深度学习基础:神经网络
目录
- 一、宽度学习?深度学习!
-
- 1.1 为什么我们将这种机器学习方法称为深度学习而不是宽度学习?
- 二、神经网络的基本组成和结构
-
- 2.1 神经元
- 2.2 单层神经网络(感知机)
- 2.3 两层神经网络(多层感知机)
- 2.4 多层神经网络(深度学习)
- 三、深度学习基本技术流程
- 四、经典神经网络
-
- 4.1 卷积神经网络(CNN)
- 4.2 循环神经网络(RNN)
- 4.3 长短期记忆网络(LSTM)
- 4.4 生成对抗网络(GAN)
- 4.5 自动编码器(Autoencoder)
- 4.6 深度信念网络(DBN)
- (Cont...)
- 五、深度学习在线性回归模型、计算机视觉、自然语言处理和语音识别等领域的应用
-
- 5.1 线性回归模型
- 5.2 计算机视觉
- 5.3 自然语言处理(NLP)
- 5.4 语音识别
- (Cont...)
一、宽度学习?深度学习!
1.1 为什么我们将这种机器学习方法称为深度学习而不是宽度学习?
深度学习之所以被称为"深度",是因为它通过构建多层神经网络模型来模拟人脑的神经元连接。每一层都包含多个神经元,这些神经元通过复杂的权重和偏置进行连接,并通过激活函数引入非线性变换。通过层层堆叠,信息从输入层逐渐传递到输出层,逐步进行特征提取和表示学习。这种多层结构允许模型在抽象层面上理解数据,并通过学习更高级别的特征表示来实现更复杂的任务。这种端到端的学习方式消除了手动提取特征的需要,使得模型能够直接从原始数据中进行端到端的学习和优化。例如最简单的感知机模型如果只有宽度而没有深度,会受限于表达能力、无法解决非线性问题、容易出现欠拟合,并且难以应对复杂任务和大规模数据。
因此,深度学习强调了通过构建多层网络来实现对复杂数据的深层次抽象和表示学习。这种深度结构和自动学习的能力是深度学习在处理复杂任务和大规模数据时具有优势的重要原因。
二、神经网络的基本组成和结构
深度学习的核心是神经网络,如图2-1,它由多个层组成,包括输入层、隐藏层和输出层。输入层接收原始数据作为模型的输入,隐藏层是网络的核心部分,负责进行特征抽象和表示学习,输出层产生最终的预测结果。因此此处先介绍神经网络。
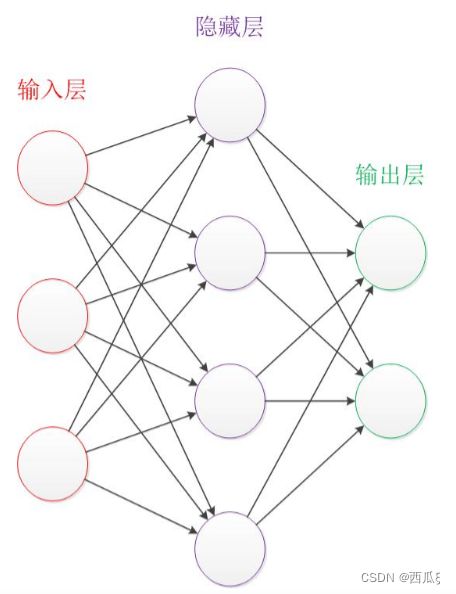
图2-1 神经网络结构图
2.1 神经元
神经元是神经网络的基本单元,模拟生物神经元的功能。如图2-2所示,一个神经元通常具有多个输入(树突)和一个输出(轴突)。通过对输入信号的加权求和并经过激活函数的处理,神经元产生一个输出结果。该输出结果可以传递给其他神经元,形成神经网络的连接。

2.2 单层神经网络(感知机)
单层神经网络,也被称为感知机(Perceptron),如图2-3,是一种最简单的神经网络模型。它只包含一个输入层和一个输出层,没有隐藏层。感知器通过将输入与对应的权重相乘并进行加权求和,然后将结果传递给激活函数来产生输出。感知器常用于解决二分类问题,并可以通过训练算法(如感知器学习规则)来调整权重,以实现对数据的准确分类。
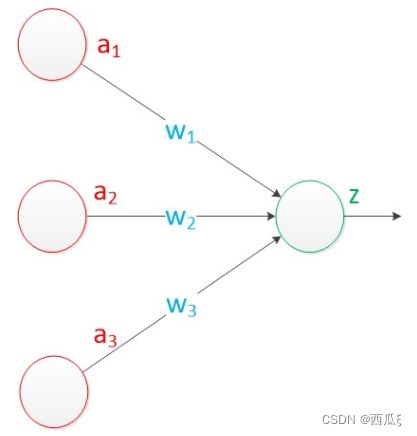
图2-3 单层神经网络
我们以一个简单的二分类问题为例,说明单层神经网络(感知机)的具体工作过程。假设我们要训练一个感知器来对输入数据进行分类,其中输入数据具有两个特征(x1和x2),并且每个样本都有对应的标签(0或1)。
import random
# 感知器模型定义
class Perceptron:
#构造函数,用于初始化感知器对象,input_size表示输入
def __init__(self, input_size):
self.weights = [0.0] * input_size
self.bias = 0.0
#预测函数,根据给定的输入特征进行预测,features表示特征值列表
def predict(self, features):
activation = self.bias
for i in range(len(features)):
activation += self.weights[i] * features[i]
return 1 if activation >= 0 else 0
#训练函数,用于训练感知器模型
def train(self, features, label, learning_rate):
prediction = self.predict(features)
error = label - prediction
self.bias += learning_rate * error
for i in range(len(features)):
self.weights[i] += learning_rate * error * features[i]
# 训练数据
train_data = [
([0, 0], 0),
([0, 1], 0),
([1, 0], 0),
([1, 1], 1)
]
# 创建感知器模型
perceptron = Perceptron(input_size=2)
# 随机打乱训练数据的顺序
random.shuffle(train_data)
# 训练感知器模型
for features, label in train_data:
perceptron.train(features, label, learning_rate=0.1)
# 预测新样本
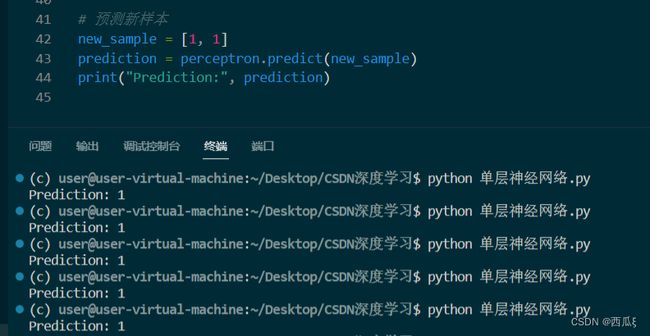
new_sample = [1, 1]
prediction = perceptron.predict(new_sample)
print("Prediction:", prediction)
在这个简单的感知机模型中,预测结果只有0和1两种可能性。因为在感知器模型中,我们使用了一个阈值函数,将加权和的结果转化为0或1的离散输出。当加权和大于等于0时,预测结果为1;当加权和小于0时,预测结果为0。可以理解为是一个AND门。
在训练过程中,通过调整权重和偏置,感知机逐渐学习到如何正确分类输入样本。最后,我们使用训练好的感知机模型对新的样本进行分类预测。如图2-4,特征值为1,1时,结果为1。对于单层感知机,对于线性可分的问题,如AND逻辑门,它是能够达到百分百的预测准确率的。
2.3 两层神经网络(多层感知机)
两层神经网络,也称为多层感知机(Multi-Layer Perceptron, MLP),在单层神经网络的基础上引入了一个或多个隐藏层。隐藏层的神经元对输入进行非线性变换和特征提取,并通过权重连接将结果传递给输出层。每个神经元都使用激活函数对输入进行处理。多层感知机具有更强的表达能力,可以解决更复杂的非线性问题。通过反向传播算法和梯度下降法等优化算法,可以对多层感知机进行训练和参数优化。就相当于神经元套娃哈哈哈哈。
我们用例子来说明,实现一个简单的两层感知机神经网络,并通过反向传播算法对其进行训练,以解决非线性分类问题。这里我们每个训练周期称为一个 Epoch:表示训练进行到某个周期时的损失值。Loss损失值是用来衡量神经网络在训练数据上的预测结果与实际标签之间的差异程度。在这个示例中,使用的是交叉熵损失函数。损失值越小,表示神经网络在训练数据上的预测越准确。可以通过观察损失值的变化来了解神经网络的训练进展情况。在训练过程中,我们希望损失值逐渐减小,表示神经网络的预测结果与实际标签之间的差异逐渐减小,即神经网络的性能逐渐改善。
import numpy as np
# 定义激活函数 sigmoid
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# 定义激活函数 sigmoid 的导数
def sigmoid_derivative(x):
return sigmoid(x) * (1 - sigmoid(x))
# 定义神经网络类
class TwoLayerPerceptron:
def __init__(self, input_size, hidden_size, output_size):
# 初始化权重和偏置
self.W1 = np.random.randn(input_size, hidden_size) #隐藏层的权重
self.b1 = np.zeros((1, hidden_size)) #隐藏层的偏置
self.W2 = np.random.randn(hidden_size, output_size) #输出层的权重
self.b2 = np.zeros((1, output_size)) #输出层的偏置
def forward(self, X):
# 前向传播计算
self.z1 = np.dot(X, self.W1) + self.b1
self.a1 = sigmoid(self.z1)
self.z2 = np.dot(self.a1, self.W2) + self.b2
self.a2 = sigmoid(self.z2)
return self.a2
def backward(self, X, y, learning_rate):
m = X.shape[0] # 样本数量
# 反向传播计算梯度
delta2 = self.a2 - y
dW2 = (1 / m) * np.dot(self.a1.T, delta2)
db2 = (1 / m) * np.sum(delta2, axis=0)
delta1 = np.dot(delta2, self.W2.T) * sigmoid_derivative(self.z1)
dW1 = (1 / m) * np.dot(X.T, delta1)
db1 = (1 / m) * np.sum(delta1, axis=0)
# 更新权重和偏置
self.W2 -= learning_rate * dW2
self.b2 -= learning_rate * db2
self.W1 -= learning_rate * dW1
self.b1 -= learning_rate * db1
def train(self, X, y, epochs, learning_rate):
for epoch in range(epochs):
# 前向传播
output = self.forward(X)
# 反向传播
self.backward(X, y, learning_rate)
# 计算损失函数(交叉熵)
loss = -np.mean(y * np.log(output) + (1 - y) * np.log(1 - output))
# 每100个周期打印一次损失
if epoch % 100 == 0:
print("Epoch:", epoch, " Loss:", loss)
# 创建一个随机的非线性分类问题数据集
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([[0], [1], [1], [0]])
# 创建神经网络对象
mlp = TwoLayerPerceptron(input_size=2, hidden_size=4, output_size=1)
# 训练神经网络
mlp.train(X, y, epochs=1000, learning_rate=0.1)
# 在训练集上进行预测
predictions = mlp.forward(X)
print("Predictions:\n", predictions)
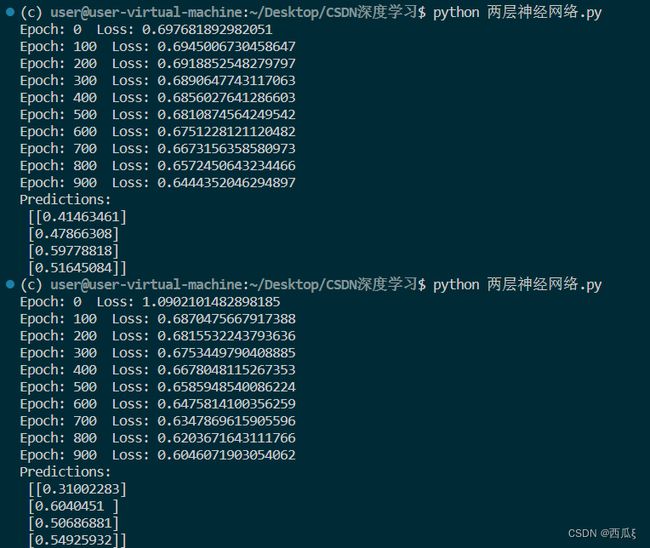
当然每次预测的结果都是不同的,如图2-5所示,因为在代码中,神经网络的权重是通过随机初始化的。每次运行代码时,权重的初始值会发生变化,导致网络的初始状态不同,从而影响了训练过程和最终的预测结果。并且代码中每次迭代时都从训练集中随机选择一部分样本进行计算梯度和更新权重。
我们来分析结果,以图2-5的第二个输出为例子,随着训练的进行,我们希望损失值逐渐减小,表示神经网络的性能逐渐改善,对训练数据的拟合程度逐渐提高,所以Loss越来越小。对于输出的矩阵,第一行 0.31002283:表示对第一个样本的预测概率,即属于正类的概率为 0.31002283。以此类推。正类即阈值在0.5之上的,所以一个样本被划分为负类,第二个样本被划分为正类,第三个样本被划分为正类,第四个样本被划分为正类。
但是,这个输出结果是在训练集上进行的预测。对于这个简单的两层感知机模型来说,它的拟合能力有限,因此在面对新的未见过的数据时,它的泛化能力可能会有所下降。
需要注意的是,代码中采用了反向传播算法对其进行训练,以及激活函数等概念可以进行查阅。此处不再赘述。(毕竟太多了哈哈哈哈哈,可以去看看数学中的链式法则)
2.4 多层神经网络(深度学习)
多层神经网络是深度学习的核心。它包含多个隐藏层,每个隐藏层都有多个神经元。深度学习的关键在于通过多层网络进行特征的层层抽象和表示学习。深层网络可以通过大规模数据和高性能计算资源的训练来提取复杂的非线性特征,并通过反向传播算法来调整权重和优化模型。深度学习在图像识别、自然语言处理、语音识别等领域取得了显著的成就,成为目前最为成功和有效的机器学习方法之一。
其实就是在两层神经网络的输出层后面,继续添加层次。原来的输出层变成中间层,新加的层次成为新的输出层。权值W可以无限套娃,就像人的神经元,它有更深入的表示特征,以及更强的函数模拟能力。更深入的表示特征可以这样理解,随着网络的层数增加,每一层对于前一层次的抽象表示更深入。在神经网络中,每一层神经元学习到的是前一层神经元值的更抽象的表示。
我们用一个简单的示例代码来解释,假设数据集是一个包含1000个样本的二分类问题,每个样本有10个特征。而且不需要去准备训练集和测试集了,我们采用随机生成(爽吧哈哈哈哈)。如图2-6所示,就是生成的data。
import os
import shutil
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
# 创建文件夹用于存放训练集和测试集
base_dir = 'data'
train_dir = os.path.join(base_dir, 'train')
test_dir = os.path.join(base_dir, 'test')
# 如果文件夹不存在,则创建文件夹
if not os.path.exists(base_dir):
os.makedirs(train_dir)
os.makedirs(test_dir)
# 生成示例数据集(这里使用随机生成的数据)
# 假设你的数据集包含1000个样本,每个样本有10个特征
num_samples = 1000
num_features = 10
# 创建随机数据
data = np.random.random((num_samples, num_features))
labels = np.random.randint(2, size=(num_samples,))
# 将数据集按照比例分成训练集和测试集
train_ratio = 0.8
train_samples = int(num_samples * train_ratio)
train_data = data[:train_samples]
train_labels = labels[:train_samples]
test_data = data[train_samples:]
test_labels = labels[train_samples:]
# 将训练集和测试集数据分别保存到对应文件夹中
def save_data_to_folder(data, labels, folder):
for i, (x, y) in enumerate(zip(data, labels)):
subdir = 'class_{}'.format(y)
subdir_path = os.path.join(folder, subdir)
if not os.path.exists(subdir_path):
os.makedirs(subdir_path)
file_path = os.path.join(subdir_path, 'sample_{}.txt'.format(i))
np.savetxt(file_path, x)
save_data_to_folder(train_data, train_labels, train_dir)
save_data_to_folder(test_data, test_labels, test_dir)
# 构建多层神经网络模型
model = Sequential()
model.add(Dense(64, activation='relu', input_shape=(num_features,)))
model.add(Dense(64, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 加载数据集
def load_data_from_folder(folder):
data = []
labels = []
for subdir in os.listdir(folder):
subdir_path = os.path.join(folder, subdir)
if os.path.isdir(subdir_path):
label = int(subdir.split('_')[1])
for file_name in os.listdir(subdir_path):
file_path = os.path.join(subdir_path, file_name)
sample = np.loadtxt(file_path)
data.append(sample)
labels.append(label)
return np.array(data), np.array(labels)
# 加载训练集和测试集
train_data, train_labels = load_data_from_folder(train_dir)
test_data, test_labels = load_data_from_folder(test_dir)
# 训练模型
model.fit(train_data, train_labels, epochs=10, batch_size=32, validation_data=(test_data, test_labels))
# 在测试集上评估模型性能
score = model.evaluate(test_data, test_labels, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
然后我们来分析代码,首先创建用于存放训练集和测试集的文件夹,然后生成示例数据集并按照指定比例分割成训练集和测试集,接着将数据保存到对应的文件夹中。接下来,使用Keras库构建了一个多层神经网络模型,并对模型进行编译。之后,通过函数从文件夹中加载训练集和测试集数据。随后,使用加载的数据对模型进行训练,指定迭代次数和批次大小,并在训练过程中使用测试集数据进行验证。最后,评估模型在测试集上的性能,计算损失值和准确率,并将结果打印出来。
对于多层神经网络模型,我们使用了Sequential模型对象来表示神经网络模型,并且通过model.add()方法添加多个层来构建多层神经网络。以下代码添加了两个隐藏层(每个层都有64个神经元)和一个输出层(1个神经元)
# 添加第一层隐藏层,输入维度为num_features,激活函数为ReLU
model.add(Dense(64, activation='relu', input_shape=(num_features,)))
# 添加第二层隐藏层,维度为64,激活函数为ReLU
model.add(Dense(64, activation='relu'))
# 添加输出层,维度为1,激活函数为Sigmoid
model.add(Dense(1, activation='sigmoid'))
通过上述代码,我们可以看到神经网络模型中的多个层的堆叠,构成了多层神经网络结构。
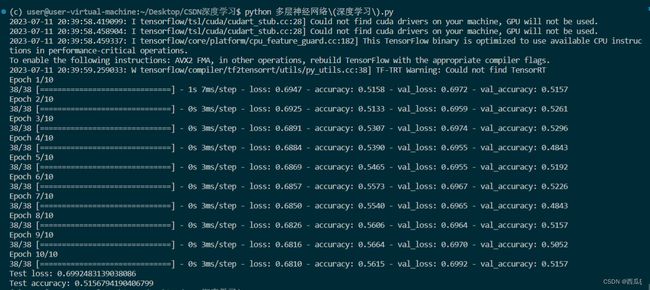
我们来看输出结果==(当然我不能用GPU呜呜呜)==,如图2-7所示,输出结果表示模型在训练和测试过程中的性能表现。在每个Epoch结束时,输出了训练集和验证集上的损失值(loss)和准确率(accuracy)。对于训练集,显示了每个Epoch的损失值和准确率。例如,第一个Epoch的训练集损失值为0.6947,准确率为0.5158。对于验证集,显示了每个Epoch的验证集损失值和准确率。例如,第一个Epoch的验证集损失值为0.6972,准确率为0.5157。最后,输出了在测试集上的损失值和准确率。根据输出结果,测试集上的损失值为0.6992,准确率为0.5157。
当然这个代码只是演示如何使用多层神经网络模型来处理一个二分类问题。代码中生成了一个随机的示例数据集,包括输入数据和对应的标签数据。然后,将数据集按照指定的比例分割为训练集和测试集。接下来,使用Keras库构建了一个多层神经网络模型,包括多个隐藏层和一个输出层。二分类问题的具体划分是通过随机生成的标签数据进行的。在生成示例数据集时,使用了np.random.randint()函数生成了随机的标签数据,标签值为0或1。这样就将样本分为了两个类别,类别0和类别1。在训练集和测试集的划分过程中,使用了指定的训练集比例(train_ratio)将数据集分割成训练集和测试集。根据划分比例,前80%的样本被用作训练集,后20%的样本被用作测试集。因此,这个二分类问题的具体分法是将生成的示例数据集中的样本按照标签值进行划分,其中类别0和类别1的样本被分别分配到训练集和测试集中,用于训练和评估模型对输入数据进行二分类预测。
三、深度学习基本技术流程
说白了只有三步!
- 数据集的收集与预处理
- 确定一个神经网络模型
- 训练与测试
我们针对手写数字识别任务的代码来完成三步,当然只是一个简单处理,并不是合起来就是整个代码,还需要代码块的辅助。
在手写数字识别任务中,一个常见的数据集是MNIST数据集,我们使用Python的库来加载和处理。
import tensorflow as tf
from tensorflow.keras.datasets import mnist
# 加载MNIST数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据预处理(归一化和reshape)
x_train = x_train.reshape(-1, 28*28) / 255.0
x_test = x_test.reshape(-1, 28*28) / 255.0
确定一个神经网络模型:我们将使用一个简单的全连接神经网络作为模型。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# 创建一个序列模型
model = Sequential()
# 添加全连接层
model.add(Dense(128, activation='relu', input_shape=(28*28,)))
model.add(Dense(10, activation='softmax'))
# 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
训练与测试:使用准备好的数据集和模型进行训练和测试。
# 训练模型
model.fit(x_train, y_train, epochs=10, batch_size=32, validation_data=(x_test, y_test))
# 在测试集上评估模型
loss, accuracy = model.evaluate(x_test, y_test)
print('Test loss:', loss)
print('Test accuracy:', accuracy)
四、经典神经网络
内容实在是太多啦!后续文章会给大家补上的!现在就放个名字,可以去查一查哈哈哈哈哈哈。
4.1 卷积神经网络(CNN)
专门设计用于图像处理任务,通过卷积层和池化层来捕捉图像中的空间特征和局部模式。
4.2 循环神经网络(RNN)
适用于处理序列数据,能够建模序列中的时序依赖关系,并保留记忆状态以处理长期依赖。
4.3 长短期记忆网络(LSTM)
一种RNN的变种,通过引入记忆单元和门控机制来解决长期依赖问题,适用于处理长序列数据。
4.4 生成对抗网络(GAN)
由生成器和判别器组成,通过对抗训练生成逼真的样本,广泛应用于图像生成和图像转换任务。
4.5 自动编码器(Autoencoder)
无监督学习的神经网络模型,通过编码和解码过程学习数据的压缩表示,用于降维、特征学习和数据去噪等任务。
4.6 深度信念网络(DBN)
由多个受限玻尔兹曼机(RBM)组成的深层神经网络,通过逐层预训练和微调来学习数据分布和高级特征表示。
(Cont…)
五、深度学习在线性回归模型、计算机视觉、自然语言处理和语音识别等领域的应用
具体的如何应用我还没学完哈哈哈哈哈,后续慢慢会补上各部分的应用实例的!!!

5.1 线性回归模型
虽然深度学习通常用于非线性问题,但也可以应用于线性回归模型。通过使用多层神经网络,可以在线性回归任务中进行更复杂的特征学习和模式识别。
5.2 计算机视觉
深度学习在计算机视觉领域有广泛的应用。卷积神经网络(CNN)是一种常用的深度学习模型,用于图像分类、目标检测、图像分割等任务。它们能够学习从原始像素数据中提取有用的特征,并在图像识别和理解方面取得了重大突破。
import cv2
import numpy as np
def sharpen_image(image):
# 创建一个锐化的卷积核
kernel = np.array([[-1, -1, -1],
[-1, 9, -1],
[-1, -1, -1]])
# 使用卷积核对图像进行滤波
# -1是图像的深度
sharpened_image = cv2.filter2D(image, -1, kernel)
return sharpened_image
# 读取图像
image = cv2.imread('input1.jpg')
# 锐化图像
sharpened_image = sharpen_image(image)
# 显示原始图像和锐化后的图像
cv2.imshow('Original Image', image)
cv2.imshow('Sharpened Image', sharpened_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
上述代码进行了一个基础的图像锐化,使用opencv库来实现,但是只对卷积层进行了处理,设置的卷积核可以加权。具体运行需要对应的cv库。
5.3 自然语言处理(NLP)
深度学习在自然语言处理领域取得了显著的进展。递归神经网络(RNN)和长短期记忆网络(LSTM)等模型常用于语言建模、文本分类、命名实体识别、情感分析等任务。深度学习模型能够从文本中学习上下文相关的特征,实现更准确的自然语言处理。
5.4 语音识别
深度学习在语音识别领域具有重要应用。循环神经网络(RNN)和卷积神经网络(CNN)等模型可用于语音识别任务,包括语音指令识别、语音转文本等。深度学习模型能够学习到语音信号中的时序模式和语音特征,提高识别准确性。
(Cont…)
理论上来讲,只要有足够大规模和高质量的数据集,一切问题都可以使用端到端的深度学习