机器学习第2天:训练数据的获取与处理
文章目录
数据的获取
简单的数据操作
数据保存
数据的读取
数据的操作
(1)按列索引
(2)按行索引
(3)iloc索引
数据分析示例
数据特征
数据关系
结语
数据的获取
我们知道机器学习的关键是数据和算法,提到数据,我们必须要有在这个大数据时代挑选我们需要的,优质的数据来训练我们的模型,这里分享几个数据获取平台
Kaggle Datasets Find Open Datasets and Machine Learning Projects | Kaggle
UC Home - UCI Machine Learning Repository
简单的数据操作
数据保存
我们收集到的数据有时是杂乱的,这时我们可以用python的pandas库来将数据保存为csv格式(excel表的一种格式)
以下是一个简单示例
import pandas as pd
dic = {'name': ['mike', 'tom', 'jane'], 'height': [178, 155, 163]}
df1 = pd.DataFrame(dic) # 将字典转化为DataFrame格式,这是一种pandas适配的二维存储格式
df1.to_csv("test.csv", index=False)举一反三,当我们获取到数据的时候,将它们保存为列表并设置索引后,就可以如示例一样保存为csv文件了,这里将index设置为False,否则会多出来一行索引列,之后我们读取数据时可以直接按序号索引,所以不必多出这一行
打开文件效果如下
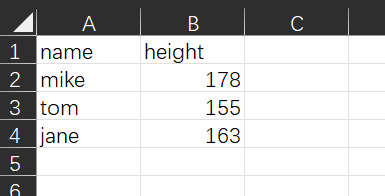
数据的读取
我们同样是用pandas来处理数据,使用刚刚的文件,一个简单示例如下
import pandas as pd
s = pd.read_csv("test.csv")
print(s)运行结果如下
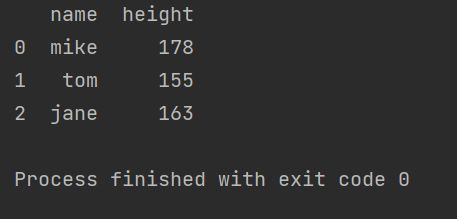
数据的操作
一个基本的操作csv表的方式就是按行按列索引了,我们同样按之前的文件来举个简单的例子
(1)按列索引
import pandas as pd
s = pd.read_csv("test.csv")
print(s["name"])运行结果
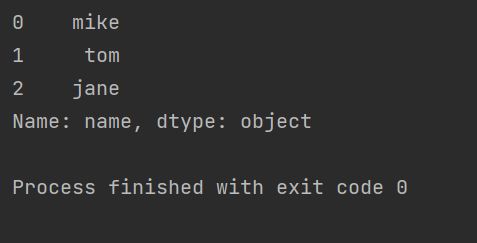
(2)按行索引
注意,当我们直接这样按行索引,是会报错的
import pandas as pd
s = pd.read_csv("test.csv")
print(s[0])这里我们介绍一种非常方便的索引方法,往下看
(3)iloc索引
iloc是一个通用的数据索引方法,让我们来看看怎么用吧
s.iloc[行,列] #一个伪代码iloc的参数用逗号隔开,前面是行的位置,后面是列的位置,例如
import pandas as pd
s = pd.read_csv("test.csv")
print(s.iloc[0, 0])我们将获得第一行第一列的值

iloc也支持切片操作,例如
import pandas as pd
s = pd.read_csv("test.csv")
print(s.iloc[:, 0])将打印第一列的所有行

数据分析示例
在这一部分我们以经典的鸢尾花数据集为例,简单介绍一下:鸢尾花数据集包括了花的种类,花瓣和花萼的长度与宽度,共五列数据,然后我们要训练一个通过花瓣,花萼长宽数据来判断品种的机器学习模型,机器学习的任务请参考这篇文章:机器学习第一天:概念与体系漫游-CSDN博客
部分数据如下
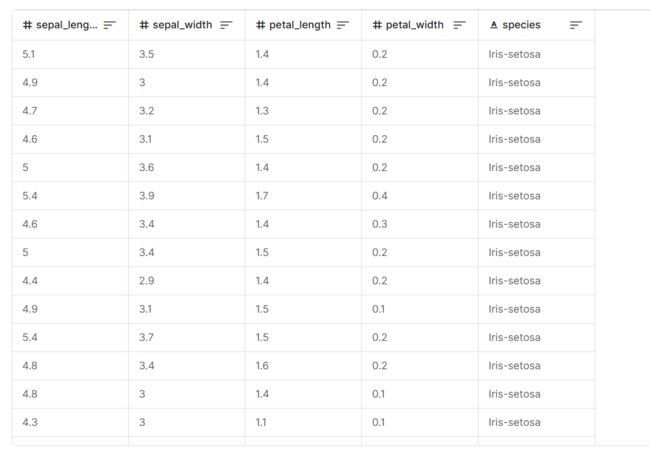
数据特征
我们来分析这个数据集的特征
value_counts()
import pandas as pd
iris = pd.read_csv("/kaggle/input/iris-flower-dataset/IRIS.csv")
iris['species'].value_counts()这里我们读取了数据集并命名为iris,然后我们统计species这一列的数据数量,得到

可以看到,三种花的种类的数据各50个
describe()
iris.describe()这个方法可以获得所有数字列的数字特征

如图可见,给出了我们数字列的数据个数,平均数,标准差,最小值等 ,通过这个方法我们可以遍观整个数据集
数据关系
接下来我们查看数据关系,这里不对具体代码做说明,仅分析意义,有兴趣的读者可以去搜索鸢尾花分类任务详细了解
我们将花萼的长和宽以散点图的形式绘制出来
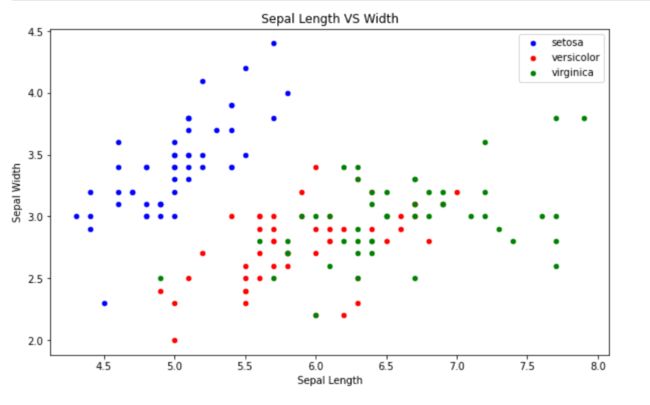
再将花瓣的长和宽绘制出来
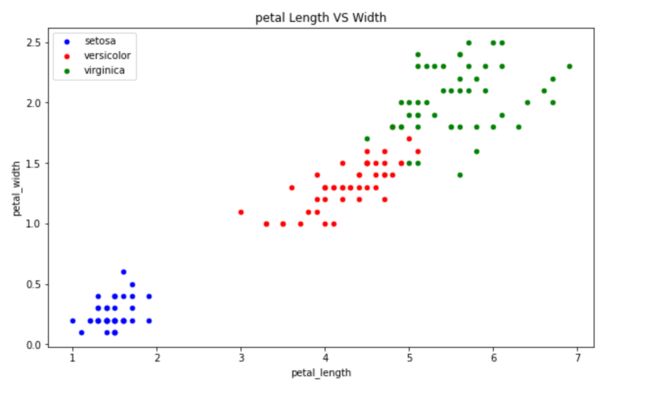
明显可以看到,花瓣长宽图中不同颜色的点(代表不同花的种类)比花萼长宽图中更加分布鲜明
这就代表,不同的鸢尾花品种,花瓣的长宽一般有很大区别,那我们在训练模型的时候就可以把花瓣长宽作为数据训练,得到的模型效果将比用花萼长宽训练出来的效果更好
这就是数据分析的意义之一:找到强特征
结语
数据的获取,处理与分析是机器学习中一个重要的过程,好的数据分析与好的算法一样重要,数据分析有许多方法,这里仅带读者了解一下,欢迎收藏,之后也许还会补充内容