80x86汇编—分支循环程序设计
文章目录
- 查表法: 实现16进制数转ASCII码显示
- 计算AX的绝对值
- 判断有无实根
- 地址表形成多分支
- 从100,99,...,2,1倒序累加
- 输入一个字符,然后输出它的二进制数
- 大小写转换
-
- 大写转小写
- 小写转大写
- 冒泡排序
- 剔除空格
查表法: 实现16进制数转ASCII码显示
题目要求:
;查表法,实现十六进制数转换为ASCII码显示
;数据段
HEX db 4bh
ASCII db 30h,31h,32h,33h,34h,35h
db 36h,37h,38h,39h ;0~9的ASCII码
db 41h,42h,43h,44h,45h,46h
;A~F的ASCII码
;任意固定了一个待转换的一位16进制数
思路:首先题目要求的是一个固定的ASCII数据段作为表,然后也固定了一个HEX作为一个待转换的十六进制的数字。希望我们用字符形式将4b显示出来,所以我们可以将高4位和低4位分离出来,然后使用02中断号逐一显示
(02中断号:从dl中取出数值显示,每次显示一个字符,光标就会向右移动一个字符的位置,素有不会覆盖前一个字符)
注意事项:该4bh是一个8位十六进制数,占一个字节数,所以我们在分离的时候很容易错的一个点是,稍不注意就把8位的al使用了(不一定使用al可以是其他寄存器),其实我们还需要将al寄存器的前4位进行清空操作。其次很容易忽略的就是,我们02中断号显示的字符码数值都是从dl中取,所以在处理好的数据后,记得将处理好的数据存进dl中。最后,ah需要存中断号,所以记得将02h存进ah中。由于我们是高低4位需要两次调用,在第二次的调用02h中断号的时候我认为还是要重新将02h存进ah中,因为这样能保证中断号肯定是02h,在第二次调用之前不知道有没有影响到ah,所以我就再次mov ah, 02h,当然你觉得没有影响的话是可以不用重复的(啰嗦一下)。
我的代码肯定不是最优,可以自己去优化一下。理论存在,开始实现!
运行结果:
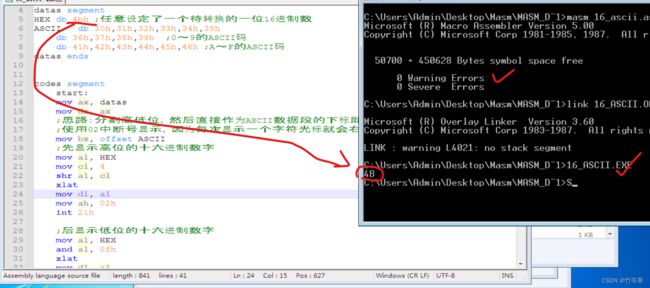
代码实现:
;实现十六进制数转换为ASCII码显示
assume cs:codes, ds:datas
datas segment
HEX db 4bh ;任意设定了一个待转换的一位16进制数
ASCII db 30h,31h,32h,33h,34h,35h
db 36h,37h,38h,39h ;0~9的ASCII码
db 41h,42h,43h,44h,45h,46h ;A~F的ASCII码
datas ends
codes segment
start:
mov ax, datas
mov ds, ax
;思路:分割高低位,然后直接作为ASCII数据段的下标即可
;使用02中断号显示,因为每次显示一个字符光标就会右移一位
mov bx, offset ASCII
;先显示高位的十六进制数字
mov al, HEX
mov cl, 4
shr al, cl
xlat
mov dl, al
mov ah, 02h
int 21h
;后显示低位的十六进制数字
mov al, HEX
and al, 0fh
xlat
mov dl, al
mov ah, 02h
int 21h
;结束代码段
mov ax, 4c00h
int 21h
codes ends
end start
计算AX的绝对值
题目要求:计算AX的绝对值
这题没啥难度,就是基本的存数,取数,然后跳转。
运行结果:

细节:判断完负数后,如果不跳转的话下一条指令就是跳过负数操作的跳转语句。这一步是实现真正的if else语句的精华,当然如果你觉得你可以实现一次跳转的话当我没说。

代码实现:同时也使用了js,判断符号位是否为1即是否为负数的转移指令也是一样效果。
;计算AX的绝对值
assume cs:codes, ds:datas
datas segment
NUM db -5
Result db ?
datas ends
codes segment
start:
mov ax, datas
mov ds, ax
mov al, NUM
cmp al, 0 ;直接跟0比较
;是否跳转可以通过看SF标志位,这是有符号数字,所以我们单看CF是否进位是不行的,
;当然可以用有符号的跳转指令,less和greater,这里我们都尝试一下
jl nee ;小于就跳转
;js nee ;SF符号位是1就表示负数,也要跳转,这个可以替换jl,等同效果
;负数就取补码
jnl none ;如果是正数需要跳过取补码的语句
nee: neg al
;正数绝对值是自己
none: mov Result, al
;结束代码段
mov ax, 4c00h
int 21h
codes ends
end start
- 优化:你还别说,还真有只用一个跳转就能实现取绝对值
其实我们只要反其道而行,判断是否不是负数,也就是说先判断是否是正数,正数就跳转直接存结果,这里通过跳转跳过了一条取补码的语句,所以说当不是正数的时候就会不跳转,直接执行取补码语句,然后自动执行原本就要执行的存结果。如下图所示
运行结果:
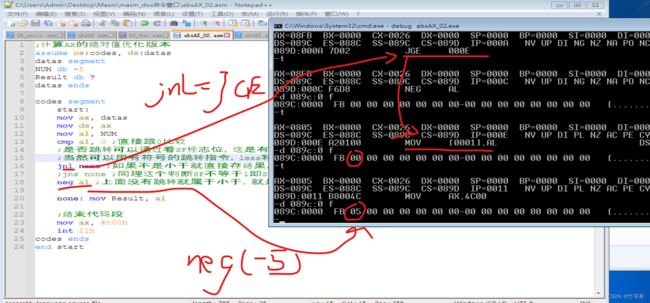
代码实现:
;计算AX的绝对值优化版本
assume cs:codes, ds:datas
datas segment
NUM db -5
Result db ?
datas ends
codes segment
start:
mov ax, datas
mov ds, ax
mov al, NUM
cmp al, 0 ;直接跟0比较
;是否跳转可以通过看SF标志位,这是有符号数字,所以我们单看CF是否进位是不行的,
;当然可以用有符号的跳转指令,less和greater,这里我们都尝试一下
jnl none ;如果不是小于就直接存结果,因为正数绝对值是自己
;jns none ;同理这个判断SF不等于1即SF=0为正数就跳转,否则就执行下面取补码
neg al ;上面没有跳转就属于小于,就是负数,自动来到这里取补码
none: mov Result, al
;结束代码段
mov ax, 4c00h
int 21h
codes ends
end start
判断有无实根
题目要求:判断有无十根,就是判断有无解
首先判断公式就是:b2 - 4ac >= 0 的话就有解
细节:我这里的4 *ac我使用的是ac结果左移两位,当然可以使用传统的imul乘4操作,基本没啥细节可讲。
运行结果:
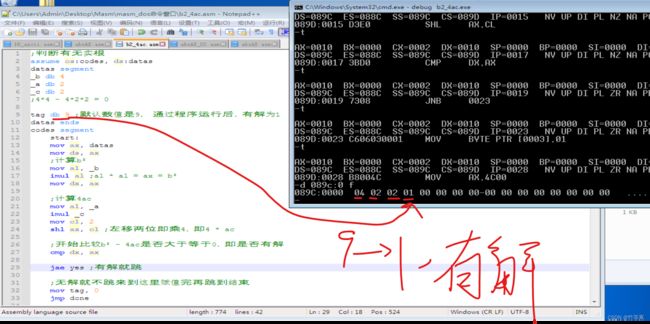
代码实现:
;判断有无实根
assume cs:codes, ds:datas
datas segment
_b db 4
_a db 2
_c db 2
;4*4 - 4*2*2 = 0
tag db 9 ;默认数值是9, 通过程序运行后,有解为1 无解为0
datas ends
codes segment
start:
mov ax, datas
mov ds, ax
;计算b²
mov al, _b
imul al ;al * al = ax = b²
mov dx, ax
;计算4ac
mov al, _a
imul _c
mov cl, 2
shl ax, cl ;左移两位即乘4,即4 * ac
;开始比较b² - 4ac是否大于等于0,即是否有解
cmp dx, ax
jae yes ;有解就跳
;无解就不跳来到这里赋值完再跳到结束
mov tag, 0
jmp done
yes: mov tag, 1 ;有解,且下一条代码就是结束了,所以不用继续跳
;代码段结束
done:
mov ax, 4c00h
int 21h
codes ends
end start
地址表形成多分支
题目要求:
需要在数据段事先安排一个按顺序排列的转移地址表
输入的数字作为偏移量。因为只有2个字节16位偏移地址,所以偏移量需要乘2
注意:这里的地址表是在前头,然后我们disp这些我把他写在了代码段最后面。不用担心未定义,因为在汇编里面的标号翻译成地址都是汇编编译器做的。

细节:最重要的就是题目已经提醒过了,很显然我在做的过程中还是把他忘记了,因为只有2个字节16位偏移地址,所以偏移量需要乘2,这就是我哦们table[bx]用bx查找表的时候需要记得将地址乘以2,因为一个元素就占两个位置,在汇编中就是这样,我们8086是以字节为单位,这里的table一个地址元素就是dw字型,所以我们要乘以2!乘以2!乘以2!,更多细节我都写在代码注释里面了,不明白为什么有的人写代码会忍得住不写注释。。。
其他没啥好注意的,这个代码敲起来还是比较爽的,分支结构越来越像我们高级语言了,实现的时候简直不要太优雅~
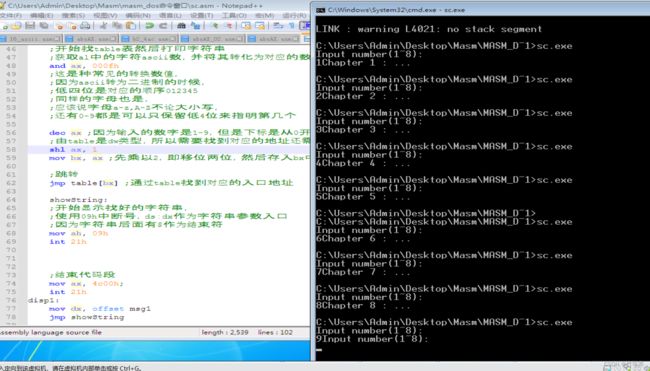
代码实现:
;table是一个标号入口表,
;这些标号都在程序后面,
;每一个标号对应将msg_num的IP地址存入dx然后使用中断号09显示
assume cs:codes, ds:datas
datas segment
msg db 'Input number(1~8):',0dh, 0ah, '$'
msg1 db 'Chapter 1 : ...' ,0dh, 0ah, '$'
msg2 db 'Chapter 2 : ...' ,0dh, 0ah, '$'
msg3 db 'Chapter 3 : ...' ,0dh, 0ah, '$'
msg4 db 'Chapter 4 : ...' ,0dh, 0ah, '$'
msg5 db 'Chapter 5 : ...' ,0dh, 0ah, '$'
msg6 db 'Chapter 6 : ...' ,0dh, 0ah, '$'
msg7 db 'Chapter 7 : ...' ,0dh, 0ah, '$'
msg8 db 'Chapter 8 : ...' ,0dh, 0ah, '$'
table dw disp1,disp2,disp3,disp4 ;取得各个标号的偏移地址
dw disp5,disp6,disp7,disp8
datas ends
codes segment
start:
;常规修改段地址
mov ax, datas
mov ds, ax
;准备工作,打印提示用户输入数字
mov dx, offset msg
mov ah, 09h
int 21h
;等待用户输入一个字符,这就需要用到01中断号,
;刚好是等待一个按键按下,输入的数据送到al中
mov ah, 01h
int 21h
;首先判断是否是1-8之间的数字
cmp al, '1'
;如果小于1就重新输入
jb start
;如果大于8就重新输入
cmp al, '8'
ja start
;开始找table表然后打印字符串
;获取al中的字符ascii数,并将其转化为对应的数值
and ax, 000fh
;这是种常见的转换数值,
;因为ascii转为二进制的时候,
;低四位是对应的顺序012345
;同样的字母也是,
;应该说字母a-z,A-Z不论大小写,
;还有0-9都是可以只保留低4位来指明第几个
dec ax ;因为输入的数字是1-9,但是下标是从0开始的,所以要减一
;由table是dw类型,所以需要找到对应的地址还需要地址转换
shl ax, 1
mov bx, ax ;先乘以2,即移位两位,然后存入bx中
;跳转
jmp table[bx] ;通过table找到对应的入口地址
showString:
;开始显示找好的字符串,
;使用09h中断号,ds:dx作为字符串参数入口
;因为字符串后面有$作为结束符
mov ah, 09h
int 21h
;结束代码段
mov ax, 4c00h;
int 21h
disp1:
mov dx, offset msg1
jmp showString
disp2:
mov dx, offset msg2
jmp showString
disp3:
mov dx, offset msg3
jmp showString
disp4:
mov dx, offset msg4
jmp showString
disp5:
mov dx, offset msg5
jmp showString
disp6:
mov dx, offset msg6
jmp showString
disp7:
mov dx, offset msg7
jmp showString
disp8:
mov dx, offset msg8
jmp showString
codes ends
end start
从100,99,…,2,1倒序累加
题目要求:将100…1相加,然后存到一个sum中
细节:我们的目的操作数是内存的时候,该运算是多少位的就要看源寄存器位置位数是多少,我们这个sum最后用8位二进制位肯定装不下,所以我们要控制他进行运算的位数是16位,所以一定要将源操作数位置中使用16位的寄存器。
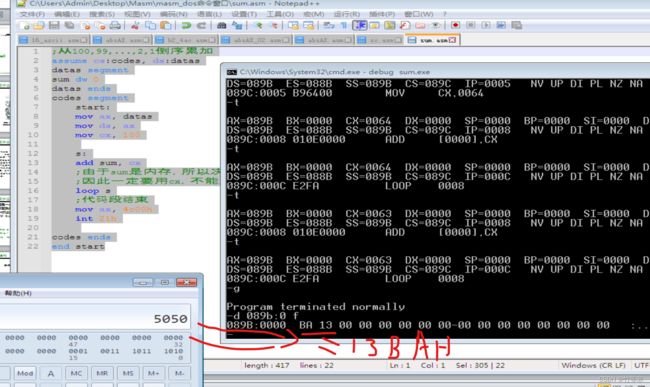
代码实现:
;从100,99,...,2,1倒序累加
assume cs:codes, ds:datas
datas segment
sum dw 0
datas ends
codes segment
start:
mov ax, datas
mov ds, ax
mov cx, 100
s:
add sum, cx
;由于sum是内存,所以决定运算位数的是源操作数,
;因此一定要用cx,不能用cl,否则会变成8位运算装不下的情况
loop s
;代码段结束
mov ax, 4c00h
int 21h
codes ends
end start
输入一个字符,然后输出它的二进制数
题目要求:你输入一个字符,然后需要你将这一个字符的ascii码的二进制数以字符的形式显示出来。
细节:记得将存在al的字符取出来。其次,需要使用adc将左移出去存在CF中的位加进去。
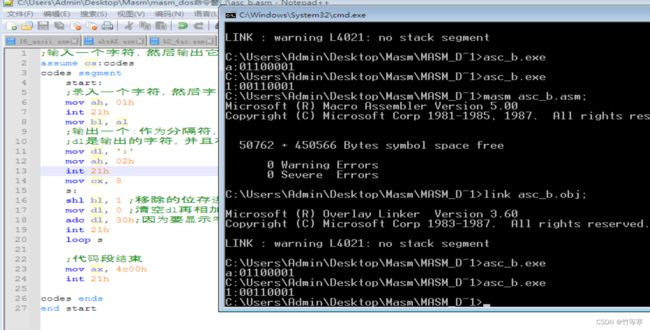
代码实现:
;输入一个字符,然后输出它的二进制数
assume cs:codes
codes segment
start:
;录入一个字符,然后字符存入al中
mov ah, 01h
int 21h
mov bl, al
;输出一个:作为分隔符,使用02中断,
;dl是输出的字符,并且右移一位
mov dl, ':'
mov ah, 02h
int 21h
mov cx, 8
s:
shl bl, 1 ;移除的位存进CF中,可以使用adc加进去
mov dl, 0 ;清空dl再相加
adc dl, 30h;因为要显示字符01,所以我们加上30h
int 21h
loop s
;代码段结束
mov ax, 4c00h
int 21h
codes ends
end start
大小写转换
大写转小写
题目要求:
将字符串中,碰到有大写的字符转为小写字符
不需要操作小写字符
碰到结尾符为0就结束
细节:小写字母中,二进制的从第0位开始数到第五位是1的就是小写字母字符的ascii,强制转小写就是:ax = ‘A’ 的时候 那就or ax , 00100000B
实现大写转小写的运行结果:

代码实现:
;将字符串中,碰到有大写的字符转为小写字符
;不需要操作小写字符
;碰到结尾符为0就结束
assume cs:codes, ds:datas
datas segment
string db "aBCDeFghIJkL"
db 0
datas ends
codes segment
start:
mov ax, datas
mov ds, ax
mov di, 0
again:
mov bl, string[di]
or bl, bl ;判断是否为0了,是的话就结束
jz done
;由于不需要操作小写字符,就要判断是否是大写范围内
cmp bl, 'Z'
;这里先判断是否大于Z,如果是大于的话肯定是小写
;假设我们先判断A的话,每次进来的是小写,小写字符肯定大于A
ja next ;是否大于Z,是就不用转换
cmp bl, 'A'
jb next ;是否小于A,是就不用转换
or bl, 20h ;字母的ascii中二进制数中的第五位为1 , 那就是小写
mov string[di], bl ;需要将转换好的字符存回去
next:
inc di
jmp again
done:
mov ax, 4c00h
int 21h
codes ends
end start
小写转大写
同理,逻辑差不多,修改一下跳转指令和转换操作修改即可。
大写字母中,二进制的从第0位开始数到第五位是0的就是大写字母字符的ascii,强制转大写就是:ax = ‘a’ 的时候 那就and ax , 11011111B
实现大写转小写的运行结果:
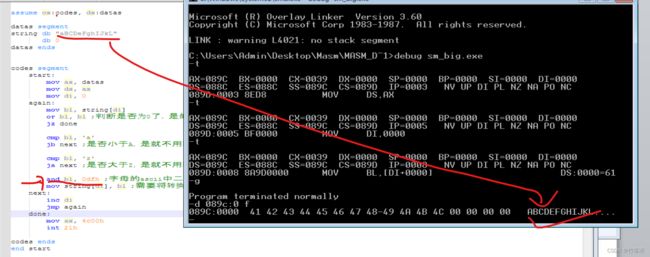
代码实现:
assume cs:codes, ds:datas
datas segment
string db "aBCDeFghIJkL"
db 0
datas ends
codes segment
start:
mov ax, datas
mov ds, ax
mov di, 0
again:
mov bl, string[di]
or bl, bl ;判断是否为0了,是的话就结束
jz done
cmp bl, 'a'
jb next ;是否小于A,是就不用转换
cmp bl, 'z'
ja next ;是否大于Z,是就不用转换
and bl, 0dfh ;字母的ascii中二进制数中的第五位为0 , 那就是大写
mov string[di], bl ;需要将转换好的字符存回去
next:
inc di
jmp again
done:
mov ax, 4c00h
int 21h
codes ends
end start
冒泡排序
题目要求:
将下面这段数据从小到大排序,使用冒泡排序
datas segment
list db 32, 85, 16, 15, 8
datas ends
既然学汇编了,那必然不是什么小人物了,所以冒泡就不介绍了。
细节:我们的list是db类型,记得使用8位寄存器来交换,否则会连累到后面的数据。别问我为什么知道会这样
代码实现:
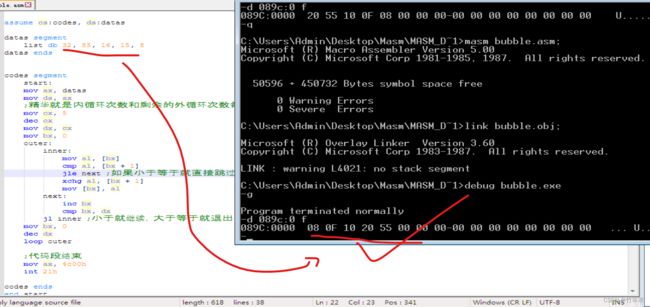
assume cs:codes, ds:datas
datas segment
list db 32, 85, 16, 15, 8
datas ends
codes segment
start:
mov ax, datas
mov ds, ax
;精华就是内循环次数和剩余的外循环次数每次都是一样的
mov cx, 5
dec cx
mov dx, cx
mov bx, 0
outer:
inner:
mov al, [bx]
cmp al, [bx + 1]
jle next ;如果小于等于就直接跳过不交换
xchg al, [bx + 1]
mov [bx], al
next:
inc bx
cmp bx, dx
jl inner ;小于就继续,大于等于就退出
mov bx, 0
dec dx
loop outer
;代码段结束
mov ax, 4c00h
int 21h
codes ends
end start
剔除空格
题目要求:
现有一个以$结尾的字符串,要求剔除其中的空格
assume cs:codes, ds:datas
datas segment
string db ‘Let us have a try !’, ‘$’
datas ends
细节:还是别忘记了字符是db,所以交换的时候记得用8位寄存器。其次我们最后的
mov al, [di-1]
cmp al, ' ′ 这两句差点把我搞崩了, d i − 1 这里需要 − 1 是因为我在之前 i n c d i 了,所以如果要找到原本的字符就要 ' 这两句差点把我搞崩了,di-1这里需要-1是因为我在之前inc di了,所以如果要找到原本的字符就要 ′这两句差点把我搞崩了,di−1这里需要−1是因为我在之前incdi了,所以如果要找到原本的字符就要,否则当你到最后的时候,由于inc di,下标过了$字符,那就永远跳不出循环了,
然后就是cmd控制台直接给你卡住…
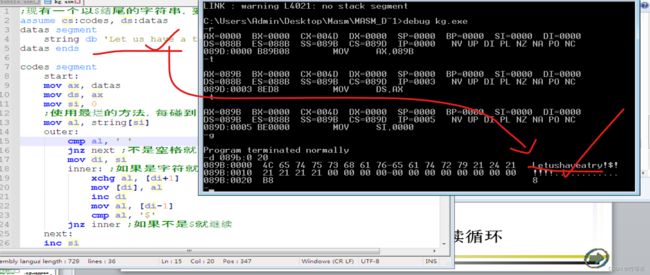
;现有一个以$结尾的字符串,要求剔除其中的空格
assume cs:codes, ds:datas
datas segment
string db 'Let us have a try !', '$'
datas ends
codes segment
start:
mov ax, datas
mov ds, ax
mov si, 0
;使用最烂的方法,每碰到一次空格就全部向前移动一次
mov al, string[si]
outer:
cmp al, ' '
jnz next ;不是空格就下一个字符
mov di, si
inner: ;如果是字符就进行移位
xchg al, [di+1]
mov [di], al
inc di
mov al, [di-1]
cmp al, '$'
jnz inner ;如果不是$就继续
next:
inc si
mov al, string[si]
cmp al, '$'
jnz outer ;如果不是$就继续
;代码段结束
mov ax, 4c00h
int 21h
codes ends
end start