, ksize=pool_shape, strides=strides_shape, padding=padding) # 定义前向传播 def inference(input_tensor): # 第一层卷积运算 32个边长为5的卷积核,步长为1,全零填充 # 输入(batch_size,28,28,1) # 输出 (batch_size,28,28,32) out_1 = add_cnn_layer(input=input_tensor , filter_shape=[5, 5, 1, 32] , strides_shape=[1, 1, 1, 1] , padding='SAME', active_function=tf.nn.relu6) # 第二层池化运算 边长2,移动步长2 # 输入(batch_size,28,28,32) # 输出 (batch_size,14,14,32) out_2 = add_pool_layer(input=out_1 , pool_shape=[1, 2, 2, 1] , strides_shape=[1, 2, 2, 1] , padding='SAME') # 第三层卷积运算 64个边长为5的卷积核,步长为1,全零填充 # 输入(batch_size,14,14,32) # 输出 (batch_size,14,14,64) out_3 = add_cnn_layer(input=out_2 , filter_shape=[5, 5, 32, 64] , strides_shape=[1, 1, 1, 1] , padding='SAME', active_function=tf.nn.relu6) # 第四层池化运算 边长2,移动步长2 # 输入(batch_size,14,14,64) # 输出 (batch_size,7,7,64) out_4 = add_pool_layer(input=out_3 , pool_shape=[1, 2, 2, 1] , strides_shape=[1, 2, 2, 1] , padding='SAME') # 第五层全连接层 # 该层的输入是一个向量,需要将第四层7x7x64拉直为一维数组 out_4_shape = out_4.get_shape().as_list() # out_4_shape[O]为一个 batch 中数据的个数。 nodes = out_4_shape[1] * out_4_shape[2] * out_4_shape[3] # 通过 tf.reshape 函数将第四层的输出变成一个 batch 的向量。 # reshaped_shape = (None,nodes) reshaped = tf.reshape(out_4, [batch_size, nodes]) # 输入(None,nodes) # 输出 (None,512) out_5 = add_layer(reshaped, nodes, 512, tf.nn.relu6) # 第六层全连接层 # 输入(None,512) # 输出 (None,10) out_6 = add_layer(out_5, 512, 10, tf.nn.relu6) return out_6 # 定义模型训练过程 def train(): global_step = tf.Variable(0) # 第一维表示一个 batch 中样例的个数 # 第二维和第三维表示图片的尺寸。 # 第四维表示图片的深度,对于RBG图片,深度为3。 x = tf.compat.v1.placeholder(tf.float32, [None,28,28,1]) y_ = tf.compat.v1.placeholder(tf.float32, [None, 10]) # 计算当前参数在神经网络上的结果 y = inference(x) # 使用交叉熵作为刻画顶训值和真实值之间差距的损失函数。 # 这里使用了 tf.softmax_cross_entropy_with_logits。 # 这个函数的第一个参数是经网络不包括 softmax 层的前向传播结果, # 第二个是训练数据的正确答案。 eross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=y, labels=y_) # 计算所有当前batch上的所有交叉熵平均值 cross_entropy_mean = tf.reduce_mean(eross_entropy) # 将交叉熵损失函数加入损失集合。 tf.compat.v1.add_to_collection('losses', cross_entropy_mean) # 总损失函数 loss = tf.add_n(tf.compat.v1.get_collection('losses')) # 记录loss tf.compat.v1.summary.scalar("loss", loss) # 初始速率0.9,后面每训练100次后在学习速率基础上乘以0.96 learning_rate = tf.compat.v1.train.exponential_decay(0.99, global_step, 5000, 0.9, staircase=True) # 使用tf.train.GradientDescentOptimizer 优化算法来优化损失函数。 train_step = tf.compat.v1.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step) # 检验。 # tf.argmax(y, 1) 计算每一个样例的预测答案。其中y是一个 batch_size*10 的二维数组, # 每一行表示一个样例的前向传播结果。 # tf.argmax 的第二个参数"l”表示选取最大值的操作仅在第一个维度中进行,也就是说,只在每一行选取最大值对应的下标。 # 于是得到的结果是一个长度为 batch_size 的一维数组,这个一维数组中的值就表示了每一个样例对应的数字识别结果。 # tf.equal 判断两个张量的每一维是否相等,如果相等返回 True,否则返回 False。 correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)) # 这个运算首先将一个布尔型的数值转换为实数型,然后计算平均值。这个平均值就是模型在这一组数据上的正确率。 accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) # 初始化会话并开始训练过程。 init_var = tf.compat.v1.global_variables_initializer() with tf.compat.v1.Session() as sess: sess.run(init_var) # 合并所有的 summary summary_op = tf.compat.v1.summary.merge_all() # 创建 summary_writer summary_writer = tf.compat.v1.summary.FileWriter('tensorboard/', sess.graph) train_feed, validate_feed, test_feed = data_init() for i in range(TRAINING_STEPS): train_batch_x, train_batch_y = train_data_batch_set(train_feed) sess.run(train_step, feed_dict={x: train_batch_x, y_: train_batch_y}) if i % 100 == 0: # loss # 使用一个batch数据获取当前loss值,防止内存不足 loss_val = sess.run(loss, feed_dict={x: train_batch_x, y_: train_batch_y}) # 一般在神经网络的训练过程中会通过验证数据来大致判断停止的条件和评判训练的效果。 # 使用一个batch数据验证当前模型,防止内存不足 # validate_batch_x, validate_batch_y = validate_data_batch_set(validate_feed) # validate_acc = sess.run(accuracy, # feed_dict={x: validate_batch_x, y_: validate_batch_y}) # print("After %d training step(s) , accuracy=%f , loss=%f" % (i, validate_acc, loss_val)) print("After %d training step(s) , loss=%f" % (i, loss_val)) # # 生成summary # summary_str = sess.run(summary_op, feed_dict={x: train_feed["x_train"], y_: train_feed["y_train"]}) # # 写summary # summary_writer.add_summary(summary_str, i) def main(): train() if __name__ == '__main__': main()
4、迁移学习
将已经训练好的模型稍作调整(仅调整后面的全连接层参数),用新的数据集重新训练模型(仅训练后面的全连接层参数)。重新训练后的模型可用于新的数据集上。
全连接层之前的卷积层可看着是一个对数据集特征提取的模型。
新训练后的全连接层看着是对卷积层输出特征的分类模型。
迁移学习的好处是使用少量的样本数据集、有限的硬件计算资源、小的训练时间成本就能够快速得到一个模型。
在数据量足够的情况下,迁移学习的效果不如完全重新训练。
- 基于样本的迁移学习
**1.**通过调整 源Domain的标签(辅助) 和 目标Domain标签的权重,协同训练得到目标模型。
**2.**非专业解释:比如你已经有一个模型,学会了猫 、狗、鸡和鸭的4分类模型,你现在要做另外一个模型区分四条腿的动物和两条腿的动物,那么之前的模型样本是不是可以迁移过来用?
- 基于特征的迁移学习
**1.**找到 “好”特征 来减少源Domain和目标Domain之间的不同,能够降低分类、回归误差。
**2.**非专业解释:比如一个小孩子,被狗咬过,他记住了狗锋利的牙齿,当有一天他来到动物园看到老虎,这种特征是不是很好判断,一下子就被人类迁移过来了,所以他害怕。同样的在我们深度学习模型中也是这样的,比如图像,在imageNet的很多模型中已经学习到了足够多的特征,当某一天我们模型要对图像进行特征判断的时候可以总以前的模型中运用。
- 基于参数的迁移学习
**1.**发现源Domain和目标Domain之间的共享参数或先验关系。
**2.**非专业解释:你们肯定有这样的学习经历,你学习了数学的一元二次方程的求解,某一天你考物理的时候,突然用数学的一元二次方程解答出来。这种就是参数,或者说函数之间的一种共享关系,比如,物理上的匀速运动的速度求解问题,用数学的平均数的知识肯定是可以解答的。我们模型也是一样的,有些具有相关的函数的神经网络也是可以迁移的,但是前提条件很苛刻,需要对模型的网络非常的了解。
5、基于inception-V3迁移学习实例
-
inception-v3模型下载(bp文件)
https://storage.googleapis.com/download.tensorflow.org/models/inception_dec_2015.zip
-
查看inception-v3模型结构
通过tensorboard 查看pb文件的计算图,获取前向传播输入节点与瓶颈层节点名称。
INCEPTION_V3_PB_FILE = 'E://python//tensorflow_study//inception_dec_2015//tensorflow_inception_graph.pb' with tf.compat.v1.Session() as sess: # 读取保仔的模型文件,并将文件解析成对应的 GraphDef_Protocol_Buffer。 with gfile.FastGFile(INCEPTION_V3_PB_FILE, "rb") as f: graph_def = tf.compat.v1.GraphDef() graph_def.ParseFromString(f.read()) _ = tf.import_graph_def(graph_def, name="") summary_writer = tf.compat.v1.summary.FileWriter('tensorboard/', sess.graph)
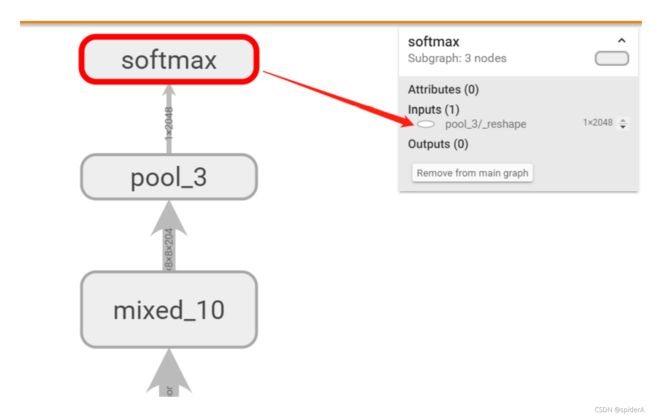
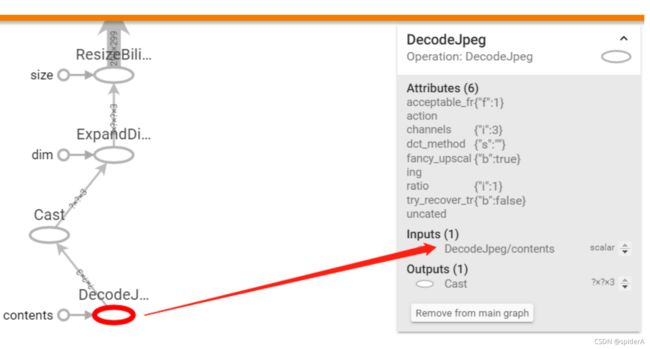
根据图知,inceptionv3 softmax层输入节点为pool_3/_reshape,即瓶颈层输出。图片数据输入节点为DecodeJpeg/contents
-
完整代码
# InceptionV3 模型加载 import tensorflow as tf import numpy as np from tensorflow.python.platform import gfile INCEPTION_V3_PB_FILE = 'E://python//tensorflow_study//inception_dec_2015//tensorflow_inception_graph.pb' class InceptionV3: def __init__(self): # 加载inceptionV3模型 with gfile.FastGFile(INCEPTION_V3_PB_FILE, "rb") as f: graph_def = tf.compat.v1.GraphDef() graph_def.ParseFromString(f.read()) self.bottleneck_tensor, self.jpeg_data_tensor = tf.import_graph_def(graph_def , return_elements=['pool_3/_reshape:0', 'DecodeJpeg/contents:0']) # 特征提取 def inception_feature(self, sess, image_data): # inception-v3 模型 DecodeJpeg/contents:0节点直接输入图片数据 image_feature_data = sess.run(self.bottleneck_tensor, {self.jpeg_data_tensor: image_data}) # 特征向量是四维的,通过squeeze函数压缩成一维的 image_feature_data = np.squeeze(image_feature_data) return image_feature_data# 数据集处理 # 数据集处理 # http://download.tensorflow.org/example_images/flower_photos.tgz import os import numpy as np import tensorflow as tf from tensorflow.python.platform import gfile import inception_v3 as iv3 # imgdata下有5个子文件夹,每一个子文件夹的名称为一种花的名称, # 代表了不同的类别。平均每一种花有 734 张图片, # 每一张图片都是 RGB 色彩模式的,大小也不相同 IMG_FILE = "E:/python/tensorflow_study/flower_photos/imgdata" OUTPUT_FILE = "E:\\python\\tensorflow_study\\flower_photos\\dataset\\dataset_inception_v3_feature_01" flowers = ['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips'] # InceptionV3 模型加载 inceptionV3 = iv3.InceptionV3() # 处理图片数据 def create_image_list(sess): img_names = [] for root, dirs, files in os.walk(IMG_FILE): for file in files: file_name = os.path.join(root, file) file_name = file_name.replace("\\", "/") img_names.append(file_name) print("图片数量%s" % (len(img_names))) # 图片数据 x = [] # 标签,flowers数组下标表示 y = [] # 打乱顺序 state = np.random.get_state() np.random.set_state(state) np.random.shuffle(img_names) state = np.random.get_state() np.random.set_state(state) np.random.shuffle(img_names) state = np.random.get_state() np.random.set_state(state) np.random.shuffle(img_names) i = 0 for img_name in img_names: image_raw_data = gfile.FastGFile(img_name, 'rb').read() feature_data = inceptionV3.inception_feature(sess, image_raw_data) x.append(feature_data) paths = img_name.split("/") flower = paths[len(paths) - 2] i = i + 1 if i % 200 == 0: print(flowers.index(flower)) y.append(flowers.index(flower)) x_np = np.asarray(x).reshape(len(x), 2048) y_np = np.asarray(y).reshape(len(y), 1) return x_np, y_np def main(): with tf.compat.v1.Session() as sess: x, y = create_image_list(sess) print(x.shape) print(y.shape) np.savez(file=OUTPUT_FILE, x=x, y=y) if __name__ == '__main__': main()# 模型训练 import numpy as np import tensorflow as tf from keras.utils import np_utils tf.compat.v1.disable_eager_execution() TRAINING_STEPS = 20000 batch_size = 500 def data_init(): OUTPUT_FILE = "E:\\python\\tensorflow_study\\flower_photos\\dataset\\dataset_inception_v3_feature_01.npz" print("读取数据...") data = np.load(OUTPUT_FILE, allow_pickle=True) print("读取完成") x_data = data['x'] y_data = data['y'] x_data = (x_data - np.min(x_data))/(np.max(x_data) - np.min(x_data)) x_train = x_data # one-hot y_train = np_utils.to_categorical(y_data, 5) return {"x_train": x_train, "y_train": y_train} \ , {"x_validate": [], "y_validate": []} \ , {"x_test": [], "y_test": []} def getRandomIndex(n, x): if x > n: x = n # 索引范围为[0, n),随机选x个不重复,注意replace=False不重复 index = np.random.choice(np.arange(n), size=x, replace=False) return index # 随机获取数据 def data_batch_set(input_data_feed): index = getRandomIndex(3670, batch_size) return input_data_feed["x_train"][index], input_data_feed["y_train"][index] # 定义全连接层函数 def add_layer(input, in_size, out_size, active_function): # input 输入矩阵 # in_size 输入矩阵列大小 # out_size 输出矩阵列大小 # active_function 激活函数 weighs = tf.Variable(tf.compat.v1.random_normal([in_size, out_size])) # 定义L2正则化(定义刻画网络复杂度的损失函数,解决过拟合问题) regularizers_L2 = tf.keras.regularizers.l2(0.000005) weighs_loss = regularizers_L2(x=weighs) # 加入集合,losses是集合的名字,第二个参数是要加入这个集合的内容。 tf.compat.v1.add_to_collection('losses', weighs_loss) bais = tf.Variable(tf.compat.v1.random_normal([1, out_size])) # 激励输入 z_i = tf.matmul(input, weighs) + bais return active_function(z_i) # 定义前向传播 def inference(input): # input 为inceptionV3输出数据batch_sizex2048 # out_1 为batch_sizeX512 out_1 = add_layer(input, 2048, 512, tf.nn.leaky_relu) # out_2 为batch_sizeX5 out_2 = add_layer(out_1, 512, 5, tf.nn.leaky_relu) return out_2 # 定义模型训练过程 def train(): with tf.compat.v1.Session() as sess: global_step = tf.Variable(0, trainable=False) # 第一维表示一个 batch 中样例的个数 # 第二维和第三维表示图片的尺寸。 # 第四维表示图片的深度,对于RBG图片,深度为3。 x = tf.compat.v1.placeholder(tf.float32, [None, 2048]) y_ = tf.compat.v1.placeholder(tf.float32, [None, 5]) # 计算当前参数在神经网络上的结果 y = inference(x) # 使用交叉熵作为刻画顶训值和真实值之间差距的损失函数。 # 这里使用了 tf.softmax_cross_entropy_with_logits。 # 这个函数的第一个参数是经网络不包括 softmax 层的前向传播结果, # 第二个是训练数据的正确答案。 eross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=y, labels=y_) # 计算所有当前batch上的所有交叉熵平均值 cross_entropy_mean = tf.reduce_mean(eross_entropy) # 将交叉熵损失函数加入损失集合。 tf.compat.v1.add_to_collection('losses', cross_entropy_mean) # 总损失函数 loss = tf.add_n(tf.compat.v1.get_collection('losses')) # 记录loss tf.compat.v1.summary.scalar("loss", loss) # 初始速率0.9,后面每训练100次后在学习速率基础上乘以0.96 learning_rate = tf.compat.v1.train.exponential_decay(0.9, global_step, 1000, 0.7, staircase=True) # 使用tf.train.GradientDescentOptimizer 优化算法来优化损失函数。 train_step = tf.compat.v1.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step) # 检验。 # tf.argmax(y, 1) 计算每一个样例的预测答案。其中y是一个 batch_size*10 的二维数组, # 每一行表示一个样例的前向传播结果。 # tf.argmax 的第二个参数"l”表示选取最大值的操作仅在第一个维度中进行,也就是说,只在每一行选取最大值对应的下标。 # 于是得到的结果是一个长度为 batch_size 的一维数组,这个一维数组中的值就表示了每一个样例对应的数字识别结果。 # tf.equal 判断两个张量的每一维是否相等,如果相等返回 True,否则返回 False。 correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)) # 这个运算首先将一个布尔型的数值转换为实数型,然后计算平均值。这个平均值就是模型在这一组数据上的正确率。 accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) # 初始化会话并开始训练过程。 init_var = tf.compat.v1.global_variables_initializer() sess.run(init_var) train_feed, validate_feed, test_feed = data_init() for i in range(TRAINING_STEPS): train_batch_x, train_batch_y = data_batch_set(train_feed) sess.run(train_step, feed_dict={x: train_batch_x, y_: train_batch_y}) if i % 500 == 0: # loss # 使用一个batch数据获取当前loss值,防止内存不足 loss_val = sess.run(loss, feed_dict={x: train_batch_x, y_: train_batch_y}) # 一般在神经网络的训练过程中会通过验证数据来大致判断停止的条件和评判训练的效果。 # 使用一个batch数据验证当前模型,防止内存不足 validate_batch_x, validate_batch_y = data_batch_set(train_feed) validate_acc = sess.run(accuracy, feed_dict={x: validate_batch_x, y_: validate_batch_y}) print("After %d training step(s) , accuracy=%f , loss=%f" % (i, validate_acc, loss_val)) # print("After %d training step(s) , loss=%f" % (i, loss_val)) saver= tf.compat.v1.train.Saver() saver.save(sess,"E:\\python\\tensorflow_study\\model\\model.ckpt") def main(): train() if __name__ == '__main__': main()
# 模型测试 import numpy as np import tensorflow as tf from PIL import Image, ImageDraw, ImageFont import inception_v3 as iv3 from tensorflow.python.platform import gfile tf.compat.v1.disable_eager_execution() IMG_FILE = "img/a.jpg" MODEL_FILE = "E:\\python\\tensorflow_study\\model\\model.ckpt" flowers = ["雏菊", "蒲公英", "玫瑰", "向日葵", "郁金香"] # 图片上写文字 def pic_text(filepath, text): # 打开图片 image = Image.open(filepath) # 新建绘图对象 draw = ImageDraw.Draw(image) draw.text((40, 40), text, font=ImageFont.truetype('C:/windows/fonts/Dengl.ttf', size=50), direction=None) image.show() # InceptionV3 模型加载 inceptionV3 = iv3.InceptionV3() with tf.compat.v1.Session() as sess: # 加载持久化图 saver = tf.compat.v1.train.import_meta_graph(MODEL_FILE + '.meta') # 加载参数 saver.restore(sess, MODEL_FILE) # 通过张量的名称来获取张量。 # 全连接输入层 x = tf.compat.v1.get_default_graph().get_tensor_by_name("Placeholder:0") # 全连接输出层(不包括sofitmax层) y = tf.compat.v1.get_default_graph().get_tensor_by_name("LeakyRelu_1:0") image_raw_data = gfile.FastGFile(IMG_FILE, 'rb').read() img_data_feature = inceptionV3.inception_feature(sess, image_raw_data) # 9.333495 # 0.0 # 9.333495为训练集中最大值,测试时同样需要对数据进行归一化处理 img_data_feature = np.asarray(img_data_feature/9.333495).reshape(1, 2048) result = sess.run(y, feed_dict={x: img_data_feature}) # 将result通过softmax函数转换为概率分布 result = sess.run(tf.argmax(tf.nn.softmax(result),-1)) pic_text(IMG_FILE,flowers[result[0]])

6、图像数据预处理
-
图像编解码
import tensorflow as tf from tensorflow.python.platform import gfile tf.compat.v1.disable_eager_execution() IMG_FILE = "img/a.jpg" with tf.compat.v1.Session() as sess: # 读取图像的原始数据 image_raw_data = gfile.FastGFile(IMG_FILE, 'rb').read() # 解码图片输出张量 tf.image_decode_png 函数对png格式的图像进行解码。 img_data = tf.image.decode_jpeg(image_raw_data) # 张量编码成图片 # 可以得到不口原始图像一样的图像。 encoded_image = tf.image.encode_jpeg(img_data) with gfile.FastGFile("new.jpg","wb") as f: f.write(encoded_image.eval()) -
图像大小调整
# 先将像素值转换为实数[0,1)范围 img_data = tf.image.convert_image_dtype(img_data, dtype=tf.float32) # 图片大小转换为300x300输出张量 # method为转换方式:0-双线性插值;1-最近邻居;2-双三次插值;3-面积插值 resized = tf.image.resize(img_data, [300, 300], method=0) -
图像翻转
# 上下翻转 flipped = tf.image.flip_up_down(img_data) # 左右翻转 flipped = tf.image.flip_left_right(img_data) # 沿对角线翻转 transposed = tf.image.transpose(img_data) -
图像色彩调整
# 亮度整体减少0.5 adjusted = tf.image.adjust_brightness(img_data, -0.5) # 数据限制在0-1之间 adjusted= tf.clip_by_value(adjusted, 0.0, 1.0) # 对比度整体增加少0.5 adjusted = tf.image.adjust_contrast(adjusted, 0.5) # 数据限制在0-1之间 adjusted= tf.clip_by_value(adjusted, 0.0, 1.0) # 饱和度整体增加少0.5 adjusted = tf.image.adjust_saturation(adjusted, 0.5) # 数据限制在0-1之间 adjusted= tf.clip_by_value(adjusted, 0.0, 1.0)
七、TensorFlow计算加速
1、tensorflow使用GPU
-
查看运算设备
import tensorflow as tf tf.compat.v1.disable_eager_execution() # 通过更改配置打印运算运行设备日志 conf = tf.compat.v1.ConfigProto(log_device_placement=True) with tf.compat.v1.Session(config=conf) as sess: a = tf.compat.v1.constant(1) b = tf.compat.v1.constant(2) c = a + b print(sess.run(c))日志如下:
默认 cpu:0
add: (AddV2): /job:localhost/replica:0/task:0/device:CPU:0
Const: (Const): /job:localhost/replica:0/task:0/device:CPU:0
Const_1: (Const): /job:localhost/replica:0/task:0/device:CPU:0
2021-09-18 14:20:24.330583: I tensorflow/core/common_runtime/placer.cc:114] add: (AddV2): /job:localhost/replica:0/task:0/device:CPU:0
2021-09-18 14:20:24.330867: I tensorflow/core/common_runtime/placer.cc:114] Const: (Const): /job:localhost/replica:0/task:0/device:CPU:0
2021-09-18 14:20:24.331179: I tensorflow/core/common_runtime/placer.cc:114] Const_1: (Const): /job:localhost/replica:0/task:0/device:CPU:0
3 -
指定设备运算
import tensorflow as tf tf.compat.v1.disable_eager_execution() # 通过更改配置打印运算运行设备日志 conf = tf.compat.v1.ConfigProto(log_device_placement=True) with tf.compat.v1.Session(config=conf) as sess: # 通过 tf.device 将运算指定到特定的设备上。 with tf.device('/gpu:0'): a = tf.constant(1) b = tf.constant(2) c = a + b print(sess.run(c))
3、并行训练
-
串行训练流程

-
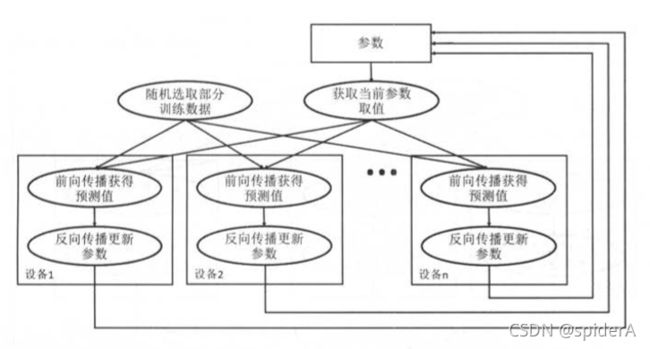
异步并行训练
多个设备在每轮获取当前参数(网络结构参数)无法保证同时获取,即不同设备获取到的参数可能不一致。导致无法到达全局最优解。
-
同步并行训练
解决异步并行训练模式中获取网络参数不一致情况,红色框中的步骤会等待所有设备计算完成后再将参数整合得到最终参数。

理论上异步模式存在缺陷,但因为训练深度学习模型时使用的随机梯度下降本身就是梯度下降的一个近似解法,而且即使是梯度下降也无法保证达到全局最优值, 所以在实际应用中,在相同时间内,使用异步模式训练的模型不一定比同步模式差。所以 这两种训练模式在实践中都有非常广泛的应用。
# 3个GPU并行同步训练方式(未测试,待验证代码正确性)
# 3个GPU并行同步训练方式
import numpy as np
import tensorflow as tf
import tensorflow.python.keras.datasets.mnist as mnist
from keras.utils import np_utils
tf.compat.v1.disable_eager_execution()
batch_size = 500
TRAINING_STEPS = 1000
# GPU数量
N_GPN = 3
# 定义mnist数据加载初始化
def data_init():
(x_train, y_train), (x_test, y_test) = mnist.load_data("E://python//tensorflow_study//MNIST_data//mnist.npz")
x_train = np.reshape(x_train, (60000, 28, 28, 1))
x_test = np.reshape(x_test, (10000, 28, 28, 1))
x_train = (x_train - 255) / 255
x_test = (x_test - 255) / 255
# one-hot
y_train = np_utils.to_categorical(y_train, 10)
y_test = np_utils.to_categorical(y_test, 10)
# 5.5W训练集
x_train_np = np.array(x_train[5000:], dtype='float32')
# 5.5W训练集对应标签
y_train_np = np.array(y_train[5000:], dtype='float32')
# 5K验证集
x_validate_np = np.array(x_train[0:5000], dtype='float32')
# 5K验证集对应标签
y_validate_np = np.array(y_train[0:5000], dtype='float32')
# 1W测试集
x_test_np = np.array(x_test[:], dtype='float32')
# 1W测试集对应标签
y_test_np = np.array(y_test, dtype='float32')
return {"x_train": x_train_np, "y_train": y_train_np} \
, {"x_validate": x_validate_np, "y_validate": y_validate_np} \
, {"x_test": x_test_np, "y_test": y_test_np}
def getRandomIndex(n, x):
# 索引范围为[0, n),随机选x个不重复,注意replace=False不重复
index = np.random.choice(np.arange(n), size=x, replace=False)
return index
# 随机获取数据
def train_data_batch_set(input_data_feed):
index = getRandomIndex(55000, batch_size)
return input_data_feed["x_train"][index], input_data_feed["y_train"][index]
# 随机获取数据
def validate_data_batch_set(input_data_feed):
index = getRandomIndex(5000, batch_size)
return input_data_feed["x_validate"][index], input_data_feed["y_validate"][index]
# 定义全连接层函数
def add_layer(input, in_size, out_size, active_function):
# input 输入矩阵
# in_size 输入矩阵列大小
# out_size 输出矩阵列大小
# active_function 激活函数
weighs = tf.compat.v1.get_variable('f_weighs', shape=[in_size, out_size],
initializer=tf.compat.v1.truncated_normal_initializer())
# 定义L2正则化(定义刻画网络复杂度的损失函数,解决过拟合问题)
regularizers_L2 = tf.keras.regularizers.l2(0.00005)
weighs_loss = regularizers_L2(x=weighs)
# 加入集合,losses是集合的名字,第二个参数是要加入这个集合的内容。
tf.compat.v1.add_to_collection('losses', weighs_loss)
bais = tf.compat.v1.get_variable('f_bais', shape=[1, out_size]
, initializer=tf.compat.v1.truncated_normal_initializer())
# 激励输入
z_i = tf.matmul(input, weighs) + bais
return active_function(z_i)
# 定义卷积层函数
def add_cnn_layer(input, filter_shape, strides_shape, padding, active_function):
# input 输入矩阵(四维张量,(b,i,j,c))
# filter_shape 过滤器参数四位向量 filter_shape[0:1] 过滤器尺寸,filter_shape[2] input矩阵深度(对应C)
# filter_shape[3] 过滤器个数
# strides_shape 四维向量,卷积步长第1、4维必须是1
# padding 填充方式,SAME表示添加全0填充“VALID”表示不添加
# active_function 激活函数
filter_weight = tf.compat.v1.get_variable('filter_weight',
shape=filter_shape,
initializer=tf.compat.v1.truncated_normal_initializer())
# 定义L2正则化(定义刻画网络复杂度的损失函数,解决过拟合问题)
regularizers_L2 = tf.keras.regularizers.l2(0.00005)
weighs_loss = regularizers_L2(x=filter_weight)
# 加入集合,losses是集合的名字,第二个参数是要加入这个集合的内容。
tf.compat.v1.add_to_collection('losses', weighs_loss)
# [filter_shape[3]为过滤器的深度,也是神经网络中下一层节点矩阵的深度。
biases = tf.compat.v1.get_variable('biases'
, shape=[filter_shape[3]]
, initializer=tf.compat.v1.truncated_normal_initializer())
# tf.nn.conv2d 提供了一个非常方便的函数来实现卷积层前向传播的算法。
# 第一个参数为当前层的节点矩阵。注意这个矩阵是一个四维矩阵,比如在输入层, 如input[0, :, :, :]表示第一张图片
# 第二个参数提供了卷积层的权重,
# 第三个参数为不同维度上的步长。虽然第三个参数提供的是一个长度为4的数组,但是第一维和最后一维的数字要求一定是1。
# 第四个参数是填充(padding)的方法, 其中SAME表示添加全0填充“VALID”表示不添加
conv = tf.nn.conv2d(input, filter_weight, strides=strides_shape, padding=padding)
# tf.nn.bias_add 提供了一个方便的函数给每一个节点加上偏置项。
z_out = tf.nn.bias_add(conv, biases)
# 将计算结果通过激活函数完成非线性化。
return active_function(z_out)
# 定义池化层函数
def add_pool_layer(input, pool_shape, strides_shape, padding):
# input 输入矩阵(四维张量,(b,i,j,c))
# pool_shape 池化过滤器参数,四维向量 pool_shape[1:2] 过滤器尺寸
# pool_shape[0]、pool_shape[3] 必须是1
# strides_shape 四维向量,卷积步长第1、4维必须是1
# padding 填充方式,SAME表示添加全0填充“VALID”表示不添加
# tf.nn.max_pool 实现了最大池化层的前向传播过程,
# 它的参数和tf.nn.conv2d 函数类似。
# ksize 提供了过滤器的尺(第一维度与最后维度必须是1)、strides 提供了步长信息(第一维度与最后维度必须是1), padding 提供填充方式。
return tf.nn.max_pool(input, ksize=pool_shape, strides=strides_shape, padding=padding)
# 定义前向传播
def inference(input_tensor, reuse_variables=None):
# 第一层卷积运算 32个边长为5的卷积核,步长为1,全零填充
# 输入(batch_size,28,28,1)
# 输出 (batch_size,28,28,32)
with tf.compat.v1.variable_scope("cnn1", reuse=reuse_variables):
out_1 = add_cnn_layer(input=input_tensor
, filter_shape=[5, 5, 1, 32]
, strides_shape=[1, 1, 1, 1]
, padding='SAME',
active_function=tf.nn.relu6)
# 第二层池化运算 边长2,移动步长2
# 输入(batch_size,28,28,32)
# 输出 (batch_size,14,14,32)
with tf.compat.v1.variable_scope("poo11", reuse=reuse_variables):
out_2 = add_pool_layer(input=out_1
, pool_shape=[1, 2, 2, 1]
, strides_shape=[1, 2, 2, 1]
, padding='SAME')
# 第三层卷积运算 64个边长为5的卷积核,步长为1,全零填充
# 输入(batch_size,14,14,32)
# 输出 (batch_size,14,14,64)
with tf.compat.v1.variable_scope("cnn3", reuse=reuse_variables):
out_3 = add_cnn_layer(input=out_2
, filter_shape=[5, 5, 32, 64]
, strides_shape=[1, 1, 1, 1]
, padding='SAME',
active_function=tf.nn.relu6)
# 第四层池化运算 边长2,移动步长2
# 输入(batch_size,14,14,64)
# 输出 (batch_size,7,7,64)
with tf.compat.v1.variable_scope("poo12", reuse=reuse_variables):
out_4 = add_pool_layer(input=out_3
, pool_shape=[1, 2, 2, 1]
, strides_shape=[1, 2, 2, 1]
, padding='SAME')
# 第五层全连接层
# 该层的输入是一个向量,需要将第四层7x7x64拉直为一维数组
out_4_shape = out_4.get_shape().as_list()
# out_4_shape[O]为一个 batch 中数据的个数。
nodes = out_4_shape[1] * out_4_shape[2] * out_4_shape[3]
# 通过 tf.reshape 函数将第四层的输出变成一个 batch 的向量。
# reshaped_shape = (None,nodes)
reshaped = tf.reshape(out_4, [batch_size, nodes])
# 输入(None,nodes)
# 输出 (None,512)
with tf.compat.v1.variable_scope("f1", reuse=reuse_variables):
out_5 = add_layer(reshaped, nodes, 512, tf.nn.relu6)
# 第六层全连接层
# 输入(None,512)
# 输出 (None,10)
with tf.compat.v1.variable_scope("f2", reuse=reuse_variables):
out_6 = add_layer(out_5, 512, 10, tf.nn.relu6)
return out_6
# 计算每一个变量梯度的平均值
def average_gradients(grads):
average_grads = []
# 枚举所有的变量和变量在不同 GPU 上计算得出的梯度。
for grad_and_vars in zip(*grads):
# 计算所有 GPU 上的梯度平均值。
grads = []
for g, _ in grad_and_vars:
expanded_g = tf.expand_dims(g, 0)
grads.append(expanded_g)
grad = tf.concat(grads, 0)
grad = tf.reduce_mean(grad, 0)
v = grad_and_vars[0][1]
grad_and_var = (grad, v)
# 将变盐和它的平均梯度对应起来。
average_grads.append(grad_and_var)
# 返问所有变茧的平均梯度,这个将被用于变量的更新。
return average_grads
# 定义模型训练过程
def train():
# 简单运算放在cpu上
with tf.Graph().as_default(), tf.device('/cpu:0'):
global_step = tf.Variable(0, trainable=False)
# 第一维表示一个 batch 中样例的个数
# 第二维和第三维表示图片的尺寸。
# 第四维表示图片的深度,对于RBG图片,深度为3。
x = tf.compat.v1.placeholder(tf.float32, [None, 28, 28, 1])
y_ = tf.compat.v1.placeholder(tf.float32, [None, 10])
# 初始速率0.9,后面每训练100次后在学习速率基础上乘以0.96
learning_rate = tf.compat.v1.train.exponential_decay(0.99, global_step, 5000, 0.9, staircase=True)
# 使用tf.train.GradientDescentOptimizer 优化算法来优化损失函数。
train_step = tf.compat.v1.train.GradientDescentOptimizer(learning_rate)
# 存储所有GPU上计算出的梯度
all_grads = []
# 存储所有GPU上计算出的loss
all_loss = []
reuse_variables = False
# 复杂运算放到多个GPU上并行计算
for i in range(N_GPN):
# 指定一个GPU
with tf.device('/gpu:%d' % i):
# 不同GPU使用不同命名空间
scope_name = 'gpu_%d' % i
with tf.name_scope(scope_name):
with tf.compat.v1.variable_scope(tf.compat.v1.get_variable_scope(), reuse=reuse_variables):
# 计算当前参数在神经网络上的结果
y = inference(x, reuse_variables)
# 使用交叉熵作为刻画顶训值和真实值之间差距的损失函数。
# 这里使用了 tf.softmax_cross_entropy_with_logits。
# 这个函数的第一个参数是经网络不包括 softmax 层的前向传播结果,
# 第二个是训练数据的正确答案。
eross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=y, labels=y_)
# 计算所有当前batch上的所有交叉熵平均值
cross_entropy_mean = tf.reduce_mean(eross_entropy)
# 将交叉熵损失函数加入损失集合。
tf.compat.v1.add_to_collection('losses', cross_entropy_mean)
# 总损失函数
loss = tf.add_n(tf.compat.v1.get_collection('losses', scope_name))
# 计算当前GPU上计算出的梯度
grads = train_step.compute_gradients(loss=loss)
all_grads.append(grads)
all_loss.append(loss)
# 在第一次声明变量之后,将控制变量重用的参数设置为 True,这样可以让不同的 GPU 更新同一组参数。
reuse_variables = True
# 计算平均梯度
average_grads = average_gradients(all_grads)
# 使用平均梯度更新参数
apply_gradient_op = train_step.apply_gradients(grads_and_vars=average_grads, global_step=global_step)
# 取所有GPU上loss的均值
average_loss = tf.reduce_mean(all_loss)
tf.compat.v1.summary.scalar("average_loss", average_loss)
# 初始化会话并开始训练过程。
init_var = tf.compat.v1.global_variables_initializer()
# 通过更改配置打印运算运行设备日志
conf = tf.compat.v1.ConfigProto(log_device_placement=True)
with tf.compat.v1.Session(config=conf) as sess:
summary_writer = tf.compat.v1.summary.FileWriter('tensorboard/', sess.graph)
sess.run(init_var)
# 创建 summary_writer
summary_writer = tf.compat.v1.summary.FileWriter('tensorboard/', sess.graph)
# 合并所有的 summary
summary_op = tf.compat.v1.summary.merge_all()
train_feed, validate_feed, test_feed = data_init()
for i in range(TRAINING_STEPS):
train_batch_x, train_batch_y = train_data_batch_set(train_feed)
sess.run(apply_gradient_op, feed_dict={x: train_batch_x, y_: train_batch_y})
if i % 100 == 0:
# loss
# 使用一个batch数据获取当前loss值,防止内存不足
loss_val = sess.run(average_loss, feed_dict={x: train_batch_x, y_: train_batch_y})
print("After %d training step(s) , loss=%f" % (i, loss_val))
# # 生成summary
# summary_str = sess.run(summary_op, feed_dict={x: train_feed["x_train"], y_: train_feed["y_train"]})
# # 写summary
# summary_writer.add_summary(summary_str, i)
def main():
train()
if __name__ == '__main__':
main()
4、TensorFlow分布式训练
# 分布式配置文件
# 指定当前服务是参数服务器还是计算服务器 ps/worker
# ps 负责tf变量管理及维护,worker负责前向传播、反向传播
job_name: ps
# 指定参数服务器集群地址
ps_hosts:
- tf_ps_1:2000
# - tf_ps_2:2000
# 指定计算服务器集群地址
worker_hosts:
- tf_worker_1:3000
- tf_worker_2:3000
- tf_worker_3:3000
# 指定当前程序运行的worker
# 表示worker_hosts数组下标
task_id: 0
# 图间分布式异步方式训练
import numpy as np
import tensorflow as tf
import tensorflow.python.keras.datasets.mnist as mnist
import yaml
from keras.utils import np_utils
tf.compat.v1.disable_eager_execution()
# 读取配置文件
conf_file = open(r'cluster.yml',encoding='utf-8')
cluster_data = yaml.load(stream=conf_file)
batch_size = 500
TRAINING_STEPS = 1000
# 定义mnist数据加载初始化
def data_init():
(x_train, y_train), (x_test, y_test) = mnist.load_data("E://python//tensorflow_study//MNIST_data//mnist.npz")
x_train = np.reshape(x_train, (60000, 28, 28, 1))
x_test = np.reshape(x_test, (10000, 28, 28, 1))
x_train = (x_train - 255) / 255
x_test = (x_test - 255) / 255
# one-hot
y_train = np_utils.to_categorical(y_train, 10)
y_test = np_utils.to_categorical(y_test, 10)
# 5.5W训练集
x_train_np = np.array(x_train[5000:], dtype='float32')
# 5.5W训练集对应标签
y_train_np = np.array(y_train[5000:], dtype='float32')
# 5K验证集
x_validate_np = np.array(x_train[0:5000], dtype='float32')
# 5K验证集对应标签
y_validate_np = np.array(y_train[0:5000], dtype='float32')
# 1W测试集
x_test_np = np.array(x_test[:], dtype='float32')
# 1W测试集对应标签
y_test_np = np.array(y_test, dtype='float32')
return {"x_train": x_train_np, "y_train": y_train_np} \
, {"x_validate": x_validate_np, "y_validate": y_validate_np} \
, {"x_test": x_test_np, "y_test": y_test_np}
def getRandomIndex(n, x):
# 索引范围为[0, n),随机选x个不重复,注意replace=False不重复
index = np.random.choice(np.arange(n), size=x, replace=False)
return index
# 随机获取数据
def train_data_batch_set(input_data_feed):
index = getRandomIndex(55000, batch_size)
return input_data_feed["x_train"][index], input_data_feed["y_train"][index]
# 随机获取数据
def validate_data_batch_set(input_data_feed):
index = getRandomIndex(5000, batch_size)
return input_data_feed["x_validate"][index], input_data_feed["y_validate"][index]
# 定义全连接层函数
def add_layer(input, in_size, out_size, active_function):
# input 输入矩阵
# in_size 输入矩阵列大小
# out_size 输出矩阵列大小
# active_function 激活函数
weighs = tf.Variable(tf.compat.v1.random_normal([in_size, out_size]))
# 定义L2正则化(定义刻画网络复杂度的损失函数,解决过拟合问题)
regularizers_L2 = tf.keras.regularizers.l2(0.00005)
weighs_loss = regularizers_L2(x=weighs)
# 加入集合,losses是集合的名字,第二个参数是要加入这个集合的内容。
tf.compat.v1.add_to_collection('losses', weighs_loss)
bais = tf.Variable(tf.compat.v1.random_normal([1, out_size]))
# 激励输入
z_i = tf.matmul(input, weighs) + bais
return active_function(z_i)
# 定义卷积层函数
def add_cnn_layer(input, filter_shape, strides_shape, padding, active_function):
# input 输入矩阵(四维张量,(b,i,j,c))
# filter_shape 过滤器参数四位向量 filter_shape[0:1] 过滤器尺寸,filter_shape[2] input矩阵深度(对应C)
# filter_shape[3] 过滤器个数
# strides_shape 四维向量,卷积步长第1、4维必须是1
# padding 填充方式,SAME表示添加全0填充“VALID”表示不添加
# active_function 激活函数
filter_weight = tf.Variable(tf.compat.v1.random_normal(filter_shape))
# 定义L2正则化(定义刻画网络复杂度的损失函数,解决过拟合问题)
regularizers_L2 = tf.keras.regularizers.l2(0.00005)
weighs_loss = regularizers_L2(x=filter_weight)
# 加入集合,losses是集合的名字,第二个参数是要加入这个集合的内容。
tf.compat.v1.add_to_collection('losses', weighs_loss)
# [filter_shape[3]为过滤器的深度,也是神经网络中下一层节点矩阵的深度。
biases = tf.Variable(tf.compat.v1.random_normal([filter_shape[3]]))
# tf.nn.conv2d 提供了一个非常方便的函数来实现卷积层前向传播的算法。
# 第一个参数为当前层的节点矩阵。注意这个矩阵是一个四维矩阵,比如在输入层, 如input[0, :, :, :]表示第一张图片
# 第二个参数提供了卷积层的权重,
# 第三个参数为不同维度上的步长。虽然第三个参数提供的是一个长度为4的数组,但是第一维和最后一维的数字要求一定是1。
# 第四个参数是填充(padding)的方法, 其中SAME表示添加全0填充“VALID”表示不添加
conv = tf.nn.conv2d(input, filter_weight, strides=strides_shape, padding=padding)
# tf.nn.bias_add 提供了一个方便的函数给每一个节点加上偏置项。
z_out = tf.nn.bias_add(conv, biases)
# 将计算结果通过激活函数完成非线性化。
return active_function(z_out)
# 定义池化层函数
def add_pool_layer(input, pool_shape, strides_shape, padding):
# input 输入矩阵(四维张量,(b,i,j,c))
# pool_shape 池化过滤器参数,四维向量 pool_shape[1:2] 过滤器尺寸
# pool_shape[0]、pool_shape[3] 必须是1
# strides_shape 四维向量,卷积步长第1、4维必须是1
# padding 填充方式,SAME表示添加全0填充“VALID”表示不添加
# tf.nn.max_pool 实现了最大池化层的前向传播过程,
# 它的参数和tf.nn.conv2d 函数类似。
# ksize 提供了过滤器的尺(第一维度与最后维度必须是1)、strides 提供了步长信息(第一维度与最后维度必须是1), padding 提供填充方式。
return tf.nn.max_pool(input, ksize=pool_shape, strides=strides_shape, padding=padding)
# 定义前向传播
def inference(input_tensor):
# 第一层卷积运算 32个边长为5的卷积核,步长为1,全零填充
# 输入(batch_size,28,28,1)
# 输出 (batch_size,28,28,32)
out_1 = add_cnn_layer(input=input_tensor
, filter_shape=[5, 5, 1, 32]
, strides_shape=[1, 1, 1, 1]
, padding='SAME',
active_function=tf.nn.relu6)
# 第二层池化运算 边长2,移动步长2
# 输入(batch_size,28,28,32)
# 输出 (batch_size,14,14,32)
out_2 = add_pool_layer(input=out_1
, pool_shape=[1, 2, 2, 1]
, strides_shape=[1, 2, 2, 1]
, padding='SAME')
# 第三层卷积运算 64个边长为5的卷积核,步长为1,全零填充
# 输入(batch_size,14,14,32)
# 输出 (batch_size,14,14,64)
out_3 = add_cnn_layer(input=out_2
, filter_shape=[5, 5, 32, 64]
, strides_shape=[1, 1, 1, 1]
, padding='SAME',
active_function=tf.nn.relu6)
# 第四层池化运算 边长2,移动步长2
# 输入(batch_size,14,14,64)
# 输出 (batch_size,7,7,64)
out_4 = add_pool_layer(input=out_3
, pool_shape=[1, 2, 2, 1]
, strides_shape=[1, 2, 2, 1]
, padding='SAME')
# 第五层全连接层
# 该层的输入是一个向量,需要将第四层7x7x64拉直为一维数组
out_4_shape = out_4.get_shape().as_list()
# out_4_shape[O]为一个 batch 中数据的个数。
nodes = out_4_shape[1] * out_4_shape[2] * out_4_shape[3]
# 通过 tf.reshape 函数将第四层的输出变成一个 batch 的向量。
# reshaped_shape = (None,nodes)
reshaped = tf.reshape(out_4, [batch_size, nodes])
# 输入(None,nodes)
# 输出 (None,512)
out_5 = add_layer(reshaped, nodes, 512, tf.nn.relu6)
# 第六层全连接层
# 输入(None,512)
# 输出 (None,10)
out_6 = add_layer(out_5, 512, 10, tf.nn.relu6)
return out_6
# 定义模型训练过程
def train():
ps_hosts = cluster_data["ps_hosts"]
worker_hosts = cluster_data["worker_hosts"]
job_name = cluster_data["job_name"]
task_id = cluster_data["task_id"]
# 通过tf.train.ClusterSpec配置TensorFlow集群
cluster = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts})
# 创建server
server = tf.compat.v1.train.Server(cluster, job_name=job_name, task_index=task_id)
# 如果是参数服务则停在这里
if job_name == 'ps':
with tf.device("/cpu:0"):
server.join()
# 计算服务器
# replica_device_setter函数会自动将参数分配到参数服务器上,计算相关分配到计算服务器上
device_setter = tf.compat.v1.train.replica_device_setter(worker_device="/job:worker/task:%d" % task_id,
cluster=cluster)
with tf.device(device_setter):
global_step = tf.Variable(0, trainable=False)
# 第一维表示一个 batch 中样例的个数
# 第二维和第三维表示图片的尺寸。
# 第四维表示图片的深度,对于RBG图片,深度为3。
x = tf.compat.v1.placeholder(tf.float32, [None, 28, 28, 1])
y_ = tf.compat.v1.placeholder(tf.float32, [None, 10])
# 计算当前参数在神经网络上的结果
y = inference(x)
# 使用交叉熵作为刻画顶训值和真实值之间差距的损失函数。
# 这里使用了 tf.softmax_cross_entropy_with_logits。
# 这个函数的第一个参数是经网络不包括 softmax 层的前向传播结果,
# 第二个是训练数据的正确答案。
eross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=y, labels=y_)
# 计算所有当前batch上的所有交叉熵平均值
cross_entropy_mean = tf.reduce_mean(eross_entropy)
# 将交叉熵损失函数加入损失集合。
tf.compat.v1.add_to_collection('losses', cross_entropy_mean)
# 总损失函数
loss = tf.add_n(tf.compat.v1.get_collection('losses'))
# 记录loss
tf.compat.v1.summary.scalar("loss", loss)
# 初始速率0.9,后面每训练100次后在学习速率基础上乘以0.96
learning_rate = tf.compat.v1.train.exponential_decay(0.99, global_step, 5000, 0.9, staircase=True)
# 使用tf.train.GradientDescentOptimizer 优化算法来优化损失函数。
train_step = tf.compat.v1.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
# 检验。
# tf.argmax(y, 1) 计算每一个样例的预测答案。其中y是一个 batch_size*10 的二维数组,
# 每一行表示一个样例的前向传播结果。
# tf.argmax 的第二个参数"l”表示选取最大值的操作仅在第一个维度中进行,也就是说,只在每一行选取最大值对应的下标。
# 于是得到的结果是一个长度为 batch_size 的一维数组,这个一维数组中的值就表示了每一个样例对应的数字识别结果。
# tf.equal 判断两个张量的每一维是否相等,如果相等返回 True,否则返回 False。
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
# 这个运算首先将一个布尔型的数值转换为实数型,然后计算平均值。这个平均值就是模型在这一组数据上的正确率。
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# StopAtStepHook 会帮忙判断是否需要退出
hooks = [tf.compat.v1.train.StopAtStepHook(last_step=TRAINING_STEPS)]
sess_config = tf.compat.v1.ConfigProto(allow_soft_placement=True, log_device_placement=False)
# 通过 MonitoredTrainingSession 管理训练深度学习模型的通用功能。
with tf.compat.v1.train.MonitoredTrainingSession(master=server.target
# 指定task_id==0为主任务,用于负责变量初始化、做checkpoint、保存summary和复原
, is_chief=(task_id == 0)
, summary_dir='tensorboard/'
, checkpoint_dir='E:\\python\\tensorflow_study\\model_01\\model.ckpt'
, save_checkpoint_secs=60
, config=sess_config
, hooks=hooks) as sess:
# 初始化会话并开始训练过程。
init_var = tf.compat.v1.global_variables_initializer()
sess.run(init_var)
train_feed, validate_feed, test_feed = data_init()
i = 0
while not sess.should_stop():
i = i + 1
train_batch_x, train_batch_y = train_data_batch_set(train_feed)
sess.run(train_step, feed_dict={x: train_batch_x, y_: train_batch_y})
if i % 100 == 0:
# loss
# 使用一个batch数据获取当前loss值,防止内存不足
loss_val = sess.run(loss, feed_dict={x: train_batch_x, y_: train_batch_y})
# 一般在神经网络的训练过程中会通过验证数据来大致判断停止的条件和评判训练的效果。
# 使用一个batch数据验证当前模型,防止内存不足
validate_batch_x, validate_batch_y = validate_data_batch_set(validate_feed)
validate_acc = sess.run(accuracy,
feed_dict={x: validate_batch_x, y_: validate_batch_y})
print("After %d training step(s) , accuracy=%f , loss=%f" % (i, validate_acc, loss_val))
def main():
train()
if __name__ == '__main__':
main()