经典卷积神经网络-LeNet-5
经典卷积神经网络-LeNet-5
一、背景介绍
LeNet-5是Yann LeCun等人在《Gradient-Based Learning Applied to Document Recogn》论文中提出的一个卷积神经网络,LeNet的基本思想和结构为后来更复杂的神经网络提供了灵感,并为研究者们提供了深入理解卷积神经网络的起点。

二、LeNet-5网络结构
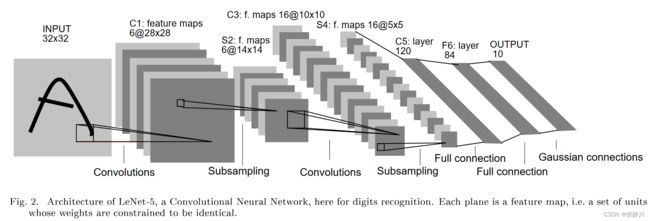
如图所示,这是论文中所介绍的LeNet-5网络结构。输入为一个32 × 32大小的灰度图像,一共包含7层(不包括输入),其中三个卷积层、两个池化层和两个全连接层。
LeNet-5通过卷积操作,利用其参数共享、稀疏连接的特点来提取特征,避免了大量的计算成本,最后再使用全连接层进行分类识别,这个网络是近20年来大量卷积神经网络架构的起源。
由于该论文中的某些技术在现在不是很适用,例如采用的激活函数、输出层采用的分类器等等。所以目前复现的网络都使用了常用的技术进行了替代:将激活函数改为ReLU、将论文中的平均池化改为最大池化、将输出层采用的分类器改为Softmax分类器。具体修改后的网络结构如下:
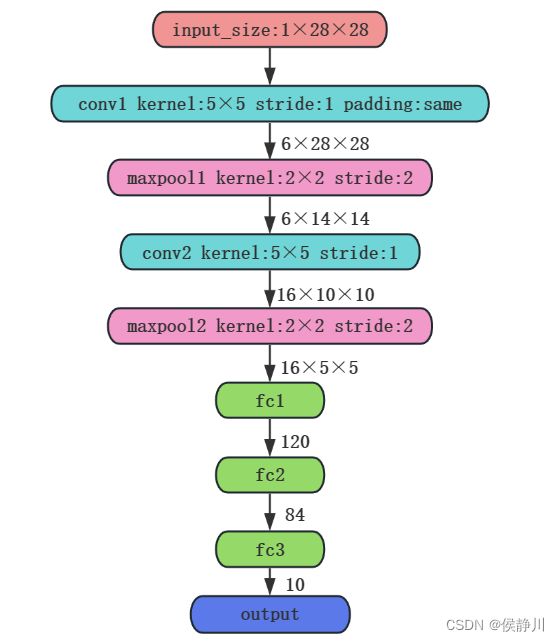
三、LeNet-5的Pytorch实现
import torch
from torch import nn
from torch.nn import Sequential
class LeNet_5(nn.Module):
def __init__(self) -> None:
super().__init__()
# input_size = (1, 28, 28)
self.conv1 = Sequential(
# 由于input_size为28×28 所以conv1的padding就采用same 即填充两层
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2, stride=2)
)
# input_size = (14, 14, 6)
self.conv2 = Sequential(
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1),
nn.MaxPool2d(kernel_size=2, stride=2)
)
# input_size = (5, 5, 16)
self.flatten1 = Sequential(
nn.Flatten(),
)
# input_size = 400
self.fc1 = Sequential(
nn.Linear(in_features=5 * 5 * 16, out_features=120),
nn.ReLU()
)
# input_size = 120
self.fc2 = Sequential(
nn.Linear(in_features=120, out_features=84),
nn.ReLU()
)
# input_size = 84
self.fc3 = Sequential(
nn.Linear(in_features=84, out_features=10)
)
def forward(self, input):
x = self.conv1(input)
x = self.conv2(x)
x = self.flatten1(x)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
if __name__ == '__main__':
model = LeNet_5()
print(model)
input = torch.ones((64, 1, 28, 28))
output = model(input)
print(output.shape)
四、案例:MNIST手写数字识别
MNIST是一个非常经典的入门数据集,下面我们使用LeNet-5来解决MNIST手写数字识别问题。
下面是训练模型的代码:
import torch
import torch.nn as nn
import torchvision
from torch.utils.tensorboard import SummaryWriter
from model import *
from torch.utils.data import DataLoader
from torchvision.transforms import ToTensor
# 1. 准备数据集
train_data = torchvision.datasets.MNIST(root='../dataset', train=True, transform=ToTensor(), download=True)
test_data = torchvision.datasets.MNIST(root='../dataset', train=False, transform=ToTensor(), download=True)
# 查看数据集的数量(长度)
train_data_size = len(train_data)
test_data_size = len(test_data)
# print("训练数据集的长度是:{}".format(train_data_size))
# print("测试数据集的长度是:{}".format(test_data_size))
# 训练数据集的长度是:60000
# 测试数据集的长度是:10000
# 2. 利用 DataLoader来加载数据集
train_dataloader = DataLoader(train_data, batch_size=100, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=False)
# 4. 创建网络模型
model = LeNet_5()
if torch.cuda.is_available():
model = model.cuda()
# 5. 创建损失函数
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_fn = loss_fn.cuda()
# 6. 创建优化器
learning_rate = 1e-3
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 7. 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 5
# 可选1 添加TensorBoard
writer = SummaryWriter("./logs_LeNet-5")
for i in range(epoch):
print("-----------第{}轮训练开始-----------".format(i + 1))
# 8. 训练步骤开始
model.train()
for data in train_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs = model(imgs)
# 计算loss值
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 50 == 0:
print("训练次数:{}, Loss:{}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 9. 测试步骤开始
model.eval()
total_test_loss = 0
total_accuracy = 0
# torch.no_grad() 是一个上下文管理器,用于禁用梯度计算 当进入with后的代码块时,Pytorch会停止跟踪梯度
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs = model(imgs)
loss = loss_fn(outputs, targets)
total_test_loss += loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy += accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的accuracy:{}".format(total_accuracy / test_data_size))
total_test_step += 1
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)
# 10. 保存每一轮我们训练的模型
torch.save(model.state_dict(), "train_model/LeNet-5_{}.pth".format(i + 1))
writer.close()
训练完毕以后,在TensorBoard查看train_loss曲线:
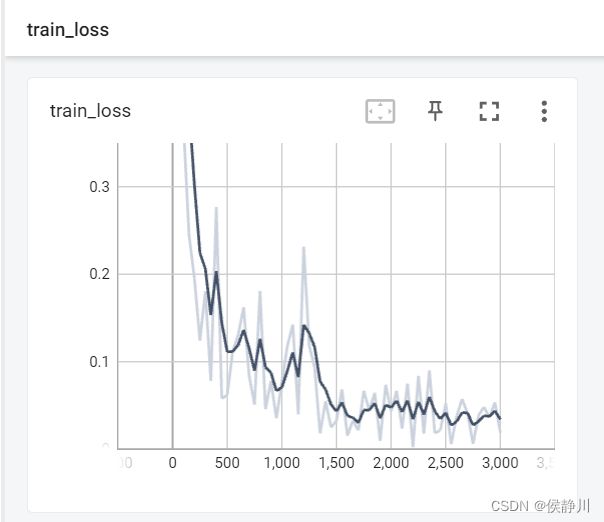
查看test_accuracy曲线:

根据结果,可以看到测试集的准确率能达到98.7%。