Decomposed Meta-Learning for Few-Shot Named Entity Recognition
原文链接:
https://aclanthology.org/2022.findings-acl.124.pdf
ACL 2022
介绍
问题
目前基于span的跨度量学习(metric learning)的方法存在一些问题:
1)由于是通过枚举来生成span,因此在解码的时候需要额外处理重叠的span;
2)non-entites类别的原型通常都是噪声;
3)跨域时,最有用的信息就是当前领域有限的样本,之前的方法只将这些样本用于分类的相似性计算。
IDEA
作者提出分解元学习(decomposed meta-learning)的方法来解决Few-shot ner任务(实体的边界检测和实体的分类)。
将span检测作为序列标注问题,并通过引入MAML(model-agnostic metalearning 不是很懂 可以参考这篇文章Model-Agnostic Meta-Learning (MAML)模型介绍及算法详解 - 知乎)训练span detector,从而找到一个能快速适应新实体类别的模型参数进行初始化;对于实体分类,作者提出MAML-ProtoNet来找到一个合适的向量空间对不同类别的span进行分类。
方法
整个方法的整体结构如下所示:

Entity span Detection
span detection模型用于定位输入句子中的实体,该模块是类别无关的,学到的只是实体的边界信息(即领域不变的内部特征,而不是特定的领域信息),因此就能跨域进行实体定位。
Basci Detector
作者使用BIOES标注框架,给定一个有L个token的序列![]() ,使用encoder
,使用encoder ![]() 来获得所有token的上下文表征,对于每个token 使用一个线性分类层来计算其是否是实体的一部分;
来获得所有token的上下文表征,对于每个token 使用一个线性分类层来计算其是否是实体的一部分;


模型的损失如下所示:

使用每个token的交叉熵损失,这里引入最大值是为了缓解损失相对较高的token导致的学习不充分问题。推理阶段,通过Viterbi算法进行解码。
Meta-Learning Procedure
在该阶段,作者对边界检测模型![]() 进行训练。
进行训练。
首先,从train数据集中进行随机采样得到![]() ,对模型执行inner-update:
,对模型执行inner-update:

其中![]() 表示在学习率为α时n步的梯度更新,来最小化loss(公式3)。
表示在学习率为α时n步的梯度更新,来最小化loss(公式3)。
然后在query set中对更新后的模型进行评估,同时通过汇总多个时间来执行meta-update:

上式中的二阶导数,使用其一阶近似值进行估算:
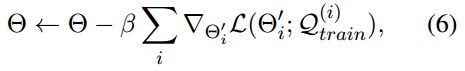
meta-test阶段,首先将在support set上训练好的span detection迁移到新领域,然后对query样本进行相应的预测。
Entity Typing
Basic Model: ProtoNet
给定输入序列L:![]() ,用公式1的方法计算word embedding hi,并按以下方式计算span的表征:
,用公式1的方法计算word embedding hi,并按以下方式计算span的表征:

对于每个类别yk,使用这个support set中属于该类别的所有span来计算原型ck:
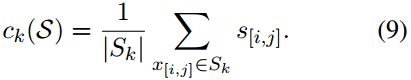
训练过程中,首先使用support set中的训练数据计算所有类别的原型,然后对于query set中的每个span,通过计算其表征与每个类别原型ck的距离来得到属于每个类别的分数:
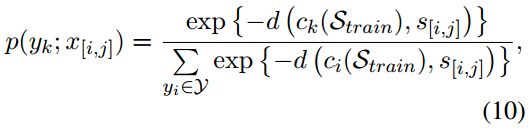
最小化分类的交叉熵损失来训练原型网络:

推理阶段,首先利用训练好的模型计算所有训练集![]() 中所有类别的原型,然后使用边界检测模型得到span,按照公式10为每个span进行分类:
中所有类别的原型,然后使用边界检测模型得到span,按照公式10为每个span进行分类:

MAML Enhanced ProtoNet
在训练集中进行随机采样,得到![]() 。对于inner-update,首先为每个类别计算原型,然后将每个span作为query对模型参数进行更新:
。对于inner-update,首先为每个类别计算原型,然后将每个span作为query对模型参数进行更新:
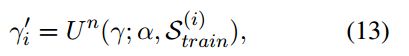
在meta-update阶段,使用![]() 重新计算每个类别的原型,即在query set上对r进行验证,同样的使用一阶导数近似值提高计算效率:
重新计算每个类别的原型,即在query set上对r进行验证,同样的使用一阶导数近似值提高计算效率:
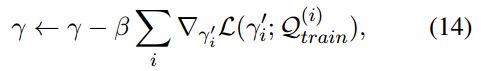
训练过程中没有见过的数据![]() ,首先利用support中的样本来对meta-learned的模型进行微调,微调好后再计算每个类别的原型,最后基于这些原型进行分类。
,首先利用support中的样本来对meta-learned的模型进行微调,微调好后再计算每个类别的原型,最后基于这些原型进行分类。
实验
对比实验
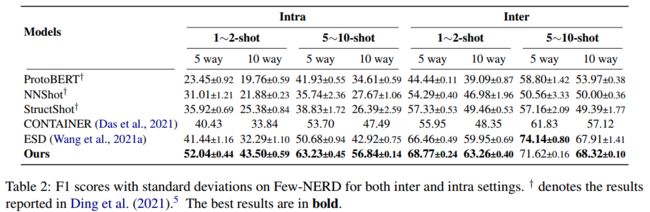
在Intra和Inter这两种数据设置下进行实验,结果如下图所示:
在Cross-Dataset数据集上进行实验,结果如下所示:

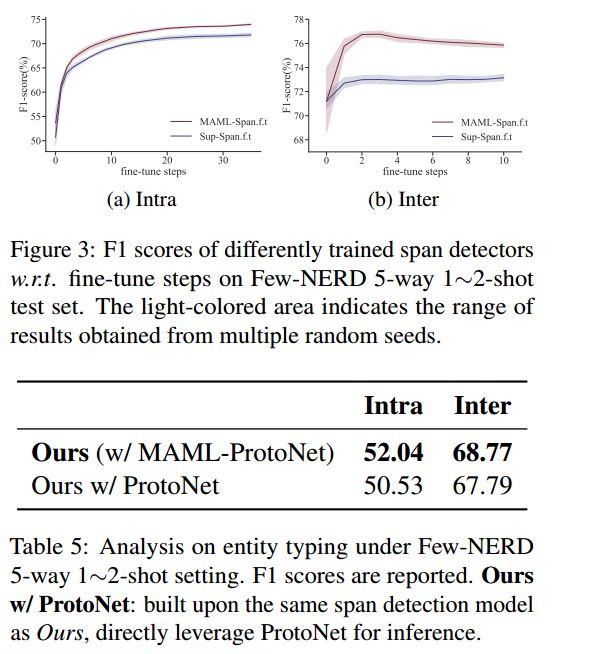
消融实验
对主要模块进行了消融实验,结果如下所示:

其他
对不同类别的span表征进行了可视化:

结论
这篇论文没有很看懂,去看了以下Meta-learning的相关内容也没有很明白,似乎就是meta-learning就是为模型训练出一个更合适的参数,使其能够更快的应用于新领域。上周看的一篇论文感觉跟这篇很像,不过不知道是不是在Few-shot ner中用原型学习的很多,感觉还挺像的。