联邦学习笔记(五):联邦学习模型压缩提升通讯效率
联邦学习模型压缩
- 联邦学习流程
-
- 数据处理
- 模型构造
- 模型压缩函数
- 模型广播和聚合函数
- 模型训练
- 其他函数
- 结果
-
- 模型准确率和loss值
-
- 模型准确率
- 模型loss值
- 联邦学习传输数据量
-
- 广播时需要传输的数据量
- 聚合时需要传输的数据量
- 实验总结
写在前面: 该联邦学习系列博客,均来自于google官方文档的整理和理解。个人能力有限,错误之处请指出。先看该系列博客,再看官方文档会更轻松一点。如果有英文阅读能力可以直接快进到官方文档。 联邦学习流程
在实验之前,首先要安装好联邦学习的环境。具体教程在该系列博客的第一期中应当有介绍。实验采emnist中的数字数据集进行分类实验,分别评估模型不压缩时联邦学习的效果,和模型压缩时联邦学习的效果。
- 导入相应的包
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
import nest_asyncio
import tensorflow as tf
import tensorflow_federated as tff
import functools
import time
import numpy as np
import matplotlib.pyplot as plt
from tensorflow_model_optimization.python.core.internal import tensor_encoding as te
nest_asyncio.apply()
数据处理
实验使用的是emnist数据集中的数字图片,以CNN神经网络模型做分类任务。因此需要将该图片处理成能够被CNN网络接受的形状。由于TFF使用的是函数式编程,官方文档说可以将TFF当作一门具有强粘合性的函数式编程语言进行学习。该数据集是灰度图片,没有通道维
- 数据展平
- 数据集打乱,切分等
代码:
def reshape_emnist_element(element):
return (tf.expand_dims(element['pixels'], axis=-1), element['label'])
def preprocess_train_dataset(dataset):
"""Preprocessing function for the EMNIST training dataset."""
return (dataset
# Shuffle according to the largest client dataset
.shuffle(buffer_size=MAX_CLIENT_DATASET_SIZE)
# Repeat to do multiple local epochs
.repeat(CLIENT_EPOCHS_PER_ROUND)
# Batch to a fixed client batch size
.batch(CLIENT_BATCH_SIZE, drop_remainder=False)
# Preprocessing step
.map(reshape_emnist_element))
加载数据集
MAX_CLIENT_DATASET_SIZE = 418
CLIENT_EPOCHS_PER_ROUND = 1
CLIENT_BATCH_SIZE = 20
TEST_BATCH_SIZE = 500
emnist_train, emnist_test = tff.simulation.datasets.emnist.load_data(only_digits=True)
#数据集处理
emnist_train = emnist_train.preprocess(preprocess_train_dataset)
模型构造
本实验使用的是CNN神经网络模型进行训练,由于在联邦学习训练过程中,神经网络模型随着服务器广播到客户端和客户端向服务端聚合,会发生改变。所以在联邦学习中使用的神经网络模型不能是一个对象,而应该是一个神经网络构造器。总结: 在TFF中不能使用网络模型对象进行训练,应当调用的是其构造函数。
使用TF代码构造神经网络模型:
def create_original_fedavg_cnn_model(only_digits=True):
"""The CNN model used in https://arxiv.org/abs/1602.05629."""
data_format = 'channels_last'
max_pool = functools.partial(
tf.keras.layers.MaxPooling2D,
pool_size=(2, 2),
padding='same',
data_format=data_format)
conv2d = functools.partial(
tf.keras.layers.Conv2D,
kernel_size=5,
padding='same',
data_format=data_format,
activation=tf.nn.relu)
model = tf.keras.models.Sequential([
tf.keras.layers.InputLayer(input_shape=(28, 28, 1)),
conv2d(filters=32),
max_pool(),
conv2d(filters=64),
max_pool(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation=tf.nn.relu),
tf.keras.layers.Dense(10 if only_digits else 62),
tf.keras.layers.Softmax(),
])
return model
使用tff.learning.from_keras_model函数构造TFF神经网络模型。创建TFF神经网络模型的构造函数。
def tff_model_fn():
keras_model = create_original_fedavg_cnn_model()
return tff.learning.from_keras_model(
keras_model=keras_model,
#此处为数据集一个batch的数据类型和形状
input_spec=input_spec,
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()])
获取上面代码注释中的input_spec以便使用
input_spec = emnist_train.create_tf_dataset_for_client(emnist_train.client_ids[0]).element_spec
模型压缩函数
在实验中,针对的是每个模型中的数值进行有选择地进行压缩。如果模型中的数值大于1000,则针对该模型进行均匀量化编码压缩,否则不进行压缩(此处存疑:文档中说的是应用恒等式,应该就是不进行压缩差不多的意思)。
在训练过程中,服务端向客户端广播模型参数与客户端向服务端上传模型参数都使用的上述同一套压缩策略。
- 服务端向客户端广播模型参数时,应用的压缩函数
#value表示针对模型参数中的每个值进行处理
def broadcast_encoder_fn(value):
"""Function for building encoded broadcast."""
spec = tf.TensorSpec(value.shape, value.dtype)
if value.shape.num_elements() > 10000:
#均匀量化压缩
return te.encoders.as_simple_encoder(
te.encoders.uniform_quantization(bits=8), spec)
else:
#应用恒等式
return te.encoders.as_simple_encoder(te.encoders.identity(), spec)
- 客户端向服务端上传模型参数时,使用的压缩函数
def mean_encoder_fn(value):
"""Function for building encoded mean."""
spec = tf.TensorSpec(value.shape, value.dtype)
if value.shape.num_elements() > 10000:
return te.encoders.as_gather_encoder(
te.encoders.uniform_quantization(bits=8), spec)
else:
return te.encoders.as_gather_encoder(te.encoders.identity(), spec)
模型广播和聚合函数
在联邦平均算法中有两个可选参数,broadcast_process和aggregation_process。在广播和聚合前对模型进行压缩对应这两个参数,因此先创建广播时的压缩处理函数和聚合时的压缩处理函数。通过调用tff.learning.framework.build_encoded_broadcast_process_from_model和tff.learning.framework.build_encoded_mean_process_from_model两个API进行创建。
- 广播压缩处理函数
encoded_broadcast_process = (
tff.learning.framework.build_encoded_broadcast_process_from_model(
tff_model_fn, broadcast_encoder_fn))
- 聚合压缩处理函数
encoded_mean_process = (
tff.learning.framework.build_encoded_mean_process_from_model(
tff_model_fn, mean_encoder_fn))
- 创建联邦平均聚合算法
federated_averaging_with_compression = tff.learning.build_federated_averaging_process(
tff_model_fn,
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(learning_rate=0.02),
server_optimizer_fn=lambda: tf.keras.optimizers.SGD(learning_rate=1.0),
broadcast_process=encoded_broadcast_process,
aggregation_process=encoded_mean_process)
模型训练
在进行训练时,要使用到的参数有:
- 联邦聚合算法策略(也就是上面的federated_averaging_with_compression)
- 全局聚合次数(num_rounds)
- 客户端本地训练次数(开头数据处理中的repeat中的数值)。
- 模型训练时,有多少个客户端参与训练。(本实验每次都是选择10个客户端进行训练)
训练函数代码
def train(federated_averaging_process, num_rounds, num_clients_per_round, summary_writer):
"""Trains the federated averaging process and output metrics."""
# Create a environment to get communication cost.
environment = set_sizing_environment()
# Initialize the Federated Averaging algorithm to get the initial server state.
state = federated_averaging_process.initialize()
with summary_writer.as_default():
for round_num in range(num_rounds):
# Sample the clients parcitipated in this round.
sampled_clients = np.random.choice(
emnist_train.client_ids,
size=num_clients_per_round,
replace=False)
# Create a list of `tf.Dataset` instances from the data of sampled clients.
sampled_train_data = [
emnist_train.create_tf_dataset_for_client(client)
for client in sampled_clients
]
# Round one round of the algorithm based on the server state and client data
# and output the new state and metrics.
state, metrics = federated_averaging_process.next(state, sampled_train_data)
# For more about size_info, please see https://www.tensorflow.org/federated/api_docs/python/tff/framework/SizeInfo
size_info = environment.get_size_info()
broadcasted_bits = size_info.broadcast_bits[-1]
aggregated_bits = size_info.aggregate_bits[-1]
print('round {:2d}, metrics={}, broadcasted_bits={}, aggregated_bits={}'.format(round_num, metrics, format_size(broadcasted_bits), format_size(aggregated_bits)))
# Add metrics to Tensorboard.
for name, value in metrics['train'].items():
tf.summary.scalar(name, value, step=round_num)
# Add broadcasted and aggregated data size to Tensorboard.
tf.summary.scalar('cumulative_broadcasted_bits', broadcasted_bits, step=round_num)
tf.summary.scalar('cumulative_aggregated_bits', aggregated_bits, step=round_num)
summary_writer.flush()
在上述代码中有sizi相关的代码,该代码不是关键,只是在最后结果展示时显得简洁一点。该相关代码在下面一小节中。
其他函数
数据量简化显示代码,在神经网络模型中代码随着训练过程的进行,需要传输的数据量会越来越大,为了简化显示才有了下述代码。
def format_size(size):
"""A helper function for creating a human-readable size."""
size = float(size)
for unit in ['bit','Kibit','Mibit','Gibit']:
if size < 1024.0:
return "{size:3.2f}{unit}".format(size=size, unit=unit)
size /= 1024.0
return "{size:.2f}{unit}".format(size=size, unit='TiB')
def set_sizing_environment():
"""Creates an environment that contains sizing information."""
# Creates a sizing executor factory to output communication cost
# after the training finishes. Note that sizing executor only provides an
# estimate (not exact) of communication cost, and doesn't capture cases like
# compression of over-the-wire representations. However, it's perfect for
# demonstrating the effect of compression in this tutorial.
sizing_factory = tff.framework.sizing_executor_factory()
# TFF has a modular runtime you can configure yourself for various
# environments and purposes, and this example just shows how to configure one
# part of it to report the size of things.
context = tff.framework.ExecutionContext(executor_fn=sizing_factory)
tff.framework.set_default_context(context)
return sizing_factory
结果
将原始不进行模型压缩的联邦平均算法和进行模型压缩的联邦平均算法进行对比。分别对比以下几点:
- 模型准确率
- 模型loss值
- 模型广播时传输数据量大小
- 模型聚合时传输数据量的大小
模型准确率和loss值
模型准确率

模型loss值

联邦学习传输数据量
广播时需要传输的数据量
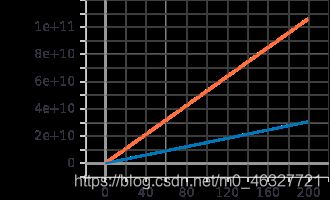
聚合时需要传输的数据量

实验总结
模型压缩后能够达到与不压缩几乎一样的效果,同时需要传输的数据量也大幅度的减小。有效提高了通信效率。实验似乎没有计算模型在测试集上的准确率和loss值。准确率在200之后貌似开始达到瓶颈,无法再进一步,这可能是由于算法本身限制的。由于没有服务器,没办法跑个几千次。