在本教程中,我们将Vue.js,Three.js和LUIS(认知服务)配对以创建语音控制的Web可视化。
但首先,有一点背景
为什么我们需要使用语音识别? 这样的问题可能会解决什么问题?
前一阵子我在芝加哥上车。 公交车司机没看见我,关上了我手腕的门。 当他开始走动时,我听到手腕上传来阵阵刺耳的声音,当其他乘客开始大喊大叫时,他的确停了下来,但直到他撕开我的手臂上的几条肌腱之前,他才停下来。
我原本应该休假,但对于当时的博物馆员工来说,我通常是签合同的,没有真正的健康保险。 我一开始的工作并不多,所以请假对我来说不是一个选择。 我经历了痛苦。 最终,我的手腕的健康开始恶化。 刷牙真的很痛苦。 语音到文本并不是当今的无处不在的技术,当时可用的最佳工具是Dragon。 它可以正常工作,但是学习起来却很沮丧,而且我仍然不得不经常动动双手,因为它经常会出错。 那是十年前的事,所以我敢肯定,自那时以来,特定技术已经有了显着改善。 那时我的手腕也得到了明显改善。
整个经历使我对语音控制技术产生了浓厚的兴趣。 如果仅通过讲话就可以控制有利于我们的网络行为,我们该怎么办? 为了进行实验,我决定使用LUIS ,这是一项基于机器学习的服务,它通过使用可以不断改进的自定义模型来构建自然语言。 我们可以将其用于应用程序,机器人和物联网设备。 这样,我们可以创建可视化效果以响应任何声音-并且可以通过学习来改善自身。
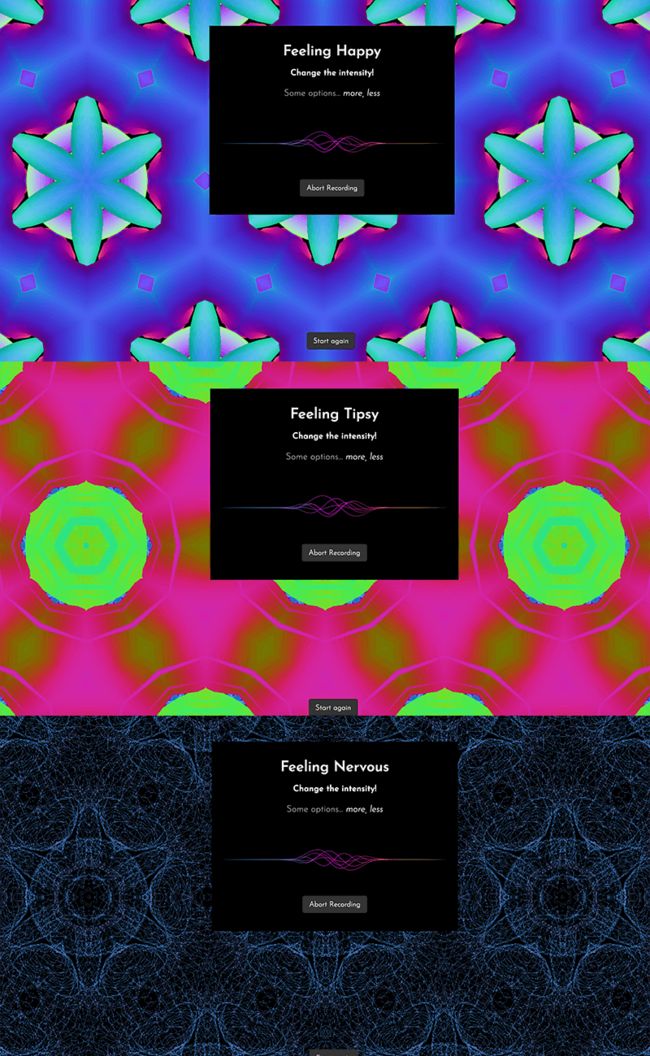
这是我们正在构建的鸟瞰图:

设置LUIS
我们将获得Azure的免费试用帐户 ,然后转到门户 。 我们将选择认知服务。
选择“ 新建→AI /机器学习”后 ,我们将选择“语言理解”(或LUIS)。

然后,我们将选择我们的名称和资源组。

我们将从下一个屏幕上收集密钥,然后转到LUIS仪表板
训练这些机器真的很有趣! 我们将建立一个新的应用程序并创建一些意图,这些意图是我们要根据给定条件触发的结果。 这是此演示的示例:
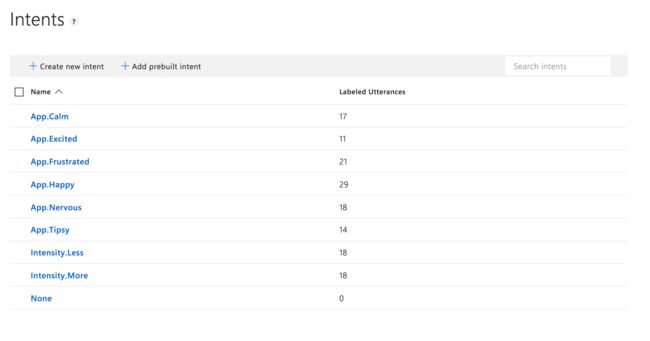
您可能会注意到我们这里有一个命名架构。 我们这样做是为了更容易对意图进行分类。 我们将首先弄清楚情绪,然后听强度,因此初始意图会以App (主要用于App.vue组件)或Intensity App.vue 。
如果我们深入研究每个特定的意图,我们就会看到如何训练模型。 我们有一些相似的短语表示大致相同的内容:
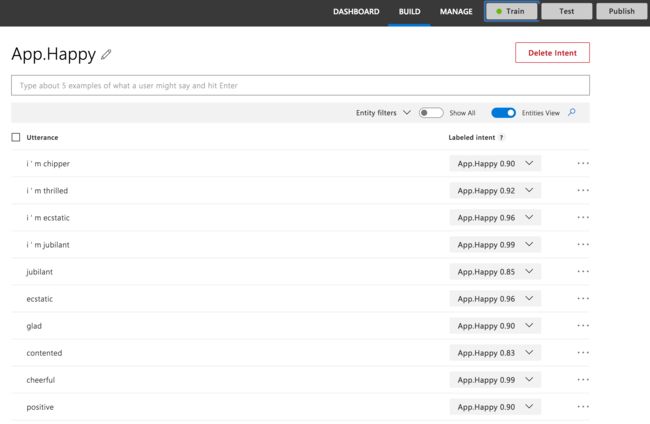
您可以看到我们有很多用于训练的同义词,但是当我们准备开始训练模型时,在上方也有“ Train”按钮。 我们单击该按钮,获得成功通知,然后就可以发布了。
设置Vue
我们将通过Vue CLI创建一个非常标准的Vue.js应用程序。 首先,我们运行:
vue create three-vue-pattern
# then select Manually...
Vue CLI v3.0.0
? Please pick a preset:
default (babel, eslint)
❯ Manually select features
# Then select the PWA feature and the other ones with the spacebar
? Please pick a preset: Manually select features
? Check the features needed for your project:
◉ Babel
◯ TypeScript
◯ Progressive Web App (PWA) Support
◯ Router
◉ Vuex
◉ CSS Pre-processors
◉ Linter / Formatter
◯ Unit Testing
◯ E2E Testing
? Pick a linter / formatter config:
ESLint with error prevention only
ESLint + Airbnb config
❯ ESLint + Standard config
ESLint + Prettier
? Pick additional lint features: (Press to select, a to toggle all, i to invert selection)
❯ ◉ Lint on save
◯ Lint and fix on commit
Successfully created project three-vue-pattern.
Get started with the following commands:
$ cd three-vue-pattern
$ yarn serve 这将为我们启动服务器,并提供典型的Vue欢迎屏幕。 我们还将向我们的应用程序添加一些依赖项: three.js , 正弦波和axios 。 three.js将帮助我们创建WebGL可视化。 正弦波为装载机提供了很好的画布抽象。 axios将为我们提供一个非常好的HTTP客户端,以便我们可以调用LUIS进行分析。
yarn add three sine-waves axios设置我们的Vuex商店
现在我们有了一个可行的模型,让我们通过axios来获取它,并将其带入我们的Vuex商店。 然后,我们可以将信息传播到所有不同的组件。
在state ,我们将存储需要的内容:
state: {
intent: 'None',
intensity: 'None',
score: 0,
uiState: 'idle',
zoom: 3,
counter: 0,
}, intent和intensity将分别存储应用程序,强度和意图。 score将存储我们的置信度(这是从0到100的分数,用于衡量模型认为其可以对输入进行排名的程度)。
对于uiState ,我们有三种不同的状态:
-
idle–等待用户输入 -
listening–听用户输入 -
fetching–从API获取用户数据
zoom和counter都是我们用来更新数据可视化的东西。
现在,在actions中 ,我们将uiState (在一个突变中)设置为fetching ,并使用在设置LUIS时收到的生成的密钥,使用axios调用API。
getUnderstanding({ commit }, utterance) {
commit('setUiState', 'fetching')
const url = `https://westus.api.cognitive.microsoft.com/luis/v2.0/apps/4aba2274-c5df-4b0d-8ff7-57658254d042`
https: axios({
method: 'get',
url,
params: {
verbose: true,
timezoneOffset: 0,
q: utterance
},
headers: {
'Content-Type': 'application/json',
'Ocp-Apim-Subscription-Key': ‘XXXXXXXXXXXXXXXXXXX'
}
}) 然后,一旦完成此操作,就可以得到评分最高的意图并将其存储在我们的state 。
我们还需要创建一些可用于更改状态的突变。 我们将在行动中使用它们。 在即将发布的Vue 3.0中,由于将删除突变,因此将简化此流程。
newIntent: (state, { intent, score }) => {
if (intent.includes('Intensity')) {
state.intensity = intent
if (intent.includes('More')) {
state.counter++
} else if (intent.includes('Less')) {
state.counter--
}
} else {
state.intent = intent
}
state.score = score
},
setUiState: (state, status) => {
state.uiState = status
},
setIntent: (state, status) => {
state.intent = status
},这一切都非常简单。 我们正在传递状态,以便我们可以为每次出现更新状态-强度除外,强度会相应地使计数器递增和递减。 我们将在下一部分中使用该计数器来更新可视化。
.then(({ data }) => {
console.log('axios result', data)
if (altMaps.hasOwnProperty(data.query)) {
commit('newIntent', {
intent: altMaps[data.query],
score: 1
})
} else {
commit('newIntent', data.topScoringIntent)
}
commit('setUiState', 'idle')
commit('setZoom')
})
.catch(err => {
console.error('axios error', err)
})在此操作中,我们将提交刚刚检查过的突变,或者在出现问题时记录错误。
逻辑的工作方式,用户将进行初始记录以说出他们的感受。 他们将按下一个按钮将其全部踢开。 可视化将出现,到那时,应用程序将不断听用户说或多或少地控制返回的可视化。 让我们设置其余的应用程序。
设置应用
在App.vue ,我们将在页面中间显示两个不同的组件,具体取决于我们是否已经指定了心情。
当UI处于侦听状态时,这两个都将为查看者以及SineWaves组件显示信息。
应用程序的基础是显示可视化内容的位置。 它将根据心情显示不同的道具。 这是两个示例:
设置数据可视化
我想使用类似于万花筒的图像进行可视化,并经过一番搜索后找到了这个仓库 。 它的工作方式是形状在空间中旋转,这将使图像分解并像万花筒一样显示出碎片。 现在,这听起来很棒,因为(是!)工作已经完成了,对吧?
不幸的是没有。
为了完成这项工作,需要进行许多重大更改,并且即使最终的视觉表达看起来与原始视觉表达相似,它实际上也是一项艰巨的任务。
- 由于事实上,如果我们决定更改可视化效果,则必须拆除可视化效果,因此我不得不将现有代码转换为使用
bufferArrays,对于这一目的,该性能更高。 - 原始代码是一个很大的块,因此我将一些功能分解为组件上的较小方法,以使其更易于阅读和维护。
- 因为我们想即时更新事物,所以我不得不将某些项目存储为组件中的数据,并最终存储为将从父级接收的道具。 我还提供了一些不错的默认值(所有默认值看起来
excited)。 - 我们使用来自Vuex状态的计数器来更新摄影机相对于物体的放置距离,以便我们可以看到更少或更多的物体,因此它变得越来越不复杂。
为了更改根据配置的外观,我们将创建一些道具:
props: {
numAxes: {
type: Number,
default: 12,
required: false
},
...
tConfig: {
default() {
return {
a: 2,
b: 3,
c: 100,
d: 3
}
},
required: false
}
},在创建形状时,我们将使用它们:
createShapes() {
this.bufferCamera.position.z = this.shapeZoom
if (this.torusKnot !== null) {
this.torusKnot.material.dispose()
this.torusKnot.geometry.dispose()
this.bufferScene.remove(this.torusKnot)
}
var shape = new THREE.TorusKnotGeometry(
this.tConfig.a,
this.tConfig.b,
this.tConfig.c,
this.tConfig.d
),
material
...
this.torusKnot = new THREE.Mesh(shape, material)
this.torusKnot.material.needsUpdate = true
this.bufferScene.add(this.torusKnot)
}, 如前所述,现在将其拆分为自己的方法。 我们还将创建另一个启动动画的方法,该方法在更新时也将重新启动。 动画利用了requestAnimationFrame :
animate() {
this.storeRAF = requestAnimationFrame(this.animate)
this.bufferScene.rotation.x += 0.01
this.bufferScene.rotation.y += 0.02
this.renderer.render(
this.bufferScene,
this.bufferCamera,
this.bufferTexture
)
this.renderer.render(this.scene, this.camera)
}, 我们将创建一个称为shapeZoom的计算属性,该属性将返回商店的缩放shapeZoom 。 如果您还记得的话,它将随着用户声音改变强度而更新。
computed: {
shapeZoom() {
return this.$store.state.zoom
}
},然后,我们可以使用观察器来查看缩放级别是否更改,并取消动画,重新创建形状并重新启动动画。
watch: {
shapeZoom() {
this.createShapes()
cancelAnimationFrame(this.storeRAF)
this.animate()
}
},在数据中,我们还存储了实例化three.js场景所需的一些东西-最值得注意的是确保相机精确居中。
data() {
return {
bufferScene: new THREE.Scene(),
bufferCamera: new THREE.PerspectiveCamera(75, 800 / 800, 0.1, 1000),
bufferTexture: new THREE.WebGLRenderTarget(800, 800, {
minFilter: THREE.LinearMipMapLinearFilter,
magFilter: THREE.LinearFilter,
antialias: true
}),
camera: new THREE.OrthographicCamera(
window.innerWidth / -2,
window.innerWidth / 2,
window.innerHeight / 2,
window.innerHeight / -2,
0.1,
1000
), 如果您想浏览存储库或使用自己的参数自行设置,此演示还有更多内容。 init方法会执行您认为可能的事:初始化整个可视化效果。 如果您正在查看源代码,我已经评论了许多关键部分。 还有另一种更新几何的方法,即您所使用的updateGeometry 。 您可能还会注意到那里有很多var。 这是因为在这种可视化中重用变量是很常见的。 我们通过在mounted()生命周期挂钩中调用this.init()来启动一切。
- 同样,如果您想使用代码, 这里是仓库
- 您可以通过获取免费的Azure帐户来建立自己的模型
- 您还需要查看LUIS(认知服务)
看到您可以为网络创建的东西很有趣,这些东西不一定需要任何手动操作即可控制。 它带来了很多机会!
翻译自: https://css-tricks.com/voice-controlled-web-visualizations-with-vue-js-and-machine-learning/