C++初阶——类与对象
目录
C++宏函数
在使用宏函数时,有几个常见的错误需要注意:
宏函数在某些情况下有以下优势:
1.C++宏函数
在 C++ 中,宏函数(Macro Function)是使用预处理器定义的宏(Macro),类似于 C 语言中的宏函数。它们在编译前进行文本替换,以实现一些简单的函数功能。
C++ 中的宏函数与 C 语言中的宏函数定义方式相同,用 #define 指令来定义。宏函数可以接受参数,并且没有函数调用的开销。
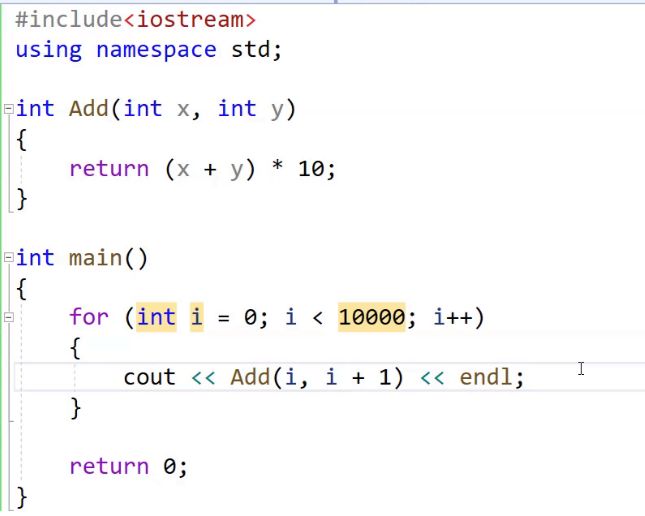
下面是一个使用宏函数计算两个整数的平方和的示例:
#define SQUARE_SUM(x, y) ((x)*(x) + (y)*(y))
int main() {
int a = 3;
int b = 4;
int result = SQUARE_SUM(a, b);
// 展开后的宏函数:((a)*(a) + (b)*(b))
// 计算结果为 3*3 + 4*4 = 9 + 16 = 25
return 0;
}
在上面的示例中,我们使用 #define 定义了一个名为 SQUARE_SUM 的宏函数,它接受两个参数 x 和 y。宏函数展开后,会将参数的值替换到相应的位置,然后进行平方和的计算。
需要注意的是,宏函数的展开是在编译前进行的,因此宏函数中的参数没有类型检查。这也是宏函数的一个缺点,可能会导致一些错误,例如参数计算多次、副作用等问题。
在 C++ 中,宏函数的使用相对较少,更推荐使用内联函数或模板来替代宏函数。内联函数和模板可以提供更好的类型安全性和可读性,并且能够进行编译时的优化。
总之,C++ 中的宏函数是通过预处理器定义的宏,用于实现简单的函数功能。它们在编译前进行文本替换,没有函数调用的开销,但可能存在潜在的问题,因此在实际编程中建议使用内联函数或模板代替宏函数。0

在使用宏函数时,有几个常见的错误需要注意:
缺少括号:由于宏函数展开是简单的文本替换,没有类型检查,因此在宏函数中使用参数时应该用括号将参数括起来,以避免优先级问题。例如,
#define SQUARE(x) x * x这个宏函数没有正确使用括号,会导致展开后的结果不符合预期。副作用问题:宏函数的参数可能会被多次计算,在某些情况下可能导致副作用。例如,
#define MAX(a, b) ((a) > (b) ? (a) : (b))这个宏函数在计算参数时会对它们进行多次求值,如果参数中包含有副作用的表达式(例如函数调用、改变变量等),则可能会导致意外的结果。名称冲突:宏函数的名称是全局的,容易与其他代码中的变量或函数名称发生冲突。为了避免名称冲突,通常可以在宏函数名称前添加特定的前缀或命名空间。
缺乏类型安全:宏函数没有类型检查,参数的类型和数量都是由开发者自行控制。这可能导致难以发现的类型错误或潜在的问题。为了提高类型安全性,建议使用内联函数或模板代替宏函数。
可读性差:宏函数展开后的代码可能会变得非常冗长,可读性较差。这使得调试和维护代码变得困难。使用内联函数或模板可以提高代码的可读性和可维护性。
总之,在使用宏函数时,需要注意上述常见的错误,并尽量避免使用宏函数可能带来的潜在问题。如果有更复杂的功能需求,建议使用内联函数、模板或其他更合适的方法来实现。
宏函数在某些情况下有以下优势:
没有函数调用开销:宏函数在编译时被展开为代码,没有函数调用的开销,可以提高程序的执行效率。
可以使用常量表达式:宏函数可以使用常量表达式作为参数,这些表达式在编译时就会被计算,并且展开后的代码也是常量表达式,可以进行编译时的优化。
可以完成简单的操作:宏函数通常用于实现简单的操作,例如计算平方、计算最大值等,可以提高代码的可读性和可维护性。
可以实现一些高级功能:宏函数可以实现一些高级功能,例如条件编译、调试信息输出等。在一些特殊的情况下,它们可以代替其他更复杂的解决方案。
具有灵活性:宏函数可以根据需要定义不同的版本,例如根据不同的平台或编译器来定义不同的实现。这使得宏函数具有一定的灵活性和适应性。
总之,在某些情况下,使用宏函数可以提高程序的效率和可读性,实现一些简单和高级功能。但是,在使用宏函数时,需要注意潜在的问题,并尽量避免使用它们可能带来的副作用和错误。
让我们来了解一下C++中的类和对象。
2.类
在C++中,类是一种用户自定义的数据类型,它可以封装数据成员和函数成员,从而表示某种抽象概念。类定义的一般形式为:
class ClassName {
private:
// 私有成员变量
public:
// 公有成员变量和函数
};
其中,private表示私有成员,只能在类内部访问;public表示公有成员,可以在类内部和外部访问。
例如,下面是一个简单的类定义:
class Dog {
private:
int age;
string name;
public:
void bark() {
cout << "汪汪!" << endl;
}
void setAge(int a) {
age = a;
}
void setName(string n) {
name = n;
}
void printInfo() {
cout << "我是一只 " << name << ",今年 " << age << " 岁。" << endl;
}
};
这个类表示了一只狗的抽象概念,包含了年龄和名字两个私有成员,以及叫声、设置年龄、设置名字、输出信息等公有成员。
3.对象
在C++中,通过类定义出来的具体实例被称为对象。对象具有类成员的特征,可以调用公有成员函数,访问公有成员变量。对象的一般形式为:
ClassName ObjectName;
例如,我们可以通过上面定义的Dog类来创建一个狗的对象:
Dog myDog;
这个对象名为myDog,它具有Dog类的属性和行为,可以调用公有成员函数,访问公有成员变量。例如,我们可以设置它的年龄和名字,然后输出它的信息:
myDog.setAge(3);
myDog.setName("小黄");
myDog.printInfo();
运行结果为
我是一只 小黄,今年 3 岁。
这样,我们就成功地使用C++中的类和对象了。
4.C++中的类与对象带来了许多优势
包括:
-
封装性:类允许将数据和相关的函数封装在一起,形成一个独立的实体。这样可以隐藏实现细节,对外部提供接口,提高代码的安全性和可维护性。
-
继承性:通过继承,一个类可以从另一个类派生,获得父类的属性和方法,并可以在此基础上添加新的功能。继承提供了代码重用的机制,减少了重复编写代码的工作量。
-
多态性:C++支持运行时多态,即通过函数重写和虚函数实现。多态性使得不同类型的对象可以以相同的方式被处理,提高了代码的灵活性和可扩展性。
-
数据抽象:类可以定义抽象数据类型,将数据和操作封装在一起。这样可以将内部细节隐藏起来,只对外提供必要的接口,提高了代码的可读性和可维护性。
-
可扩展性:类允许在已有的基础上进行扩展和修改。可以通过添加新的成员函数或成员变量来增加功能,也可以通过派生新的类来扩展已有的类。
-
数据共享和保护:类的对象可以根据需要创建多个实例,每个实例都有独立的数据。这样可以实现数据的共享和保护,不同对象之间的数据不会相互干扰。
-
可维护性:类的使用使得代码更加模块化和结构化,易于维护和调试。类的修改只需要关注特定的部分,不会影响到其他部分,降低了出错的概率。
5.C++类的案例
#include
using namespace std;
class Rectangle {
private:
int width, height;
public:
Rectangle() {
width = 0;
height = 0;
}
Rectangle(int w, int h) {
width = w;
height = h;
}
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
int getArea() {
return width * height;
}
};
int main() {
Rectangle r1;
Rectangle r2(3, 4);
r1.setWidth(5);
r1.setHeight(6);
cout << "r1 area is " << r1.getArea() << endl;
cout << "r2 area is " << r2.getArea() << endl;
return 0;
}
上述代码定义了一个名为Rectangle的类,用于计算矩形的面积。该类包含两个私有成员变量width和height,以及构造函数、设置宽高的函数和计算面积的函数。在main函数中,创建了两个Rectangle对象r1和r2,分别通过构造函数和设置函数设置其宽高,并调用getArea函数计算面积并输出。
以上仅是一个简单的案例,展示了C++类的基本使用方法,实际应用中类可以包含更多的成员变量和成员函数,实现更加复杂的操作。
6.C++类相关的选择题
以及它们的答案:
6.1以下哪个选项描述了C++类的封装性?
- a) 类的继承性 b) 类的多态性 c) 类的数据抽象性 d) 类的可扩展性
答案: c) 类的数据抽象性
6.2在C++中,通过继承可以实现什么?
- a) 封装数据和函数 b) 对象的创建和销毁 c) 代码的重用和扩展 d) 多个对象之间的通信
答案: c) 代码的重用和扩展
6.3下面关于C++类的说法正确的是:
- a) 类只能有一个成员变量 b) 类可以直接访问私有成员变量 c) 类可以包含其他类的对象作为成员变量 d) 类不能包含静态成员变量
答案: c) 类可以包含其他类的对象作为成员变量