论文阅读笔记:Tailor A soft-prompt-based approach to attribute-based controlled text generation
文章的主要工作
(1)提出了一种基于软提示的属性驱动 CTG 方法,名为 Tailor。为了在统一的范式中同时包括单属性和多属性 CTG,Tailor 使用一组预训练的前缀来引导一个固定的PLM生成具有预定义属性的句子,然后有效地将它们连接起来生成多属性句子。
(2)通过实验揭示了连续提示的组合能力。为了增强这种组合,在单属性 CTG 后探索了两种有效的策略,一种是无需训练的策略(MAP mask + RP sequence),另一种是需要训练的策略(MAP connector)。特别是,MAP connector 在六个多属性生成任务上取得了出色的表现,甚至在未见过的任务上也表现出色。
Tailor for 单属性CTG
总体架构

方法
与为每个属性微调一整份预训练语言模型(PLMs)的方法不同,我们的基本理念是用一组预训练的连续向量——即单属性提示符——来引导预训练语言模型的生成。
与此同时,每个提示符代表一个期望的属性。我们固定了GPT-2的参数,并在与属性相关的数据上训练每个提示符。经过训练,这些提示符可以作为期望的单属性条件文本生成(CTG)的插件。例如,对于前缀“Once upon a time”,GPT-2可以在表示墨西哥食品主题的提示符引导下续写“I had to order my tacos …”,或者在表示积极情感的提示符引导下续写“the food was good”。通过这种方式,我们的方法可以轻松扩展:如果出现新的属性,我们只需要训练一个属性提示符,然后控制一个PLM生成特定属性的句子。确切地说,我们采用语言模型学习目标来训练这样一组单属性提示符。
详细来说,首先随机初始化第k个单属性提示 S k S_k Sk ,其长度为 l k l_k lk,其中 S k ∈ R l k × d e m b S_k \in \mathbb{R}^{l_k \times d_{emb}} Sk∈Rlk×demb 。这里的 d e m b d_{emb} demb 是GPT-2的词嵌入维度。同时,给定一个特定属性的句子 x = { x 1 , x 2 , . . . , x n } x = \{x_1, x_2, ..., x_n\} x={x1,x2,...,xn} ,长度为 n n n,我们通过GPT-2嵌入后得到一个词序列矩阵 X e m b ∈ R n × d e m b X_{emb} \in \mathbb{R}^{n \times d_{emb}} Xemb∈Rn×demb 。接着,将 S k S_k Sk 与 X e m b X_{emb} Xemb 进行拼接,形成一个输入矩阵 [ S k ; X e m b ] ∈ R ( l k + n ) × d e m b [S_k; X_{emb}] \in \mathbb{R}^{(l_k+n) \times d_{emb}} [Sk;Xemb]∈R(lk+n)×demb ,该矩阵随后被送入一个固定的GPT-2模型中。最终,基于语言模型的学习目标是:
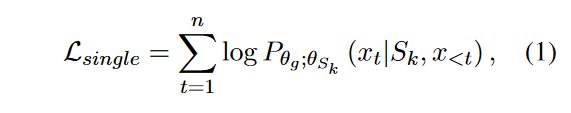
其中, θ g \theta_g θg 和 θ S k \theta_{S_k} θSk 分别代表GPT-2模型和单属性提示的参数。在训练阶段,仅更新 θ S k \theta_{S_k} θSk 参数。
这句话说明了在训练过程中,GPT-2模型的参数 θ g \theta_g θg 保持不变,而只有与单属性提示 S k S_k Sk 相关的参数 θ S k \theta_{S_k} θSk 会得到更新。这通常是为了调整模型以更好地适应特定的属性,同时保持模型对其他知识的普遍性不变。
Tailor for 多属性CTG
总体架构

无需训练的策略
简单来说是将单属性提示简单的串联起来。
为了更好地利用单属性提示(single-attribute prompts),缩小训练阶段(每个任务对应一个单属性提示)与测试阶段(将多个单属性提示串联起来)之间的差异无疑是重要的。在多属性连续文本生成(multiattribute CTG)的测试阶段,第二个提示也会关注到第一个提示的串联,同时位置嵌入也发生变化。为了填补这一差距,我们在生成时向固定的预训练语言模型(PLM)中引入了MAP mask和RP sequence。MAP遮罩避免了单属性提示表示之间的交叉注意力,以逼近单属性CTG训练阶段的条件。同时,RP序列为交换保持了稳定的提示位置,防止了这种串联范式对位置的敏感性。
MAP Mask
为了便于实施,我们将MAP mask矩阵 M p M_p Mp引入到了GPT-2的softmax逻辑中。给定一个普通的注意力模块:

其中 n n n是输入句子 x x x的长度, Q , K Q,K Q,K分别表示query和key的表示。对于MAP Mask,给定两个单属性提示 S u S_u Su, S v S_v Sv,长度分别为 l u l_u lu, l v l_v lv,则注意力模块为修改为:
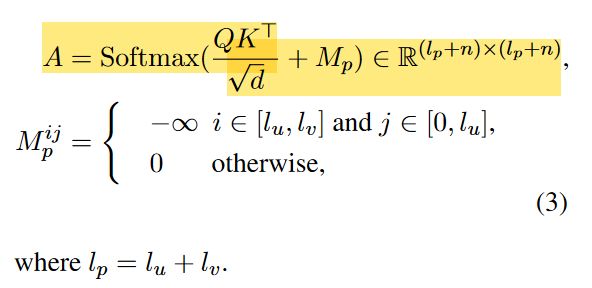
RP Sequence
在连接时修改了 PLM 的位置序列,对于给定的原始序列:
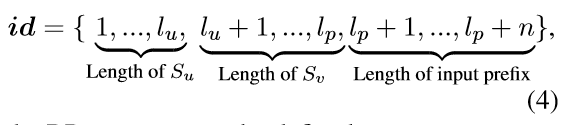
RP序列可以定义为:
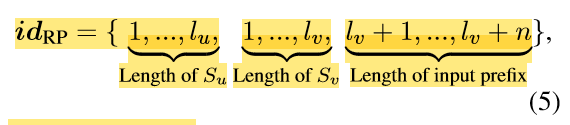
请注意, l v = l u l_v = l_u lv=lu。在这种情况下,交换不会带来任何变化,因为提示的位置是由 RP 序列固定的,同时避免了 MAP 掩码的交叉注意力。
需要训练的策略
MAP连接器,它也是一种训练的连续提示,用于将两个单属性提示组合成多属性CTG。为了仅利用单属性句子进行多属性 CTG,提出了一种基于伪属性提示的 MAP 连接器训练策略。伪属性提示构建方法和MAP连接器的工作流程详细信息如下:
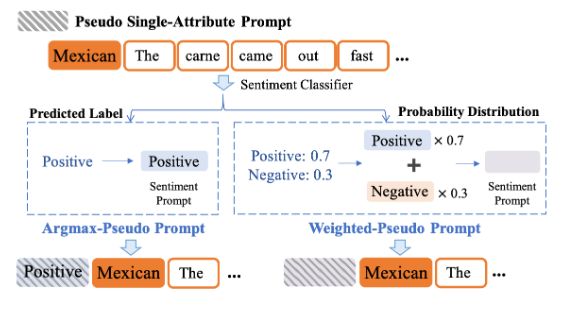
构建伪单属性提示
核心理念在于为每一个单属性句子构建另一个伪属性提示符,这样MAP(多属性)连接器就能在多属性环境中进行训练。构建方法概览在上图中展示,其中以墨西哥食物为主题的句子作为展示案例。确切地说,我们首先在相同的单属性CTG(有条件的文本生成)训练集上训练一个属性分类器。因此,这样一个具有 n c l a s s n_{class} nclass个类别的分类器对应于预训练的单属性提示集合 S = S 1 , S 2 , . . . , S n c l a s s S = {S_1, S_2, ..., S_{n_{class}}} S=S1,S2,...,Snclass。给定一个具有其他属性类别的特定属性句子 x x x,我们首先获得类概率集合 p = p 1 , p 2 , . . . , p n c l a s s p = {p_1, p_2, ..., p_{n_{class}}} p=p1,p2,...,pnclass。然后,可以通过两种方法获得伪单属性提示符:

其中argmax-伪提示方法利用预测情绪对应的单属性提示得到伪提示 S a S_a Sa, I n d e x ( ⋅ ) Index(·) Index(⋅)表示得到对应的索引。
相比之下,加权伪提示方法利用预测的概率分布分别乘以相应的单属性提示。然后这些加权提示通过逐元素相加形成一个完整的提示 S w S_w Sw。
MAP 连接器工作流程
在训练阶段,我们将包含不同单一属性的句子统一起来,以训练MAP(多属性提示)连接器,每个句子都通过前述方法加上了一个额外的伪单属性提示(用斜线图案的框表示)。具体来说,对于每一个训练样本,我们首先将两个单一属性提示(真实的和伪造的)、MAP连接器以及输入句子连接成一个序列,然后输入到一个固定的GPT-2模型中。值得注意的是,在训练阶段,只有MAP连接器的参数会被更新。因此,给定两个单一属性提示 S u S_u Su和 S v S_v Sv,以及长度为 l C l_C lC的MAP连接器 C C C,其中 C ∈ R l C × d emb C \in \mathbb{R}^{l_C \times d_{\text{emb}}} C∈RlC×demb,我们将 S u S_u Su、 S v S_v Sv、 C C C以及输入句子的矩阵 X emb X_{\text{emb}} Xemb连接起来,形成一个输入矩阵表示为 [ S u ; S v ; C ; X emb ] [S_u; S_v; C; X_{\text{emb}}] [Su;Sv;C;Xemb]。学习目标是:
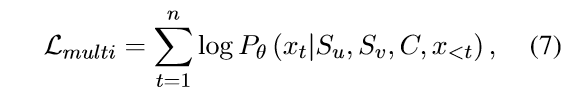
在上文中, θ \theta θ 表示模型的参数集合,可以被表示为 θ = [ θ g ; θ S u ; θ S v ; θ C ] \theta = [\theta_g; \theta_{S_u}; \theta_{S_v}; \theta_C ] θ=[θg;θSu;θSv;θC]。这里的 θ g \theta_g θg、 θ S u \theta_{S_u} θSu、 θ S v \theta_{S_v} θSv 和 θ C \theta_C θC 分别代表GPT-2、两个单一属性提示以及MAP连接器的参数。在训练阶段,仅有 θ C \theta_C θC(即MAP连接器的参数)会被更新。
到了推理阶段,我们将每个多属性生成任务分解为若干个单一属性生成任务,并寻找对应的单一属性提示。然后,这些提示将与MAP连接器连接起来,以生成满足多属性的句子。
在这个过程中,MAP连接器扮演了一个关键角色,因为它能够整合来自单一属性提示的信息,并将这些信息有效地转换为能够指导GPT-2生成满足特定多属性要求的文本。通过这种方式,模型能够在没有直接训练多属性任务的情况下,灵活地处理这类任务,从而提高了其在复杂文本生成任务中的适用性和效率。