Dynamic Movement Primitives (DMP) 学习
Dynamic Movement Primitives (DMP) 学习
【知乎】Dynamic Movement Primitives介绍及Python实现与UR5机械臂仿真
1. DMP的建模过程
链接:Dynamic Movement Primitives介绍及Python实现与UR5机械臂仿真 - 知乎 (zhihu.com)
沙漏大佬!!!!!!!!!!
通过预编程来规划参考轨迹比较复杂。
示教是一种比较简单直观的方法,我们可以让有经验的人带着机器人先完成一次任务,然后让机器人自动学习其中的过程,从而省去编程的复杂过程。
- 能够使用少量的参数来建模示教的轨迹,通过这些参数能够快速地复现示教轨迹
- 在复现示教轨迹的时候能够增加一些任务参数来泛化和改变原始轨迹
采用 “吸引点” 模型,是自稳定的二阶动态系统,通过改变这个 “吸引点” 来改变系统的最终状态,从而达到修改轨迹目标位置的目的。
最简单最常用的二阶系统就是弹簧阻尼系统(PD控制器)
y ¨ = α y ( β y ( g − y ) − y ˙ ) \ddot y = \alpha_{y}(\beta_{y}(g-y)-\dot y) y¨=αy(βy(g−y)−y˙)
y y y 表示系统状态(例如关节角度), y ˙ \dot y y˙ 和 y ¨ \ddot y y¨ 分别表示 y y y 的一阶导数和二阶导数。 g g g 表示目标状态,最后系统会收敛到这个状态上。 α y \alpha_{y} αy 和 β y \beta_{y} βy 是两个常数,相当于PD控制器中的P参数和D参数。
不足之处:能够让系统收敛到目标状态 g g g ,却无法控制收敛的过程量,比如轨迹的形状。
在这个PD控制器上叠加一个非线性项来控制收敛过程量
把DMP看作是一个PD控制器与一个轨迹形状学习器的叠加
通过改变目标状态 g g g 和非线性项 f f f 来调整我们的轨迹终点和轨迹形状 → \rightarrow → 空间上的改变
y ¨ = α y ( β y ( g − y ) − y ˙ ) + f \ddot y = \alpha_{y}(\beta_{y}(g-y)-\dot y)+f y¨=αy(βy(g−y)−y˙)+f
f f f 就是非线性函数,用于控制过程变量。
不足之处:收敛速度不确定。
在速度曲线 y ˙ \dot y y˙ 上增加一个放缩项 τ \tau τ 来实现
τ 2 y ¨ = α y ( β y ( g − y ) − τ y ˙ ) + f \tau^{2}\ddot y = \alpha_{y}(\beta_{y}(g-y)-\tau\dot y)+f τ2y¨=αy(βy(g−y)−τy˙)+f
DMP的核心公式!
2. 非线性函数 f f f 的确定
叠加非线性函数 f f f 的目的:能够用来改变轨迹的形状
非线性函数 f f f 本质上可以看作给系统施加的 “外力” ,因为 f f f 直接作用到轨迹的二阶导数上,与加速度类似
通过 多个 非线性基函数 的 归一化 线性叠加 来实现
f ( t ) = ∑ i = 1 N Φ i ( t ) ω i ∑ i = 1 N Φ i ( t ) f(t)=\frac{\sum_{i=1}^{N}\Phi_{i}(t)\omega_{i}}{\sum_{i=1}^{N}\Phi_{i}(t)} f(t)=∑i=1NΦi(t)∑i=1NΦi(t)ωi
这个基函数所使用的就是高斯基函数(径向基函数)ω t \omega_t ωt 为每个基函数对应的权重, N N N 为基函数的个数。
不足之处:这样的非线性函数与时间 t t t 高度相关,无法同时建模多个自由度的轨迹,并让它们在时间上与控制系统保持同步。
解决方法:去时间化。
离散型 DMP → \rightarrow → 时间无关的量 x x x 代替 t t t ;
节律型 DMP → \rightarrow → 时间无关的相位 ϕ \phi ϕ 代替 t t t ;
3. 离散型 DMP
离散型DMP 对应 连续的节律型DMP,主要的目的是为了解决笛卡尔空间的轨迹规划问题。
离散型 DMP → \rightarrow → 时间无关的量 x x x 代替 t t t , x x x 来自于一个一阶系统(正则系统)
τ x ˙ = − α x x \tau \dot x=-\alpha_{x} x τx˙=−αxx
推导:
τ d x d t = − α x x τ d x x = − α x d t ∫ τ d x x = ∫ − α x d t τ ln x = − α x t x = exp { − α x τ t } \tau \frac{dx}{dt}=-\alpha_{x}x \\ \tau \frac{dx}{x} =-\alpha_{x}dt \\ \int \tau \frac{dx}{x} = \int -\alpha_{x}dt \\ \tau \ln x = -\alpha_{x}t \\ x = \exp\{-\frac{\alpha_{x}}{\tau}t\} τdtdx=−αxxτxdx=−αxdt∫τxdx=∫−αxdtτlnx=−αxtx=exp{−ταxt}
α x \alpha_{x} αx 是一个常数,常数 τ \tau τ 与DMP公式的 τ \tau τ 保持一致。
当两个常数 α x \alpha_{x} αx 和 τ \tau τ 都是正数的时候, t → ∞ t\rightarrow \infin t→∞ 导致变量 x x x 趋向于 0。
两个常数 α x \alpha_{x} αx 和 τ \tau τ 都将会影响到系统的收敛速度。
因此,可以设置变量 x x x 为任意一个非零正值,这个非零正值本身蕴含着时间 t t t 的信息(因为 x x x 本身就是 t t t 的函数)。变量 x x x 可以看成一个相位变量。
存在某个时刻 t 0 t_{0} t0 使得变量 x = exp { − α x τ t 0 } = 1 x=\exp\{-\frac{\alpha_{x}}{\tau}t_{0}\}=1 x=exp{−ταxt0}=1 的时候表示系统处于初始状态,当变量 x = exp { − α x τ ∞ } = 0 x=\exp\{-\frac{\alpha_{x}}{\tau}\infin\}=0 x=exp{−ταx∞}=0 的时候表示系统收敛到了目标状态。
非线性函数在相位 x x x 的存在下而重新定义。
f ( x , g ) = ∑ i = 1 N Φ i ( x ) ω i ∑ i = 1 N Φ i ( x ) x ( g − y 0 ) f(x,g)=\frac{\sum_{i=1}^{N}\Phi_{i}(x)\omega_{i}}{\sum_{i=1}^{N}\Phi_{i}(x)}x(g-y_{0}) f(x,g)=∑i=1NΦi(x)∑i=1NΦi(x)ωix(g−y0)
x x x 项:保证这个函数能收敛到0;( g − y 0 ) (g-y_{0}) (g−y0)项:是这个函数的 “幅值” ,包含着想要改变轨迹的变化的程度
不足之处:轨迹的目标位置与起始位置都在同一个位置的情况来说, g − y 0 = 0 g-y_{0}=0 g−y0=0,那 f f f 就没有存在的意义。
注意:对于三维空间中的轨迹来说,不是每个维度都要一致才叫一致。
只要其中有任何一个维度是一致的,那么这个维度的 f f f 就会失效,我们就无法学习得到轨迹的形状。
4. 离散型 DMP 中基函数的选择问题
径向基函数,实际就是概率中正态分布的 “核” 函数。
Φ i ( x ) = exp ( − 1 2 σ i 2 ( x − c i 2 ) ) \Phi_{i}(x) = \exp(-\frac{1}{2\sigma_{i}^{2}}(x-c_{i}^{2})) Φi(x)=exp(−2σi21(x−ci2))
σ i \sigma_{i} σi 和 c i c_{i} ci 基函数 Φ i ( x ) \Phi_{i}(x) Φi(x) 的宽度和中心位置,这些都是通过示教过程中学习学到的
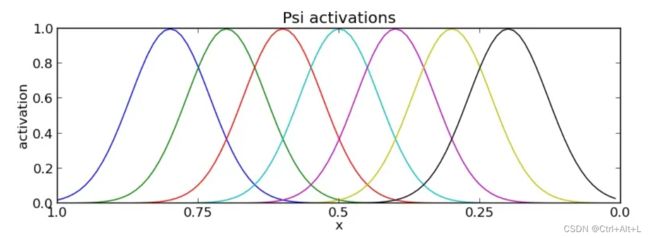
之前描述可知,变量 x x x 可以从 1 收敛到 0.0 。而一系列径向基函数要在区间 [ 0 , 1 ] [0,1] [0,1] 上分布,那么这就意味着这些径向基函数的中心值应该均匀分布一些,这样都能照顾得到。

增加不同权值后的最终非线性函数 f f f ,可见都能收敛到最终值 0.0 。
而由于正则系统最终都能收敛到 0.0 ,从而保证了随着时间推进,非线性项起的作用越来越小,系统最终会趋于稳定,而不会发散失控。
不足之处:变量 x x x 上的均匀布置并不代表时间上的均匀布置。我们增加径向基函数的本质是要增加示教轨迹不同阶段的可改变程度,如果径向基函数都 “扎堆” 在前期,而后期比较少的话,后期改变的程度很有限的。
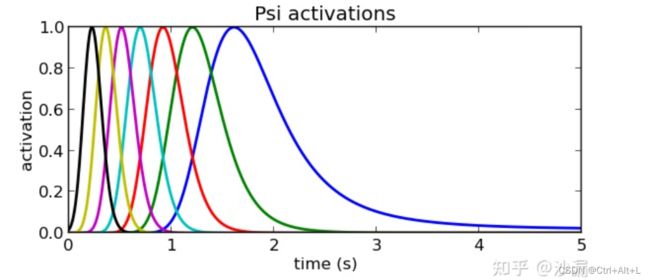
大部分的高斯基函数都集中在初始时刻附近,而随着时间的进行,基函数所起的作用越来越小,这样会导致在曲线拟合的初始阶段效果很好,而在趋于目标位置的末段曲线的拟合效果变差,甚至是无法拟合。这就导致变量 x = 1 x=1 x=1 的时候收敛很快,变化很好;但是变量 x = 0.0 x=0.0 x=0.0 的时候,变化很慢。
从上面的图可以看出,时间轴在 1 ∼ 2 1\sim 2 1∼2 秒左右径向基函数很多,但是在 2 2 2 秒之后就很少径向基函数了,那么在前 2 2 2 秒变化会很 “灵敏”,但是2秒之后就变化很 “愚钝” 。

解决思路:用时间上的均匀布置的点 t 1 , t 2 ⋯ t_{1},t_{2}\cdots t1,t2⋯ 的对应的 x x x 变量 x 1 , x 2 ⋯ x_1,x_2\cdots x1,x2⋯ 来作为中心点。
因为径向基函数本身就关于变量 x x x 的函数,那么这组变量 x 1 , x 2 ⋯ x_1,x_2\cdots x1,x2⋯ 肯定能覆盖在 x x x 区间 [ 0 , 1 ] [0,1] [0,1] 上。
正则系统 x x x 的收敛速度是越来越慢的,那么如果我们把每个基函数的宽度在 x x x 的维度上设定为一样的,就会导致早期的基函数持续时间短,而后期的基函数持续时间长。
因为时间越往后,经过同样宽度的 x x x 所需的时间越多,从而导致在时间的维度上出现基函数的宽度不一致的问题,时间约靠后的宽度越大。
因此,基函数的宽度应该随着时间的递增而递减,从而保证在时间的维度上,每个基函数的宽度也是均匀的。
最后得到的结果是:
h i = N B F s c i h_{i} = \frac{N_{BFs}}{c_{i}} hi=ciNBFs
N B F s N_{BFs} NBFs 的径向基函数的数量。
5. 节律型DMP
因为自己研究暂未涉及到节律型MDP,所以这部分就先仅仅了解下~
节律型 DMP(Rhythmic DMP)是解决连续周期的节律型轨迹规划问题的。
周期性曲线我们需要进行改变和泛化的往往是曲线的幅值与频率,从而获取不同的曲线来满足不同的任务需求。
在节律型DMP中,目标状态是轨迹的中心位置(或者平均位置)。我们可以理解为在做周期性运动时,轨迹会 “围绕” 这个中心位置做往复运动。
节律型DMP的 x ( ϕ ) x(\phi) x(ϕ) 来自另一个正则系统,该系统收敛于一个极限环(Limit cycle)。
τ ϕ ˙ = 1 , ϕ ∈ [ 0 , 2 π ] \tau\dot\phi =1,\phi\in[0,2\pi] τϕ˙=1,ϕ∈[0,2π]
节律型 DMP 的非线性函数
f ( x , g ) = ∑ i = 1 N Φ i ( x ) ω i ∑ i = 1 N Φ i ( x ) r f(x,g)=\frac{\sum_{i=1}^{N}\Phi_{i}(x)\omega_{i}}{\sum_{i=1}^{N}\Phi_{i}(x)}r f(x,g)=∑i=1NΦi(x)∑i=1NΦi(x)ωir
基函数是冯米塞斯函数
Φ i = exp ( h i ⋅ ( cos ( ϕ − c i ) − 1 ) ) \Phi_{i}=\exp(h_i\cdot(\cos(\phi-c_{i})-1)) Φi=exp(hi⋅(cos(ϕ−ci)−1))
通过 r r r 来控制曲线运动的幅值。
在DMP模型的参数学习阶段,我们可以设置 r = 1 r=1 r=1,这样可以保证DMP可以学习到与示教曲线一样的幅值;
在轨迹复现阶段,我们可以通过给定不同的 r r r 来得到不同的幅值。
6. DMP模型学习和轨迹复现
给定示教的轨迹 [ y d e m o , y ˙ d e m o , y ¨ d e m o ] [y_{demo},\dot y_{demo},\ddot y_{demo}] [ydemo,y˙demo,y¨demo]
需要确定的参数:
| PD控制器 | 基函数 | 正则系统 |
|---|---|---|
| α y \alpha_{y} αy β y \beta_{y} βy | 基函数个数 N N N 宽度 c i c_{i} ci 中心值 σ i \sigma_{i} σi 权重 ω i \omega_{i} ωi | α i \alpha_{i} αi |
常数可以自己调整,也可以用强化学习自动改参数
论文采用了局部加权归回方法LWR(Locally Weighted Regression)来学习得到
- 它的计算效率高
- 实时性比较好
- LWR中每个模型Component的学习过程是相互独立的
目标函数 f t a r g e t f_{target} ftarget ,实际就是做了移项
f t a r g e t = τ 2 y ¨ d e m o − α y ( β y ( g − y d e m o ) − τ y ˙ d e m o ) f_{target}=\tau^{2}\ddot y_{demo}-\alpha_{y}(\beta_{y}(g-y_{demo})-\tau\dot y_{demo}) ftarget=τ2y¨demo−αy(βy(g−ydemo)−τy˙demo)
而从前面我们已经分析了非线性项 f f f 是通过基函数加权得到的,因此我们需要构造损失函数,然后使用最优化方法LWR来学习得到这些基函数的模型参数。
构造平方损失函数,然后用最优化方法求解。
J i = ∑ t = 1 P Φ i ( t ) ( f t a r g e t ( t ) − ω i ξ ( t ) ) 2 J_{i}=\sum_{t=1}^{P}\Phi_{i}(t)(f_{target}(t)-\omega_{i}\xi(t))^{2} Ji=t=1∑PΦi(t)(ftarget(t)−ωiξ(t))2
推导:
f ( x , g ) = ∑ i = 1 N Φ i ( x ) ω i ∑ i = 1 N Φ i ( x ) x ( g − y 0 ) ∑ i = 1 N Φ i ( x ) f ( x , g ) = ∑ i = 1 N Φ i ( x ) ω i x ( g − y 0 ) f(x,g)=\frac{\sum_{i=1}^{N}\Phi_{i}(x)\omega_{i}}{\sum_{i=1}^{N}\Phi_{i}(x)}x(g-y_{0}) \\ \sum_{i=1}^{N}\Phi_{i}(x)f(x,g)=\sum_{i=1}^{N}\Phi_{i}(x)\omega_{i}x(g-y_{0}) \\ f(x,g)=∑i=1NΦi(x)∑i=1NΦi(x)ωix(g−y0)i=1∑NΦi(x)f(x,g)=i=1∑NΦi(x)ωix(g−y0)
取每一个子项,则有:
Φ i ( x ) f ( x , g ) = Φ i ( x ) ω i x ( g − y 0 ) \Phi_{i}(x)f(x,g) = \Phi_{i}(x)\omega_{i}x(g-y_{0}) Φi(x)f(x,g)=Φi(x)ωix(g−y0)
最后把 f t a r g e t f_{target} ftarget 替换 f ( x , g ) f(x,g) f(x,g) ,再转换成平方损失,就有上述表达式。
P P P 表示整条轨迹的总时间步数(即 t d t \frac{t}{dt} dtt ),对于离散型DMP, ξ ( t ) = x ( t ) ( g − y 0 ) \xi(t)=x(t)(g−y_0) ξ(t)=x(t)(g−y0) ,对于节律型DMP, ξ ( t ) = r \xi(t)=r ξ(t)=r。上述损失函数的求解过程是一个加权线性回归问题。
ω i = s T Γ i f t a r g e t s T Γ i s \omega_{i} = \frac{s^{T}\Gamma_{i}f_{target}}{s^{T}\Gamma_{i}s} ωi=sTΓissTΓiftarget

2023/03/06 - 上午 - 先看到这里,去吃饭了~
2023/03/06 - 下午 - 对文案又做了一些解释~