论文阅读——RoBERTa A Robustly Optimized BERT Pretraining Approach
RoBERTa A Robustly Optimized BERT Pretraining Approach
Abstract
Devlin等人在 BERT Pre-training of Deep Bidirectional Transformers for Language Understanding 提出的BERT预训练研究虽然已达到最优结果,但
- 训练成本比较高,很难彻底得到训练
- 训练的时候通常是在不同大小的私有数据集上进行训练的,很难判断具体哪个部分对结果有促进作用
所以,作者重新衡量了关键参数和数据集大小的影响,并提出了改进BERT的方法,即RoBERTa
1 Introduction
本文贡献:
-
出了一套重要的BERT设计选择和培训策略,并引入了能够提高下游任务绩效的备选方案
-
使用了一个新的数据集,CCNEWS,并确认使用更多的数据进行预训练进一步提高了下游任务的性能
-
训练改进表明,在正确的设计选择下,
masked language model的预训练可以与所有其他最近发表的方法相媲美
2 Background
BERT
预训练有两个目标:
-
Masked Language Model (MLM)
15%
token进行替换,其中80%被替换为[MASK]替换,10%保持不变,10%被随机选择的token替代。 -
Next Sentence Prediction (NSP)
用于预测两句话在原文中是否相邻。正例和负例的采样概率相等。NSP目标旨在提高下游任务的性能
BERT的优化算法中,Adam参数: β 1 = 0.9 , β 2 = 0.999 , ϵ = l e − 6 β_1=0.9,β_2=0.999,\epsilon=le-6 β1=0.9,β2=0.999,ϵ=le−6, L 2 L_2 L2重量衰减0.01
3 Experimental Setup
GPU
数据集介绍
各大榜单介绍
4 Training Procedure Analysis
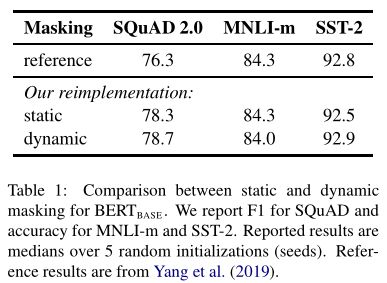
4.1 Static vs. Dynamic Masking
-
静态Masking
对每一个序列随机选择15%的
Tokens替换成[MASK],为了消除与下游任务的不匹配,还对这15%的Tokens进行:(1)80%的时间替换成
[MASK];(2)10%的时间不变;
(3)10%的时间替换成其他词。
但整个训练过程,这15%的
Tokens一旦被选择就不再改变,也就是说从一开始随机选择了这15%的Tokens,之后的N个epoch里都不再改变了。这就叫做静态Masking。 -
动态Masking
一开始把预训练的数据复制10份,每一份都随机选择15%的
Tokens进行Masking,也就是说,同样的一句话有10种不同的mask方式。然后一份数据(同一种mask方式)都被训练了N/10个epoch(同一种mask的数据被训练了N/10次),相当于一共N个epoch,且每个序列被mask的Tokens是会变化的。这就叫做动态Masking。
作者在只将静态Masking改成动态Masking,其他参数不变的情况下做了实验,动态Masking确实能提高性能。
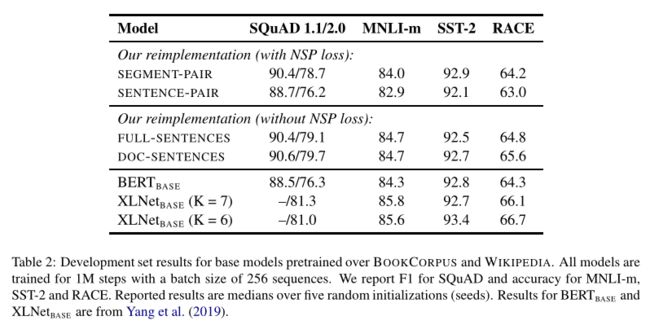
4.2 Model Input Format and Next Sentence Prediction(with NSP and without NSP)
**原始BERT:**为了捕捉句子之间的关系,使用了NSP任务进行预训练,就是输入一对句子A和B,判断这两个句子是否是连续的。在训练的数据中,50%的B是A的下一个句子,50%的B是随机抽取的(假的)。
RoBERTa:去除了NSP,而是每次输入连续的多个句子,直到最大长度512(可以跨文章)。这种训练方式叫做FULL-SENTENCES,而原来的BERT每次只输入两个句子。
作者比较了四种方式:
- SEGMENT-PAIR+NSP:这遵循BERT中使用的原始输入格式,并带有NSP损失。每个输入都有一对段,每个段可以包含多个自然句子,但总组合长度必须小于512个标记。
- SENTENCE-PAIR+NSP:每个输入包含一对自然句子,从一个文档的连续部分或从单独的文档中采样。由于这些输入明显少于512个令牌,我们增加批处理大小,以便令牌的总数保持类似于SEGMENT-PAIR+NSP。我们保留NSP损失。
- FULL-SENTENCES
- DOC-SENTENCES:输入的构造类似于 FULL-SENTENCES,除了它们不能跨越文档边界。在文档末尾附近采样的输入可能小于512个令牌,因此在这些情况下,我们动态地增加批处理大小,以获得与 FULL-SENTENCES 类似的令牌总数。我们消除了NSP损失。
实验表明在MNLI这种推断句子关系的任务上,RoBERTa也能有更好性能。
4.3 Training with large batches
原始的 B E R T b a s e BERT_{base} BERTbase: batch_size=256,训练步数steps=1M。
RoBERTa: batch_size 为 8k。为什么要用更大的batch size呢?作者借鉴了在机器翻译中,用更大的batch size配合更大学习率能提升模型优化速率 和 模型性能 的现象,并且也用实验证明了确实BERT还能用更大的batch_size。

4.4 Text Encoding
Byte-Pair Encoding (BPE):BPE依赖于子词单元,而不是全词,子词单元是通过对训练语料库进行统计分析提取的。**主要通过wordpiece技术将word分解为更为细粒度的片段。RoBERTa采用BPE,获得了超过5w个token(BERT只有3w)。**Radford等人(2019)引入了一个聪明的BPE实现,它使用字节而不是unicode字符作为基本子字单元。使用字节可以学习一个中等大小(50K units)的子单词词汇表(原始BERT使用30k),它仍然可以编码任何输入文本,而不会引入任何“un-known”标记。
5 RoBERTa(实验结果)
借鉴XLNet用了比BERT多10倍的数据,RoBERTa也用了更多的数据,性能确实有所提升,但相应的也需要更长的训练时间。
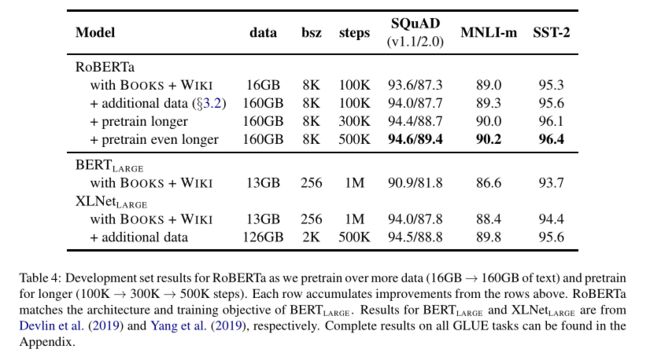
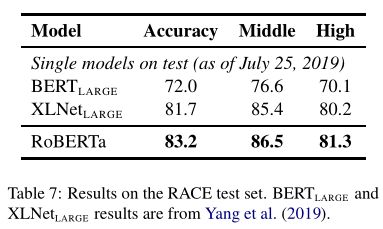
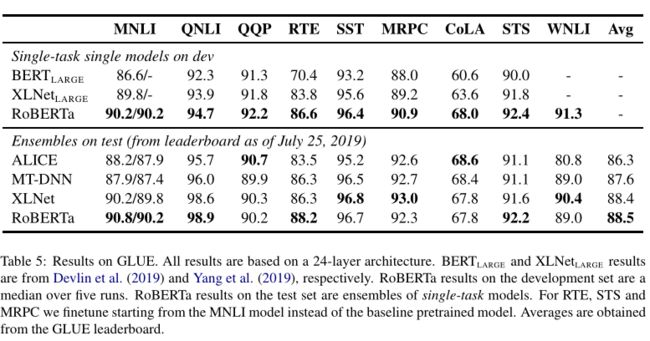
RoBERTa参与了SQuAD、RACE和GLUE的打榜,并与当时最好的模型XLNet进行比对,结果如下:
GLUE Results
SQuAD Results

RACE Results