11、(复现)openvino 扑克检测模型,ssd_mobilenet轻量级模型,ssd+tensorflow,pytorch+yolov5,转openvino加速,onnx使用及网络架构的摘除转化
# 关键词:
训练ssd_mobilenet 轻量级模型、 ssdlite_mobilenet 转为 openvino、cpu级别的加速、
yolov5转为openvino、tensorflow+ssd训练数据、pytorch+yolov5训练数据、
yolov5、SSD目标检测模型、模型压缩、openvino(intel公司的推理加速模型)、开放神经网络转化器:onnx、
ssdlite_mobilenet 轻量目标检测模型、模型加速、netron网络层-查看工具、wandb可视化工具、tensorflow+ssd、pytorch+yolov5
# 厉害之处:即使放在cpu上推理、也可以到 60-70帧率/每秒!!!3-4倍加速!!!
目标:
1、训练轻量级目标检测模型 ssdlite_mobilenet_v2
2、使用openvino对 ssdlite_mobilenet 进行加速
3、使用openvino对yolov5 进行加速
*4、树莓派 + ncs2(神经计算加速棒)运行 openvino模型.... # 舍弃、没板子!!
# 目的:
1、SSD目标检测模型
2、轻量目标检测模型 ssdlite_mobilenet
3、openvino
4、ssdlite_mobilenet 转为 openvino
5、yolov5 转为 openvino
*6、树莓派安装 openvino # 舍弃、没板子!!
*7、树莓派 + ncs2(神经计算加速棒)运行 openvino模型.... # 舍弃、没板子!!
一、SSD目标检测模型:
目标检测方法,分类:
1、one-stage(一阶段方法): 如yolo,SSD的方法, 优点:速度快!!!
思路: 均匀地在图片的不同位置,进行密集采集抽样,抽样时,可采用不同的尺寸和长宽比,
然后,利用 CNN提取特征后,直接进行分类和回归,这只需要一步!!
2、two-stage(二阶段方法): 如 r-cnn方法, 优点:准确度高!!
思路: 通过启发式方法,或是CNN网络,产生一系列候选框,再对候选框,进行分类和回归!
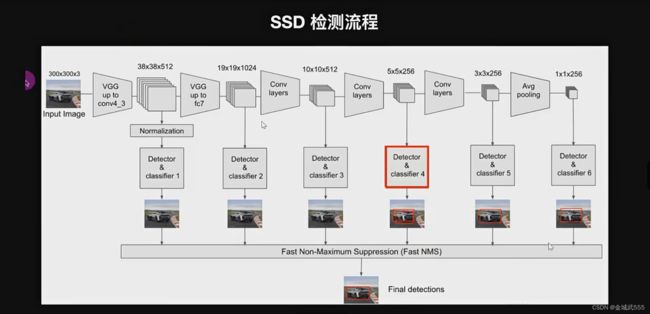
SSD: Single Shot MultiBox Detector , 一阶段、多框、检测,
SSD的网络架构:
在vgg 16的网络结构基础上,添加了一些卷积层,进行下采样的特征提取
使用vgg的网络架构,提取图形的有用特征, 之后,再通过几个卷积层,进行下采样的特征提取!
可以理解为: 就是在原图上,不同的尺寸,特征表达, 大尺寸:检测小目标,小尺寸:检测大目标!
vgg 16: 当年参加 打imageNet比赛,提出的架构!
vgg 16的网络架构: 卷积不改变画面大小,通过池化层,将通道数,降为原来的一半!
不同尺寸的缩放比例: 2的1~5次方,压缩比例! 2-4-8-16-32。 224*224*3->112*112*64
->56*56*128->28*28*256->14*14*512...->7*7*512、
最后,通过3个全连接层,将他修改为,输出为1000类的概率信息!!!
vgg网络,一层一层的往下输送!!! 尺寸,也进行了改变!!
SSD中,对VGG16的修改之处:
1、输入图像,由244->300 2、fc6、fc7变成卷积层
3、修改了最后一个 pool的大小 4、去掉了所有的dropout层,和fc8层,全改成了卷积层!
详细介绍: conv4、conv7、conv8、conv9、conv10、conv11,这6个卷积层提取出来,作为目标检测的6个征图....没全部提取!!
从conv4开始,2的3次方==8, 尺寸=原来的1/8, 300÷8=37.5≈38,conv4的尺寸== 38*38*512 512=上层输送的通道数!
yolo和SSD的不同:
1、yolo是以画出小格子的方式,检测出物体和框框
2、ssd,先验框的方式,借鉴了fast-rcnn中的锚框,命名为ssd default box(先验框),精心挑选的,比例都是量身定制统计筛选过的。
先验框:预设不同尺寸的框,提前在图像上预设好的不同大小,不同长宽比的框
先验框的粗糙理解,可以理解为在6个不同尺寸的特征图中,以先预定长宽比的框先标定,再用nms筛出iou最大的一个框!
ssd_mobilenet_v2: 非常轻量的检测模型!
简单理解: 就是用 mobilenet_v2 替换掉了,原来的 VGG 16网络架构!因为对移动端而言,vgg 16太大了,运行太慢了!!!
mobilenet,谷歌公司提出的轻量级神经网路,移动端和嵌入式使用,减少了卷积运算,降低了参数量,提高了速度!
二、训练ssdlite_mobilenet_v2_coco 模型:【tensorflow + ssd + openvino】
1.1 安装TensorFlow object detection 环境: course_tf1_env1
## 流程: 两个问题:1、cmake编译错误! 2、python 3.6换成 3.7, 3、降低 pip 版本!
1、安装 tensorflow object detection,或者直接解压已有的文件!!
安装git工具: conda install -c anaconda git
使用, git clone https://github.com/tensorflow/models.git 克隆仓库到一个空的文件夹。
2、创建3.6的训练环境:
conda create --name course_tf1_env python=3.6
3、# 安装TensorFlow 1.15 (cuda 10.1及以上!)
pip install tensorflow-gpu==1.15
4、# 安装protobuf,编译工具!
conda install -c anaconda protobuf
5、# 安装object detection,进入解压目录!!models下的research目录!!!
cd models/research
6、# 编译
protoc object_detection/protos/*.proto --python_out=.
7、如果是probuf 3.5及以后的版本!!! # Windows and using Protobuf 3.5 or later
Get-ChildItem object_detection/protos/*.proto | foreach {protoc "object_detection/protos/$($_.Name)" --python_out=.}
8、#拷贝# 安装
cp object_detection/packages/tf1/setup.py .
python -m pip install --use-feature=2020-resolver .
9、验证::: 打印出一切 ok,就是正常!!!
python object_detection/builders/model_builder_tf1_test.py
### 小插曲: vs studio报错!!!
vs各个版本,查找ms-build路径的命令,我的是vs 2019社区版本的,如下命令!!!:
"C:\Program Files (x86)\Microsoft Visual Studio\Installer\vswhere.exe" -latest -prerelease -products * -requires Microsoft.Component.MSBuild -find MSBuild\**\Bin\MSBuild.exe
### 正确路线:: 1、下载python 3.7 ::: 解决 opencv的编译错误
2、降低pip 版本 ::: python -m pip install pip==20.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
1.2 测试预训练模型 环境:course_tf2_env
# 创建Python=3.6的虚拟环境
conda create --name course_tf2_env python=3.7 # 3.6的有问题,下载 3.7的!!! 一定要 3.7的,3.6的会报错!!!!
# python -m pip install pip==20.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
# 安装TensorFlow 2.2.0
#pip install tensorflow==2.2.0 # 除非你是cuda 10.1,装不了gpu版的 tf,不然别装这个!
pip install tensorflow-gpu==2.2.0
# 安装protobuf
conda install -c anaconda protobuf
# 安装object detection
cd models/research
# 编译
protoc object_detection/protos/*.proto --python_out=.
# Windows and using Protobuf 3.5 or later
Get-ChildItem object_detection/protos/*.proto | foreach {protoc "object_detection/protos/$($_.Name)" --python_out=.}
# 安装
cp object_detection/packages/tf1/setup.py .
python -m pip install --use-feature=2020-resolver .
# 安装OpenCV
pip install opencv-python==4.4.0.40
# 测试,官方的预训练模型:
取出 2、预训练模型的文件夹,切目录,python tf_test.py 运行测试!!! 完成!!!
1.3 准备训练数据集
1、切回第一个训练的环境,激活,安装 lableImg: pip install lableImg
2、解压数据集,标注!!
3、注意: 不同于 yolov5的 coco数据集, ssd采用的是 pascal voc 数据集!!! lableImg,记得进行,格式切换!!
4、解压: 复制已经标注好的数据集, 放在和 models 同级的目录!!
tar文件,命令行解压!! tar -xvf pascal_voc_images.tar.gz # 文件名字 pascal_voc_images.tar.gz
命令行解压的好处: 在没有解压软件,或是只有命令行的情况下,进行解压!!!
5、制作训练类别! 1-52,各个类别!!对应的是什么!!!
打开lable img,查看一下数据集,以及标注情况!!!
6、样本类别、名称,生成脚本!
脚本 ./annotations/Untitled.ipynb 类别文件!! ./annotations/label_map.pbtxt # 【注意格式:pbtxt】
1.4 训练模型
1-3 里有训练代码,把训练代码文件夹里的文件,复制后,放在models同级目录!!!
tf_record, tensorflow自己读取数据集的格式,需要有这个才能,读取标注数据
2、生成 tf-record,运行脚本命令!!
训练集,测试集,分别运行: (models同级目录!!)
# 生成训练集
python generate_tfrecord.py -x data/images/train -l data/annotations/label_map.pbtxt -o data/annotations/train.record
# 生成测试集
python generate_tfrecord.py -x data/images/test -l data/annotations/label_map.pbtxt -o data/annotations/test.record
# python代码 -x 路径: 图片路径 -l : 标签lable -o: 输出文件, 名字和位置...
1.5 修改配置文件!!!
创建一个新的文件夹pretrained_model与models同级,将预训练模型文件夹复制进pretrained_model
修改训练配置文件
用VS CODE等文本编辑器打开data/ssdlite_mobilenet_v2_coco.config配置文件,修改以下内容:
1、 ssd {num_classes: 6 # 修改为检测类别数量 ## 6- 52
2、 train_config: {batch_size: 24 # batch size # 批数量,量力而行,24就挺好... 一个批次时间多久,越短越好,调优
3、 fine_tune_checkpoint: "./pretrained_model/ssdlite_mobilenet_v2_coco_2018_05_09/model.ckpt" # 预训练模型位置,后面的 .index,不用管!!
【训练样本路径】
4、 train_input_reader: {tf_record_input_reader {input_path: "./data/annotations/train.record" # 训练集tfrecord位置,
5、 label_map_path: "./data/annotations/label_map.pbtxt" # 标注文件位置
【测试样本路径】
6、 eval_input_reader: {tf_record_input_reader {input_path: "./data/annotations/test.record" # 测试集tfrecord位置,
7、 label_map_path: "./data/annotations/label_map.pbtxt" # 标注文件位置
1.6 开始训练!!!
# 训练指令: 注意: tensorflow 1.15版本,要降低numpy!!
# pipeline_config_path:配置文件位置
# model_dir:训练好的模型保存位置
# num_train_steps:训练步数, 推荐 1-5 w步数!! 后面的参数不用管,固定的参数!!
python ./model_main.py --pipeline_config_path=./data/ssdlite_mobilenet_v2_coco.config --model_dir=./my_model_dir --num_train_steps=100000 --sample_1_of_n_eval_examples=1 --alsologtostderr
# 报错!!! NotImplementedError: Cannot convert a symbolic Tensor (cond_2/strided_slice:0) to a numpy array.
原因: numpy版本过高 1.21.6,numpy降级一下, pip uninstall numpy , pip install numpy==1.19.5
# 数据可视化: tensorboard --logdir=./my_model_dir
total-loss,一般降到 4以下,就是相当不错!!!
# 训练太慢了,请调 batch_size ,调大!!! 训练比较耗时...
1.7 导出推理模型 !!
# --pipeline_config_path:配置文件位置
# --trained_checkpoint_prefix:训练好的模型checkpoint(忽略后面的.meta,model.ckpt-100000)
# --output_directory:生成的推理文件位置(生成文件夹)
python ./export_inference_graph.py --input_type=image_tensor --pipeline_config_path=./data/ssdlite_mobilenet_v2_coco.config --trained_checkpoint_prefix=./my_model_dir/model.ckpt-100000 --output_directory=./inference_model
1.8 使用、导出的推理模型 !! 环境:course_tf2_env !!!
复制 tf_test.py,到我们刚才导出的推理模型,文件夹!!!
修改: tf_test.py
1、复制lable标签,到同级目录!!【lable_map.pbtxt】 # path_to_lable: 填在这里!!
2、detection_model = tf.saved_model.load('./saved_model') # 同级目录修改下!!!更改!!!
测试 python .\tf_test.py
# 报错: UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd5 in position 74: invalid continuation byte
# 报错原因: path_to_lable: 名字写错了!!! 修改完成,测试成功!!! 帧率 50-60左右!!速度可以,效果一般!!! 因为,数据标注不太好,小目标!
三、openvino转ssdlite_mobilenet_v2 模型:
2.1、openvino: intel公司的 推出的,加速-模型推理,sdk包, 作用: 加速模型推理!!!
有点类似于英伟达的tensor-rt 推理引擎!
深度学习: 一般情况,训练和部署是分开的, 部署的时候,精度维持的情况下,当然希望越快越好!
openvino ,他就可以做中间的转化,把各个神经网路框架的模型,放在自家的cpu上进行加速!
流程: pytorch、tensorflow、caffe、mxnet、keras、onnx等模型 -->> openvino,转化为可执行表达文件 --->> intel 自己的cpu、gpu、igpu、vpu上加速运行!
按步骤,创建3.7的环境:
conda create -n course_openvino_2021.4.0 python=3.7 一定要 3.7的,3.6的会报错!!!!
1、安装openvino环境、及其开发套件!!
openvino: 推理引擎、 openvino-dev:开发者套件、优化、转化等..... 仅需推理、装openvino即可!!!
每个版本不一样,容易踩坑、树莓派也能安装这个版本!
pip install openvino==2021.4.0
pip install openvino-dev[tensorflow,onnx]==2021.4.0 # 开发者套件、需要什么框架、往里丢、如:【tensorflow、onnx、pytorch】
# mo -h 验证是否,正常安装!!
2.2 COCO数据集,预训练模型转openvino
# 进入COCO数据集预训练模型文件夹
cd 4.转openvino/coco
# 安装tensorflow==2.2.0
pip install tensorflow==2.2.0
# 转化
# input_model:需要转的推理模型、预训练的模型...
# transformations_config、tensorflow_object_detection_api_pipeline_config:模型需要的配置信息
ssd_v2_support.json 很难找,官方git要找很久... ssd_support_api_v2.json【因为,tf版本 2.2】
# output_dir:转换后模型的保存路径、转化到的文件夹
# ssd_v2_support.json来源:
mo --input_model=./ssdlite_mobilenet_v2_coco_2018_05_09/frozen_inference_graph.pb --transformations_config=./ssd_v2_support.json --tensorflow_object_detection_api_pipeline_config=./ssdlite_mobilenet_v2_coco_2018_05_09/pipeline.config --output_dir=./ir_model
# 报错!!! probuf需要降级: pip install protobuf==3.19
# 成功!!! .xml是网络架构!!! .bin 二进制文件,权重信息!!!
# 运行
# m:openvino模型、即是上述 xml 网络架构!!!
# d:运算设备(CPU, GPU, FPGA, HDDL or MYRIAD神经加速棒!)
python demo.py -m ir_model/frozen_inference_graph.xml -d CPU
# coco的预训练模型、只能识别 80种物体!!!
# 同步:150-200帧、 异步多线程:1000帧、突破上限!
2.3 转化,我们已经训练好的模型
# 进入训练好的自定义数据模型
cd 4.转openvino/poker
# 切回自己训练的 tf环境!! 降版本 tensorflow!!
# 安装tensorflow==1.15
pip install tensorflow==1.15
# 转化
# input_model:需要转的推理模型
# transformations_config、tensorflow_object_detection_api_pipeline_config:模型需要的配置信息、ssd_support_api_v1.15.json【因为,tf版本 1.15】
# output_dir:转换后模型的保存路径
mo --input_model=./poker_infer_model/frozen_inference_graph.pb --transformations_config=./ssd_support_api_v1.15.json --tensorflow_object_detection_api_pipeline_config=./poker_infer_model/pipeline.config --output_dir=./ir_model
# 运行
# m:openvino模型
# d:运算设备(CPU, GPU, FPGA, HDDL or MYRIAD)
python demo.py -m ir_model/frozen_inference_graph.xml -d CPU # 毕竟是轻量级检测模型、所以、针对大目标检测模型,效果比较好!!!
三、YOLOV5模型转openvino模型 【pytorch + yolov5 + openvino】
3.1 Pacal VOC数据集转为COCO格式
复制 \2.yolov5\convert_voc_to_yolo.py至数据集目录下, data目录里!!
运行python convert_voc_to_yolo.py开始转换、 # 因为标注文件,是.xml格式,Pascal voc数据集,我们要将他转为,coco格式的 txt数据集!!
#### 生成 一个 lables文件夹、里面有训练集和测试集,的标注数据!!! ###
labelImg验证转换后的格式是否正确。
#### 不放心的话,打开标注文件的文件夹,查看是否正确, ###
1、打开 labelImg, 2、选择打开文件夹:image,选择保存文件夹:label 3、更改格式: 为yolov
4、不保存!!!! 5、分类文件txt复制到,对应的test标注集里!!!(缺少一个,类别文件classes.txt),正确打开!!!
3.2 训练及可视化
参考《YOLOV5安全头盔防护服检测》流程。
1、修改coco128.yaml的三个路径,分别写入52个类别... 2、修改yolov5n.yaml的nc数量==52
3、样本较大,不需要、使用预训练模型,训练!!!
#python .\train.py --data .\data\coco_chv.yaml --cfg .\models\yolov5n_chv.yaml --weights .\weights\yolov5n.pt --batch-size 20 --epochs 120 --workers 4 --name base_n --project yolo_test # 小样本、中样本
python train.py --data custom.yaml --weights '' --cfg yolov5s.yaml # 大样本、本次采用的方式!!!
# 正确训练命令!!!
#python .\train.py --data .\data\coco_chv.yaml --cfg .\models\yolov5n_chv.yaml --weights '' --batch-size 20 --epochs 120 --workers 4 --name base_n --project yolo_test
python .\train.py --data .\data\coco_chv.yaml --cfg .\models\yolov5n_chv.yaml --batch-size 20 --epochs 100 --workers 4 --name poker_base_n --project yolo_test_poker # 报错,没找到dataset,因为 val的路径写错了,应该是 test!!! epoch--100就好!!
3.3 运行pytorch CPU版Demo
# 复制附件:\2.yolov5\1.torch版 至一个空的文件夹
# 创建一个新的虚拟环境
conda create -n course_torch_openvino python=3.7 # 3.6的opencv安装,报错!!
# 安装pytorch CPU版、但训练要用 gpu版本!! cpu版本、只是为了对比一下加速效果!!!
pip install torch torchvision torchaudio
# 安装YOLOv5
cd yolov5
pip install -r requirements.txt
# 返回上层目录,运行
cd ../
python demo.py # 速度差点、但是精度很满意!
3.4 YOLOV5转换openvino
# Open Neural Network Exchange 、 开放-神经网络-转化器、作为中转器: yolov5-> onnx -->> openvino !!!
pip install onnx==1.11.0
# 修改export.py line 121
opset_version=10 # 因为 onnx官方,版本不支持更高版本的原因!!!给他定死!
# 导出onnx、yolov5的文件夹,会生成 onnx文件: poker_n.pt
cd yolov5
python export.py --weights ../weights/poker_n.pt --img 640 --batch 1
# 转换为openvino、
# 安装openvino及openvino-dev
pip install openvino-dev[onnx]==2021.4.0 # 开发者套件:只需要onnx即可!! openvino-dev
pip install openvino==2021.4.0 # 推理引擎: openvino
# 安装netron:::专门查看 网络结构的工具!!!
实战项目11:\2.yolov5\3.netron安装包 # dmg苹果版的,exe是win版的...
# netron查看模型架构
1、选择:导出模型 2、路径:转化后的onnx路径,weights目录 3、选择对应的 .onnx 后缀的文件....
# 水平显示: views-> show horizontal !!
# 定位:几个输出层: ctrl+f 搜索: transpose
# 全输出,需要自己修改Conv_294,Conv_245,Conv_196为自己查询的结果::
我的名称是: /model.24/m.0/Conv、/model.24/m.1/Conv、/model.24/m.2/Conv
目的: 去掉小目标检测,去掉最小的卷积核!!!== 去掉最大的特征图!!!
对于我而言,就是去掉 m0层的,小目标检测,提升检测速度!!!
#### 命令!!! ####
# input_model:需要转换的模型
# model_name:导出名称
# s:原始网络输入将除以该值,÷255 ==归一化...
# reverse_input_channels:RGB 转变为 BGR(或者从 BGR 转变为 RGB)
# output: 模型的输出操作
cd ..
# mo --input_model weights/poker_n.onnx --model_name weights/ir_model_full -s 255 --reverse_input_channels --output Conv_264,Conv_230,Conv_196
mo --input_model weights/poker_n.onnx --model_name weights/ir_model_full -s 255 --reverse_input_channels --output /model.24/m.0/Conv,/model.24/m.1/Conv,/model.24/m.2/Conv # 紧接着,在weights目录下,就会生成 三个文件了!!ir_model_full....
# 加速,丢弃小目标检测
#mo --input_model weights/poker_n.onnx --model_name weights/ir_model_part -s 255 --reverse_input_channels --output Conv_264,Conv_230
mo --input_model weights/poker_n.onnx --model_name weights/ir_model_part -s 255 --reverse_input_channels --output /model.24/m.1/Conv,/model.24/m.2/Conv # 对于我而言,是,去掉了/model.24/m.0/Conv,== 关闭掉,小目标检测!!!
# 测试运行
复制:\2.yolov5\2.openvino版\yolov5_demo.py 到weights同级目录,做测试!!!!
# 运行
# 完全版、和部分版,测试!! 部分版:去掉小目标检测
python yolov5_demo.py -i cam -m weights/ir_model_full.xml -d CPU
python yolov5_demo.py -i cam -m weights/ir_model_part.xml -d CPU
# 结果!!!
完全版: +小目标检测: 同步/异步: 15-18帧率,
部分版: -小目标检测: 同步/异步: 65-70帧率,极大地提升!!!
# 结论:
大部分场景、扔掉了小目标检测,可以获得极大的帧率提升,是够用的,
但是,在,距离非常远的情况下,则不能舍弃!!!


vgg 16

vgg 16 的网络架构 
ssd对vgg 16的改动

ssd对vgg 16的改动