论文阅读三——端到端的帧到凝视估计
论文阅读三——端到端的帧到凝视估计
-
- 主要内容
-
- 研究问题
- 文章的解题思路
- 文章的主要结构
- 论文实验
-
- 关于端到端凝视估计的数据集
- 3种基线模型与EFE模型的对比
- 在三个数据集中与SOTA进行比较
- 问题分析
- 重要架构
-
- U-Net
- 基础知识
主要内容
文章从端到端的方法出发,提出了根据heatmap和sprase depth map生成凝视原点和通过图像帧获得凝视方向,将两者结合获得注视点(PoG),和先前传统的通过裁剪人脸眼睛和脸部特征有所区别,并且PoG误差较之前的小。
研究问题
文章所需要解决的问题是远程基于网络摄像头的凝视估计,即如何通过通过单个用户面向的、远程放置的摄像头捕捉用户的图像,然后利用这些图像来估计用户的凝视方向的问题。譬如远程RGB图像凝视估计(使用面向用户的单个RGB摄像头,而无需额外工具(如红外光源)来更容易地解决凝视估计问题)
在传统的解决方法中,有着以下两点难题:
- 传统的学习型远程凝视估计方法通常需要将小的裁剪图像(眼睛或者面部图像)作为输入,以预测凝视方向。
- 这些输入以及凝视起源必须根据面部特征的预定义过程生成,通常通过数据规范化等方式。
使用基于卷积神经网络(CNN)的学习型方法(输入是简单的裁剪图像 / 通过“数据归一化”过程产生的图像块)不会考虑到3D头部姿势,而大幅度头部旋转的情况下会导致不同的尺寸和图像比例。为了解决这个问题,论文提出了**"End-to-end Frame-to-Gaze Estimation(EFE)"方法,直接从相机帧**中回归3D凝视起源和3D凝视方向,允许模型适应新的相机-屏幕几何结构,方法避免了昂贵的数据规范化步骤。但是,不可忽视的是原始帧中眼部区域较小,且需要对凝视起源进行准确估计。
因此,文章作者作出了这样的模型设计:
- 使用全卷积U-Net架构预测凝视起源的2D热图和深度图。
- 利用多层感知机(MLP)从U-Net架构的瓶颈特征中预测3D凝视方向。
- 使用相机内参和外参参数,通过可微分方式将凝视射线与已知屏幕平面相交,以得到Point-of-Gaze(PoG)。
文章的解题思路
文章在摘要前便直接展示了一张图,体现了自身模型与传统的凝视估计不同,图像如下:

端到端帧到视线估计方法**(EFE)被训练成直接从输入的摄像机帧预测眼睛的凝视**,而传统方法有许多的预处理模块(人脸检测模块、地标检测模块、数据归一化模块,然后进行凝视估计(视差估计)),而文章表示他们在跳过这些过程的情况下,还可以提升性能!
从论文的第一张图片以及摘要我们可以得到作者提出的EFE模型和过去大部分传统模型的差别:
传统的凝视方法:需要一个或多个眼部或面部区域的裁剪作为输入,并产生一个凝视方向向量作为输出。
- 根据面部标志从输入摄像头帧中裁剪眼部/面部补丁,通过拟合通用的3D面部模型估计3D头部姿势,进而生成3D凝视起源(上图没体现)。
- 在摄像机坐标系中输出凝视方向(是通过眼睛的凝视行为进行估计的,而不仅仅是头部姿势的估计),通过将预测的凝视方向与在数据归一化步骤中获得的凝视原点合成,可以构建凝视射线。
但是传统凝视方法中的裁剪有好处也有坏处,如下:
- 好处:在眼部区域获得更高的分辨率,并且减少混淆因素(衣服、头发)。
- 坏处:眼部/面部裁剪过程昂贵、容易出错,并且对于不同的方法具有特定的实现。
- EFE方法:构建一个模型,实现以端到端的方式直接从相机帧中估计一个包括凝视起源和凝视方向的6D凝视射线(3D凝视原点+3D凝视方向),而无需对面部或眼睛进行任何裁剪。
总之,文章提出了一种无需进行面部或眼睛裁剪即可直接从原始帧进行凝视估计的方法,在实现简化流程、降低成本的同时,实现效果可以与当今最先进的模型进行媲美。
文章的主要结构
为了通过相机帧来确定人眼的注视点(PoG),文章使用了以下结构:
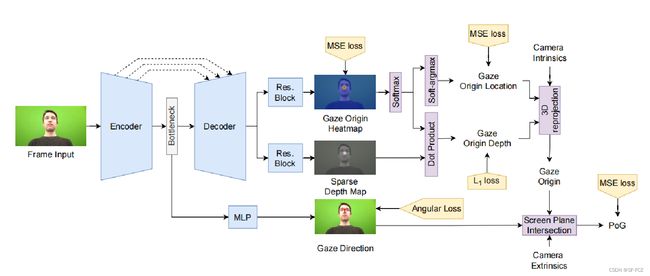
如上图,作者提出了一种类似U-Net的体系结构,其中输出特征被映射到图像上的2D凝视原点位置和稀疏深度图中,它们结合在一起来产生3D凝视原点;使用瓶颈特征作为输入,利用MLP预测三维视线方向(POG是使用预测的凝视原点和凝视方向以及相机转换矩阵来计算的)。
(注:感觉这里的系数深度图的图像是有问题的,可能是作者为了美观而将后面的Gaze Origin Depth的图像前移了,否则不会出现范围性的深度结果。)
-
预测凝视原点
-
预测2D凝视起源热图和稀疏深度图:使用 U-Net-like 结构,模型预测一个 2D 凝视起源热图和一个稀疏深度图。
-
热图和深度图的训练损失:
- 热图的预测,使用均方误差损失(MSE)用于预测热图,获得热图后通过softargmax获得。
L h e a t m a p = 1 n ∑ i = 1 n ∣ ∣ h − h ^ ∣ ∣ 2 2 n = W × H h : 预测的凝视原点在相机帧上的 2 D 位置 h ^ 是通过以凝视原点为中心绘制二维高斯而生成的地面真实热图 通过损失函数获得最终的热图后,使用 s o f t − a r g m a x 来确定最终的凝视点坐标 L_{heatmap}=\frac{1}{n}\sum_{i=1}^{n}||h-\hat{h}||_2^2\\ n=W×H\\ h:预测的凝视原点在相机帧上的2D位置 \\ \hat{h}是通过以凝视原点为中心绘制二维高斯而生成的地面真实热图\\ 通过损失函数获得最终的热图后,使用soft-argmax来确定最终的凝视点坐标 Lheatmap=n1i=1∑n∣∣h−h^∣∣22n=W×Hh:预测的凝视原点在相机帧上的2D位置h^是通过以凝视原点为中心绘制二维高斯而生成的地面真实热图通过损失函数获得最终的热图后,使用soft−argmax来确定最终的凝视点坐标
之所以预测凝视原点为热图的概率分布而不是固定的某个点,是因为数据集的ground truth本身存在一定的误差,可以更好地应对凝视原点位置定义的模糊性和地面实况标签的误差。
- 对于 2D 凝视起源位置的预测,同样使用均方误差损失。深度图的预测则使用 L1 范式损失,该损失函数仅考虑到对于可见的用户面部区域的点。-
2D凝视位置损失:
L g = ∣ ∣ g − g ^ ∣ ∣ 2 2 g ^ 是在摄像头帧上的真实 2 D 凝视位置。 L_g=||g-\hat{g}||_2^2\\ \hat{g}是在摄像头帧上的真实 2D 凝视位置。 Lg=∣∣g−g^∣∣22g^是在摄像头帧上的真实2D凝视位置。
-
z = h ⋅ d L d = ∣ ∣ z − z ^ ∣ ∣ 1 z ^ 是真实的深度值(距离) , d : 预测稀疏深度图 z=h·d\\ L_d=||z-\hat{z}||_1\\ \hat{z}是真实的深度值(距离),d:预测稀疏深度图 z=h⋅dLd=∣∣z−z^∣∣1z^是真实的深度值(距离),d:预测稀疏深度图
-
计算 3D 凝视起源:通过将2D图像坐标转换为世界坐标,利用相机内参矩阵 K,计算 3D 凝视起源 。
# 相机参数矩阵K K = np.array([ [fx, 0, cx], [0, fy, cy], [0, 0, 1]]) # fx,fy是相机的焦距 # cx,cy是相机的中心点 ```
热图通过soft-argmax获得一个2D凝视点坐标g=(x,y),设该点深度为d。通过相机内参矩阵可以将2D凝视点坐标进行归一化,如下操作:
u = x − c x f x v = y − c y f y u=\frac{x-c_x}{f_x}\\ v=\frac{y-c_y}{f_y} u=fxx−cxv=fyy−cy
所以得到归一化后的点g1=(u,v,1),其中数字1是为了让坐标可以进行齐次坐标转换。
[ x y z 1 ] = K − 1 [ u v 1 ] ⋅ d \begin{bmatrix} x \\ y\\ z\\ 1 \end{bmatrix}=K^{-1}\begin{bmatrix} u\\ v\\ 1 \end{bmatrix}·d xyz1 =K−1 uv1 ⋅d
则o=(x,y,z)就是3D的凝视起源坐标。
-
预测凝视方向: 通过映射从图像空间到3D方向的方式进行凝视方向的预测。
- 使用了类似U-Net的中间瓶颈特征进行凝视方向的预测,共享特征提取器的信息。
- 针对凝视方向的预测,使用了角度损失 Lr 进行监督。使用角度余弦进行计算损失Lr:
L r = a r c c o s ( r ^ ⋅ r ∣ ∣ r ^ ∣ ∣ ⋅ ∣ ∣ r ∣ ∣ ) L_r=arccos(\frac{\hat{r}·r}{||\hat{r}||·||r||}) Lr=arccos(∣∣r^∣∣⋅∣∣r∣∣r^⋅r)
-
如何计算注视点(PoG)
-
PoG:与屏幕平面相交的6D凝视光线(由凝视起源和方向组成)的交点。
-
利用凝视起源 o 和凝视方向 r,可以获取到屏幕框架的距离 λ*。*
λ = r ⋅ n s ( a s − o ) ⋅ n s 凝视起点: o , 凝视方向: r 屏幕框架法线: n s 屏幕平面上的样本点: a s ( 用于计算凝视距离 λ 的屏幕平面上的一个随机点 ) \lambda=\frac{r·n_s}{(a_s-o)·n_s}\\ 凝视起点:o,凝视方向:r\\ 屏幕框架法线:n_s\\ 屏幕平面上的样本点:a_s(用于计算凝视距离 λ 的屏幕平面上的一个随机点) λ=(as−o)⋅nsr⋅ns凝视起点:o,凝视方向:r屏幕框架法线:ns屏幕平面上的样本点:as(用于计算凝视距离λ的屏幕平面上的一个随机点) -
PoG的计算:
P o G = o + λ r PoG=o+\lambda r PoG=o+λr
- PoG计算的损失函数
L P o G = ∣ ∣ p − p ^ ∣ ∣ —— 2 2 L_{PoG}=||p-\hat{p}||——2^2 LPoG=∣∣p−p^∣∣——22
综上可以得到凝视估计点,而纵观全过程,EFE的总体损失函数为:
L t o t a l = λ g L g + λ h L h e a t m a p + λ d L d + λ P o g L P o G L_{total}=\lambda_gL_g+\lambda_hL_{heatmap}+\lambda_dL_d+\lambda_{Pog}L_{PoG} Ltotal=λgLg+λhLheatmap+λdLd+λPogLPoG -
与之前的论文阅读相比,作者认为其实现了真正的端到端(从原始输入到最终输出的完整流程,而不需要手动处理中间步骤或阶段):
- 输入与输出直接相关: EFE 模型从摄像机帧直接预测凝视方向,而不需要在中间阶段进行额外的预处理或特征提取。
- EFE 避免了预处理步骤,直接使用原始帧进行训练和推理。这使得模型训练和使用更加直接和全面。
- EFE 使用整个相机帧作为输入,因此可以被视为全图输入模型。
论文实验
关于端到端凝视估计的数据集
| 数据集 | 任务 | 内容 | 数据处理 |
|---|---|---|---|
| EVE | 端到端凝视估计 | 连续视频,Tobii Pro Spectrum眼动仪提供地面实况凝视标签 | 创建图像数据集,训练集进行0.6的子采样率,将帧的大小调整为480 × 270像素 |
| GazeCapture | 端到端凝视估计 | 通过众包方式使用手机和平板电脑进行采集,1450多人,近250万帧 | 提供原始帧输入和相对于摄像机的PoG,假设摄像机和屏幕共面 |
| MPIIFaceGaze | 端到端凝视估计 | 15名受试者的笔记本电脑下的3000张面部图像,自然头部运动和各种光照条件 | 提供原始摄像机帧、通过数据归一化估计的3D凝视起源、3D凝视方向以及屏幕上的2D PoG |
3种基线模型与EFE模型的对比
文中考虑了3中基线模型,分别是:方向回归、单独模型和联合预测,其对比表格如下:
| 模型/方法 | 特点 | 性能 |
|---|---|---|
| 方向回归方法 | 直接估计 PoG,不预测凝视起源或凝视方向 | 性能较差 |
| 独立模型方法 | 通过两个独立的模型估计凝视起源和凝视方向 | 较好的性能,因为有更大的模型容量 |
| 联合预测方法 | 通过共享网络和独立 MLP 联合估计凝视起源和凝视方向,使用 PoG 损失进行优化 | 性能较差,不能有效地共同学习凝视起源和凝视方向 |
| EFE(提出的方法) | 通过 U-Net-like 架构,使用热图回归凝视起源,同时学习稀疏深度图进行凝视方向估计,最终通过屏幕平面计算 PoG | 最佳性能,相对于其他方法表现更好,尤其在复杂的 EVE 数据集上 |
其结构图如下:

其中联合预测方法,作者使用了共享卷积神经网络来提取图像特征,然后使用两个独立的多层感知机来分别预测凝视的起源和凝视的方向。这方法与EFE模型是不一样的。
对比结果:

在三个数据集中与SOTA进行比较
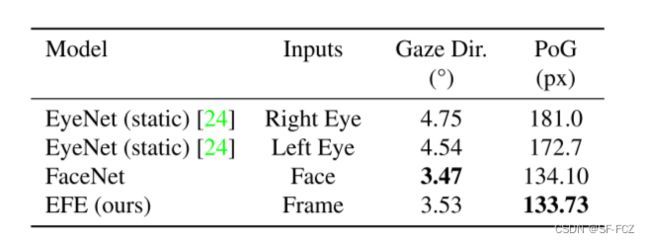
- 在EVE数据集中,比较效果如下:
- 在GazeCpture数据集中,比较效果如下:
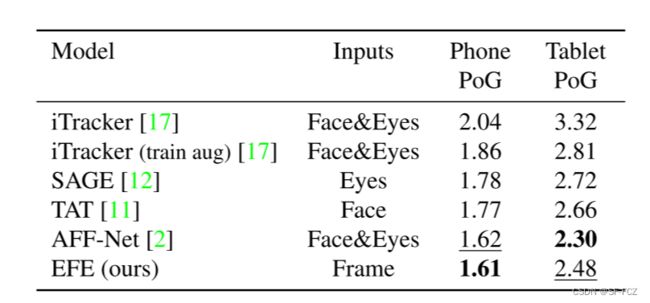
ITracker方法接受多个输入:裁剪的面、左眼、右眼和面占用栅格。
EFE只接受调整大小的原始帧作为输入。
- 在MPIIGaze数据集中

在15倍交叉验证评估方案下,将EFE与最先进的POG估计方法Full-Face、Far-Net和AFF-Net进行了比较,从数据上看,性能sota模型持平,部分领先。
与EFE模型不同,其他三个模型都是使用数据归一化后的人脸图像以及通过数据归一化计算的地面真实凝视原点作为输入,模型只输出凝视方向,而没有生成凝视原点。
问题分析
EVE上PoG残差的直方图,通过比较数据归一化计算凝视原点和EFE预测了凝视的来源,结果表明,我们的端到端学习方法在POG误差方面表现出较小的偏差。图像如下:

文章最后还提到了一个效果极好的深度图可视化:

文章提到:用户的脸是离相机更远还是更靠近相机的粗略概念被捕捉到了。
文章还进行了跨相机评估,,将EFE模型与FaceNet模型(要数据归一化)进行了比较。文章指出,对数据进行归一化是为了让生成的归一化数据在更多的相机中可以进行使用(适配)。最后,将两个模型在EVE数据集中进行对比,其结果如下:
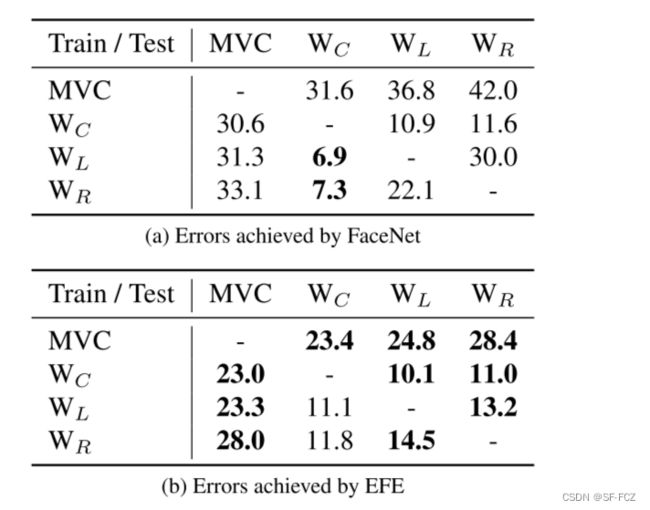
说明:机器视觉摄像头(MVC),显示器顶部(WC)、左上角(WL)和右上角(WR)上的网络摄像头,通过结果图来看,在大多数跨摄像头配置中,EFE的表现都超过了基于数据归一化的FaceNet,在许多情况下,EFE的表现要比基于数据标准化的FaceNet高出很多。文章中说,在WL摄像头进行训练,在WR中进行测试,得到的精度,EFE模型会明显优于FaceNet(提高了16.8).
重要架构
U-Net
可以进行图像分割
组成:从图像中提取相关特征的编码器,以及获取提取的特征并重建分割掩模的解码器部分。
- 编码器部分,使用了卷积层,然后使用
ReLU和MaxPool作为特征提取器。 - 解码器部分,转置卷积以增加特征图的大小并减少通道数。使用填充来保持卷积运算后特征图的大小相同。

从上图中我们可以发现,其没有全连接层!随着我们扩展编码器和解码器层中的层数,可以有效地越来越“缩小”特征图,这样会导致编码器可能会丢弃更详细的特征,而选择更一般的特征。
由于深度神经网络在通过连续层传递信息时可能会“忘记”某些特征,因此跳过连接可以重新引入它们以使学习变得更强。因此,U-Net引入了残差网络 (ResNet) 进行改进,从而引入了跳跃连接(通过将编码器的某一层的特征图与解码器的对应层的特征图进行拼接而实现的),并显示出分类改进以及更平滑的学习梯度,使得其具有跳跃连接以确保精细细节不会丢失。

这样的话,U-Net有了以下特性:
- 没有全连接层
- 随着编码器和解码器层数的加深,提取越通用的特征。
- 将详细功能重新引入解码器的跳过连接。
文章中,U-Net-like结构主要是以U-Net为主体,U-Net以Efficient V2为主干网络,为了更好的训练参数以及加快训练速度。而EfficientV2较Efficient V1进行了改进,以fused MBConv模块替换了MBConv模块,达到了加快速度的方法,如下图:

基础知识
face Landmark Detector:检测图像或视频中物体的关键点或地标,通常指的是人脸的关键点,如眼睛的位置、鼻子的位置、嘴巴的位置等。
多层感知机MLP:一种人工神经网络结构,由多个神经元层组成,通常包括输入层、隐藏层和输出层。
原始帧:拍摄场景的视觉信息(头部姿势、面部表情、眼部状态等等),但是会有很多无用的信息,譬如背景、头法,衣服等等。
跨人凝视估计:在凝视估计任务中,模型能够处理和泛化到不同个体的情况,使模型具有足够的泛化能力,以便在面对新的、不同于训练集的个体时,依然能够准确地估计其凝视方向。
凝视起源/原点:用户凝视的起始点或者视线的源头,即在眼睛的视觉轴上的起始位置。
凝视射线:指从眼睛到凝视目标的一条直线。它连接了观察者(用户)的眼睛位置(凝视起源)和他们正在凝视的目标的位置,形成一个向目标指示的直线。
凝视方向:人的眼睛所注视的方向,通常以某种坐标系表示,凝视方向可以用来描述眼睛的注视点,即眼球看向的具体位置或方向,通常以空间坐标或相对于某个参考点或平面的角度来表示。
3D原点(3D origin): 指凝视光线的起点在三维空间中的位置,即光线从眼睛的位置发出的点。
3D方向(3D direction): 指凝视光线的方向,即光线的路径或轨迹,表示为视线的方向,从眼睛指向观察场景的某个点。
注视点(Point-of-Gaze):观察者注视的具体位置或方向,通常以屏幕上的像素坐标表示,在凝视估计领域中,通常表示用户当前正在屏幕上注视的位置。
Heatmap: 二维图像,其中的像素值表示了凝视原点(gaze origin)在输入图像中的可能位置。 训练得到的热图可以被视为对凝视原点位置的概率分布,热图用于表示模型对凝视起源位置的预测信心程度。
Depth Map: 二维图像,其中的像素值表示了凝视原点的深度或距离。深度图提供了凝视原点相对于摄像头的距离信息。通过深度图,可以了解观察者注视目标的距离。