机器学习项目实战
Titanic 幸存者预测-监督学习分类
- 1.数据准备
- 2.数据加载及处理
-
- 1.加载结构化的训练集
- 2.处理缺失值,异常值
- 3.特征工程
- 4.逻辑回归算法训练模型
- 5.模型性能评估
- 6.模型持久化
-
- 6.1 sklearn 0.21之前
- 6.2 sklearn 0.21之后
1.数据准备
数据集地址:https://www.kaggle.com/c/titanic/data
项目完整代码及数据网盘地址:https://pan.baidu.com/s/1nN3508FF5gWuhatK5j6luQ
提取码:elfu
算法:逻辑回归
技术框架:python3.6.9+numpy1.18.1+pandas1.0.1+sklearn0.22.2+matplotlib2.2.4
2.数据加载及处理
1.加载结构化的训练集
import pandas as pd
data=pd.read_csv("train.csv")
#查看下数据样式
print(data.shape)
print(data.head())
#查看下数据的信息
print(data.info()) #data.describe()
字段信息如下:
PassengerId,乘客的ID
Survived,是否幸存标记0,1survived
Pclass,乘客船票等级1,2,3
Name,乘客姓名
Sex,性别
Age,年龄
SibSp,兄弟姐妹数
Parch,父母孩子数
Ticket,船票信息
Fare,船票价格
Cabin,船舱信息
Embarked,登陆港口
共891个样本,12个维度
各个字段的信息如下:

Age字段有部分缺失值,可以填充这部分缺失值
Cabin缺失值太多,无法处理,直接删除
Embarked有两个缺失值,可以直接删掉这两个样本
PassengerId为乘客的Id,显然对是否幸存无影响,通过相关系数分析或者卡方检验可以得出结果

Name 乘客姓名类似于Id,对预测也无影响,仅是区别乘客
Ticket票据的信息对预测也无影响
2.处理缺失值,异常值
#删除无用的维度
data.drop(["PassengerId","Cabin","Name","Ticket"],axis=1,inplace=True)
#删除Embarked缺失的样本
data=data.loc[data["Embarked"].notnull(),:]
#用均值填充Age字段的缺失值
age=data["Age"]
mean=age.mean() #Series对象自动忽略缺失值
data["Age"]=age.fillna(mean)
#再次看下数据
print(data.info())

此时数据只有889个样本,8个维度,均没有缺失值了,但是还有点问题,就是数据类型不一致,还需要进一步处理。
#选择object数据类型,编码转换,否则无法使用算法建模
df1=data.select_dtypes(include=["object"])
df2=data.select_dtypes(include=["int64","float64"])
print(df1.head())
print(df2.head())

可以看到Sex,Embarked两个字段的数据还不是数值类型,模型还不能使用,所以需要转换,这里采用pandas哑编码
#编码Sex
df_sex=pd.get_dummies(df1["Sex"],prefix="sex")
#编码Embarked
df_embarked=pd.get_dummies(df1["Embarked"],prefix="embarked")
df1=pd.concat([df_sex,df_embarked],axis=1)
print(df1.head())

最后获取总的数值类型的数据帧
df=pd.concat([df1,df2],axis=1).astype("float64")
print(df.head())
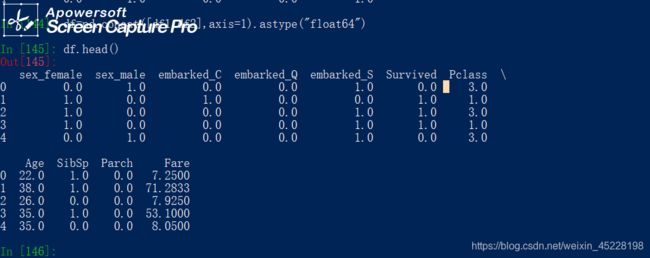
到这里就得到一个数据帧df,889个样本,11个维度,全部为float64类型的数据
通过相关系数分析,这11个维度都与是否幸存相关,如下:

当然也可以通过卡方检验,互信息等分析方法进行分析。
通过简单分析可知基本没有异常值,保留当前所有的样本
3.特征工程
特征工程其实也就是一些特征数据的处理,特征的选择,新特征的构造等,在第二步中也基本处理的差不多了 。这里只简单的归一化数据特征,方便模型算法的快速收敛
#这里使用手动的方式进行归一化,当然使用sklearn的preprocessing 进行归一化更便捷
#获取目标值
y=df.pop("Survived").values
#获取数据值
x=df.values
#训练数据的均值
x_mean=np.mean(x,axis=0)
x_std=np.std(x,axis=0)
x=(x-x_mean)/x_std
这里的归一化使用numpy手动处理,重在理解原理,项目源代码中使用的sklearn库处理,重在便捷
4.逻辑回归算法训练模型
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=3,shuffle=True)
gs=GridSearchCV(LogisticRegression(),[{"C":np.linspace(0.05,1.5,30),"penalty":["l2"],"solver":["lbfgs"]}],cv=10)
gs.fit(x_train,y_train)
#经过网格搜索超参数,得到一个针对当前训练集最优化的逻辑回归模型
estimator=gs.best_estimator_
5.模型性能评估
使用上一步得到的模型,拟合x_train,y_train,查看其学习曲线如下:
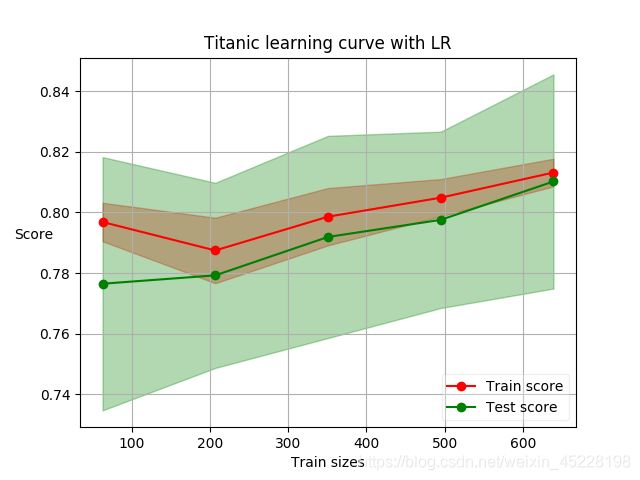
因为是二元分类,还可以看下其ROC曲线,如下:

综上可以看出模型性能还不错,acc,auc 均在0.8,后续就看通过一些特征工程的技巧或者选择其他的算法,还能不能进一步提升模型的性能,也就是模型的优化工作。
6.模型持久化
如果模型的性能满足我们的需求了,那就要把模型固化存储起来,方便上线部署使用。
这里分sklearn的不同版本介绍两种模型持久化的方法
6.1 sklearn 0.21之前
#固化存储之前,模型重新拟合所有数据集,避免数据的浪费
estimator.fit(x,y)
from sklearn.externals import joblib
joblib.dump(estimator,"../model/titanic_lr.pkl")
#但是这种方法在sklearn 0.21及以后的版本已经抛弃了
6.2 sklearn 0.21之后
import joblib
joblib.dump(estimator,"../model/titanic_lr.gz")
好了,整个项目到这里就结束了,下面看看还能不能再优化一下吧。