论文阅读—— Multimodal Foundation Models:From Specialists to General-Purpose Assistants(Chapter 3)
Multimodal Foundation Models:From Specialists to General-Purpose Assistants
Chapter 3 Visual Generation
Visual generation 是AIGC的核心。
人类将自己的意图作为输入条件输入到生成模型中,例如类标签、文本、边界框、布局掩码等。鉴于开放式文本描述提供的灵活性,文本条件(包括文本到图像/视频/3D)已成为条件视觉生成的关键主题。本章描述如何在视觉生成中与人类意图保持一致,重点是图像生成。
3.1 Overview
3.1.1 Human Alignments in Visual Generation
本章深入研究了四个常见的研究问题:
Spatial controllable T2I generation:文本是人机交互的强大媒介,使其成为条件视觉生成的焦点。然而,文本本身无法提供精确的空间参考。空间可控T2I生成旨在将文本输入与其他条件相结合,以获得更好的可控性,从而便于用户生成所需图像。
Text-based image editing:局部改变一个物体或者调整整张图片。
Better following text prompts:尽管T2I模型被训练来重建以配对文本输入为条件的图像,但训练目标并不一定确保或直接优化在图像生成过程中严格遵守文本提示。
Visual concept customization:将视觉概念融入文本输入对于各种应用程序至关重要,例如在不同的环境中生成宠物狗或家庭成员的图像,或制作以特定角色为特征的视觉叙事。这些视觉元素往往包含难以用语言表达的复杂细节。
3.1.2 Text-to-Image Generation

T2I models 用文本图片对进行训练,文本作为输入,图片为目标输出。相关技术:
Generative adversarial networks (GAN):生成对抗网络。
Variational autoencoder (VAE):编码器网络优化将图像编码为潜在表示,而解码器细化将采样的潜在表示转换回新图像的过程。VAE是通过最小化原始图像和解码图像之间的重建误差训练。
Discrete image token prediction:tokenizer and detokenizer,auto-regressive Transformer
Diffusion model:扩散模型,是最广泛使用的开源T2I模型。扩撒模型介绍如下: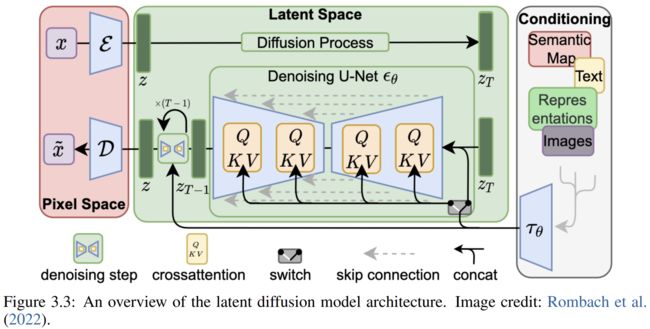
扩散模型(SD模型)包括三个模块:an image VAE, a denoising U-Net, a condition encoder。
3.2 Spatial Controllable Generation
将相关研究分为三个主题。(i) 从将普通T2I模型中的图像级文本描述扩展到基于区域的文本描述使得开放式文本描述可以精确地操作于特定的空间区域。(ii)从方框扩展到表示为2D阵列的密集空间条件,例如分割掩模、边缘图、深度图、关键点。(iii)推理引导的技术这些技术在没有模型微调的情况下实现空间控制。
Region-controlled T2I generation:
用坐标表示位置。
位置标记(例如,<687>、<204>、<999>、<833>)与文本标记无缝混合,并作为空间修饰符操作,指示后面的文本仅在指定的空间区域上操作,例如“棒球运动员…球衣”。
T2I generation with dense conditions:
用2D 数组表示空间位置,如分割掩码,边缘图,深度图。以ControlNet举例,ControlNet基于Stable Diffusion构建,并引入了一个额外的可训练的ControlNet分支,为文本提示添加了额外的输入条件。这个额外的条件可以是canny边缘图、hough线、HED边界、草图、人体姿势图、分割掩模、深度图像、法线图或线条图,每个都有其独特的模型副本。添加的分支从SD的U-Net中的预训练下采样块初始化。该分支将添加的视觉潜在特征(隐变量)和额外的密集条件作为输入。在将输入密集条件与输入中的视觉潜在特征结合并将ControlNet分支的输出合并回SD的上采样块之前,有一个独特的零初始化1×1卷积层。该层作为一个门控连接器,逐渐将额外的条件注入到预训练的Stable Diffusion模型中。通过额外的密集空间控制,ControlNet提供了一个有效的生成可控性通道。
Inference-time spatial guidance:


这个方法不需要微调训练,但是可能不会产生微调方法一样精确的结果。
需要一个鉴别器,鉴别器可以是f表示的Faster-RCNN目标检测器,它在中间估计图像zˆ0上运行,并使用期望布局c计算目标检测损失ℓ,以指导生成ϵˆ(zt, t)。s(t)是指导强度。
3.3 Text-based Editing
Diffusion process manipulations
首先向输入图像添加噪声进行编辑,然后对样本进行去噪,可以产生有意义的编辑。或扩散过程操纵可以通过用户生成的对象掩模m实现局部对象编辑,等。混合空间潜变量存在一定的局限性。首先,要求人为生成的掩码并不总是可行的。其次,生成过程有时会在边缘产生伪影。Prompt2Prompt 发现,交叉注意力层控制着视觉区域和文本单词之间的交互。基于这一观察,该研究实现了对扩散T2I模型生成的图像进行三种编辑,包括单词交换、添加新短语和注意力重新加权,每种编辑都通过对图像文本交叉注意力图进行相应的操作来实现。Imagic超越了编辑合成生成图像的范畴,探索编辑真实的自然图像。其核心思想是将要编辑的图像表示为文本嵌入,并将该嵌入与描述所需图像的目标文本嵌入混合。这种混合确保了生成的图像保留了原始图像的元素,同时与目标文本提示中详细描述的美学相一致。在实践中,需要测试时微调来生成高质量的图像。
Text instruction editing
直接用语言编辑指令,如“swap sunflowers with roses”。
Editing with external pre-trained models
引入额外的语言或视觉模型编辑。
3.4 Text Prompts Following
当句子复杂时生成模型生成的效果不好,可能物体数量、关系等不对,或者丢失名词。
Inference-time manipulation:在推理时解析文本查询,并明确强制T2I模型以更密切地关注每个名词短语,可以生成更好地遵循文本提示的图像。
Model tuning to follow text prompt:实现这一点的一种很有前途的方法是通过强化学习,使用图像-文本相似性作为奖励,而不是主要T2I训练中使用的图像生成目标。这允许对模型进行优化,以实现更好的图像-文本对齐。
3.5 Concept Customization
Single-concept customization:视觉概念定制的目标是使T2I模型能够理解为非常具体的情况量身定制的额外视觉概念。在文本反转中研究的问题设置涉及将少数图像中的视觉概念转换为独特的标记嵌入。如图3.13左侧所示,T2I模型处理不同犬种的四个图像,随后学习新标记的嵌入,表示为[V]。这个[V]标记可以用作表示这个特定狗的文本标记。[V]标记可以与其他文本描述无缝集成,以在各种上下文中呈现特定的狗,例如游泳、在水桶里和理发。
Multi-concept customization:将多个视觉概念集成到单个文本到图像(T2I)模型中。
Customization without test-time finetuning:进行微调的情况下实现概念定制。
3.6 Trends: Unified Tuning for Human Alignments
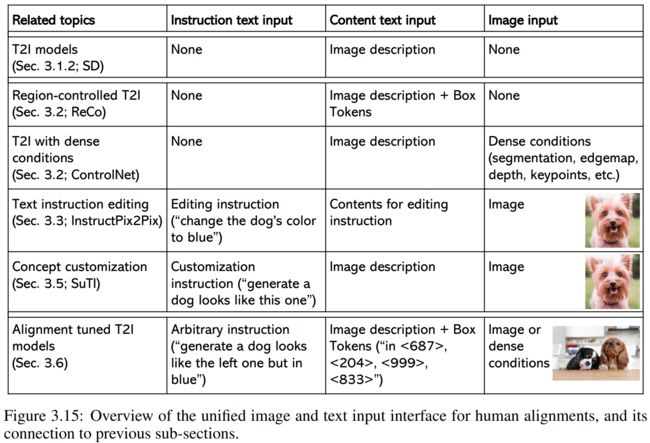
Unified image and text inputs:
Tuning with alignment-focused loss and rewards
Closed-loop of multimodal content understanding and generation