Spark Streaming提取数据
一、简介
Spark Streaming是一个从各种来源获取实时流数据的框架。它支持的流资包括HDFS、Kafka、Flume以及自定义流等。Spark Streaming操作可以从故障中自动恢复,这对于在线数据处理十分重要。Spark Streaming表示使用离散流(DStream)的流数据,该数据流周期性的创建包含最后一个时间窗口中进入的数据的RDD.
Spark Streaing可以与单个程序中的其他Spark组建结合,将实时处理与机器学习、SQL和图形操作统一起来。从Spark2.0开始,新的结构化流式API使Spark流程序更像Spark批处理程序。

二、Maven添加依赖
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
// 会使用kafka做数据源
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.5</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.4.5</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.4.5</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.5</version>
</dependency>
三、spark streaming提取数据
spark steaming提供了很多内置接收器,其中又分为基础数据源(文件系统、套接字等)和高级数据源(kafka、flume等),当然也支持用户自定接收器
数据源
1、Socket数据源
可以使用Spark Streaming直接从TCP/IP套接字接收数据,代码如下:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreamDemo1 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkStream")
// 创建StreamingContext实例,指定3秒为每次采集的时间间隔
val streamingContext = new StreamingContext(conf,Seconds(3))
// 指定采集的方法,采用socket做数据源
val socketLineStream: ReceiverInputDStream[String] = streamingContext.socketTextStream("192.168.233.133",7777) // 指定ip和端口号
// 将采集的信息进行处理,统计数据(wordcount)
val wordStream: DStream[String] = socketLineStream.flatMap(line=>line.split("\\s+")) // 以空格作为分隔符
val mapStream: DStream[(String, Int)] = wordStream.map(x=>(x,1)) // 形成键值对
val wordcountStream: DStream[(String, Int)] = mapStream.reduceByKey(_+_) // 统计单词个数
// 打印,此处print并不会直接触发 job 的执行,对于 Spark Streaming 而言具体是否触发真正的 job 运行,是基于设置的采集时间间隔
// 要注意的是 Spark Streaming应用程序要想执行具体的Job,对DStream就必须有 output Stream操作,如:print,saveAsTextFile,saveAsHadoopFile等
wordcountStream.print()
// 启动采集器
streamingContext.start()
// 等待结束,监控一个线程的中断操作
streamingContext.awaitTermination()
}
}
2、文件数据源
文件数据流:能够读取所有HDFS API兼容的文件系统文件,通过fileStream方法进行读取。Spark Streaming 将会监控 dataDirectory 目录并不断处理移动进来的文件,文件进入 dataDirectory的方式需要通过移动或者重命名来实现。一旦文件移动进目录,则不能再修改,即便修改了也不会读取新数据。
如果文件比较简单,则可以使用 textFileStream(dataDirectory)方法来读取文件。
依然以wordcount为例:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreamFileDataSourceDemo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("fileDataSource")
val streamingContext = new StreamingContext(conf,Seconds(5))
// 通过读取文件的方式创建DStream
val fileDStream: DStream[String] = streamingContext.textFileStream("file:///f:/test/")
val wordStream: DStream[String] = fileDStream.flatMap(line=>line.split("\\s+"))
val mapStream: DStream[(String, Int)] = wordStream.map((_,1))
val sumStream: DStream[(String, Int)] = mapStream.reduceByKey(_+_)
sumStream.print()
streamingContext.start()
streamingContext.awaitTermination()
}
}
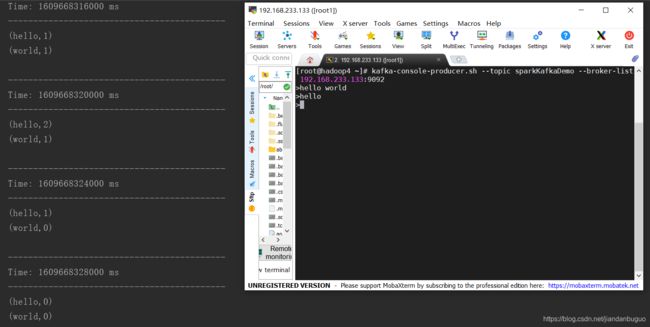
3、kafka数据源
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreamKafkaSource {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("kafkaSource")
val streamingContext = new StreamingContext(conf,Seconds(5))
// 设置检查点,用于容错处理
streamingContext.checkpoint("checkpoint")
// 想要从Kafka中读取数据,需要设置参数映射
val kafkaParams: Map[String, String] = Map(
(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "192.168.233.133:9092"),
(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.GROUP_ID_CONFIG, "kafkaGroup1")
)
// 创建DSteam
val kafkaStream: InputDStream[ConsumerRecord[String,String]] = KafkaUtils.createDirectStream(
streamingContext,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe(Set("sparkKafkaDemo"), kafkaParams)
)
// wordCount
val wordStream: DStream[String] = kafkaStream.flatMap(v=>v.value().toString.split("\\s+"))
val mapStream: DStream[(String, Int)] = wordStream.map((_,1))
val sumStream: DStream[(String, Int)] = mapStream.reduceByKey(_+_)
sumStream.print()
streamingContext.start()
streamingContext.awaitTermination()
}
}
4、自定义接收器
自定义接收器要实现org.apache.spark.streaming.receiver.Receiver类来从其他的数据源中接收数据。
所有的自定义接收器必须扩展Receiver抽象类,并且实现其中两个方法:
- 1、onStart():这个函数主要负责启动数据接收相关的事情;
- 2、onStop():这个函数主要负责停止数据接收相关的事情。
不管是onStart()和onStop()方法都不可以无限期地阻塞。通常情况下,onStart()会启动相关线程负责接收数据,而onStop()会保证接收数据的线程被终止。接收数据的线程也可以使用Receiver类提供的isStopped()方法来检测是否可以停止接收数据。
数据一旦被接收,这些数据可以通过调用store(data)方法存储在Spark中,store(data)方法是由Receiver类提供的。Receiver类提供了一系列的store()方法,使得我们可以把一条一条地或者多条记录存储在Spark中。值得注意的是,使用某个store()方法实现接收器将会影响其可靠性和容错性,这将在后面详细地讨论。
接收线程中可能会出现任何异常,这些异常都需要被捕获,并且恰当地处理来避免接收器挂掉。restart()将通过异步地调用onStop()和onStart() 方法来重启接收器。stop()将会调用onStop()方法并且中止接收器。同样, reportError()将会向Driver发送错误信息(这些错误信息可以在logs和UI中看到),而不停止或者重启接收器
import java.io.{BufferedReader, InputStreamReader}
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.receiver.Receiver
// 自定义接收器
class MyReceiver(host:String,port:Int) extends Receiver[String](StorageLevel.MEMORY_ONLY){
// 通过socket获取数据
var socket:java.net.Socket=null;
def receive():Unit={
socket = new java.net.Socket(host,port)
val reader = new BufferedReader(new InputStreamReader(socket.getInputStream,"UTF-8"))
// 调用store(data)方法将数据存储在Spark中
var line:String = null;
while (!isStopped && (line=reader.readLine())!=null){
if(line.equals("end")){
return
}else{
this.store(line)
}
}
}
override def onStart(): Unit = {
// 启动获取数据的线程
new Thread(new Runnable {
override def run(): Unit = {
receive()
}
}).start()
}
override def onStop(): Unit = {
// 停止接受数据时,关闭socket连接
if(socket!=null){
socket.close()
socket=null
}
}
}
object MyReceiverDemo{
def main (args: Array[String] ): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("myReceiver")
val streamingContext = new StreamingContext(conf,Seconds(5))
// 在目标IP:端口上创建带有自定义接收器的输入流
val receiverStream: ReceiverInputDStream[String] = streamingContext.receiverStream(new MyReceiver("192.168.233.133",7777))
// wordCount操作
val lineStream: DStream[String] = receiverStream.flatMap(line=>line.split("\\s+"))
val mapStream: DStream[(String, Int)] = lineStream.map((_,1))
val sumStream: DStream[(String, Int)] = mapStream.reduceByKey(_+_)
sumStream.print()
streamingContext.start()
streamingContext.awaitTermination()
}
}
转换操作
下面列举了一些常用的算子
| 算子 | 解释 |
|---|---|
| map(func) | 对DStream中的各个元素进行func函数操作,然后返回一个新的DStream |
| flatMap(func) | 与map方法类似,只不过各个输入项可以被输出为零个或多个输出项 |
| filter(func) | 过滤出所有函数func返回值为true的DStream元素并返回一个新的DStream |
| repartition(numPartitions) | 增加或减少DStream中的分区数,从而改变DStream的并行度 |
| union(otherStream) | 将源DStream和输入参数为otherDStream的元素合并,并返回一个新的DStream |
| count() | 通过对DStream中的各个RDD中的元素进行计数 |
| reduce(func) | 对源DStream中的各个RDD中的元素利用func进行聚合操作,然后返回只有一个元素的RDD构成的新的DStream |
| countByValue() | 对于元素类型为K的DStream,返回一个元素为(K,Long)键值对形式的新的DStream,Long对应的值为源DStream中各个RDD的key出现的次数 |
| reduceByKey(func, [numTasks]) | 利用func函数对源DStream中的key进行聚合操作,然后返回新的(K,V)对构成的DStream |
| join(otherStream, [numTasks]) | 输入为(K,V)、(K,W)类型的DStream,返回一个新的(K,(V,W))类型的DStream |
| cogroup(otherStream, [numTasks]) | 输入为(K,V)、(K,W)类型的DStream,返回一个新的 (K, Seq[V], Seq[W]) 元组类型的DStream |
| transform(func) | 通过RDD-to-RDD函数作用于DStream中的各个RDD,返回一个新的RDD |
| updateStateByKey(func) | 根据于key的前置状态和key的新值,对key进行更新,返回一个新状态的DStream |
| mapWithState(func)) | mapWithState也会统计全局的key的状态,但是如果没有数据输入,便不会返回之前的key的状态 |
- transform
在数据源读取中已经使用了很多算子,这里重点写写一下transform。transform算子可以用来对DStream和其他的DataSet(rdd)进行运算。比如:将DStream每个批次中的RDD和另一个Dataset进行关联(join)操作,这个功能DStream API并没有直接支持,可以用transform实现。
下面是一个简单的黑名单过滤的例子:
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreamTransform {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("transform")
val streamingContext = new StreamingContext(conf,Seconds(2))
val spark: SparkContext = streamingContext.sparkContext
// 垃圾数据
val blacks = List("zs","ls")
val blackRDD: RDD[(String, String)] = spark.parallelize(blacks).map((_,"true"))
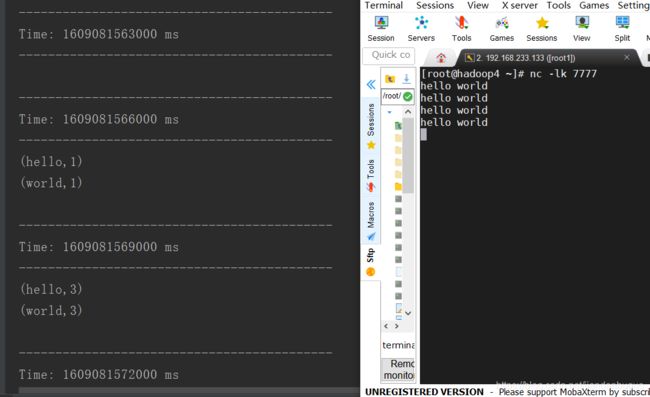
val lines: ReceiverInputDStream[String] = streamingContext.socketTextStream("192.168.233.133",7777)
val resultDStream: DStream[String] = lines.map(x => (x.split(",")(0), x))
.transform(x => {
x.leftOuterJoin(blackRDD) // 将DStream中的RDD和blacksRDD关联,并实时过滤垃圾数据
.filter(x => x._2._2.getOrElse("false") != "true")
.map(x => x._2._1)
})
resultDStream.print()
streamingContext.start()
streamingContext.awaitTermination()
}
}

输出
spark Stream处理后的数据除了能打印到控制台,还可以保存成各种文件类型
| 操作 | 解释 |
|---|---|
| print() | 打印到控制台 |
| saveAsTextFiles(prefix, [suffix]) | 保存DStream的内容为文本文件,文件名为”prefix-TIME_IN_MS[.suffix] |
| saveAsObjectFiles(prefix, [suffix]) | 保存DStream的内容为SequenceFile,文件名为 “prefix-TIME_IN_MS[.suffix]” |
| saveAsHadoopFiles(prefix, [suffix]) | 保存DStream的内容为Hadoop文件,文件名为”prefix-TIME_IN_MS[.suffix]” |
| foreachRDD(func) | 对Dstream里面的每个RDD执行func,并将结果保存到外部系统,如保存到RDD文件中或写入数据库 |
四、窗口操作(window)
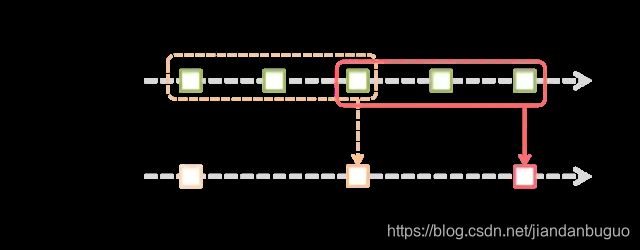
window操作就是窗口函数。Spark Streaming提供了滑动窗口操作的支持,从而让我们可以对一个滑动窗口内的数据执行计算操作。每次掉落在窗口内的RDD的数据,会被聚合起来执行计算操作,然后生成的RDD,会作为window DStream的一个RDD。比如下图中,就是对每3个time时间内的数据执行一次滑动窗口计算,这3个time时间内的3个RDD会被聚合起来进行处理,然后过了2个time时间,又会对最近3个time时间内的数据执行滑动窗口计算。所以每个滑动窗口操作,都必须指定两个参数,窗口长度以及滑动间隔,而且这两个参数值都必须是batch间隔的整数倍。
1、window(windowLength, slideInterval)
传入一个窗口长度参数,一个窗口移动速率参数,然后将当前时刻当前长度窗口中的元素取出形成一个新的DStream
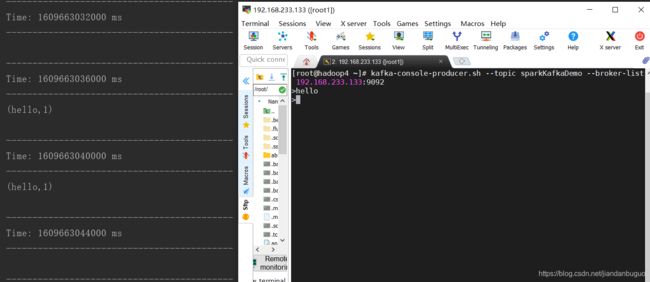
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
object SparkWindowDemo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("kafkaSource2")
val streamingContext = new StreamingContext(conf,Seconds(2))
// 设置检查点路径
streamingContext.checkpoint("checkpoint")
// kafka配置信息
val kafkaParams: Map[String, String] = Map(
(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "192.168.233.133:9092"),
(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.GROUP_ID_CONFIG, "kafkaGroup2")
)
val kafkaStream: InputDStream[ConsumerRecord[String,String]] = KafkaUtils.createDirectStream(
// Streaming上下文
streamingContext,
/*
* LocationStrategies:Kafka消费者的分布策略,有三种策略:PreferBrokers,PreferConsistent,PreferFixed
* PreferBrokers:当Spark集群和Kafka集群属于同一组机器时使用
* PreferConsistent:最常用的策略,当Spark机器和Kafka机器不属于同一组机器时使用
* PreferFixed:当数据分布不均衡,由用户自行制定KafkaPartition和机器的关系
* */
LocationStrategies.PreferConsistent,
// Kafka配置
ConsumerStrategies.Subscribe(Set("sparkKafkaDemo"), kafkaParams)
)
// wordcount操作
val numStream: DStream[(String, Int)] = kafkaStream.flatMap(
line => line.value().toString.split("\\s+"))
.map((_, 1))
.window(Seconds(8),Seconds(4)) // 第一个参数为窗口大小,第二个为滑动时间(选填),默认与批处理时间相同
// 输出到控制台
numStream.print()
streamingContext.start()
streamingContext.awaitTermination()
}
}
2、countByWindow(windowLength,slideInterval)
返回指定长度窗口中的元素个数
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkWindowDemo2 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("kafkaSource")
val streamingContext = new StreamingContext(conf,Seconds(2))
streamingContext.checkpoint("checkpoint")
val kafkaParams: Map[String, String] = Map(
(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "192.168.233.133:9092"),
(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.GROUP_ID_CONFIG, "kafkaGroup2")
)
val kafkaStream: InputDStream[ConsumerRecord[String,String]] = KafkaUtils.createDirectStream(
streamingContext,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe(Set("sparkKafkaDemo"), kafkaParams)
)
// 求出单词数量
val numStream: DStream[Long] = kafkaStream.flatMap(line => line.value().toString.split("\\s+"))
.map((_, 1))
.countByWindow(Seconds(8),Seconds(4)) // 指定窗口大小为8秒,滑动时间为4秒
numStream.print()
streamingContext.start()
streamingContext.awaitTermination()
}
}
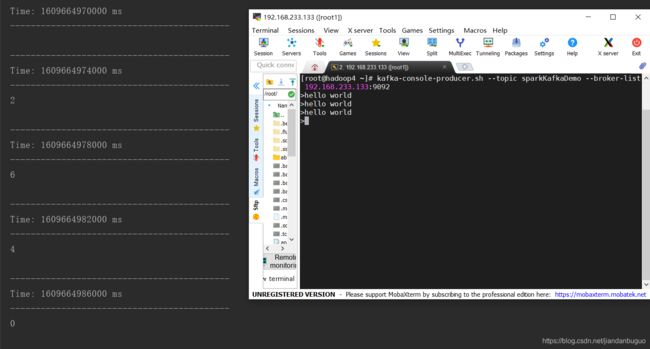
3. countByValueAndWindow(windowLength,slideInterval, [numTasks])
统计当前时间窗口中元素值相同的元素的个数
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/*
* countByValueAndWindow
* 功能类似wordCount
* */
object SparkWindowDemo3 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("kafkaSource")
val streamingContext = new StreamingContext(conf,Seconds(2))
streamingContext.checkpoint("checkpoint")
val kafkaParams: Map[String, String] = Map(
(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "192.168.233.133:9092"),
(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.GROUP_ID_CONFIG, "kafkaGroup2")
)
val kafkaStream: InputDStream[ConsumerRecord[String,String]] = KafkaUtils.createDirectStream(
streamingContext,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe(Set("sparkKafkaDemo"), kafkaParams)
)
val numStream: DStream[((String), Long)] = kafkaStream.flatMap(
line => line.value().toString.split("\\s+"))
.countByValueAndWindow(Seconds(8), Seconds(4))
numStream.print()
streamingContext.start()
streamingContext.awaitTermination()
}
}
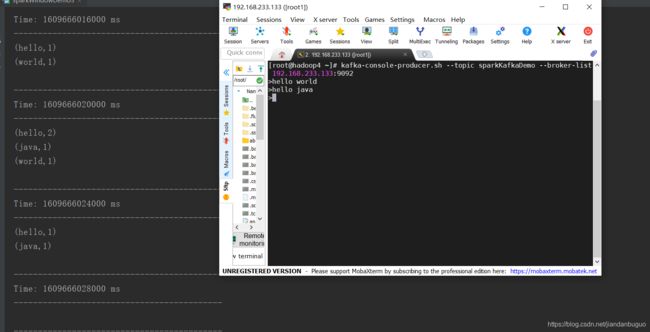
4、reduceByWindow(func, windowLength,slideInterval)
在调用DStream上首先取窗口函数的元素形成新的DStream,然后在窗口元素形成的DStream上进行reduce
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkWindowDemo4 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("kafkaSource")
val streamingContext = new StreamingContext(conf,Seconds(2))
streamingContext.checkpoint("checkpoint")
val kafkaParams: Map[String, String] = Map(
(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "192.168.233.133:9092"),
(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.GROUP_ID_CONFIG, "kafkaGroup2")
)
val kafkaStream: InputDStream[ConsumerRecord[String,String]] = KafkaUtils.createDirectStream(
streamingContext,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe(Set("sparkKafkaDemo"), kafkaParams)
)
// 将输入的字符用:连接
val numStream: DStream[String] = kafkaStream.flatMap(
line => line.value().toString.split("\\s+"))
.reduceByWindow(_ +":"+ _, Seconds(8), Seconds(6))
numStream.print()
streamingContext.start()
streamingContext.awaitTermination()
}
}
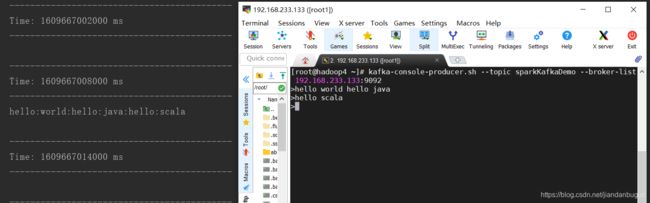
5、reduceByKeyAndWindow
- reduceByKeyAndWindow(func,windowLength, slideInterval, [numTasks])
reduceByKeyAndWindow的数据源是基于该DStream的窗口长度中的所有数据进行计算。该操作有一个可选的并发数参数
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkWindowDemo5 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("kafkaSource")
val streamingContext = new StreamingContext(conf,Seconds(2))
streamingContext.checkpoint("checkpoint")
val kafkaParams: Map[String, String] = Map(
(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "192.168.233.133:9092"),
(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.GROUP_ID_CONFIG, "kafkaGroup2")
)
val kafkaStream: InputDStream[ConsumerRecord[String,String]] = KafkaUtils.createDirectStream(
streamingContext,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe(Set("sparkKafkaDemo"), kafkaParams)
)
val numStream: DStream[(String, Int)] = kafkaStream.flatMap(line => line.value().toString.split("\\s+"))
.map((_, 1))
.reduceByKeyAndWindow((x: Int, y: Int) => {
x + y
}, Seconds(8), Seconds(4))
numStream.print()
streamingContext.start()
streamingContext.awaitTermination()
}
}
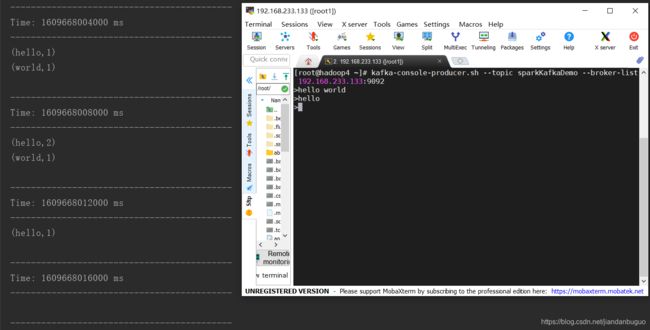
- reduceByKeyAndWindow(func, invFunc,windowLength, slideInterval, [numTasks])
这个窗口操作比上一个多传入一个函数invFunc。前面的func作用和上一个reduceByKeyAndWindow相同,后面的invFunc是用于处理流出rdd的
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkWindowDemo5 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("kafkaSource")
val streamingContext = new StreamingContext(conf,Seconds(2))
streamingContext.checkpoint("checkpoint")
val kafkaParams: Map[String, String] = Map(
(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "192.168.233.133:9092"),
(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"),
(ConsumerConfig.GROUP_ID_CONFIG, "kafkaGroup2")
)
val kafkaStream: InputDStream[ConsumerRecord[String,String]] = KafkaUtils.createDirectStream(
streamingContext,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe(Set("sparkKafkaDemo"), kafkaParams)
)
val numStream: DStream[(String, Int)] = kafkaStream.flatMap(line => line.value().toString.split("\\s+"))
.map((_, 1))
.reduceByKeyAndWindow((x: Int, y: Int) => {
x + y
},(x: Int, y: Int) => {
x - y
}, Seconds(8), Seconds(4))
numStream.print()
streamingContext.start()
streamingContext.awaitTermination()
}
}