————CNN一些实践性技巧,高效BP方法
转载:http://lib.csdn.net/article/deeplearning/42985
《 Neural Networks Tricks of the Trade.2nd》这本书是收录了1998-2012年在NN上面的一些技巧、原理、算法性文章,对于初学者或者是正在学习NN的来说是很受用的。全书一共有30篇论文,本书期望里面的文章随着时间能成为经典,不过正如bengio(超级大神)说的“the wisdom distilled here should be taken as a guideline, to be tried and challenged, not as a practice set in stone”。
本博文意在介绍其中第一篇论文《Efficient BackProp》,这是yann lecun他们(超级大神)在1998年写的,虽然文中有些观点略显过时,不过仍不乏借鉴之处,按历史潮流,取其精华即可。
一、引言
BP算法正因为它的概念简单、计算高效和总是能够work受到大家的青睐。不过对于设计和训练一个网络来说,很多的东西看起来是艺术大过于学术,比如神经元的数量、类型,网络的层数,学习率,训练和测试集等等。不过它们是数据依赖的,所以没有任何的简单明了的规则告诉我们应该怎么设定。不过还是有一些潜在的原理有助于我们在这些参数的选择上有理可依。
本文工作安排:先介绍下标准的BP然后讨论下一些简单的启发式方法和技巧;然后讨论收敛的问题;接着介绍一些经典的二阶非线性优化算法,并且介绍它们在NN的训练上的限制。最后提出了一个新的二阶方法使得能够在某些情况下能够加速学习。
1.2、学习和泛化
虽然有着很多的方法能够进行网络的训练,不过大多数成功的方法都可以归为基于梯度学习的方法。正如下图:
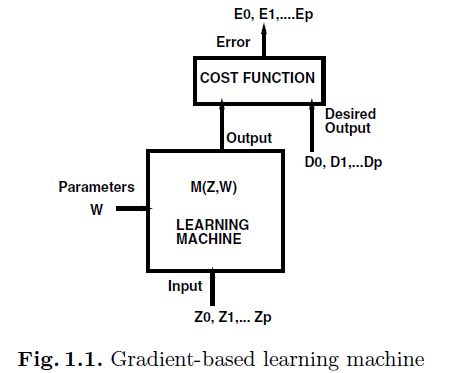
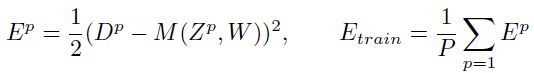
其中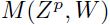 表示第P个输入的
表示第P个输入的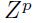 和
和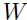 之间的函数,即预测函数,这里表示系统中可调节的参数。损失函数
之间的函数,即预测函数,这里表示系统中可调节的参数。损失函数 表示真实的目标和预测的目标之间的差距。其中
表示真实的目标和预测的目标之间的差距。其中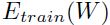 表示损失函数在训练集上的平均误差。最简单来说,学习问题就是找到参数能够让最小(个人:当然这里是最简单的理解,否则一味的最小化训练集的误差会造成过拟合的)。当然人们并不关心在训练集上的表现,而是看重模型系统在测试集上(与训练集不相交)的表现。最常用的损失函数就是均值平方误差了,也就是上面的这个函数(个人:当然还有交叉熵函数等等)。
表示损失函数在训练集上的平均误差。最简单来说,学习问题就是找到参数能够让最小(个人:当然这里是最简单的理解,否则一味的最小化训练集的误差会造成过拟合的)。当然人们并不关心在训练集上的表现,而是看重模型系统在测试集上(与训练集不相交)的表现。最常用的损失函数就是均值平方误差了,也就是上面的这个函数(个人:当然还有交叉熵函数等等)。
我们在关注如何提升最小化损失函数过程的同时也要注意最大化网络的泛化能力(即预测那些未出现在训练集中样本的目标的能力)。为了理解什么是泛化,先假设我们有一个数据集,而该数据集是某个理想函数的输入和输出。因为测量过程通常都是有噪音的,所以样本中自然会有错误。我们可以想像假设我们有多个数据集,每个数据集因为噪音和采样的点的不同而有着轻微的不同。每个这样的数据集在训练的网络的最小化的时候所得到的值都和理想(即真实的函数)函数都会有着些许差别。学习当然就是让某个具体的数据集在一个模型上最小化误差。而泛化技术是试图修正因为选择不同的数据集造成的引入网络的错误(个人:说白了就是不同的数据集上效果都好,那么泛化性能就是好)。
而且也有一些原理性的实验来分析最小化训练集误差的学习过程(有时候这个过程被称之为经验风险最小化)比如(《The Nature of Statistical Learning Theory》这本书)。这些原理性的分析都是基于将泛化误差分解成两项:偏置和方差。偏置指的是测量基于所有可能数据集上网络的输出与理想函数输出之间的差别(即高偏置就是欠拟合,说明模型根本不能代表理想的函数);而方差是指数据集之间的网络输出的变化(高方差就是过拟合,说明模型对某个或者某些数据集拟合的足够好,而对于其他数据集却表现很差)。在训练的早期自然是高偏置,因为网络的输出离理想函数还很远。而在训练的后期,随着网络学习的变好,离理想函数越来越近,然而,如果训练的太久,网络会把数据集中的噪音也给学了过来,这就是过学习了。所以当偏置和方差的都达到最小的时候,才是总的错误最小的时候。许多方法(比如早点停止、正则化)都是为了在使用BP的时候最大化网络泛化能力。
模型的选择、模型的结构和损失函数都是获得好泛化的关键。所以记得如果使用了错误的模型并且没有合适的模型选择,那么即使一个极好的最小化都没有任何帮助。事实上,一些作者认为不精确的最小化算法可以比精确的算法更好。
1.3、标准的BP
虽然本文中的技巧在多层前馈NN部分,不过大多数技巧仍然适用于基于梯度学习的方法。最简单的通过基于梯度学习的多层学习机就是模型的堆叠形式。每个模型都是为了执行函数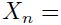
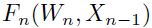 ,即通过下层模型的输出作为该层模型的输入然后计算得到该层的输出。而其中
,即通过下层模型的输出作为该层模型的输入然后计算得到该层的输出。而其中 就是输入的特征
就是输入的特征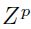 。如果
。如果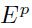 关于
关于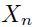 的偏导数已经知道了,那么关于
的偏导数已经知道了,那么关于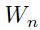 和
和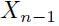 的偏导数可以通过后向递归得到:
的偏导数可以通过后向递归得到:
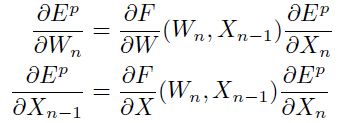
这里 是
是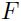 关于
关于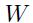 的jacobian矩阵上
的jacobian矩阵上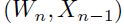 点的值。而
点的值。而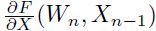 是关于
是关于 的。一个向量函数的jacobian是一个包含着所有输出关于所有输入的偏导数的矩阵(其实就是输出关于输入的一阶导数矩阵)。当将上面的等式逆序的用到模型中,从第N层到第1层,那么损失函数关于所有参数的偏导数都可以计算出来了。这种计算梯度的方法就叫做BP。
的。一个向量函数的jacobian是一个包含着所有输出关于所有输入的偏导数的矩阵(其实就是输出关于输入的一阶导数矩阵)。当将上面的等式逆序的用到模型中,从第N层到第1层,那么损失函数关于所有参数的偏导数都可以计算出来了。这种计算梯度的方法就叫做BP。
传统的多层NN就是上面系统的一个特殊形式,其中的模块是交替的一层一层累积起来的,先通过矩阵计算然后是进行sigmoid 函数的映射:
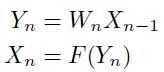
通过使用求导链式规则,可以求得如下的BP过程:
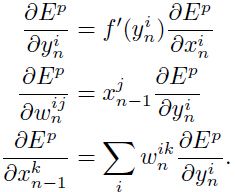
上面的式子写成矩阵形式为:

其中最简单的学习方法是梯度下降算法,其中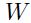 的迭代方式如下:
的迭代方式如下:
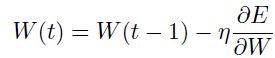 (1.3.11)
(1.3.11)
通常来说,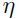 是学习率,最简单的情况就是其是一个标量常量,或者通过一些自适应算法让其变成变量。在其他方法(例如,牛顿法,拟牛顿法)中,这是一个对角矩阵的形式,或者是一个损失函数的逆hessian矩阵的估计(个人:即不能得到准确的,只是个逼近)形式。
是学习率,最简单的情况就是其是一个标量常量,或者通过一些自适应算法让其变成变量。在其他方法(例如,牛顿法,拟牛顿法)中,这是一个对角矩阵的形式,或者是一个损失函数的逆hessian矩阵的估计(个人:即不能得到准确的,只是个逼近)形式。
1.4、一些实践性的技巧
Bp在多层网络中是很慢的,特别是网络的损失表面(即损失函数在矩阵空间中形成的曲面)通常是非二次的、非凸的、高维并且有着许多的局部最小 和/或 平坦区域。没有公式说能够保证:a)网络可以收敛到一个很好的解;b)迅速收敛;3)每次都能收敛。本节就是介绍一些技巧来帮助我们找到一个好的解并且减少收敛所需的时间。
1.4.1 随机vs批量学习
随机(在线)学习是一次随机挑选一个样本,然后求梯度,更新权重;而批量学习是一次更新一批样本,然后求这些样本上的平均梯度,然后更新梯度:
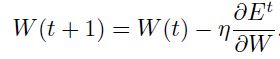
因为梯度的计算是有噪音的,所以权重的每次迭代中移动的可能不那么准确,即不是一直朝着最小值方向。不过正如我们将要说的,每次迭代中的“噪音”可以变成有利的。随机学习通常更适合于BP,因为:
a)随机学习通常比批量更快;
b)随机学习通常得到更好的解;
c)随机学习可以用来追踪样本的变化。
在大型冗余数据集上,随机学习通常比批量学习更快。原因很简单,假设我们有一个1000个样本的训练集,其中由100个不同类的副本组成,即每个类中的10个样本是完全一样的。对整个1000个样本求平均梯度,就等于求每个类中一个样本的梯度。所以批量梯度下降通常是比较浪费的,因为它在一个参数更新之前重复计算了10次;另一方面来说,随机梯度是迭代了了10次(epoch)完整的长为100的训练集。不过在实际中,很少样本会在一个数据集中出现2次,不过对于同类的样本来说其实还是挺相似的。例如在音素分类中,所有的音素样本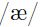 通常都会包含很多一样的信息,这也会造成冗余使得批量学习慢于在线(随机)学习。
通常都会包含很多一样的信息,这也会造成冗余使得批量学习慢于在线(随机)学习。
随机学习通常得到更好的解是因为迭代中存在的噪音。非线性网络通常有着多个不同深度的最小值。训练的目标就是为了找到其中的一个最小值。批量学习找到的最小值通常都是初始化时候的那个最小值区域;而随机学习中,迭代更新中的噪音会让权重从一个最小值区域跳到另一个最小值区域,可能是一个更深的局部最小。这在下面的参考文献[15][30]中被证明了。
随机学习在当被建模的函数在随着时间变化的时候也是很有用的,一个很常见的情况是在工业应用中,数据的分布是会随着时间的变化而变化的,比如采样数据用的机器的磨损。如果学习的算法没检测并且适应这种变化的话,那么就不可能很好的学到数据中的信息,并且会有较大的泛化误差出现。使用批量学习的话,变化是没法检测的,而且会得到相当坏的结果,就因为会有个平均操作;而对于在线学习来说,如果操作是恰当的,那么就会追踪这个变化,并且一直会有个很好的效果。
暂且不说随机学习,还是有很多原因使得我们会使用批量学习:
a)收敛的条件很容易理解;
b)许多技术只有在批量学习中才可以用来加速(例如共轭梯度);
c)在权重动态性和收敛比率的原理性分析更容易。
虽然在随机学习中噪音有利于跳过一些局部最小值,但是这些让找到更好的局部最小的噪音同样会阻止完整的收敛到最小值。而且会因为权重的动荡导致收敛停滞。动荡的程度取决于随机更新的噪音的程度。而且关于局部最小值的动荡的方差是与学习率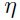 成比例的。为了减少这些动荡,我们可以减小(退火)学习率或者使用一个自适应batch_size。在文献[13,30,35,36]中,显示学习率的最优的退火策略是:
成比例的。为了减少这些动荡,我们可以减小(退火)学习率或者使用一个自适应batch_size。在文献[13,30,35,36]中,显示学习率的最优的退火策略是:
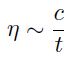
这里 是样本的个数(个人:指的是batch_size中样本的个数还是整个训练集样本的个数?,不过按照这里还未介绍mini-batch的顺序来说,这里指的是整个训练集的样本个数),
是样本的个数(个人:指的是batch_size中样本的个数还是整个训练集样本的个数?,不过按照这里还未介绍mini-batch的顺序来说,这里指的是整个训练集的样本个数),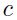 是常量。在实际操作中,这也许会太快了。
是常量。在实际操作中,这也许会太快了。
另一个移除噪音的方法就是使用“mini-batches”。先以一个小的batch size 开始,然后随着训练的次数增加,加大size。在文献[25,31]中有较详细的说明,然而,决定增大多少size,和何时增大并且哪些样本该被放入某个batch都是很困难的。在随机学习中学习率的size的影响就和mini batch 有关的size一样。
不过移除数据中的噪音有时候不那么重要,因为我们需要考虑到泛化问题,而且在噪音真的具备影响力之前还有很长的时间。批量学习的另一个优势在于它可以使用二阶方法来加速学习过程。二阶方法加速是不止使用梯度而是使用损失表面的曲率来计算的。在给定曲率的基础上,就可以计算得到真实最小值的近似位置了。
不过总的来说,在大规模数据集的情况下使用随机学习还是更好,因为它更快。
1.4.2 打乱样本
网络可以从最不期望的样本中最快的学习,所以每次迭代的时候选择一个与系统最不相似的样本是最明智的。不过这只适用于随机学习,因为输入的顺序是无关紧要的(在batch中梯度是需要相加然后求平均的,当梯度的值存在一个明显的范围的时候,顺序可能会被舍入误差影响到)。当然没有简单的方法来辨识哪个输入的信息量更多,不过一个非常简单的技巧就是从不同类中挑选后续的样本,因为来自一个类的样本之间或多或少会包含更多的相似性信息。
另一个判断一个训练样本包含多少新信息的方法是 通过将其作为网络的输入检查其网络预测输出与目标值之间的误差。一个较大的误差意味着该输入样本没有被网络学到,所以其包含着较多的信息。所以可以将该输入的出现频率提高。这里的较大时相对于所有的其他训练样本来说的。当网络训练的时候,这些相关的误差是会变的,同样的对于某个具体的输入样本来说其出现的频率也是要变得。一个修改每个样本出现次数的概率的方法叫做强调方案(emphasizing scheme)
使用最大信息内容来选择样本:
a)打乱训练集使其后续的训练样本不再(几乎)有相同的类别;
b)让能够生成更大误差的样本的出现频率大于能够生成更小误差的样本
值得注意的是,当微扰动正常的输入样本的频率的时候需要特别的小心,因为这会改变网络在不同样本上的相对重要性。这有好有坏,比如对于离群点来说,这就是坏的,因为离群点本来就是会产生更大误差的,而其出现的次数不能被增加。另一方面来说,该技术对于,例如音素识别中出现次数较低的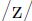 来说,有助于提升模型的性能。
来说,有助于提升模型的性能。
1.4.3 归一化输入样本(0均值,1 方差)
如果训练集中的每个输入变量的均值接近于0的话,收敛通常可以更快。例如,假设所有的输入都是正的。对于第一层权重层中的某个节点上关联的权重,他们更新都是与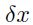 成比例的,这里
成比例的,这里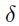 是一个在该节点上的(标量)误差,而
是一个在该节点上的(标量)误差,而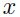 是输入向量。当输入向量的所有成分都是正的时候,那么该节点对应的权重的所有更新都是有着相同的符号(
是输入向量。当输入向量的所有成分都是正的时候,那么该节点对应的权重的所有更新都是有着相同的符号(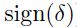 )。也就是说,这些权重在给定的一个样本的情况下:要不都减少,要不都上升。所以如果一个权重向量必须改变方向,到达最优解的话,那么就只能通过 Z字形来完成了,明显这会很慢。
)。也就是说,这些权重在给定的一个样本的情况下:要不都减少,要不都上升。所以如果一个权重向量必须改变方向,到达最优解的话,那么就只能通过 Z字形来完成了,明显这会很慢。
上面的例子中,输入都是正的,然而,通常来说,任何输入向量的均值平移都会让更新以某个方向进行偏移,所以这会减慢学习。所以最好的平移输入的方法就是将训练集的均值尽可能的接近0。该策略应该用到所有的层上,因为我们希望节点的输出的均值也尽可能的接近0,因为这些输出就是下一层的输入。这里先介绍下输入转换。
不止是输入如上那样平移有助于加速收敛,而且可以通过缩放使得所有的样本都有相同的协方差(covariance), :
:
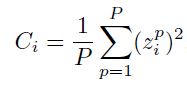
这里 P 是训练样本的个数,是第 i 个输入变量的协方差, 是第 p 个训练样本的第 i 个成分。缩放有助于加速学习是因为它能够平衡连接到输入节点的权重的学习速率。该协方差的值应该匹配所使用的sigmoid函数。对于给定的下面的sigmoid,协方差的值选1 是一个好选择。
是第 p 个训练样本的第 i 个成分。缩放有助于加速学习是因为它能够平衡连接到输入节点的权重的学习速率。该协方差的值应该匹配所使用的sigmoid函数。对于给定的下面的sigmoid,协方差的值选1 是一个好选择。
不过当已经知道某些输入重要性明显不如比其他输入时,就不能缩放所有的协方差到相同的值。在这样的情况下,将较不重要的输入进行缩放使得它们对于学习过程来说不那么显眼是有利的。(个人:其实就是对不重要的输入进行缩放就行)
转换输入样本:
a)基于整个训练集对每个输入向量的均值应该接近于0;
b)将输入变量进行缩放使其的协方差都是一样的;
c) 如果可以的话,输入变量之间应该不相关.
上面的a 和 b 执行起来还是比较简单的。剩下的一个相当的有效,不过却比较难执行。考虑图1.2的那个简单的网络结构:
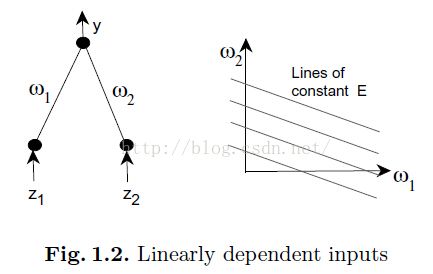
如果输入是不相关的,那么在计算当最小化误差时候的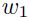 值就不需要考虑
值就不需要考虑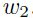 了(即可以独立考虑)。换句话说,这两个变量是独立的(系统的等式是对角化的);如果输入是相关的,一个解决的时候就必须捎带上另一个,也就是两个必须同时考虑,这是相比更困难的。PCA(也被称之为karhunen -loeve 扩展),可以被用来移除输入中的线性相关性。
了(即可以独立考虑)。换句话说,这两个变量是独立的(系统的等式是对角化的);如果输入是相关的,一个解决的时候就必须捎带上另一个,也就是两个必须同时考虑,这是相比更困难的。PCA(也被称之为karhunen -loeve 扩展),可以被用来移除输入中的线性相关性。
如果输入是线性依赖的(相关性的极端例子)也可能产生依赖性使得学习减慢。假如一个输入总是另一个输入的两倍(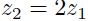 )。该网络的输出总是沿着线:
)。该网络的输出总是沿着线: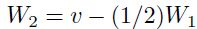 ,这里
,这里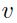 是一个常量。所以梯度为0的时候是沿着图1.2中的方向的,移动这些线对于学习来说没有什么影响。这里,我们是试图在2D中解决一个1D问题。理想情况下我们想移除其中一个输入从而降低网络的size,从而能够简化问题。
是一个常量。所以梯度为0的时候是沿着图1.2中的方向的,移动这些线对于学习来说没有什么影响。这里,我们是试图在2D中解决一个1D问题。理想情况下我们想移除其中一个输入从而降低网络的size,从而能够简化问题。
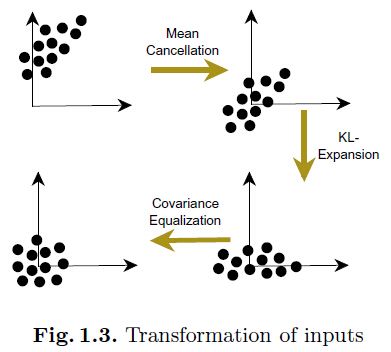
图1.3介绍了整个输入转换的过程,第(1)布是将输入平移到均值为0的地方;(2)是解相关输入;(3)是使协方差相等:
1.4.4 sigmoid
非线性激活函数可以给网络非线性的能力。最常用的激活函数就是sigmoid,其中最常用的例子就是标准的逻辑函数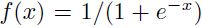 ,和双曲线正切
,和双曲线正切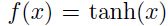 ,如图1.4(个人:当然12年hinton提出的relu,和之后的prelu等等其他激活函数)sigmoid是原点对称的(图1.4b),所以这也是一个需要输入必须归一化的原因:
,如图1.4(个人:当然12年hinton提出的relu,和之后的prelu等等其他激活函数)sigmoid是原点对称的(图1.4b),所以这也是一个需要输入必须归一化的原因:
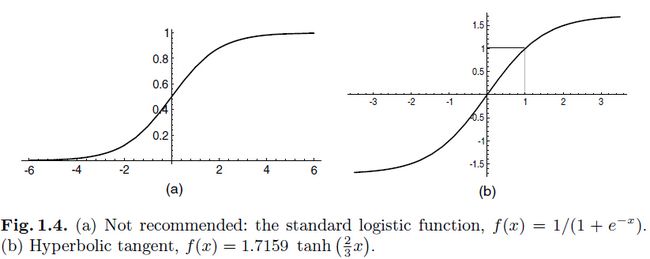
因为他们生成的输出的均值通常都是接近于0 的。而对于逻辑函数来说,输出总是正数,所以输出得到的值的均值总是为正的。(个人:即使用逻辑函数得到的输出的均值总是偏向正的,这也是一个为什么不推荐而 推荐正切函数的原因,当然现在大都使用relu激活函数)
sigmoid:
a)对称的sigmoid例如双曲线正切通常比标准的逻辑函数收敛更快;
b)一个推荐的sigmoid为: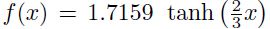 。因为该tanh函数有时候计算代价比较大,可以通过使用一个多项式系数来逼近代替它。详细内容查阅参考文献[19]
。因为该tanh函数有时候计算代价比较大,可以通过使用一个多项式系数来逼近代替它。详细内容查阅参考文献[19]
c)有时候增加一个小的线性项是有帮助的,例如
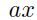 来避免平坦区域。
来避免平坦区域。
选择上面推荐的sigmoid中的约束,是因为就算使用转换后的输入,输出的方差还是会接近于1 的,因为sigmoi的有效区域大多是接近1的(个人:因为在1的附近 导数变化才大)。具体来说,该sigmoid的特性为:a)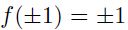 ;b)二阶导数在 x =1 的时候得到最大值;c)有效的区域接近于1.
;b)二阶导数在 x =1 的时候得到最大值;c)有效的区域接近于1.
使用对称sigmoid函数的一个潜在的问题是该误差表面可以在接近于原点的时候非常平坦。基于此,最好避免使用非常小的权重来初始化。而且因为sigmoid的饱和问题,误差表面同样是平坦的。通过增加一个小的线性项有时候有助于避免平坦区域
1.4.5 选择目标值
在分类问题中,目标值通常是二值的(即,+1 ,-1)。通常明智的是目标值设置成sigmoid的渐近线。不过这会有几个缺陷。
首先,导致学习不稳定。训练的过程是试图让输出尽可能的接近目标值,而这只能渐进的实现。所以,当sigmoid的导数接近0时,权重(输出和甚至隐藏层)会变得越来越大,非常大的权重虽然会增大梯度,然而这些梯度随后被一个很小的sigmoid导数相乘(当加一个扭曲项到sigmoid的时候除外,即如上面的,在tanh后面增加一个线性项)生成一个接近于0的权重更新项,所以权重就卡住了。
其次,当输出饱和的时候,网络并没有任何有关置信程度的指示。当一个输入样本落在了决策边缘附近时,输出的类别是不确定的。理想情况下,这应该输出一个介于两个类之间的输出值,即,不是在渐近线附近。然而,大的权重倾向于让所有的输出都位于sigmoid的尾巴位置,而不管是否确定。所以,网络会预测一个错误的类别而没有给出任何有关该结果是低置信度的指示。大的权重会饱和该节点使得没法区分正常和异常的样本。
一个解决上面的问题的方法是让目标值位于sigmoid的范围之内,而不是在渐近线的值上。然而,必须小心确保该节点不是被限制成sigmoid的线性部分。设置目标值为sigmoid 的二阶导数的最大值上的点是最好的方法了,这有了非线性的优势而且没有饱和该sigmoid。这也是另一个推荐图1.4b的sogmoid函数的原因。它的最大二阶导数值在+1和-1上(对应着分类问题中二值分类)。
目标:
选择目标值为sigmoid的二阶导数最大值上的点有助于避免输出单元的饱和。
1.4.6 权重初始化
初始化的权重的值对于训练的过程来说影响是很明显的。权重应该被随机选择,不过这时候sigmoid主要在它的线性区域上被激活。如果权重都非常大,那么sigmoid将会饱和并生成很小的梯度,这会让学习慢下来。如果权重非常小,那么梯度同样也是很小的。能够覆盖sigmoid的线性区域的中等权重的优势有:a)梯度足够大使得学习能够继续下去;b)网络会学到更复杂的非线性部分前的线性部分。
达到这样的目的,需要协调训练集归一化、sigmoid的选择、权重初始化选择之间的关系。我们在初始时,会要求 每个节点输出的分布的标准差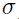 都接近1,这可以通过在开始对训练集进行归一化实现。为了使得第一层隐藏层输出的标准差接近1 ,我们只需要使用之前推荐的sigmoid,然后输入到sigmoid的值的标准差
都接近1,这可以通过在开始对训练集进行归一化实现。为了使得第一层隐藏层输出的标准差接近1 ,我们只需要使用之前推荐的sigmoid,然后输入到sigmoid的值的标准差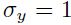 。假设一个单元的输入
。假设一个单元的输入 是不相关的,并且方差为1,那么该单元的权重的标准差为:
是不相关的,并且方差为1,那么该单元的权重的标准差为:
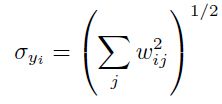
所以,为了确保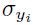 逼近1,权重应该是从一个有着0均值,标准差为下面式子的分布中随机采样得到的:
逼近1,权重应该是从一个有着0均值,标准差为下面式子的分布中随机采样得到的:
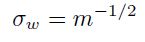
这里 m 是指输入到该单元的权重个数。
初始化权重:
假设:a)训练集已经归一化了,并且b)选择的是图1.4b的sigmoid函数。那么权重应该如上面那样随机采样得到,即取均匀分布,其中的上下限为:[-1/sqrt(m),1/sqrt(m) ]。
1.4.7 选择学习率
存在至少一种原理良好的方法(在下面1.9.2部分介绍)来计算理想的学习率。许多其他方法(大多数更像是经验式的)在以往文献中提出了很多方法用来自动的调节学习率。大多数的方法都会选择在权重向量“震荡”的时候降低学习率,并且在权重向量有了一段较为平稳的方向时升高学习率。这些方法的一个重要的问题在于他们不适合随机梯度或者在线学习,因为这时候权重向量是一直在震荡的。
在基于选择一个全局学习率的基础上,可以对每个独立的权重都挑选一个不同的学习率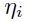 ,以此来改善收敛情况。在基于计算二阶导数的基础上,一个原理良好的方法在后面的1.9.1中会有介绍。这里体现的想法是需要让网络中所有的权重都已大致相同速度进行收敛。
,以此来改善收敛情况。在基于计算二阶导数的基础上,一个原理良好的方法在后面的1.9.1中会有介绍。这里体现的想法是需要让网络中所有的权重都已大致相同速度进行收敛。
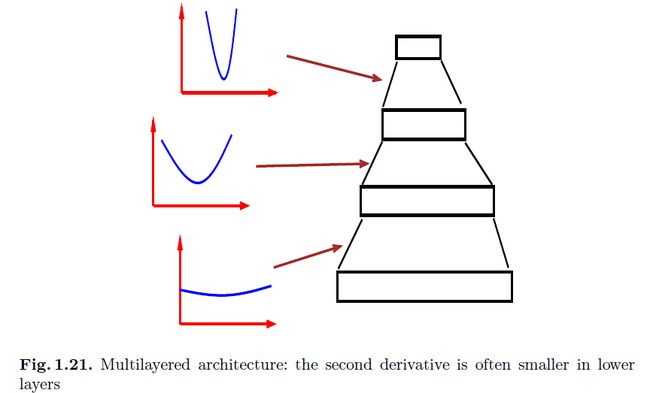
基于误差表面的曲面基础上,许多权重需要一个小的学习率来避免发散,同时其他权重需要一个大的学习率来以合理的速度收敛。因此,低层中的学习率应该要大于高层中的学习率(下面的图1.21)。这基于的事实是:在大多数nn结构中,损失函数关于低层的权重的二阶导数要通常小于高层的。
如果共享的权重,如延时nn(tdnn)或者cnn中那样,学习率应该与共享该权重的连接数的平方根成比例,因为我们知道梯度或多或少是一个独立项的和。
平衡学习速度:
a)给每个权重一个自己的学习率;
b)学习率应该与该单元的fan-in个数的平方根成比例;
c)更低层的权重通常比更高层的权重要大
其他加速收敛的技巧有:
动量:
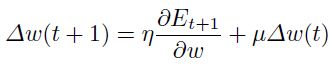
当损失表面是高度非球形的时候,可以提升速度,因为它会衰减高曲率方向上的步长,从而产生更大的有效的沿着低曲率方向上的学习率(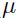 表示动量项的强度)。已经被证实动量项通常有助于在批量学习中而不是随机学习中,不过暂时没有系统性研究的作者(本论文发布于1998年,所以这是那时候的事情)。
表示动量项的强度)。已经被证实动量项通常有助于在批量学习中而不是随机学习中,不过暂时没有系统性研究的作者(本论文发布于1998年,所以这是那时候的事情)。
自适应学习率。
有包括Sompolinsky , Darken & Moody , Sutton , Murata .等人提出了一些自动调节学习率的方法 (参考文献[9,38,28,16]),通过基于误差增加或减少学习率来控制收敛的速度。并基于假设以下事实来探讨学习率自适应算法:a)hessian的最小特征值明显要小于第二小的特征值;b)在经过大量的迭代之后,参数向量 会沿着hessian的最小特征向量的方向达到最小。基于这些约束下,所需要计算的参数可以作为一维来处理,并且最小的特征向量可以通过如下式子计算(大量的迭代,如图1.5)得到:
会沿着hessian的最小特征向量的方向达到最小。基于这些约束下,所需要计算的参数可以作为一维来处理,并且最小的特征向量可以通过如下式子计算(大量的迭代,如图1.5)得到:
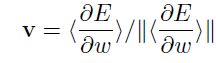
这里 表示
表示 范式,所以我们可以使用到逼近的最小值特征向量
范式,所以我们可以使用到逼近的最小值特征向量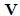 的投影作为衡量到最小值的距离(1维的):
的投影作为衡量到最小值的距离(1维的):
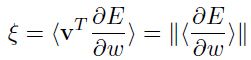
该距离可以用来控制学习率(可参阅参考文献【28】):
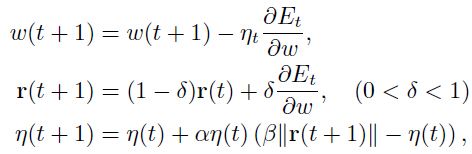 (1.4.7.4、1.4.7.5、1.4.7.6)
(1.4.7.4、1.4.7.5、1.4.7.6)
这里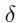 控制着leak size of average(个人:暂时不知道怎么翻译,不过应该是说逼近值与真实值之间的差距吧),
控制着leak size of average(个人:暂时不知道怎么翻译,不过应该是说逼近值与真实值之间的差距吧),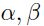 是常量,并且
是常量,并且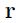 作为辅助变量来计算梯度
作为辅助变量来计算梯度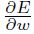 的leaky average。
的leaky average。
这些规则是很容易计算的,并且容易实现。我们只需要保持追踪一个额外的向量(式子 1.4.7.5):平均梯度。随后该向量的范数可以用来控制学习率的size(式子1.4.7.6)该算法的动机在于:远离最小值的时候(大距离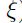 )生成一个大步长;靠近最小值的时候退火该学习率(参考文献[10])。
)生成一个大步长;靠近最小值的时候退火该学习率(参考文献[10])。
1.4.8 径向基函数vs sigmoid 单元
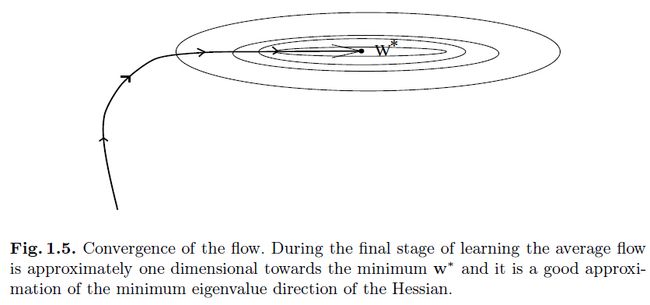
虽然大部分系统使用的都是先点积然后是sigmoid,不过还是有许多其他类型的神经元(或者层)。一个通常的替代方法是径向基网络。在RBF网络中(参考文献【5,7,26,32】),权重和输入向量的点积被换成了输入和权重之间的欧式距离,sigmoid也换成了一个指数函数。输出的激活计算形式为(对于一个输出):
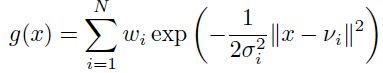
这里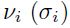 是第 i 个高斯的均值(标准差)。这些单元可以被标准单元替换或者共存,他们通常可以通过梯度下降无监督聚类一起来训练,并用来决定RBF单元的均值和方差。
是第 i 个高斯的均值(标准差)。这些单元可以被标准单元替换或者共存,他们通常可以通过梯度下降无监督聚类一起来训练,并用来决定RBF单元的均值和方差。
不同于sigmoidal的单元能够覆盖整个空间,一个RBF单元只能覆盖输入空间的一个小的局部区域。这带来的优势就是学习可以更快。RBF单元通常可以用来形成一个更好的基函数的集合,并用来对输入空间进行建模,这比sigmoid单元要好,虽然这是高度问题依赖的。不过另一方面来说,RBF的局部特性在高维空间中可能是个劣势,因为许多单元需要覆盖整个空间。所以通常来说RBF单元更适合在高层(低维度),而sigmoid适合在低层(高维度)中。
1.5 梯度下降的收敛
1.5.1 一个简短的原理介绍
我们先简单介绍下对于一维的梯度下降更新式子:
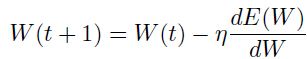 (1.5.1.1)
(1.5.1.1)
我们想要知道学习率是如何影响收敛和学习速率的。图1.6可以看到几个不同的学习率下的学习行为,这期间权重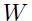 都是已经朝着局部最小前进了:
都是已经朝着局部最小前进了:
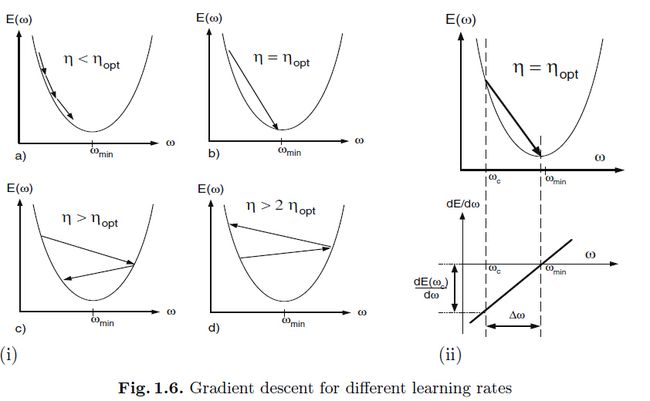
对于一维的来说,是很容易定义最优学习率 的,就如图1.6b那样准确的可以一步到位。如果
的,就如图1.6b那样准确的可以一步到位。如果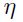 小于那么,步长就比较小了,然后就需要好几个时间步来收敛,如果位于和 2*之间,那么权重将会围绕着
小于那么,步长就比较小了,然后就需要好几个时间步来收敛,如果位于和 2*之间,那么权重将会围绕着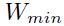 盘旋,不过最后还是会收敛的(图1.6c)如果大于其两倍(图1.6d),那么步长会大到权重最后远离,导致结果发散。
盘旋,不过最后还是会收敛的(图1.6c)如果大于其两倍(图1.6d),那么步长会大到权重最后远离,导致结果发散。
那么到底最优解是多少呢?我们来首先考虑1维的情况,假设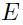 可以通过二次函数逼近,可以通过在当前权重
可以通过二次函数逼近,可以通过在当前权重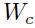 的泰勒展开式的一阶展开求导得到:
的泰勒展开式的一阶展开求导得到:
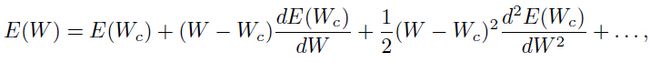 (1.5.1.2)
(1.5.1.2)
这里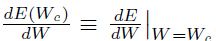 。如果是二次的,那么其二阶导数就是常量,而且更高阶的导数项就是为0。那么将两边关于进行求导得到:
。如果是二次的,那么其二阶导数就是常量,而且更高阶的导数项就是为0。那么将两边关于进行求导得到:
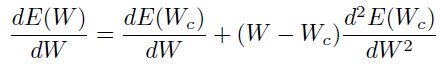 (1.5.1.3)
(1.5.1.3)
当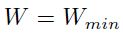 ,并且
,并且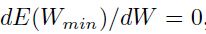 。得到的解为:
。得到的解为:
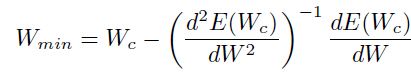 (1.5.1.4)
(1.5.1.4)
通过(1.5.1.1)式子,我们可以一步就得到最优解:
 (1.5.1.5)
(1.5.1.5)
也许一个更简单获得该结果的方法如图1.6(ii),其中下面的图:的梯度为的函数。因为是二次的,梯度就是简单的一条直线,其中在最小值的时候值为0,并且在当前权重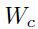 上时是
上时是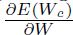 。
。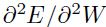 是该线的斜率,并且可以使用标准斜率方程来计算:
是该线的斜率,并且可以使用标准斜率方程来计算:
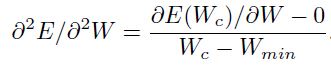
通过计算得到式子(1.5.1.4)。
虽然最速收敛的学习率为,最大学习率可以在不引起发散的时候使用(图1.6(i)d):
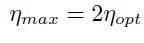
如果不是准确的二次的话,那么式子(1.5.1.2)中更高阶的项就不会等于0 了,所以式子(1.5.1.4)只是个近似而已。这种情况下,当使用的时候,需要多次迭代才能定位最小值,不过收敛还是很快的。
在多维情况中,决定的值是一个更加复杂的事情,因为(1.5.1.5)式子的右边是一个逆矩阵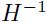 ,而且
,而且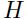 被称之为hessian,其中的成分为:
被称之为hessian,其中的成分为:
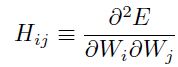
这里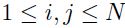 ,而且
,而且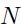 等于权重的总的数量。
等于权重的总的数量。
是关于的曲率的测量。在二维情况中,关于二次损失的常量的线围成的是如图1.7中的椭圆:
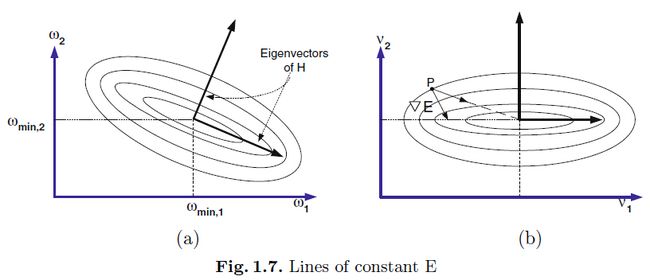
的特征向量为其中的主轴和次轴的方向。特征值可以用来计算对应特征方向上的的坡度。
例子。在最小均方算法中(LMS),我们可以得到一个单层线性网络,其中的误差函数为:
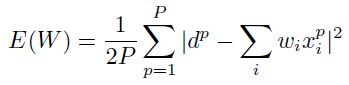
这里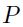 是训练向量的个数。这时候的hessian和输入的协方差居住一样:
是训练向量的个数。这时候的hessian和输入的协方差居住一样:
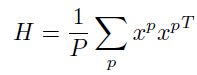
所以,如图1.8中,的每个特征值同样可以用来测量协方差或者沿着对应特征方向上输入的传播(速度):
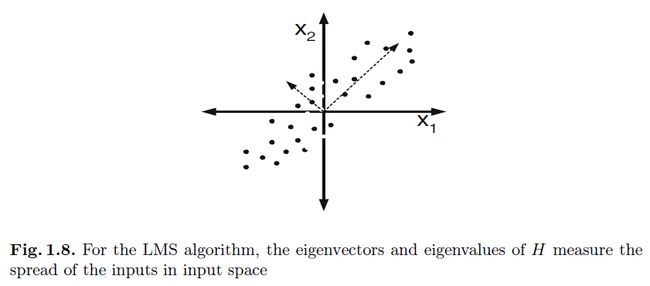
在多维中使用一个标量学习率本身就是有问题的。我们希望学习率能够足够大,这样学习的速度就会很快,而如果太大的话那么权重最好却会沿着步长的方向发散。为了更详细的说明该过程,我们和上面一样对进行扩展。不过这次是位于最小值点上:
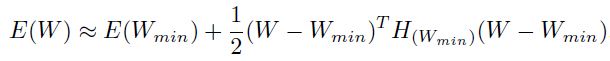
对上面式子进行微分,然后使用(1.5.1.1)的更新式子,得到如下结果:
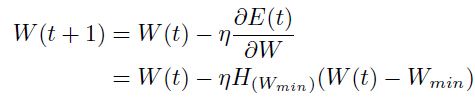
从两边减去 ,得到:
,得到:
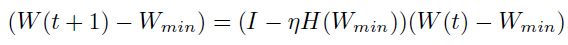
如果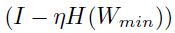 是一个变换矩阵,且总是会缩小一个向量(即它的特征值都小于1)那么更新式子就会收敛了。
是一个变换矩阵,且总是会缩小一个向量(即它的特征值都小于1)那么更新式子就会收敛了。
这有助于选择学习率吗?理想环境下,我们想要在不同的特征方向上有着不同的学习率。如果说特征方向是以权重为坐标轴的方向的话,这还是挺简单的。在这种情况下,权重都是不耦合的,所以我们可以对每个权重基于他们对应的特征值指定它们自己的学习率。然而,如果权重是耦合的,那么我们首先需要旋转,使得对角化,即坐标轴是沿着特征方向的(图1.7b)。这就是之前hessian讨论的需要对角化的目的。
假设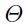 是旋转矩阵:
是旋转矩阵:
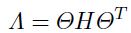 (1.5.1.14)
(1.5.1.14)
这里 是对角化矩阵,并且
是对角化矩阵,并且 。损失函数可以写成:
。损失函数可以写成:
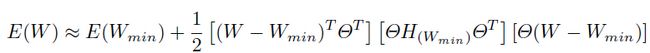
将坐标系变换成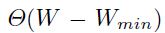 ,可以简化上面的式子得到:
,可以简化上面的式子得到:
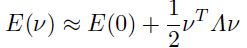
然后转换后的更新式子就变成了:
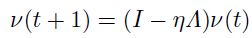
注意这里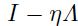 是对角化的,其中的对角成分为
是对角化的,其中的对角成分为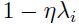 。当
。当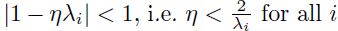 时, 该等式会收敛。如果对于所有的权重限制成只有一个单一的标量学习率,那么我们必须满足:
时, 该等式会收敛。如果对于所有的权重限制成只有一个单一的标量学习率,那么我们必须满足:
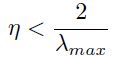
为了防止发散,这里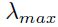 是的最大特征值。对于最快收敛来说:
是的最大特征值。对于最快收敛来说:
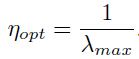
如果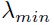 比小很多,那么沿着方向上收敛就是很慢的。事实上,收敛时间是与条件数
比小很多,那么沿着方向上收敛就是很慢的。事实上,收敛时间是与条件数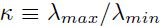 成比例的,所以最好的就是传播的特征值尽可能小。
成比例的,所以最好的就是传播的特征值尽可能小。
然而,因为我们将旋转成与坐标轴对齐,所以事实上包含了 N 个独立的1 维等式。所以我们可以对每个独立的权重选择不同的学习率。我们发现第 i 个权重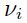 的最优的学习率是
的最优的学习率是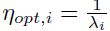 。
。
1.5.2 例子讲解
线性网络
图1.10中是从两个高斯分布(它们的中心为(-0.4,-0.8)和(0.4和0.8))上采样得到的100个样本。该协方差矩阵的特征值分别是0.84和0.036。我们训练的线性网络结构为2个输入、一个输出、2个权重、1个偏置(图1.9).使用批量模式的LMS算法。图1.11中为当训练的时候使用的学习率分别为1.5和2.5时候的权重轨迹和误差。注意到学习率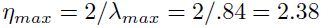 会导致发散,所以2.5的时候更会发散。
会导致发散,所以2.5的时候更会发散。
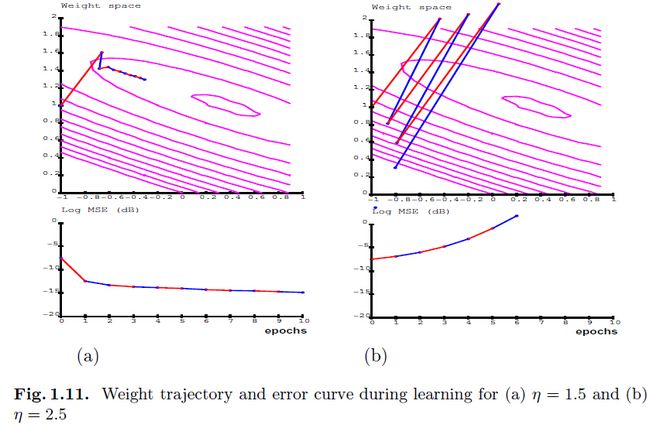
图1.12中的是基于相同的样本,使用随机学习而不是批量模式的学习。这里,使用的学习率是0.2。我们可以看到该轨迹比批量模式有更多的噪音,这是因为一次迭代中梯度只算一次。该损失是关于epoch的函数。一个epoch简单的定义成100个输入表征,对于随机学习来说,对应这100个权重的更新。在批量模式中,一个epoch对应一次权重更新。
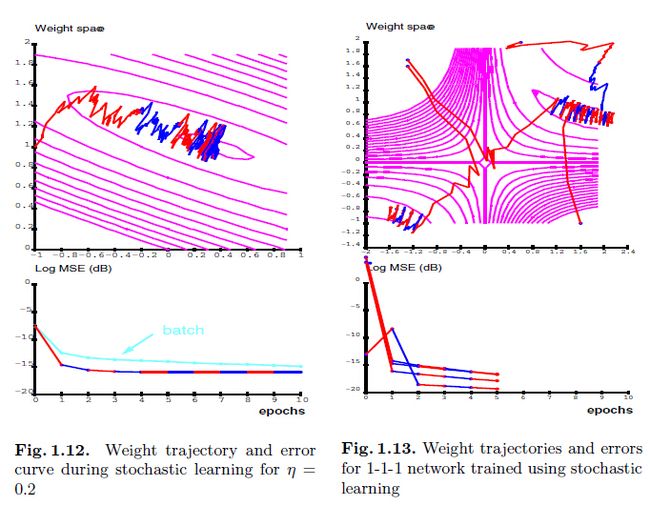
多层网络
图1.14中为一个非常简单的多层网络的结构:1个输入节点、1个隐藏节点、1个输出节点。有2个权重和2个偏置。激活函数为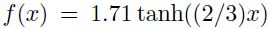 。
。

训练集包含了来自2个类中的10个样本。两个类都是高斯分布,他们的标准差为0.4。类1的均值为-1,类2的均值为+1。类1的目标值为-1,类2的目标值为+1.图1.13是随机学习的轨迹。
1.5.3 重新审视输入转换和误差表面转换
我们可以使用之前介绍的那些结果来决定之前使用的那几个技巧。
从输入变量中减去均值
该技巧是因为在输入变量中的非0均值会生成一个非常大的特征值。这意味着条件数也会很大,那么损失表面在某些方向上会很深,而在其他方向上很浅,使得收敛会非常慢。该解决方法就是简单的通过减去他们的均值来预处理输入。
对于一个单一的线性神经元,hessian的特征向量(已经减去均值了)指向的是训练向量群的主轴(图1.8).在输入空间中每个不同的方向上有着较大变化的传播的输入就会有着较大的条件数,并且学习很慢。所以才需要下面这个技巧
对输入变量的方差归一化
如果输入变量都是相关的,那么就没法让误差表面成为球面,不过这可能会降低它的中心偏移程度。相关的输入变量通常会导致的特征向量旋转到远离坐标轴(图1.7a vs 1.7b)所以权重更新是不会解耦的。解耦的权重可以通过“一个权重一个学习率”的方法优化,所以,接着有下面的技巧:
解相关输入变量
现在,假设一个神经元的输入变量都是不相关的,那么该神经元的hessian就是对角化的,并且它的特征值指向坐标轴的方向。在这种情况下,梯度就不是最理想的下降方向了,如图1.7b。在点P上,该箭头指向的梯度不是指向最小值的。然而,如果我们让每个权重有其自己的学习率(等于对应特征值的逆),然后下降的方向就是该点的其他箭头指向最小值的方向。
对每个权重使用独立的学习率
1.6 传统的二阶优化方法
在下面中,我们就简单的介绍下牛顿,共轭梯度、高斯牛顿、levenberg marquardt 和拟牛顿(BFGS)方法(参考文献[3,5,11,34]):
1.6.1 牛顿算法
为了理解Newton的方法,先概括下1.5.1部分的结果。假设有个二次损失函数 (1.5.1.1)如图1.6(ii)描述的那样,我们可以按照等式(1.5.1.1)-(1.5.1.3)进行权重更新:
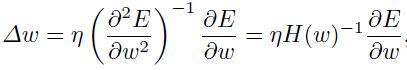 (1.6.1.1)
(1.6.1.1)
因为在真实问题上通常不是二次的,所以学习率的范围为 ,当然在这个等式中,hessian矩阵通常也考虑进去了。如果误差函数是二次的,那么就能一步收敛了。
,当然在这个等式中,hessian矩阵通常也考虑进去了。如果误差函数是二次的,那么就能一步收敛了。
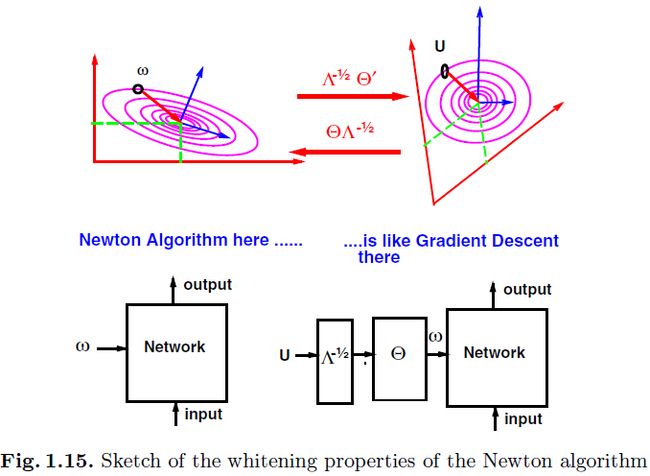
通常来说,最小值周围的能量表面是椭圆的,或者极端情况像一个taco 壳,这些都取决于hessian的情况。一个白化操作(在信号处理的文献29中众所周知)可以将该椭圆形状变化成球形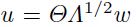 (图1.15和式子1.5.1.14)。所以式子(1.6.1.1)中的逆hessian在局部的错误表面上基本上就是球形的。后面的两个方法等效于:a)在一个未变换的权重空间中使用newton算法;b)在白化的坐标系系统中使用常用的梯度下降(图1.15)(参考文献【19】)
(图1.15和式子1.5.1.14)。所以式子(1.6.1.1)中的逆hessian在局部的错误表面上基本上就是球形的。后面的两个方法等效于:a)在一个未变换的权重空间中使用newton算法;b)在白化的坐标系系统中使用常用的梯度下降(图1.15)(参考文献【19】)
总结下,如果误差函数是二次的,那么就可以使用newton算法一次收敛,而且(不同于梯度下降)不受到关于输入向量的线性变换的影响。这也就是说收敛的时间不受到输入向量平移、缩放、旋转的影响。不过这里最大的缺点就是,一个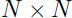 的hessian矩阵必须要存储起来,而且要求逆,这在每次迭代的时候的复杂度为
的hessian矩阵必须要存储起来,而且要求逆,这在每次迭代的时候的复杂度为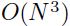 ,所以在变量数量增多之后该方法就不那么实用了。因为误差函数通常不是二次的,所以不敢保证能够收敛。如果hessian不是正定的(如果它有一些0或者甚至是负的特征值,那么对应的就是在误差表面平坦或者某些方向上是向下弯曲的),那么newton算法就会发散了,所以hessian必须是正定的。当然多层网络的hessian矩阵通常不是每个地方都是正定的。因为这些原因,newton算法的原始形态是不能用来给通用的nn学习的。然而这还是给更复杂的算法提供了很好的见解,如下算法
,所以在变量数量增多之后该方法就不那么实用了。因为误差函数通常不是二次的,所以不敢保证能够收敛。如果hessian不是正定的(如果它有一些0或者甚至是负的特征值,那么对应的就是在误差表面平坦或者某些方向上是向下弯曲的),那么newton算法就会发散了,所以hessian必须是正定的。当然多层网络的hessian矩阵通常不是每个地方都是正定的。因为这些原因,newton算法的原始形态是不能用来给通用的nn学习的。然而这还是给更复杂的算法提供了很好的见解,如下算法
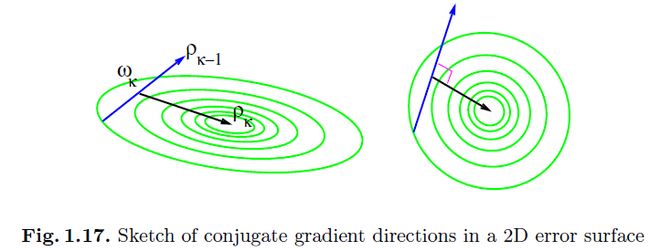
1.6.2 共轭梯度
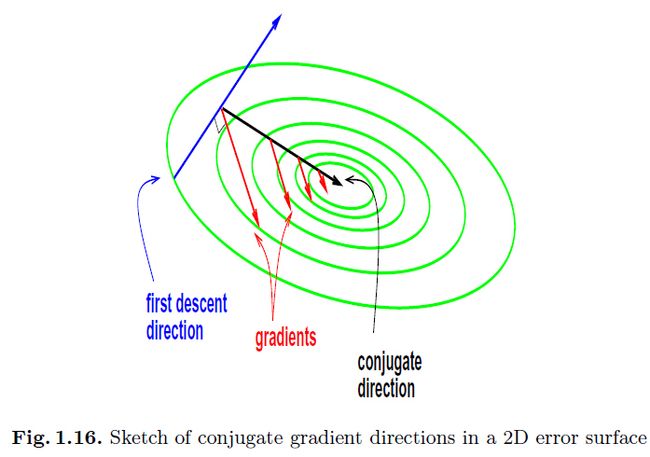
在共轭梯度优化中有几个重要的特性:a)这是一个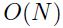 方法;b)不需要显式的使用hessian;c)试图在基于之前迭代得到的结果的基础上,最小的破坏之前的结果并寻找下降方向;d)使用线性搜索;e)最重要的是,只能用在批量学习上。
方法;b)不需要显式的使用hessian;c)试图在基于之前迭代得到的结果的基础上,最小的破坏之前的结果并寻找下降方向;d)使用线性搜索;e)最重要的是,只能用在批量学习上。
第三个特性呈现图1.16中。假设我们挑选了一个下降方向,即,梯度。然后我们沿着这个方向进行最小化(线性搜索)。随后,我们接着找另一个方向,该方向上梯度不会改变它的方向,不过会改变它的length(共轭方向),因为沿着这个方向移动不会破坏之前迭代得到的结果。在第k 次迭代的下降方向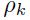 的计算如下:
的计算如下:
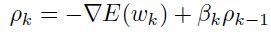 (1.6.2.1)
(1.6.2.1)
这里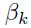 的选择式子有下面两种:fletcher 和reeves(参考文献 34):
的选择式子有下面两种:fletcher 和reeves(参考文献 34):
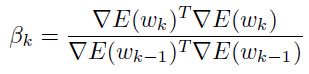
或者polak 和 ribiere:
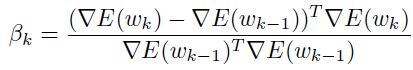
如果满足下面的式子,那么两个方向 和
和 就是共轭的:
就是共轭的:
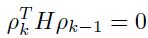
即共轭方向是在同一个hessian矩阵的空间中的正交方向(图1.17).对于收敛来说,在两个选择中重要的就是它们都是一个很好的线性搜索过程。对于一个完美的有着N个变量的二次函数,可以证明只要N步就能收敛。对于非二次函数来说,polak 和ribiere 的选择更加的鲁棒。共轭梯度(1.6.2.1)同样可以被看成是在nn训练中选择的动量项。该方法在当数据量中等,并且数据中冗余不太多时,使用多层网络可以很成功。通常的应用范围包括函数逼近、机器人控制[39]、时序预测和其他想要高准确的的实值问题等。不过在大的并且冗余的(分类)问题上随机BP还是更快的。虽然可以使用mini-batch【25】,共轭梯度的主要缺点还是它是一个批量方法(特别是因为线性搜索方法中的准确度要求)。
1.6.3 拟牛顿(BFGS)
拟牛顿(BFGS)方法:a)迭代的计算逆hessian的值;b)是一个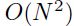 算法;c)需要线性搜索;d)只用在批量学习上。逆hessian的正定估计可以直接通过使用梯度信息计算而不需要矩阵求逆。算法描述如下:a)首先选择一个正定矩阵,即
算法;c)需要线性搜索;d)只用在批量学习上。逆hessian的正定估计可以直接通过使用梯度信息计算而不需要矩阵求逆。算法描述如下:a)首先选择一个正定矩阵,即 ;b)然后设置搜索的方向:
;b)然后设置搜索的方向:
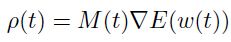
c)沿着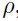 进行线性搜索,然后得到在时间 t 时的参数更新式子:
进行线性搜索,然后得到在时间 t 时的参数更新式子:
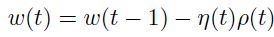
最后,d)更新逆矩阵的计算。对比牛顿算法来说,拟牛顿方法只需要梯度信息。而且最成功的拟牛顿算法是broyden-fletcher-glodfarb-shanno(bfgs)。逆hessian的计算的更新规则为:
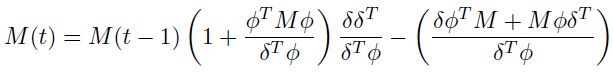
对一些符号缩写,得到如下的 向量:
向量:
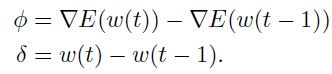
虽然如上所说,复杂度为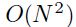 ,不过我们仍需要存储一个
,不过我们仍需要存储一个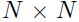 的矩阵,所以该算法值适用于小的网络,并且没有冗余的训练集的情况。近年来许多变种提出来就是为了减少存储的需要([3])
的矩阵,所以该算法值适用于小的网络,并且没有冗余的训练集的情况。近年来许多变种提出来就是为了减少存储的需要([3])
1.6.4 高斯牛顿和levenberg marquardt
高斯牛顿和levenberg marquardt 算法:a)使用平方jacobi逼近;b)主要设计用于批量学习;c)复杂度为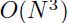 ;d)最重要的,他们只用于均值平方误差损失函数。高斯牛顿就像牛顿算法一样,不过这里的hessian是通过jacobian的平方逼近计算的(在1.7.2节有更详细的讨论):
;d)最重要的,他们只用于均值平方误差损失函数。高斯牛顿就像牛顿算法一样,不过这里的hessian是通过jacobian的平方逼近计算的(在1.7.2节有更详细的讨论):
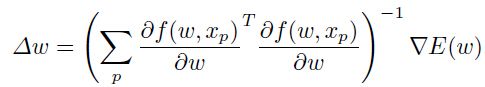
levenberg marquardt 方法就像是高斯牛顿一样,不过如果某些特征值很小的话,它有一个正则化参数 可以防止其爆炸,:
可以防止其爆炸,:
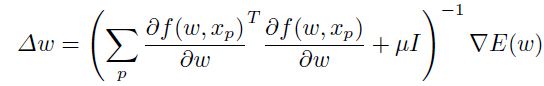
这里 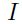 是单位矩阵。高斯牛顿的方法对于二次损失函数来说是有效的,同时与使用kullback-leibler损失的一个相似的过程被称之为自然梯度(natural gradient ,【1,2,44】)
是单位矩阵。高斯牛顿的方法对于二次损失函数来说是有效的,同时与使用kullback-leibler损失的一个相似的过程被称之为自然梯度(natural gradient ,【1,2,44】)
1.7 在多层网络中hessian信息的计算技巧
这节介绍几个用来计算全或者部分hessian矩阵的方法:a)有限差分方法;b)平方jacobian逼近(高斯牛顿和levenberg-marquardt 算法);c)hessian对角化的计算;d)在不计算hessian矩阵的情况下计算hessian矩阵与向量的乘积。其他能够计算全hessian矩阵的半分析方法这里就不介绍了,因为他们相对来说很复杂,而且需要许多的前馈/反向传播([5,8])。
1.7.1 有限差分
hessian的第k 行可计算为:

这里 是一个只有第k 个元素为1 而其他位置为0的向量。这可以简单的用一个组合方法来实现:a)通过多次前馈和反向传播步骤,计算总的梯度;b)在第 k 参数上加上
是一个只有第k 个元素为1 而其他位置为0的向量。这可以简单的用一个组合方法来实现:a)通过多次前馈和反向传播步骤,计算总的梯度;b)在第 k 参数上加上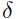 ,然后再次计算梯度;c)两者的结果相减,并除以。因为这存在的数值误差会导致hessian计算的结果不会那么完美对称。这时候需要如下进行对称化。
,然后再次计算梯度;c)两者的结果相减,并除以。因为这存在的数值误差会导致hessian计算的结果不会那么完美对称。这时候需要如下进行对称化。
1.7.2 gauss-牛顿的平方jacobian逼近和levenberg-marquardt 算法
假设一个均值平方损失函数:
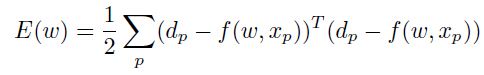
那么梯度为:
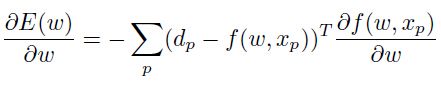
生成的hessian矩阵为:
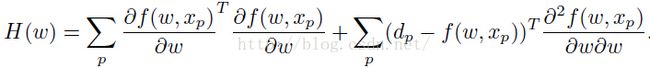
一个简单的得到hessian矩阵的逼近方法为使用jacobian的平方形式,其中该jacobian矩阵是一个半正定矩阵,其维度为: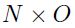
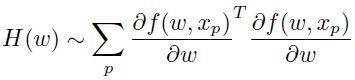
可以看出之前的hessian的第二项被丢弃掉了,这等效于是假设该网络是一个关于权重参数的线性函数。再一次提醒,这可以通过jacobian的第 k 列很好的实现:a)先前馈传播;b)然后设置第k 个输出单元的激活值为1,其他的为0;c)采用BP方法然后累加计算的梯度。
1.7.3 回向传播二阶导数
我们先来考虑一个多层系统,其中每层有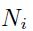 个输入,
个输入,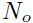 个输出和
个输出和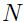 个参数,函数形式为:
个参数,函数形式为: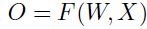 。现在假设我们已知了
。现在假设我们已知了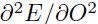 ,这是一个
,这是一个 的矩阵。然后可以很容易的计算该矩阵:
的矩阵。然后可以很容易的计算该矩阵:
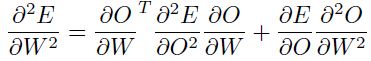
我们可以把该式子右边第二项丢弃,然后得到的hessian估计矩阵是半正定的。如果我们忽略其他的部分,只保留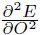 的对角线部分的项:
的对角线部分的项:
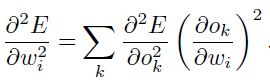
同样的,采用相似的求导方法,可以得到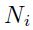 乘以的矩阵:
乘以的矩阵: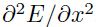
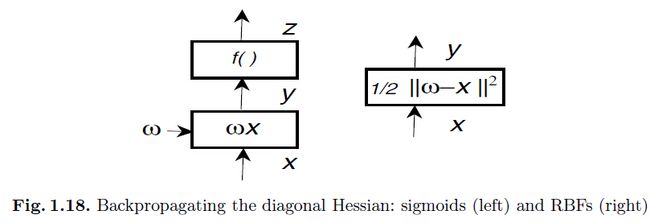
1.7.4 在nn中回向传播对角化的hessian
在文献[4,18,19]中介绍了如何用BP来计算对角化的hessian矩阵。假设网络中每一层都有函数形式为: (图1.18的sigmoidal网络)。使用高斯牛顿逼近(丢弃包含
(图1.18的sigmoidal网络)。使用高斯牛顿逼近(丢弃包含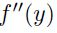 的项),我们可以得到:
的项),我们可以得到:
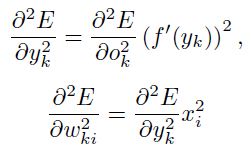
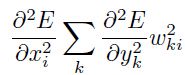 (个人:这里应该少了等号)
(个人:这里应该少了等号)
上面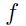 是一个高斯的非线性函数,如图1.18,对于RBF网络来说,我们得到的:
是一个高斯的非线性函数,如图1.18,对于RBF网络来说,我们得到的:
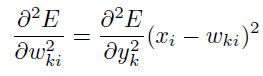
和
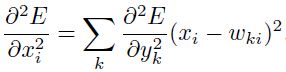
对角化二阶导数的损失计算可以通过将这些式子从最后一层到第一层进行传统的BP传播计算得到,只是这时候不使用权重化和(weighted sums)的权重而已,该技术被用在“最优化大脑损伤”修剪过程([21]):
1.7.5 计算hessian与一个向量的乘积
在许多方法中都用到了hessian矩阵,而通常也会涉及到hessian与向量相乘的情况。有趣的是,可以通过不计算hessian自身而直接计算得到这样的乘积结果。对于任意向量 来说,可以使用有限差分方法达到这样的目的:
来说,可以使用有限差分方法达到这样的目的:

只是用了2次梯度计算(在点 和
和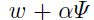 上),这可以很容易的通过BP计算得到(
上),这可以很容易的通过BP计算得到(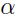 是一个小的常量)。
是一个小的常量)。
该方法可以用来计算的主特征向量和特征值。通过迭代:
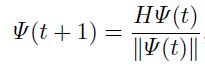
向量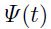 可以收敛成的最大特征向量,而
可以收敛成的最大特征向量,而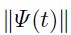 对应着的特征值(【10,14,23】).文献[33]中有个更准确的方法:a)不需要使用有限差分;b)复杂度也差不多。
对应着的特征值(【10,14,23】).文献[33]中有个更准确的方法:a)不需要使用有限差分;b)复杂度也差不多。
1.8 多层网络中hessian的分析
理解之前介绍的这些技巧如何影响hessian也是个有意思的事情,即hessian是如何随着结构和实现的细节变化而改变的。通常来说,hessian的特征值分布看起来像图1.20中概述的一样:一些小的特征值,许多中等的特征值,一些非常大的特征值。现在我们认为大的特征值是会引起训练过程中的问题的([22,23]):
a):输入或者神经元的状态的均值是非0的([22])
b):层到层之间二阶导数变化较大;
c):状态变量之间是相关的
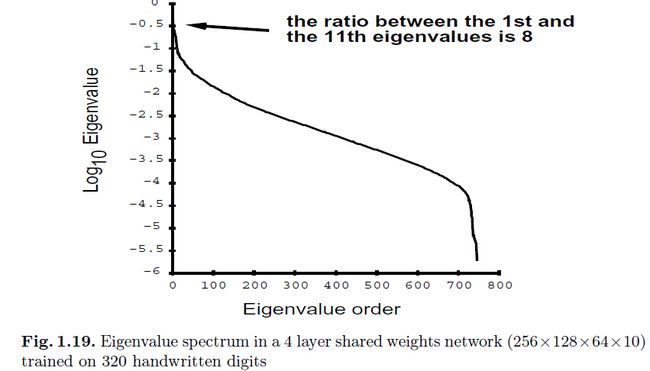
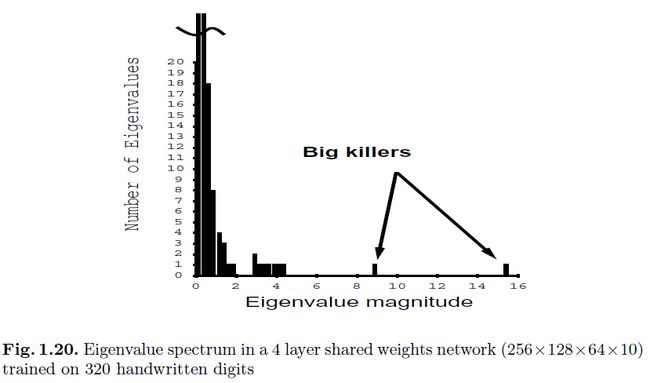
为了例证上面的三个理由,图1.20显示的是在OCR数据上训练的网络的特征值分布情况。可以很清楚的看到特征值跨度还是挺大的(图1.19),我们可以发现介于第一和第八的特征值之间的比例居然是8。特征值分布的长尾巴(图1.20)是比较麻烦的,因为介于最大和最小特征值之间的比例会限制网络的训练问题。一个较大的比例能够说明对应着椭圆形状的误差函数的轴上的差距:越大的比例,那么就能找到更多taco-shell形状的最小值,极端情况下这在短轴方向上会很深,而在长轴上会很陡峭。
在多层网络中hessian矩阵的另一个特性就是在层之间的传播了。图1.21中我们可以粗略看到hessian的形状变化,是如何从第一层相对较平而变成最后一层相对陡峭的样子的。这会影响学习的速度并且有助于解释低层中学习的缓慢和最后层学习的快速(有时候会震荡)的现象。一种弥补这样学习状态的方法是使用逆对角化hessian矩阵来控制学习率。(1.6节)
1.9 将二阶方法应用到多层网络中
在介绍如何将二阶方法用于训练大型网络之前,先来重复下一些关于传统二阶方法不好的事实:使用全hessian信息的方法(高斯牛顿、levenberg-marquardt和BFGS)只可以用在非常小的网络上,并以批量模式进行学习,然而,这些小网络恰恰却不是最需要加速的网络。大多数二阶方法(共轭梯度,BFGS)需要一个线性搜索,所以没法用在随机学习中。从我们的经验来看,我们知道在大型的分类问题上,经过精心设计的随机梯度下降法是很难被击败的。对于更小的那些需要准确的实数输出的任务来说,例如函数逼近或者控制问题,我们发现共轭梯度(polak-ribiere)可以将速度、可靠性和简单性结合的最好。在文献【17,25,31】中有几个通过minibatch的方法将共轭梯度用在大型、冗余问题上。共轭梯度的一个变种(缩放cg):其中的线性搜索过程被1D的levenberg marquardt 类型的算法所代替[24]。
1.9.1 一个随机对角化levenberg marquardt 方法
为了得到levenberg marquardt算法的随机版本,一个想法就是基于每个参数的二阶导数的运行时估计(running estimate)基础上计算对角化hessian。这里的二阶导数可以通过BP计算得到,一旦我们有了这些导数的运行时估计,我们就能用他们计算每个参数各自独立的学习率:
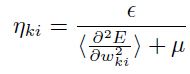 (1.9.1.1)
(1.9.1.1)
这里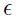 表示全局学习率,
表示全局学习率, 是关于
是关于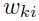 的对角化二阶导数的运行时估计。
的对角化二阶导数的运行时估计。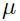 是防止二阶导数太小而造成学习率爆炸的情况,即当在误差函数的平缓表面上优化的时候。该运行时估计可以如下计算:
是防止二阶导数太小而造成学习率爆炸的情况,即当在误差函数的平缓表面上优化的时候。该运行时估计可以如下计算:
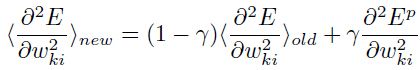
这里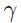 是一个小的常量,用来决定使用的内存的数量。这里的二阶导数可以先于训练被直接计算,例如,一个训练集的子集.因为它们的变化是很慢的,所以他们只需要在每几个epoch上重新计算即可。注意这里基于常规BP上的额外的损失(cost)是可以忽略不计的,而收敛比一个精心设计的随机梯度算法要快3倍。
是一个小的常量,用来决定使用的内存的数量。这里的二阶导数可以先于训练被直接计算,例如,一个训练集的子集.因为它们的变化是很慢的,所以他们只需要在每几个epoch上重新计算即可。注意这里基于常规BP上的额外的损失(cost)是可以忽略不计的,而收敛比一个精心设计的随机梯度算法要快3倍。
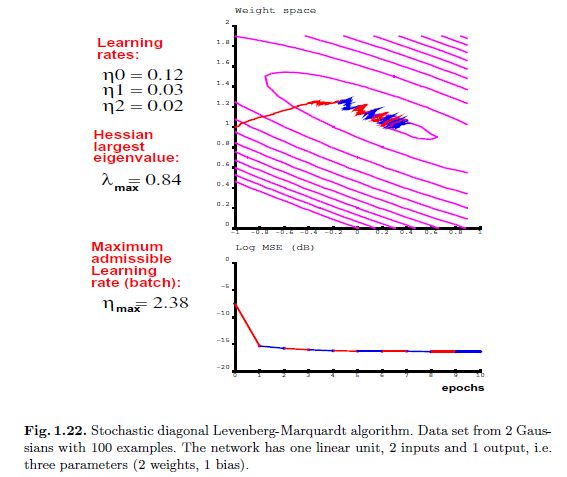
在图1.22和1.23中,分别为基于同一个样本集上两个不同的学习率集合上的随机对角化levenberg marquardt 方法的收敛(1.9.1.1)过程。显然图1.22中的实验比图1.23中的波动要少,这是因为使用了更小的学习率。

1.9.2 计算hessian的主特征值/向量
下面我们会介绍三个关于计算hessian矩阵的主特征值/向量(而不涉及到计算hessian自身)的技巧,在之前的1.4.7节中,我们介绍了一个通过均化(【28】)来逼近hessian最小特征向量(不涉及到计算hessian自身)的方法。
power 方法:先随机初始化向量 ,然后迭代:
,然后迭代:

最后收敛到主特征向量(或者主特征空间中的一个向量), 收敛到对应的特征值[10,14].
收敛到对应的特征值[10,14].
泰勒展开:另一个方法即:小扰动的梯度同样可以得到的主特征向量:
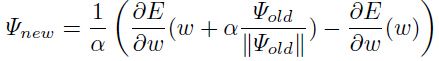
这里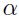 是一个小的常量。该过程迭代一次需要在训练集中的每个样本上两次前馈和两次反向传播。
是一个小的常量。该过程迭代一次需要在训练集中的每个样本上两次前馈和两次反向传播。
在线计算:该规则是通过使用运行时 平均(running average) 来快速的得到平均 hessian(average hessian)的最大特征值:
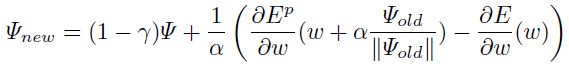
总结,特征值/向量的计算步骤如下:
1、对随机初始化;
2、通过一个输入计算其对应的输出,一次前馈和反向传播,然后将梯度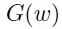 存储起来;
存储起来;
3、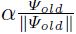 加到当前权重向量
加到当前权重向量 上;
上;
4、在执行一次前馈和反向传播,不过其中的权重向量是有轻微扰动的(即步骤3的结果),然后将梯度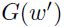 存储起来;
存储起来;
5、计算差分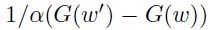 然后更新特征向量的运行时平均(running average);
然后更新特征向量的运行时平均(running average);
6、循环步骤2-6,直到得到了一个合理稳定的;
7、得到最优学习率:
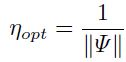
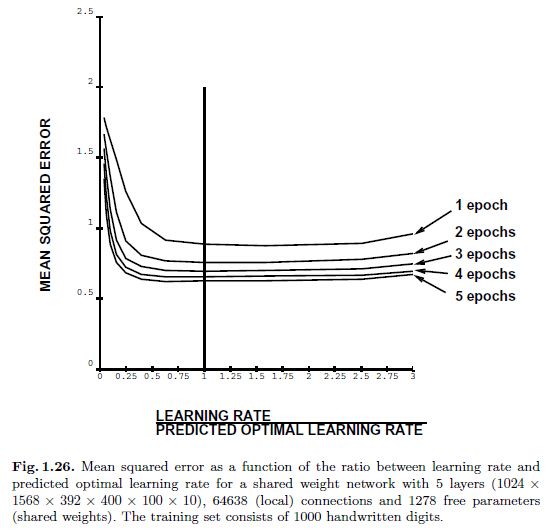
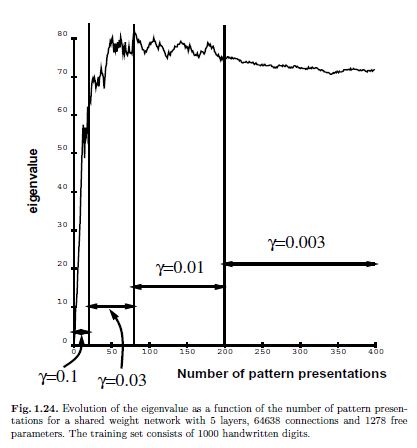
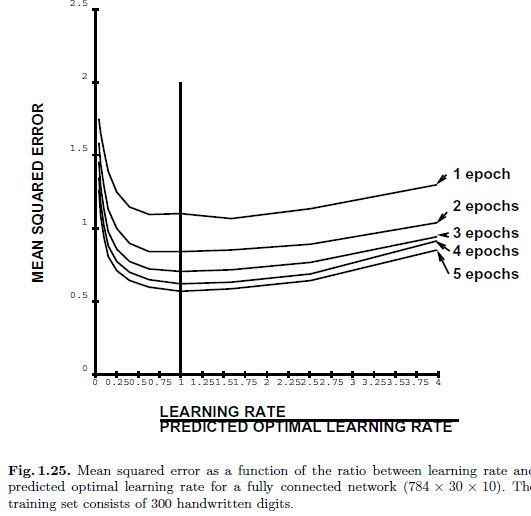
在图1.24中,我们看到特征值的改变就如手写字符识别任务中nn的样本表征的个数的函数一样。实际上,我们调整运行时平均的leak size 是为了得到更小的波动(如图中所示)。在图中我们看到在100个样本表征之后,特征值趋于稳定,即学习率也稳定了。从该实验中,我们观察到在训练的时候平均hessian的扰动是很小的。
在图1.25和1.26中,我们先以相同的条件初始化,然后通过预定义的常量乘以预测的学习率得到的学习率在定量的epoch上训练。常量1 (即,使用预测的最优学习率)的选择得到的残差总是接近最优常量得到的误差,换句话说,“预测的最优学习率”总是最优的。
1.10 总结
针对上面的这些提到的内容,在面对多层网络训练问题的时候的步骤通常为:
a)打乱样本的顺序;
b)通过减去均值来中心化输入的变量;
c)归一化输入变量使其标准差为1;
d)如果可以的话,让输入变量之间解相关(即尽可能的不相关);
e)挑选一个有着sigmoid函数的网络;
f)将目标值设置成sigmoid能够表示的范围,通常是 正1 和负 1;
g)通过前面描述的随机初始化权重。
在选择网络的时候:
a)如果训练集很大(超过100个样本)并且很冗余,如果任务是分类,那么使用随机梯度算法,并谨慎的进行调整,或者使用随机对角levenberg marquardt 方法;
b)如果训练集不是很大的话,或者任务是回归,那么使用共轭梯度方法。
传统的二阶方法在几乎所有的情况下都是不太实用的。多层网络中的随机梯度下降法的非线性动态性(其对泛化的程度有很重要关系)还是不能够很好的被理解,所以还是需要更多的原理性工作和对应的实验性工作。
参考文献:
[1] Amari, S.: Neural learning in structured parameter spaces — natural riemannian gradient. In: Mozer, M.C., Jordan, M.I., Petsche, T. (eds.) Advances in Neural Information Processing Systems, vol. 9, p. 127. MIT Press (1997)
[2] Amari, S.: Natural gradient works efficiently in learning. Neural Computation 10(2), 251–276 (1998)
[3] Battiti, R.: First- and second-order methods for learning: Between steepest descent and newton’s method. Neural Computation 4, 141–166 (1992)
[4] Becker, S., LeCun, Y.: Improving the convergence of backbropagation learning with second oder metho ds. In: Touretzky, D., Hinton, G., Sejnowski, T. (eds.) Proceedings of the 1988 Connectionist Models Summer School, pp. 29–37. Lawrence Erlbaum Associates (1989)
[5] Bishop, C.M.: Neural Networks for Pattern Recognition. Clarendon Press, Oxford (1995)
[6] Bottou, L.: Online algorithms and stochastic approximations. In: Saad, D. (ed.) Online Learning in Neural Networks (1997 Workshop at the Newton Institute).
The Newton Institute Series. Cambridge University Press, Cambridge (1998)
[7] Broomhead, D.S., Lowe, D.: Multivariable function interpolation and adaptive networks. Complex Systems 2, 321–355 (1988) 1. Efficient BackProp 47
[8] Buntine, W.L., Weigend, A.S.: Computing second order derivatives in Feed- Forward networks: A review. IEEE Transactions on Neural Networks (1993) (to
appear)
[9] Darken, C., Moody, J.E.: Note on learning rate schedules for stochastic optimization.In: Lippmann, R.P., Moody, J.E., Touretzky, D.S. (eds.) Advances in Neural
Information Processing Systems, vol. 3, pp. 832–838. Morgan Kaufmann, San Mateo (1991)
[10] Diamantaras, K.I., Kung, S.Y.: Principal Component Neural Networks. Wiley,New York (1996)
[11] Fletcher, R.: Practical Methods of Optimization, ch. 8.7: Polynomial time algorithms, 2nd edn., pp. 183–188. John Wiley & Sons, New York (1987)
[12] Geman, S., Bienenstock, E., Doursat, R.: Neural networks and the bias/variance dilemma. Neural Computation 4(1), 1–58 (1992)
[13] Goldstein, L.: Mean square optimality in the continuous time Robbins Monro procedure. Technical Report DRB-306, Dept. of Mathematics, University of Southern
California, LA (1987)
[14] Golub, G.H., Van Loan, C.F.: Matrix Computations, 2nd edn. Johns Hopkins University Press, Baltimore (1989)
[15] Heskes, T.M., Kappen, B.: On-line learning processes in artificial neural networks. In: Tayler, J.G. (ed.) Mathematical Approaches to Neural Networks, vol. 51, pp.
199–233. Elsevier, Amsterdam (1993)
[16] Jacobs, R.A.: Increased rates of convergence through learning rate adaptation. Neural Networks 1, 295–307 (1988)
[17] Kramer, A.H., Sangiovanni-Vincentelli, A.: Efficient parallel learning algorithms for neural networks. In: Touretzky, D.S. (ed.) Proceedings of the 1988 Conference
on Advances in Neural Information Processing Systems, pp. 40–48. Morgan Kaufmann, San Mateo (1989)
[18] LeCun, Y.: Modeles connexionnistes de l’apprentissage (connectionist learning models). PhD thesis, Universitè P. et M. Curie, Paris VI (1987)
[19] LeCun, Y.: Generalization and network design strategies. In: Pfeifer, R., Schreter, Z., Fogelman, F., Steels, L. (eds.) Proceedings of the International Conference
Connectionism in Perspective, University of Zürich, October 10-13. Elsevier, Amsterdam(1988)
[20] LeCun, Y., Boser, B., Denker, J.S., Henderson, D., Howard, R.E., Hubbard, W.,Jackel, L.D.: Handwritten digit recognition with a backpropagation network. In:
Touretsky, D.S. (ed.) Advances in Neural Information Processing Systems, vol. 2.Morgan Kaufmann, San Mateo (1990)
[21] LeCun, Y., Denker, J.S., Solla, S.A.: Optimal brain damage. In: Touretsky, D.S. (ed.) Advances in Neural Information Processing Systems, vol. 2, pp. 598–605
(1990)
[22] LeCun, Y., Kanter, I., Solla, S.A.: Second order properties of error surfaces. In:Advances in Neural Information Processing Systems, vol. 3. Morgan Kaufmann,
San Mateo (1991)
[23] LeCun, Y., Simard, P.Y., Pearlmutter, B.: Automatic learning rate maximization by on-line estimation of the hessian’s eigenvectors. In: Giles, Hanson, Cowan (eds.)
Advances in Neural Information Processing Systems, vol. 5. Morgan Kaufmann, San Mateo (1993)
[24] Møller, M.: A scaled conjugate gradient algorithm for fast supervised learning. Neural Networks 6, 525–533 (1993)
[25] Møller, M.: Supervised learning on large redundant training sets. International Journal of Neural Systems 4(1), 15–25 (1993) 48 Y.A. LeCun et al.
[26] Moody, J.E., Darken, C.J.: Fast learning in networks of locally-tuned processing units. Neural Computation 1, 281–294 (1989)
[27] Murata, N.: PhD thesis, University of Tokyo (1992) (in Japanese)
[28] Murata, N., Müller, K.-R., Ziehe, A., Amari, S.: Adaptive on-line learning in changing environments. In:Mozer, M.C., Jordan, M.I., Petsche, T. (eds.) Advances
in Neural Information Processing Systems, vol. 9, p. 599. MIT Press (1997)
[29] Oppenheim, A.V., Schafer, R.W.: Digital Signal Processing. Prentice-Hall, Englewood Cliffs (1975)
[30] Orr, G.B.: Dynamics and Algorithms for Stochastic learning. PhD thesis, Oregon Graduate Institute (1995)
[31] Orr, G.B.: Removing noise in on-line search using adaptive batch sizes. In: Mozer, M.C., Jordan, M.I., Petsche, T. (eds.) Advances in Neural Information Processing
Systems, vol. 9, p. 232. MIT Press (1997)
[32] Orr, M.J.L.: Regularization in the selection of radial basis function centers. Neural Computation 7(3), 606–623 (1995)
[33] Pearlmutter, B.A.: Fast exact multiplication by the hessian. Neural Computation 6, 147–160 (1994)
[34] Press,W.H., Flannery, B.P., Teukolsky, S.A., Vetterling,W.T.: Numerical Recipies in C: The art of Scientific Programming. Cambridge University Press, Cambridge
(1988)
[35] Saad, D. (ed.): Online Learning in Neural Networks (1997Workshop at the Newton Institute). The Newton Institute Series. Cambridge University Press, Cambridge
(1998)
[36] Saad, D., Solla, S.A.: Exact solution for on-line learning in multilayer neural networks. Physical Review Letters 74, 4337–4340 (1995)
[37] Sompolinsky, H., Barkai, N., Seung, H.S.: On-line learning of dichotomies: algorithms and learning curves. In: Oh, J.-H., Kwon, C., Cho, S. (eds.) Neural
Networks: The Statistical Mechanics Perspective, pp. 105–130. World Scientific, Singapore (1995)
[38] Sutton, R.S.: Adapting bias by gradient descent: An incremental version of deltabar- delta. In: Swartout, W. (ed.) Proceedings of the 10th National Conference on
Artificial Intelligence, pp. 171–176. MIT Press, San Jose (July 1992)
[39] van der Smagt, P.: Minimisation methods for training feed-forward networks. Neural Networks 7(1), 1–11 (1994)
[40] Vapnik, V.: The Nature of Statistical Learning Theory. Springer, New York (1995)
[41] Vapnik, V.: Statistical Learning Theory. Wiley, New York (1998)
[42] Waibel, A., Hanazawa, T., Hinton, G., Shikano, K., Lang, K.J.: Phoneme recognition using time-delay neural networks. IEEE Transactions on Acoustics, Speech, and Signal Processing ASSP-37, 328–339 (1989)
[43] Wiegerinck, W., Komoda, A., Heskes, T.: Stochastic dynamics of learning with momentum in neural networks. Journal of Physics A 27, 4425–4437 (1994)
[44] Yang, H.H., Amari, S.: The efficiency and the robustness of natural gradient descent learning rule. In: Jordan, M.I., Kearns, M.J., Solla, S.A. (eds.) Advances in
Neural Information Processing Systems, vol. 10. MIT Press (1998)