初识rabbitmq
最近因为自己做的项目需要使用到rabbitmq,所以心血来潮,写一篇关于rabbitmq的博客。
这篇博客会简要介绍下使用docker在云服务器搭建rabbitmq,AMQP协议,rabbitmq的作用以及为什么要使用rabbitmq
让我们从搭建rabbitmq开始吧~
这里我建议大家使用docker进行搭建。因为windows搭建rabbitmq实在是太麻烦了。
废话不多说,让我们现在使用阿里云服务器把它给运行起来吧~
dockerf云服务器搭建rabbimq
使用命令拉取镜像:
docker pull rabbitmq:management

这里 我们以守护态的形式把rabbitmq运行在本地端口上~
docker run -d --name rabbit -p 15672:15672 rabbitmq:management
![]()
接下来我们就可以看到它运行到咱们的云服务器上了~

默认的用户名和密码都是guest
rabbitmq运行在服务器上的默认web界面
在这个页面上 我们看到它是由Erlang语言编写的
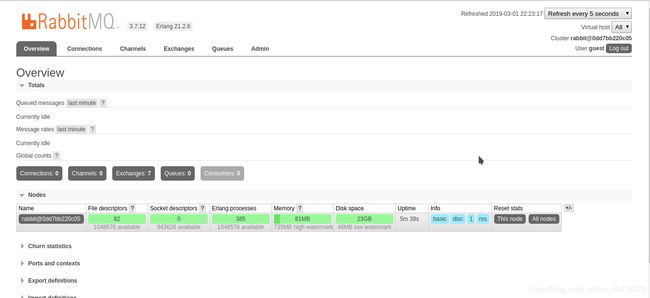
咱们看看Erlang语言的介绍:
Erlang支持超大量级的并发进程,并且不需要操作系统具有并发机制。Erlang编写的程序不仅有健壮性,还具有多种基本的错误检测能力,它们比较使用用于构建容错系统。
作为处理高并发的工具,它的稳定性是我们值得信赖的。在这个界面上 我们看到了连接Connection,通道Channels,交换机Exchanges以及队列Queues,这些我将会在后面慢慢细说。
什么是AMQP协议
现在我主要介绍一下,rabbitmq的一个核心AMQP(Advanced Message Queuing Protocol高级消息队列协议)协议

如今AMQP高级消息队列协议1.0已被批准为国际标准,OASIS标准。
让我们看看官网是怎么描述它的

是一个关于消息传递中间件的开放协议,通过遵守这个协议,不同平台,不同语言之间可以互相发消息了。AMQP解决了不同组织之间及时传递有价值信息的问题。AMQP使消息中间件有了互操作性,不同的网络协议和代理服务的语义都被定义在AMQP上
通俗一点说:AMQP一个定义在通讯中的协议,这套协议统一规定了双方和容器和各个组件所需要遵守的约定和规则。
而咱们的rabbitmq就是实AMQP的一种实现,在AMQP协议下,两个不同应用传递消息时,消息的发送不会马上到接受者手中,而是通过规则分发存放在了一个个容器里。当满足一定条件之后,才能从容器中取出这个消息。
在rabbitmq这里发送消息的人我们称作生产者(Producer),接收消息的人我们称作消费者(Consumer),这个容器就是队列(Queue),这个分发就是消息交换机(Exchange),它规定了什么规则和路由到哪个队列,这个规则我们称之为绑定(Binding)。
rabbitmq的作用
说了这么多,那么rabbitmq有什么用呢?让我们看下官网是怎么形容的

rabbitmq是一个消息代理,它接收和转发消息,你可以认为它是一个邮差,当你把要发布的邮件放到邮箱的时候,你可以确定邮件最终会发到收件人的手里。
rabbitmq只是一个容器,它既不是写信的人,也不是收信的人,它只是一个“邮差”。而这个邮差能接受的“信件容量”,就是存储器和磁盘容量本质上是一个消息缓冲器。也就是我们说的 消息队列 。
为什么要使用消息队列?
微服务之间是通过轻量级的通讯协议进行通信,而网络常常也相对脆弱、网络资源也相当有限。 如果我们能够跟踪每一个请求,了解请 求经过哪些微服务、请求的耗时、网络延迟、业务逻辑耗时这些指标,这样我们就能够更好的分析系统的瓶颈、针对的解决系统问题。因此、我们微服务体系中加上跟踪还是很有必要的。
消息的收发是异步的,消息的发送者生产者在等待确认的同时,还可以继续发送消息,避免因消息的发送而导致的阻塞。当确认消息到达生产者应用程序,生产者应用程序的回调方法就会被触发来处理确认消息。在高并发的情况下,利用消息队列达到削峰的作用。
如有错误,欢迎在博客下方评论我会第一时间回复,转发请注明出处谢谢。
参考资料:
- rabbitmq官网 http://www.rabbitmq.com/
- AMQP官网 http://www.amqp.org/