hugging face transformers模型文件 config文件
模型的组成
一般transformer模型有三个部分组成:1.tokennizer,2.Model,3.Post processing。如下图所示,图中第二层和第三层是每个部件的输入/输出以及具体的案例。我们可以看到三个部分的具体作用:Tokenizer就是把输入的文本做切分,然后变成向量,Model负责根据输入的变量提取语义信息,输出logits;最后Post Processing根据模型输出的语义信息,执行具体的nlp任务,比如情感分析,文本自动打标签等;可见Model是其中的核心部分,Model又可以分为三种模型,针对不同的NLP任务,需要选取不同的模型类型:Encoder模型(如Bert,常用于句子分类、命名实体识别(以及更普遍的单词分类)和抽取式问答。),Decoder模型(如GPT,GPT2,常用于文本生成),以及sequence2sequence模型(如BART,常用于摘要,翻译,生成性问答等)

说了很多理论的内容,我们可以在huggingface的官网,随便找一个预训练模型具体看看包含哪些文件。在这里我举了一个中文的例子”Bert-base-Chinese“(中文还有其他很优秀的预训练模型,比如哈工大和科大讯飞提供的:roberta-wwm-ext,百度提供的:ernie)。这个模型据说是根据中文维基百科内容训练的,因此语义内容可能不是足够丰富,毕竟其他大佬们提供的数据更多。
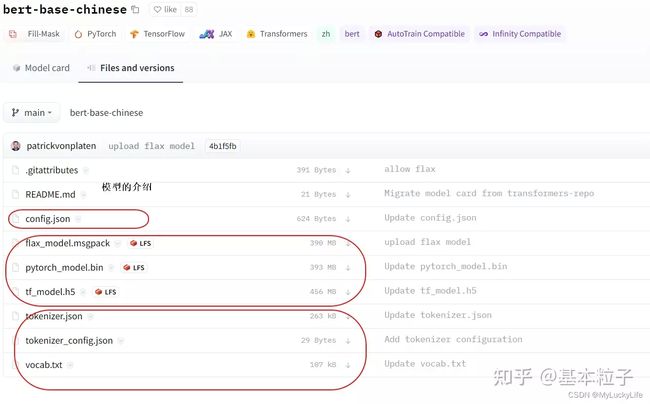
readme一般是模型的介绍,包括使用方法都会放到里面,不介绍了。其他最重要的组成部分,大概分为三类:
- config
控制模型的名称、最终输出的样式、隐藏层宽度和深度、激活函数的类别等。这些参数我补齐了说明,对于初学者来说,大家一般不需要调整。这些参数都可以通过configuration类更改。
{
"architectures": [
"BertForMaskedLM" # 模型的名称
],
"attention_probs_dropout_prob": 0.1, # 注意力机制的 dropout,默认为0.1
"directionality": "bidi", # 文字编码方向采用bidi算法
"hidden_act": "gelu", # 编码器内激活函数,默认"gelu",还可为"relu"、"swish"或 "gelu_new"
"hidden_dropout_prob": 0.1, # 词嵌入层或编码器的 dropout,默认为0.1
"hidden_size": 768, # 编码器内隐藏层神经元数量,默认768
"initializer_range": 0.02, # 神经元权重的标准差,默认为0.02
"intermediate_size": 3072, # 编码器内全连接层的输入维度,默认3072
"layer_norm_eps": 1e-12, # layer normalization 的 epsilon 值,默认为 1e-12
"max_position_embeddings": 512, # 模型使用的最大序列长度,默认为512
"model_type": "bert", # 模型类型是bert
"num_attention_heads": 12, # 编码器内注意力头数,默认12
"num_hidden_layers": 12, # 编码器内隐藏层层数,默认12
"pad_token_id": 0, # pad_token_id 未找到相关解释
"pooler_fc_size": 768, # 下面应该是pooler层的参数,本质是个全连接层,作为分类器解决序列级的NLP任务
"pooler_num_attention_heads": 12, # pooler层注意力头,默认12
"pooler_num_fc_layers": 3, # pooler 连接层数,默认3
"pooler_size_per_head": 128, # 每个注意力头的size
"pooler_type": "first_token_transform", # pooler层类型,网上介绍很少
"type_vocab_size": 2, # 词汇表类别,默认为2
"vocab_size": 21128 # 词汇数,bert默认30522,这是因为bert以中文字为单位进入输入
}2. tokenizer(包含三个文件)
这些文件是tokenizer类生成的,或者处理的,只是处理文本,不涉及任何向量操作。
vocab.txt是词典文件(打开就是单个字符,我这里用的是bert-base-chinsese,可以看到里面都是保留符号和单个汉字索引,字符)
tokenizer.json和config是分词的配置文件,根据vocab信息和你的设置更新,里面把vocab都按顺序做了索引,将来可以根据编码生成one-hot向量,然后跟embeding训练的矩阵相乘,就可以得到该字符的向量。下图是tokenizer.json内容。

模型文件一般是tensor flow(上图中的h5文件)和py-torch(上图中的bin文件)的都有.