yolo v1论文笔记
yolov1
参考这篇文章
https://zhuanlan.zhihu.com/p/46691043
摘要
we frame object detection as a regression problem to spatially separated bounding boxes and associated class probabilities.
作者将目标检测问题变成一个回归问题,包括bounding boxes的计算和目标类别的概率。
A single neural network predicts bounding boxes and class probabilities directly from
full images in one evaluation. Since the whole detection pipeline is a single network, it can be optimized end-to-end directly on detection performance
直接用一个卷积网络,就是卷呗。能用端到端的方法进行优化。
Our unified architecture is extremely fast.
我们的速度很快。
介绍
Unlike sliding window and region proposal-based techniques, YOLO sees the entire image during training and test time so it implicitly encodes contextual information about classes as well as their appearance.
和滑动窗口的方法以及region proposal的方法不一样,yolo 在训练和测试阶段都是可以“看见”整个图片的,所以它能隐式的编码关于类别和外观的上下文信息。
YOLO learns generalizable representations of objects. When trained on natural images and tested on artwork, YOLO outperforms top detection methods like DPM and R-CNN by a wide margin. Since YOLO is highly generalizable it is less likely to break down when applied to new domains or unexpected inputs.
yolo算法学习目标的高度概泛化性的表征。当训练网络时,yolo算法比DPM和R-CNN要好很多。因为YOLO是一个高度泛化的模型,所以yolo不会在应用到其他场景和输入的时候出现较大的问题。
统一化的检测步骤
Our network uses features from the entire image to predict each bounding box. It also predicts all bounding boxes across all classes for an image simultaneously.
网络使用特征图从整个图片的角度去预测每个bounding box,同样也预测所有类别的bounding box。
Our system divides the input image into an S × S grid. If the center of an object falls into a grid cell, that grid cell is responsible for detecting that object.
如下图所示,网络将输入图像最后得到一个7×7×30(原文中S×S gird)的特征图,这个特征图映射回输入图片大小的尺寸,可以表示为将原始图像划分乘7×7个大小的网格(gird),如果原始图像中某个目标在这个gird当中,那么这个gird就负责检测这个目标。
Each grid cell predicts B bounding boxes and confidence scores for those boxes. These confidence scores reflect how confident the model is that the box contains an object and also how accurate it thinks the box is that it predicts.
每个gird预测B个bounding boxes和这些bounding boxes的置信度分数。置信度分数反应了模型包含一个目标以及对bounding box中目标越的准确率。
如下面图(来自zhihu)

再借用zhihu中的一张图和一段话。
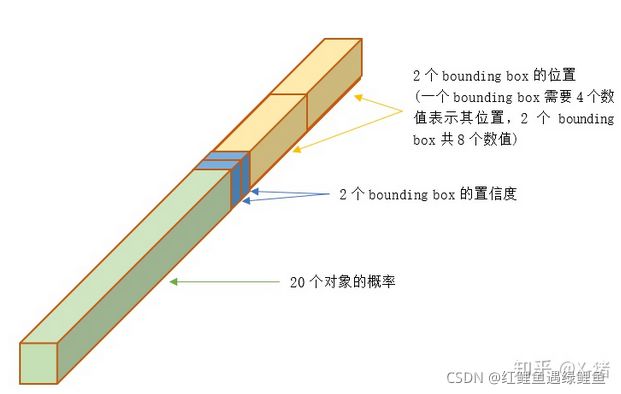 30维向量 = 20个对象的概率 + 2个bounding box * 4个坐标 + 2个bounding box的置信度
30维向量 = 20个对象的概率 + 2个bounding box * 4个坐标 + 2个bounding box的置信度
定义置信度的计算方法为:
P r ( o b j e c t ) ∗ I O U p r e d t r u t h Pr(object) * IOU^{truth}_{pred} Pr(object)∗IOUpredtruth 表示为: 目标存在的概率 * 预测的bounding box与ground truth的IOU
如果目标存在的概率是0,表示gird中不存在目标;
每个bounding box包含5个值,分别是x, y, w, h以及置信度。
The (x,y) coordinates represent the center of the box relative to the bounds of the grid cell.
(x,y)表示相对于网格单元边界的框的中心位置。
The width and height are predicted relative to the whole image.
w, h表示相对于整个图片的框的宽高。
Finally the confidence prediction represents the IOU between the predicted box and any ground truth box.
预测的置信度表示预测的box与任意一个一个ground true 框的IOU。
Each grid cell also predicts C conditional class probabilities, P r ( C l a s s i ∣ O b j e c t ) Pr(Class_i |Object) Pr(Classi∣Object). These probabilities are conditioned on the grid cell containing an object.
每个特征图上的点也预测目标为某一个类别的概率,表示为 P r ( C l a s s i ∣ O b j e c t ) Pr(Class_i |Object) Pr(Classi∣Object),意思是在当前的框包含目标的情况下,是类别i的概率。
We only predict one set of class probabilities per grid cell, regardless of the number of boxes B.
注意,预测的目标类别分数是针对每个特征图上的点来说的,而不是每个bounding box,因为每个特征图上的点回预测多个bounding box(比如两个),但是实际上只会有一组类别分数。
At test time we multiply the conditional class probabilities and the individual box confidence predictions。
在测试阶段,我们把每个类别的条件概率和bounding box框的置信度相乘,得到类别的最终概率。
在yolo中支持20种目标类别的识别,每个目标类别都有一个条件概率。
p r ( c l a s s i ∣ o b j e c t ) pr(class_i | object) pr(classi∣object) 表示一个bounding box在确定是一个目标的情况下,分类为i的概率的是多少。
预测过程中,每个特征图上的点会预测两个bounding box,一共有8组坐标。
P r ( o b j e c t ) Pr(object) Pr(object)表示预测的bounding box是否包含目标.
那么,根据条件概率公式,最后可以得到的
P r ( c l a s s i ) ∗ I O U p r e d t r u t h = P r ( c l a s s i ∣ o b j e c t ) ∗ P r ( o b j e c t ) ∗ I O U p r e d t r u t h Pr(class_i) * IOU^{truth}_{pred} = Pr(class_i | object) * Pr(object) * IOU^{truth}_{pred} Pr(classi)∗IOUpredtruth=Pr(classi∣object)∗Pr(object)∗IOUpredtruth
I O U p r e d t r u t h IOU^{truth}_{pred} IOUpredtruth 表示预测的bounding box与ground truth的交并比。
注意,上面的计算是针对训练阶段,因为测试阶段没有ground truth提供。
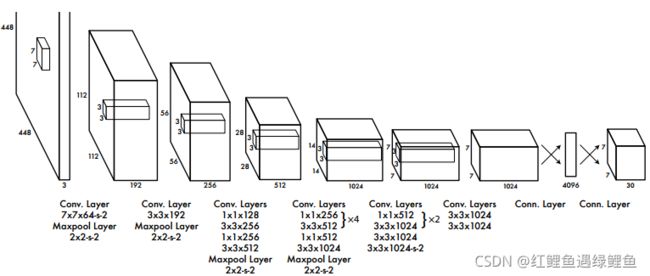 Our network architecture is inspired by the GoogLeNet model for image classification [34]. Our network has 24 convolutional layers followed by 2 fully connected layers.
Our network architecture is inspired by the GoogLeNet model for image classification [34]. Our network has 24 convolutional layers followed by 2 fully connected layers.
Instead of the inception modules used by GoogLeNet, we simply use 1 × 1 reduction layers followed by 3 × 3 convolutional layers, similar to Lin et al [22].
网络的结构是源于GoogLeNet的分类模型,网络有24个卷积层,最后接着两个全连接层。
作者将3×3的卷积后面接了一个1×1的降维的层。
最后一层预测目标概率和bounding box的坐标,并对预测到的坐标相对于原始图片进行归一化,得到一个[0,1]的小数。同样,对bounding box的 (x,y)进行转换成相对特征图中点的偏移,这样(x,y)也归一化为[0,1]。(以上是为了训练用)
在网络的最后一层加上leaky relu
网络先在识别的数据集上训练backbone,在用其它检测的数据集训练。
误差计算
图片来自zhihu
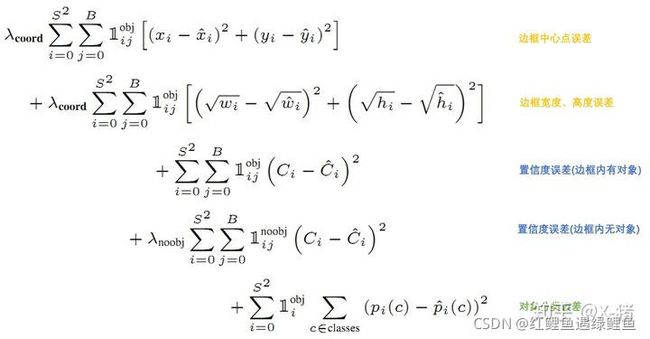 对于loss函数,是通过ground truth和输出之间的sum-squared error进行计算的,所以相当于把分类问题也当成回归问题来计算loss。
对于loss函数,是通过ground truth和输出之间的sum-squared error进行计算的,所以相当于把分类问题也当成回归问题来计算loss。
B表示一个网格有多少个bounding box(文中两个)
S表示特征图的尺寸(文中为7)
λ c o o r d λ_{coord} λcoord 表示bounding box位置误差的权重(相对分类误差和置信度误差)
λ n o o b j λ_{noobj} λnoobj表示为调节不存在对象的bounding box的置信度的权重(相对其它误差)
1 i j o b j 1^{obj}_{ij} 1ijobj表示网格i的第j个bounding box中存在对象,值为1或0。
1 i o b j 1^{obj}_{i} 1iobj表示网格i中存在对象,值为1或0。
1 i j n o o b j 1^{noobj}_{ij} 1ijnoobj表示网格i的第j个bounding box中不存在对象,值为1或0。
x i , y i x_i, y_i xi,yi 表示预测的目标中心点,同理其它的参数
由上面公式12行可知, 1 i j o b j 1^{obj}_{ij} 1ijobj意味着只有"负责"(IOU比较大)预测的那个bounding box的数据才会计入误差。
第2行宽度和高度先取了平方根,因为如果直接取差值的话,大的对象对差值的敏感度较低,小的对象对差值的敏感度较高,所以取平方根可以降低这种敏感度的差异,使得较大的对象和较小的对象在尺寸误差上有相似的权重。
乘以 λ c o o r d λ_{coord} λcoord 调节bounding box位置误差的权重(相对分类误差和置信度误差)
第3行是存在对象的bounding box的置信度误差。带有$1^{obj}_{ij}意味着只有"负责"(IOU比较大)预测的那个bounding box的置信度才会计入误差。
第4行是不存在对象的bounding box的置信度误差。因为不存在对象的bounding box应该老老实实的说"我这里没有对象",也就是输出尽量低的置信度。如果它不恰当的输出较高的置信度,会与真正"负责"该对象预测的那个bounding box产生混淆。其实就像对象分类一样,正确的对象概率最好是1,所有其它对象的概率最好是0。
第4行会乘以 λ n o o b j λ_{noobj} λnoobj调节不存在对象的bounding box的置信度的权重(相对其它误差)。
预测
训练好的YOLO网络,输入一张图片,将输出一个 7730 的张量(tensor)来表示图片中所有网格包含的对象(概率)以及该对象可能的2个位置(bounding box)和可信程度(置信度)
为了从中提取出最有可能的那些对象和位置,YOLO采用NMS(Non-maximal suppression,非极大值抑制)算法。
主要思路是:选择得分最高的作为输出,与该输出重叠的去掉,不断重复这一过程直到所有备选处理完。
计算方法如下:
网络输出的7730的张量,在每一个网格中,对象 C i C_i Ci位于第j个bounding box的得分:
S c o r e i j = P ( C i ∣ O b j e c t ) ∗ C o n f i d i e n c e j Score_{ij} = P(C_i|Object) * Confidience_j Scoreij=P(Ci∣Object)∗Confidiencej 表示某个对象 C i C_i Ci存在于第j个bounding box的可能性
每个网格有:20个对象的概率*2个bounding box的置信度,共40个得分(候选对象)。49个网格共1960个得分。Andrew Ng建议每种对象分别进行NMS,那么每种对象有 1960/20=98 个得分。
NMS步骤如下:
1)设置一个Score的阈值,低于该阈值的候选对象排除掉(将该Score设为0)
2)遍历每一个对象类别
2.1)遍历该对象的98个得分
2.1.1)找到Score最大的那个对象及其bounding box,添加到输出列表
2.1.2)对每个Score不为0的候选对象,计算其与上面2.1.1输出对象的bounding box的IOU
2.1.3)根据预先设置的IOU阈值,所有高于该阈值(重叠度较高)的候选对象排除掉(将Score设为0)
2.1.4)如果所有bounding box要么在输出列表中,要么Score=0,则该对象类别的NMS完成,返回步骤2处理下一种对象
限制
- yolov1在选取bounding box的时候有很强的空间约束,因为每个gird只预测两个bounding box,只能包含一个类别。这种约束限制了可以预测的邻近目标的数量。
- 网络模型直接学习预测边界框(faster rcnn和ssd都是学习框的偏移),很难泛化到不同长宽比的新目标,另外下采样次数影响对框定位的准确性。
- 同样是因为定位不准确,大目标的框和小目标的框采用了相同的错误处理,在相同的框定位的误差下,大的目标可以容忍,但是小的目标很难容忍。
代码
标签
参考这篇博客的代码
https://blog.csdn.net/weixin_41424926/article/details/105383064
def convert_bbox2labels(bbox):
"""将bbox的(cls,x,y,w,h)数据转换为训练时方便计算Loss的数据形式(7,7,5*B+cls_num)
B表示bbox 5 * B表示一个bbox里面的(cls,x,y,w,h)
注意,输入的bbox的信息是(xc,yc,w,h)格式的,转换为labels后,bbox的信息转换为了(px,py,w,h)格式"""
gridsize = 1.0/7
labels = np.zeros((7,7,5*NUM_BBOX+len(CLASSES))) # 注意,此处需要根据不同数据集的类别个数进行修改
for i in range(len(bbox)//5):
gridx = int(bbox[i*5+1] // gridsize) # 当前bbox中心落在第gridx个网格,列
gridy = int(bbox[i*5+2] // gridsize) # 当前bbox中心落在第gridy个网格,行
# (bbox中心坐标 - 网格左上角点的坐标)/网格大小 ==> bbox中心点的相对位置
gridpx = bbox[i * 5 + 1] / gridsize - gridx
gridpy = bbox[i * 5 + 2] / gridsize - gridy
# 将第gridy行,gridx列的网格设置为负责当前ground truth的预测,置信度和对应类别概率均置为1
labels[gridy, gridx, 0:5] = np.array([gridpx, gridpy, bbox[i * 5 + 3], bbox[i * 5 + 4], 1])
labels[gridy, gridx, 5:10] = np.array([gridpx, gridpy, bbox[i * 5 + 3], bbox[i * 5 + 4], 1])
labels[gridy, gridx, 10+int(bbox[i*5])] = 1
return labels
上面的代码是如何将标记的数据转换成在网络中训练所使用的格式。
因为在yolo v1中,最后得到一个7×7×30的特征图,将特征图映射回原始图像,即将原始的图像分割成7×7份,也就是上面代码中的girdx和girdy。如果bbox正好落在某个gird当中,那么这个gird就标记为一个目标。
loss计算
上面得到的标签与最后预测生成的7×7×30得到的bbox计算loss
class Loss_yolov1(nn.Module):
def __init__(self):
super(Loss_yolov1,self).__init__()
def forward(self, pred, labels):
"""
:param pred: (batchsize,30,7,7)的网络输出数据
:param labels: (batchsize,30,7,7)的样本标签数据
:return: 当前批次样本的平均损失
"""
num_gridx, num_gridy = labels.size()[-2:] # 划分网格数量
num_b = 2 # 每个网格的bbox数量
num_cls = 20 # 类别数量
noobj_confi_loss = 0. # 不含目标的网格损失(只有置信度损失)
coor_loss = 0. # 含有目标的bbox的坐标损失
obj_confi_loss = 0. # 含有目标的bbox的置信度损失
class_loss = 0. # 含有目标的网格的类别损失
n_batch = labels.size()[0] # batchsize的大小
# 可以考虑用矩阵运算进行优化,提高速度,为了准确起见,这里还是用循环
for i in range(n_batch): # batchsize循环
for n in range(7): # x方向网格循环
for m in range(7): # y方向网格循环
if labels[i,4,m,n]==1:# 如果包含物体
# 将数据(px,py,w,h)转换为(x1,y1,x2,y2)
# 先将px,py转换为cx,cy,即相对网格的位置转换为标准化后实际的bbox中心位置cx,xy
# 然后再利用(cx-w/2,cy-h/2,cx+w/2,cy+h/2)转换为xyxy形式,用于计算iou
bbox1_pred_xyxy = ((pred[i,0,m,n]+n)/num_gridx - pred[i,2,m,n]/2,(pred[i,1,m,n]+m)/num_gridy - pred[i,3,m,n]/2,
(pred[i,0,m,n]+n)/num_gridx + pred[i,2,m,n]/2,(pred[i,1,m,n]+m)/num_gridy + pred[i,3,m,n]/2)
bbox2_pred_xyxy = ((pred[i,5,m,n]+n)/num_gridx - pred[i,7,m,n]/2,(pred[i,6,m,n]+m)/num_gridy - pred[i,8,m,n]/2,
(pred[i,5,m,n]+n)/num_gridx + pred[i,7,m,n]/2,(pred[i,6,m,n]+m)/num_gridy + pred[i,8,m,n]/2)
bbox_gt_xyxy = ((labels[i,0,m,n]+n)/num_gridx - labels[i,2,m,n]/2,(labels[i,1,m,n]+m)/num_gridy - labels[i,3,m,n]/2,
(labels[i,0,m,n]+n)/num_gridx + labels[i,2,m,n]/2,(labels[i,1,m,n]+m)/num_gridy + labels[i,3,m,n]/2)
iou1 = calculate_iou(bbox1_pred_xyxy,bbox_gt_xyxy)
iou2 = calculate_iou(bbox2_pred_xyxy,bbox_gt_xyxy)
# 选择iou大的bbox作为负责物体
if iou1 >= iou2:
coor_loss = coor_loss + 5 * (torch.sum((pred[i,0:2,m,n] - labels[i,0:2,m,n])**2) \
+ torch.sum((pred[i,2:4,m,n].sqrt()-labels[i,2:4,m,n].sqrt())**2))
obj_confi_loss = obj_confi_loss + (pred[i,4,m,n] - iou1)**2
# iou比较小的bbox不负责预测物体,因此confidence loss算在noobj中,注意,对于标签的置信度应该是iou2
noobj_confi_loss = noobj_confi_loss + 0.5 * ((pred[i,9,m,n]-iou2)**2)
else:
coor_loss = coor_loss + 5 * (torch.sum((pred[i,5:7,m,n] - labels[i,5:7,m,n])**2) \
+ torch.sum((pred[i,7:9,m,n].sqrt()-labels[i,7:9,m,n].sqrt())**2))
obj_confi_loss = obj_confi_loss + (pred[i,9,m,n] - iou2)**2
# iou比较小的bbox不负责预测物体,因此confidence loss算在noobj中,注意,对于标签的置信度应该是iou1
noobj_confi_loss = noobj_confi_loss + 0.5 * ((pred[i, 4, m, n]-iou1) ** 2)
class_loss = class_loss + torch.sum((pred[i,10:,m,n] - labels[i,10:,m,n])**2)
else: # 如果不包含物体
noobj_confi_loss = noobj_confi_loss + 0.5 * torch.sum(pred[i,[4,9],m,n]**2)
loss = coor_loss + obj_confi_loss + noobj_confi_loss + class_loss
# 此处可以写代码验证一下loss的大致计算是否正确,这个要验证起来比较麻烦,比较简洁的办法是,将输入的pred置为全1矩阵,再进行误差检查,会直观很多。
return loss/n_batch
上面的calculate_iou函数是计算两个box的iou,因为设置每个gird只生成两个box,那么选取于ground truth的iou最大的作为检测到目标计算的loss,iou较小的哪个box负责作为反例子计算loss。
预测阶段
def labels2bbox(matrix):
"""
将网络输出的7*7*30的数据转换为bbox的(98,25)的格式,然后再将NMS处理后的结果返回
:param matrix: 注意,输入的数据中,bbox坐标的格式是(px,py,w,h),需要转换为(x1,y1,x2,y2)的格式再输入NMS
:return: 返回NMS处理后的结果
"""
if matrix.size()[0:2]!=(7,7):
raise ValueError("Error: Wrong labels size:",matrix.size())
bbox = torch.zeros((98,25))
# 先把7*7*30的数据转变为bbox的(98,25)的格式,其中,bbox信息格式从(px,py,w,h)转换为(x1,y1,x2,y2),方便计算iou
for i in range(7): # i是网格的行方向(y方向)
for j in range(7): # j是网格的列方向(x方向)
bbox[2*(i*7+j),0:4] = torch.Tensor([(matrix[i, j, 0] + j) / 7 - matrix[i, j, 2] / 2,
(matrix[i, j, 1] + i) / 7 - matrix[i, j, 3] / 2,
(matrix[i, j, 0] + j) / 7 + matrix[i, j, 2] / 2,
(matrix[i, j, 1] + i) / 7 + matrix[i, j, 3] / 2])
bbox[2 * (i * 7 + j), 4] = matrix[i,j,4]
bbox[2*(i*7+j),5:] = matrix[i,j,10:]
bbox[2*(i*7+j)+1,0:4] = torch.Tensor([(matrix[i, j, 5] + j) / 7 - matrix[i, j, 7] / 2,
(matrix[i, j, 6] + i) / 7 - matrix[i, j, 8] / 2,
(matrix[i, j, 5] + j) / 7 + matrix[i, j, 7] / 2,
(matrix[i, j, 6] + i) / 7 + matrix[i, j, 8] / 2])
bbox[2 * (i * 7 + j)+1, 4] = matrix[i, j, 9]
bbox[2*(i*7+j)+1,5:] = matrix[i,j,10:]
return NMS(bbox) # 对所有98个bbox执行NMS算法,清理cls-specific confidence score较低以及iou重合度过高的bbox
上面代码中输入的matrix就是(batch, 7, 7 ,30)的矩阵,矩阵的含义已经清楚,如何根据矩阵中的信息选区最佳检测框的结果?
上面代码是把matrix转换称bbox的格式,共98个bbox,每个bbox的维度是25,前5个数据表示(x,y, w,h)以及置信度,后面20个数据表示类别的概率。
接下来调用NMS非极大值抑制的算法,得到最优的box
def NMS(bbox, conf_thresh=0.1, iou_thresh=0.3):
"""bbox数据格式是(n,25),前4个是(x1,y1,x2,y2)的坐标信息,第5个是置信度,后20个是类别概率
:param conf_thresh: cls-specific confidence score的阈值
:param iou_thresh: NMS算法中iou的阈值
"""
n = bbox.size()[0]
bbox_prob = bbox[:,5:].clone() # 类别预测的条件概率
bbox_confi = bbox[:, 4].clone().unsqueeze(1).expand_as(bbox_prob) # 预测置信度
bbox_cls_spec_conf = bbox_confi*bbox_prob # 置信度*类别条件概率=cls-specific confidence score整合了是否有物体及是什么物体的两种信息
bbox_cls_spec_conf[bbox_cls_spec_conf<=conf_thresh] = 0 # 将低于阈值的bbox忽略
for c in range(20):
rank = torch.sort(bbox_cls_spec_conf[:,c],descending=True).indices
for i in range(98):
if bbox_cls_spec_conf[rank[i],c]!=0:
for j in range(i+1,98):
if bbox_cls_spec_conf[rank[j],c]!=0:
iou = calculate_iou(bbox[rank[i],0:4],bbox[rank[j],0:4])
if iou > iou_thresh: # 根据iou进行非极大值抑制抑制
bbox_cls_spec_conf[rank[j],c] = 0
bbox = bbox[torch.max(bbox_cls_spec_conf,dim=1).values>0] # 将20个类别中最大的cls-specific confidence score为0的bbox都排除
bbox_cls_spec_conf = bbox_cls_spec_conf[torch.max(bbox_cls_spec_conf,dim=1).values>0]
res = torch.ones((bbox.size()[0],6))
res[:,1:5] = bbox[:,0:4] # 储存最后的bbox坐标信息
res[:,0] = torch.argmax(bbox[:,5:],dim=1).int() # 储存bbox对应的类别信息
res[:,5] = torch.max(bbox_cls_spec_conf,dim=1).values # 储存bbox对应的class-specific confidence scores
return res
上面代码中
bbox_cls_spec_conf = bbox_confi*bbox_prob 表示对每个box中的类别概率乘以该box的的置信度,即该box存在目标。并去掉小于阈值的box(设置成0)。
按照上面NMS的规则,剔除掉不合理的的box,最后留下的即为目标框