【机器学习】log loss、logistic loss与cross-entropy的关系
结论:
- log loss就是cross-entropy。
- 二分类时,cross-entropy等价于logistic loss,算是一种特例情况。主要是看预测概览的类别有几种,cross-entropy也可以多分类,logistic loss就是只能二分类。
目录
一、logistic loss与cross-entropy
二、log loss与cross-entropy
三、Python 实现
一、logistic loss与cross-entropy
二分类时,logistic loss与cross-entropy

二、log loss与cross-entropy
对数损失函数的计算公式:
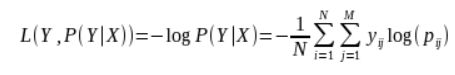
这不就是cross-entropy吗?
其中, Y 为输出变量, X为输入变量, L 为损失函数. N为输入样本量, M为可能的类别数, yij 是一个二值指标, 表示类别 j 是否是输入实例 xi 的真实类别. pij 为模型或分类器预测输入实例 xi 属于类别 j 的概率.
如果只有两类 {0, 1}, 则对数损失函数的公式简化为

这时, yi 为输入实例 xi 的真实类别, pi 为预测输入实例 xi 属于类别 1 的概率. 对所有样本的对数损失表示对每个样本的对数损失的平均值, 对于完美的分类器, 对数损失为 0。
三、Python 实现
采用自定义 logloss 函数和 scikit-learn 库中 sklearn.metrics.log_loss 函数两种方式实现对数损失, 如下所示:
#!/usr/bin/env python
# -*- coding: utf8 -*-
#author: klchang
#date: 2018.6.23
# y_true: list, the true labels of input instances
# y_pred: list, the probability when the predicted label of input instances equals to 1
def logloss(y_true, y_pred, eps=1e-15):
import numpy as np
# Prepare numpy array data
y_true = np.array(y_true)
y_pred = np.array(y_pred)
assert (len(y_true) and len(y_true) == len(y_pred))
# Clip y_pred between eps and 1-eps
p = np.clip(y_pred, eps, 1-eps)
loss = np.sum(- y_true * np.log(p) - (1 - y_true) * np.log(1-p))
return loss / len(y_true)
def unitest():
y_true = [0, 0, 1, 1]
y_pred = [0.1, 0.2, 0.7, 0.99]
print ("Use self-defined logloss() in binary classification, the result is {}".format(logloss(y_true, y_pred)))
from sklearn.metrics import log_loss
print ("Use log_loss() in scikit-learn, the result is {} ".format(log_loss(y_true, y_pred)))
if __name__ == '__main__':
unitest()参考:
分类问题为什么不用Logistic loss而用cross entropy? - 知乎
【深度学习】一文读懂机器学习常用损失函数(Loss Function)
对数损失函数(Logarithmic Loss Function)的原理和 Python 实现