机器学习入门(一)通过KNN算法来实现人群分类(Python)
前言(一些瞎感慨,可以不用看)
机器学习这门技术,已经听到多次可以说并不陌生。也知道他是从事数据科学工作的一个入门。虽然一直心向往之,却没有进行学习。这却与我的性格原因有很大的关系。我是有一些完美主义情节的。
所以就像儿时在开学之际,用积攒一冬的压岁钱买了梦寐以求的拼装。虽然满怀激动,爱不释手。但是不敢轻易的打开包装,一是担心自己没有准备好,又害怕没有仔细阅读好说明书,如果此时再有其他事情的打扰不免让人烦恼。所以我一般是选择一个周末睡一个懒觉,养足了精神。再到了午后,趁着大人们也已午睡,此时不会有其他事情打扰。找一两个儿时的好友打开拼装享受着充满和煦阳光下的时光。
我对待机器学习这门学科同样也是如此的,我学习编程的时间其实并不算短。大概从高中时,就从微机老师手里借来了dos命令详解这算是走入编程世界的入门吧,后面到了大学时又学了一系列语言无奈只是学学皮毛,没有深入钻研某一门语言,现在想来不免十分可惜。所以我自认为是一个喜欢尝试的人,但是对于机器学习我却没有那么早的尝试。
因为什么呢,一是害怕数学基础不是很完善,又担心分布式自己也不是很熟练,又想到机器学习比较枯燥如果准备不足失去了兴趣。就一拖再拖想把数学知识熟练了进行系统的学习。这一拖就是将近两年,数学知识跟分布式等等都没有多大提高,机器学习的知识也是一片空白。这期间我也从一个在校的学生,也成为了漂浮在一线大城市的社畜。大块的时间更没有了。
我知道了如果我此时不开始机器学习的相关学习,我以后可能就跟这一奇妙的学科失之交臂。
说了这么多,可能是前20多年对待软件学习的一个总结吧,同时希望这篇文章能成为机器学习开始的一门见证,我也希望对这门学科抱有浓厚的兴趣并也想要把这个世界变得更美好的设计师能够坚持去学习自己所喜欢的。文章我会不时的更新与修改,如果发现文章中有问题,也请您能够指正。
KNN算法
什么叫KNN算法呢?KNN算法就是K最近邻(k-Nearest Neighbor)分类算法,其中KNN是英文名字的简写。是一个理论上比较成熟的方法,也是最简单的机器学习算法之一,同时也是分类算法。该方法的思路是:在特征空间中,样本的最邻近的N个点,出现频率最高的类别就是他的类别了。
简单来说,如图1-1所示:
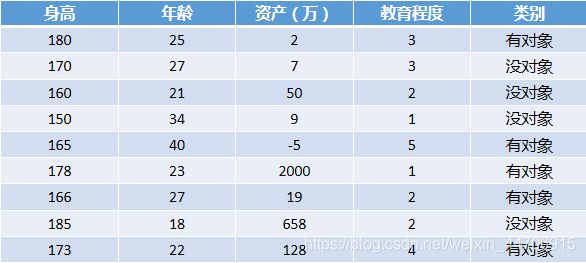
假设我们收集了本市10万名男性的数据,分别收集到了他们的身高、年龄、资产、教育程序(1为高中,2为大专,3为本科,4为重点/研究生,5为世界top50\博士)。这些就是样本数据的特征值,而他们被分为了有对象和没对象两个类别。
而图1-1即为样本中的信息判断。这个时候我们又的到了本市一名男性的特征值,但是并不知道他有没有对象,我们就可以计算出跟他距离最近的20个数据样本,如果这20个数据样本有18个都没有对象,我们就推测出该男性是没有对象的。
具体的实现
分类算法
import numpy as np
def ClassiFy(Sample,dataSet,category,k):
dataSetSize = len(dataSet)
diffMat = np.tile(Sample,(dataSetSize,1)) - dataSet#求距离
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5#求距离,即为欧拉距离。
sortedDistIndicies = distances.argsort()#返回距离从小到大的索引组成的列表
classCount={}
for i in range(k):
voteIlabel=category[sortedDistIndicies[i]]
classCount[voteIlabel]=classCount.get(voteIlabel,0)+1
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)#返回一个由大到小以类别出现频率的列表
return sortedClassCount[0][0]#返回出现频率最高的那个类别
这就是最简单的分类算法了,这个函数我们提供了4个参数,分别是要测试数据的特征值(身高、年龄、财产、教育)等,样本数据即为本市10万男性的特征值,样本数据中对应的类别即为有对象,或者没对象,取值数量,即为我们取的邻近多少个点,如果为20就是与该男子最相近的20条样本数据。其处理流程就是找到k条最邻近的数据,再找到出现频率最高的类别,这个类别就是我们预测的该测试数据对应的类别。
假设本市有一名成年男性张三[180,22,15,3],我们通过这个去求他的类别,可是我们发现并不是那么回事。张三的年龄和教育与样本中每条数据的特征值差别都不是很大,但是张三的教育程序和身高却与样本中的数据有很大差别,这样计算的结果很大程度上会受到财富和身高的影响,但是我们认为这4个条件都是同样重要的,为了公平起见,第二套算法应运而生。
归一化法
什么叫归一化法呢,就是把没一类数据在整个样本中数据的影响能力的值给求出来,简单的来说就是我们所说的
假设身高的最大值为200,最小值为150
那么图1-1,第一条数据的特征值就应该为(180-150)/(200-150)
换成方程表达就应该为newvalue = (value-min)/(max-min)
用代码表达就是
def GuiHua(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges, (m,1))
return normDataSet
有了这个方法,我们就可以视作是各个特征值的影响是相同的,但是这个并不是一定的。根据具体的业务需求而定,有时候可能需要你提供更多的约束,比如每个特征值会有特定的权值,特征值可能用的不是归一法,而是平均比值法等等。
总结(没看前言就不用看了)
学的第一个机器学习的算法,并不算很难,但是千里之行,始于足下。
学习是枯燥的,关于数据相关的学习就更加枯燥了并且非常抽象,所以除了我们自身的自制力外在学习过程中应尽量把学习变得有趣。第一种尽量量用所学的知识帮我我们的日常的数据工作,再一个则为要多去练习,多去试,感受自己的成果这样才能从中提供源源不断的精神的愉悦。
这篇文章虽然是一篇技术文章,但是可能有很多我想说的话,但没有说的话。我虽然年轻但是看过很多文章,看过很多前人的经验。做数据科学,乃至很多技术除了获取到的报酬之外,其中的枯燥年复一年的枯燥与坚持是常人无法忍受的。可能很多人说技术的深度与智力水平有很大的关系,我相信是但不是全部。而是选择坚持技术走向,还是学会左右逢源具有更多领导的性能能。社会赋予每个人的使命,每个人成长的方向却是不尽相同。而求而不得的时候,难免就会有很多迷茫与焦虑的。可以这么说,自从毕业以来。这种迷茫与焦虑无不一时困扰着我,而我相信此时在读这篇文章的大家也许有跟我所思所想十分的相似。
与君共勉的鸡血名言我就不写了,我希望的是此时的大家都找到自己的真实,做一些自己不讨厌的事吧。