李宏毅2023机器学习作业HW04解析和代码分享
ML2023Spring - HW4 相关信息:
课程主页
课程视频
Kaggle link
Sample code
HW04 视频
HW04 PDF
个人完整代码分享: GitHub | Gitee | GitCodeP.S. 即便 kaggle 上的时间已经截止,你仍然可以在上面提交和查看分数。但需要注意的是:在 kaggle 截止日期前你应该选择两个结果进行最后的Private评分。
每年的数据集size和feature并不完全相同,但基本一致,过去的代码仍可用于新一年的 Homework。
文章目录
- 任务目标(多类分类)
- 性能指标(Metric)
- 数据解析
- Baselines
-
- Simple baseline (0.66025)
- Medium baseline (0.814)
- Strong baseline (0.88500)
- Boss baseline (0.93175)
-
- Ablation Study
- Gradescope
-
- The variant of Transformer
-
- 模型架构图
-
- 1. SpecAug (简单了解即可)
- 2. Convolution Subsampling
- 3. Linear & Dropout
- 4. Conformer Block
任务目标(多类分类)
- Speaker prediction (预测说话者的身份)
性能指标(Metric)
Categorization Accuracy: 分类准确度
数据解析
-
训练数据: 56666 个处理过的带有标签的音频特征。
-
测试数据: 4000 个处理过的音频特征(公共和私有)没有标签。
-
标签: 600 个标签,每个标签对应于一个演讲者。
-
Dataset 文件夹下:
-
metadata.json
- “n_mels”: mel 光谱图(Mel spectrogram)的维数
- “speakers”: 一个字典
- Key: 演讲者 id
- Value:
- “feature_path”: 对应的音频文件(uttr-{random string}.pt)
- “mel_len”: mel 光谱图的长度
-
testdata.json(基本同上)
- “n_mels”
- “utterances”
- “feature_path”
- “mel_len”
-
mapping.json
- “speaker2id”: 指明了演讲者和 id 的对应关系,例: id00464": 0, “id00559”: 1, “id00578”: 2, “id00905”: 3
-
uttr-{random string}.pt: 语音片段
-
数据是 VoxCeleb2 的子集(随机选取了其中的 600 个演讲者)
Baselines
Simple baseline (0.66025)
- 运行所给的 sample code
Medium baseline (0.814)
-
修改 transformer 模块的参数
- d_model
- nhead
- self.pred_layer 中的网络
这一部分我跑了个片面的 Grid Search(网格搜索)来搜寻参数,最后的选择是(并非最优解):
- d_model: 512
- nhead: 16
- pred_layer:

在 total_steps=70000 的情况下,public_score 为 0.83300。
关于自动调参可以简单的参考这篇文章:使用Optuna进行模型的自动调参。
Strong baseline (0.88500)
-
将模型架构从 Transformer 转化为 Conformer
在这里直接修改 Medium 的 Classifier 部分,使用 Conformer 论文源码中的 Conformer Block,publicScore 便能达到 0.897,随手将 pred_layer 跟 Conformer 源码一样改为一层全连接层(红线)后,在epoch=70,000 的时候,publicScore 就达到了 0.95525,而原来的模型架构(绿线)在跑到 700,000 个 epoch 时,publicScore=0.95475,其实到此为止,已经达成了 Boss baseline,但出于学习目的,我会在 Boss baseline 中简单描述其他 hint。
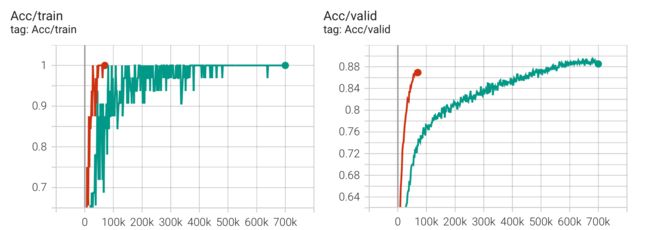
Boss baseline (0.93175)
HW04_PDF中并没有给出 Boss baseline 的具体分数,这个分数是在今年的 Kaggle 上查到的。
-
self-attention pooling
class SelfAttentionPooling(nn.Module): """ Implementation of SelfAttentionPooling Original Paper: Self-Attention Encoding and Pooling for Speaker Recognition https://arxiv.org/pdf/2008.01077v1.pdf """ def __init__(self, input_dim): super(SelfAttentionPooling, self).__init__() self.W = nn.Linear(input_dim, 1) def forward(self, batch_rep): """ input: batch_rep : size (N, T, H), N: batch size, T: sequence length, H: Hidden dimension attention_weight: att_w : size (N, T, 1) return: utter_rep: size (N, H) """ softmax = nn.functional.softmax att_w = softmax(self.W(batch_rep).squeeze(-1), dim=-1).unsqueeze(-1) utter_rep = torch.sum(batch_rep * att_w, dim=1) return utter_rep -
Additive Margin Softmax
```python from torch.autograd import Variable # https://github.com/zhilangtaosha/SpeakerVerification_AMSoftmax_pytorch/blob/63629989c152664c838823456532682585d72e31/model/model.py#L257 class AMSoftmax(nn.Module): def __init__(self): super(AMSoftmax, self).__init__() def forward(self, input, target, scale=10.0, margin=0.35): cos_theta = input target = target.view(-1, 1) # size=(B,1) index = cos_theta.data * 0.0 # size=(B,Classnum) index.scatter_(1, target.data.view(-1, 1), 1) index = index.byte() index = Variable(index) output = cos_theta * 1.0 # size=(B,Classnum) output[index.bool()] -= margin output = output * scale logpt = F.log_softmax(output, dim=1) logpt = logpt.gather(1, target) logpt = logpt.view(-1) loss = -1 * logpt loss = loss.mean() return loss
这两个模块都有放进Boss baseline的代码中,但我发现并没有让模型的效果变得更好,所以在 main function 模块的最后用了两个全局变量来决定是否使用(这里也有可能是我的用法或者架构问题,才使得效果不好,欢迎大家提出意见)。
Ablation Study
这里做一下 Self-Attention Pooling 和 AMSoftmax 在 epoch=70,000 下的消融实验。
这里的 AMSoftmax 接受的是 pred_layer 后的输出而非 pred_layer 的输入,我尝试过接受 pred_layer 的输入(也就是encoder 的输出),然后在 AMSoftmax 中重新训练一个全连接层,但效果依旧不好,这里我更倾向于是代码的问题,如果能有改进的建议,非常感谢 : )
| Public Score | Private Score | |
|---|---|---|
| Boss | 0.95125 | 0.9535 |
| + Self-Attention Pooling | 0.94925 | 0.9555 |
| + AMSoftmax | 0.94925 | 0.951 |
| + Combined Hints | 0.94925 | 0.951 |
Gradescope
The variant of Transformer
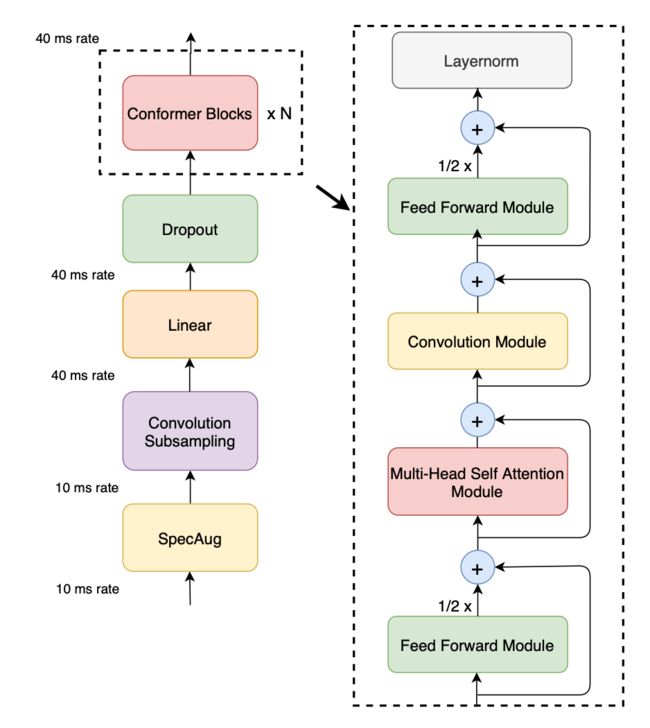
简单介绍一个 Transformer 的变体,结合模型架构图。
既然完成 Strong baseline 的 Hint 是将模型架构转变为 Conformer,那这里就直接以 Conformer 为例子进行介绍,源代码:Pytorch 版本。
模型架构图
1. SpecAug (简单了解即可)
使用了数据增强的方法进行处理,所引用的相关论文为:
- [1904.08779] SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition
该篇论文的 Augmentation Policy:- Time wraping
在时间维度上对频谱进行非线性变换,以模拟声音的变化。论文原文中使用的是 tensorflow 中的 sparse image warp 进行处理的。 - Frequency masking
在频率维度掩码,在频率维度上随机选择(根据均匀分布)一些连续的频带,并将其值设为零,以模拟声音的噪声或失真。 - Time masking
在时间维度掩码,基本同上。
- Time wraping
- [1912.05533] SpecAugment on Large Scale Datasets
- 基于上面的方法进行了研究,证明了其在大规模数据集任务上的有效性。
- Adaptive masking
作者认为对于不同长度的语音使用固定的掩码并不合适,使用了自适应掩码。
2. Convolution Subsampling
将 conv2d 的 stride 设置为 2 进行下采样操作。
推荐拓展阅读:Pooling vs. stride for downsampling
class Conv2dSubampling(nn.Module):
def __init__(self, in_channels: int, out_channels: int) -> None:
super(Conv2dSubampling, self).__init__()
self.sequential = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=2),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=2),
nn.ReLU(),
)
def forward(self, inputs: Tensor, input_lengths: Tensor) -> Tuple[Tensor, Tensor]:
outputs = self.sequential(inputs.unsqueeze(1))
batch_size, channels, subsampled_lengths, sumsampled_dim = outputs.size()
outputs = outputs.permute(0, 2, 1, 3) # (batch_size, subsampled_lengths, channels, subsampled_dim)
outputs = outputs.contiguous().view(batch_size, subsampled_lengths, channels * sumsampled_dim)
output_lengths = input_lengths >> 2
output_lengths -= 1
return outputs, output_lengths
3. Linear & Dropout
- Linear
对经过下采样处理后的数据做一个映射,((input_dim - 1) // 2 - 1) // 2是下采样之后的维度。 - Dropout
随机失活层,在训练过程中以一定的概率随机丢弃一些特征,用于防止过拟合。
class ConformerEncoder(nn.Module):
def __init__(self, ...):
...
self.conv_subsample = Conv2dSubampling(in_channels=1, out_channels=encoder_dim)
self.input_projection = nn.Sequential(
Linear(encoder_dim * (((input_dim - 1) // 2 - 1) // 2), encoder_dim),
nn.Dropout(p=input_dropout_p),
)
...
def forward(self, ...):
...
outputs, output_lengths = self.conv_subsample(inputs, input_lengths)
outputs = self.input_projection(outputs)
...
4. Conformer Block
-
Feed Forward Module
前馈和后馈模块,其实就是对输入进行 Layernorm 之后,过两层Linear,中间使用 Swish 激活并且进行 Dropout 操作,最后再过一次 Dropout。class FeedForwardModule(nn.Module): def __init__( self, encoder_dim: int = 512, expansion_factor: int = 4, dropout_p: float = 0.1, ) -> None: super(FeedForwardModule, self).__init__() self.sequential = nn.Sequential( nn.LayerNorm(encoder_dim), Linear(encoder_dim, encoder_dim * expansion_factor, bias=True), Swish(), nn.Dropout(p=dropout_p), Linear(encoder_dim * expansion_factor, encoder_dim, bias=True), nn.Dropout(p=dropout_p), ) def forward(self, inputs: Tensor) -> Tensor: return self.sequential(inputs) -
Multi-Head Self Attention Module
多头自注意力模块,这里还使用了相对位置编码(源于 Transformer-XL)from typing import Optional class RelativeMultiHeadAttention(nn.Module): def __init__( self, d_model: int = 512, num_heads: int = 16, dropout_p: float = 0.1, ): super(RelativeMultiHeadAttention, self).__init__() assert d_model % num_heads == 0, "d_model % num_heads should be zero." self.d_model = d_model self.d_head = int(d_model / num_heads) self.num_heads = num_heads self.sqrt_dim = math.sqrt(d_model) self.query_proj = Linear(d_model, d_model) self.key_proj = Linear(d_model, d_model) self.value_proj = Linear(d_model, d_model) self.pos_proj = Linear(d_model, d_model, bias=False) self.dropout = nn.Dropout(p=dropout_p) self.u_bias = nn.Parameter(torch.Tensor(self.num_heads, self.d_head)) self.v_bias = nn.Parameter(torch.Tensor(self.num_heads, self.d_head)) torch.nn.init.xavier_uniform_(self.u_bias) torch.nn.init.xavier_uniform_(self.v_bias) self.out_proj = Linear(d_model, d_model) def forward( self, query: Tensor, key: Tensor, value: Tensor, pos_embedding: Tensor, mask: Optional[Tensor] = None, ) -> Tensor: batch_size = value.size(0) query = self.query_proj(query).view(batch_size, -1, self.num_heads, self.d_head) key = self.key_proj(key).view(batch_size, -1, self.num_heads, self.d_head).permute(0, 2, 1, 3) value = self.value_proj(value).view(batch_size, -1, self.num_heads, self.d_head).permute(0, 2, 1, 3) pos_embedding = self.pos_proj(pos_embedding).view(batch_size, -1, self.num_heads, self.d_head) content_score = torch.matmul((query + self.u_bias).transpose(1, 2), key.transpose(2, 3)) pos_score = torch.matmul((query + self.v_bias).transpose(1, 2), pos_embedding.permute(0, 2, 3, 1)) pos_score = self._relative_shift(pos_score) score = (content_score + pos_score) / self.sqrt_dim if mask is not None: mask = mask.unsqueeze(1) score.masked_fill_(mask, -1e9) attn = F.softmax(score, -1) attn = self.dropout(attn) context = torch.matmul(attn, value).transpose(1, 2) context = context.contiguous().view(batch_size, -1, self.d_model) return self.out_proj(context) def _relative_shift(self, pos_score: Tensor) -> Tensor: batch_size, num_heads, seq_length1, seq_length2 = pos_score.size() zeros = pos_score.new_zeros(batch_size, num_heads, seq_length1, 1) padded_pos_score = torch.cat([zeros, pos_score], dim=-1) padded_pos_score = padded_pos_score.view(batch_size, num_heads, seq_length2 + 1, seq_length1) pos_score = padded_pos_score[:, :, 1:].view_as(pos_score) return pos_score class MultiHeadedSelfAttentionModule(nn.Module): def __init__(self, d_model: int, num_heads: int, dropout_p: float = 0.1): super(MultiHeadedSelfAttentionModule, self).__init__() self.positional_encoding = PositionalEncoding(d_model) self.layer_norm = nn.LayerNorm(d_model) self.attention = RelativeMultiHeadAttention(d_model, num_heads, dropout_p) self.dropout = nn.Dropout(p=dropout_p) def forward(self, inputs: Tensor, mask: Optional[Tensor] = None): batch_size, seq_length, _ = inputs.size() pos_embedding = self.positional_encoding(seq_length) pos_embedding = pos_embedding.repeat(batch_size, 1, 1) inputs = self.layer_norm(inputs) outputs = self.attention(inputs, inputs, inputs, pos_embedding=pos_embedding, mask=mask) return self.dropout(outputs) -
Convolution Module
卷积模块,架构如图所示。

class DepthwiseConv1d(nn.Module): def __init__( self, in_channels: int, out_channels: int, kernel_size: int, stride: int = 1, padding: int = 0, bias: bool = False, ) -> None: super(DepthwiseConv1d, self).__init__() assert out_channels % in_channels == 0, "out_channels should be constant multiple of in_channels" self.conv = nn.Conv1d( in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, groups=in_channels, stride=stride, padding=padding, bias=bias, ) def forward(self, inputs: Tensor) -> Tensor: return self.conv(inputs) class PointwiseConv1d(nn.Module): def __init__( self, in_channels: int, out_channels: int, stride: int = 1, padding: int = 0, bias: bool = True, ) -> None: super(PointwiseConv1d, self).__init__() self.conv = nn.Conv1d( in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride, padding=padding, bias=bias, ) def forward(self, inputs: Tensor) -> Tensor: return self.conv(inputs) class ConformerConvModule(nn.Module): def __init__( self, in_channels: int, kernel_size: int = 31, expansion_factor: int = 2, dropout_p: float = 0.1, ) -> None: super(ConformerConvModule, self).__init__() assert (kernel_size - 1) % 2 == 0, "kernel_size should be a odd number for 'SAME' padding" assert expansion_factor == 2, "Currently, Only Supports expansion_factor 2" self.sequential = nn.Sequential( nn.LayerNorm(in_channels), Transpose(shape=(1, 2)), PointwiseConv1d(in_channels, in_channels * expansion_factor, stride=1, padding=0, bias=True), GLU(dim=1), DepthwiseConv1d(in_channels, in_channels, kernel_size, stride=1, padding=(kernel_size - 1) // 2), nn.BatchNorm1d(in_channels), Swish(), PointwiseConv1d(in_channels, in_channels, stride=1, padding=0, bias=True), nn.Dropout(p=dropout_p), ) def forward(self, inputs: Tensor) -> Tensor: return self.sequential(inputs).transpose(1, 2)
ConformerBlock code
需要注意的是,每个 Module 都使用了残差连接。
class ConformerBlock(nn.Module):
def __init__(
self,
encoder_dim: int = 512,
num_attention_heads: int = 8,
feed_forward_expansion_factor: int = 4,
conv_expansion_factor: int = 2,
feed_forward_dropout_p: float = 0.1,
attention_dropout_p: float = 0.1,
conv_dropout_p: float = 0.1,
conv_kernel_size: int = 31,
half_step_residual: bool = True,
):
super(ConformerBlock, self).__init__()
if half_step_residual:
self.feed_forward_residual_factor = 0.5
else:
self.feed_forward_residual_factor = 1
self.sequential = nn.Sequential(
ResidualConnectionModule(
module=FeedForwardModule(
encoder_dim=encoder_dim,
expansion_factor=feed_forward_expansion_factor,
dropout_p=feed_forward_dropout_p,
),
module_factor=self.feed_forward_residual_factor,
),
ResidualConnectionModule(
module=MultiHeadedSelfAttentionModule(
d_model=encoder_dim,
num_heads=num_attention_heads,
dropout_p=attention_dropout_p,
),
),
ResidualConnectionModule(
module=ConformerConvModule(
in_channels=encoder_dim,
kernel_size=conv_kernel_size,
expansion_factor=conv_expansion_factor,
dropout_p=conv_dropout_p,
),
),
ResidualConnectionModule(
module=FeedForwardModule(
encoder_dim=encoder_dim,
expansion_factor=feed_forward_expansion_factor,
dropout_p=feed_forward_dropout_p,
),
module_factor=self.feed_forward_residual_factor,
),
nn.LayerNorm(encoder_dim),
)
def forward(self, inputs: Tensor) -> Tensor:
return self.sequential(inputs)