时间语义 和 窗口
目录
时间语义
分类
设置时间语义
窗口
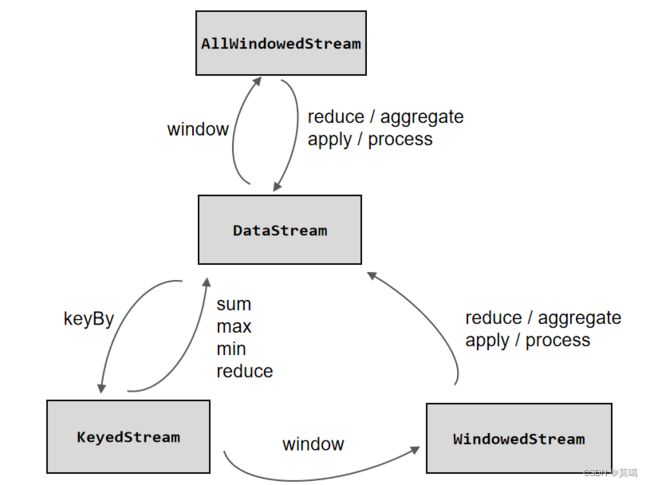
keyed streams和non-keyed streams
窗口的分类
一、按驱动类型:
(1).时间窗口(Time Window)
(2).计数窗口(Count Window)
二、按分配数据:
(1).滚动窗口(Tumbling Window)
(2).滑动窗口(Sliding Windows)
(3).会话窗口(Session Windows)
(4).全局窗口(Global Windows)
窗口函数(Window Functions)
增量聚合函数
1.ReduceFunction(归约函数)
2.AggregateFunction(聚合函数)
3.ProcessWindowFunction(全窗口函数)
增量聚合的 ProcessWindowFunction
ReduceFunction 增量聚合
AggregateFunction 增量聚合
时间语义
分类
一、事件时间(Event Time):指数据生产的时间(时间戳 Timestamp)
二、处理时间( Processing Time):数据真正被处理的时间
三、摄取时间(Ingestion Time):事件进入Flink的时间
到底是以哪种时间作为衡量标准就是所谓的时间语义
设置时间语义
在 Flink 的流式处理中, 绝大部分的业务都会使用 eventTime, 一般只在eventTime 无法使用时,才会被迫使用ProcessingTime 或者 IngestionTime
在Flink中,我们需要在执行环境层面设置使用哪种时间语义。下面的代码使用Event Time:
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
如果想用另外两种时间语义,需要替换为:TimeCharacteristic.ProcessingTime和TimeCharacteristic.IngestionTime。
窗口
窗口(Window)是处理无界流的关键所在。窗口可以将数据流装入大小有限的“桶”中,再对每个“桶”加以处理。 本文的重心将放在 Flink 如何进行窗口操作以及开发者如何尽可能地利用 Flink 所提供的功能。
keyed streams和non-keyed streams
在定义窗口操作之前,首先需要确定,到底是基于按键分区(Keyed)的数据流KeyedStream来开窗,还是直接在没有按键分区的DataStream上开窗。也就是说,在调用窗口算子之前,是否有keyBy操作。
这两者唯一的区别仅在于:keyed streams 要调用
keyBy(...)后再调用window(...), 而 non-keyed streams 只用直接调用windowAll(...)。留意这个区别,它能帮我们更好地理解后面的内容。
窗口的分类
一、按驱动类型:
窗口本身是一个截取有界数据的一种方式,所以窗口一个非常重要的信息就是“怎样截数据”。换句话说,就是以什么标准来开始和结束数据就截取,我们把它叫做窗口的“驱动类型”。
(1).时间窗口(Time Window)
时间窗口以时间点来定义窗口的开始(start)和结束(end),所以截取出来的就是某一时间段的时间的数据。到达结束时间时,窗口不再收集数据,触发计算数据结果,并将窗口关闭销毁。所以可以说基本思路就是“定点发车”。
(2).计数窗口(Count Window)
计数窗口基于元素的个数来截取数据,到达固定的个数时就触发计算并关闭窗口。每个窗口截取数据的个数,就是窗口的大小。基本思路是“人齐发车”。

二、按分配数据:
根据分配数据的规则,窗口的具体实现分可以分为4类:滚动窗口(Tumbling Window)、滑动窗口(Sliding Window)、会话窗口(Session Window)、全局窗口(Global Window)。
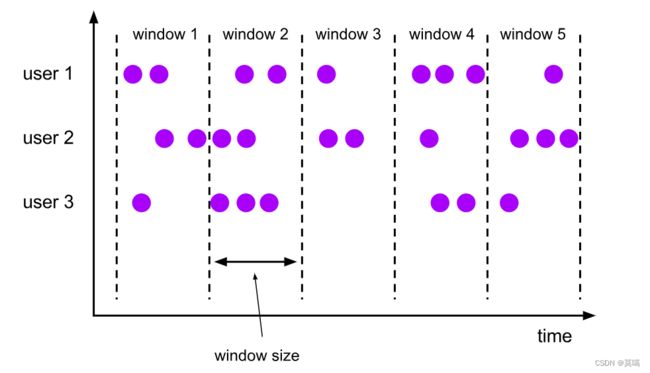
(1).滚动窗口(Tumbling Window)
滚动窗口的大小是固定的,且各自范围之间不重叠。比如,如果你指定了滚动窗口的大小为5分钟,那么每5分钟就会有一个窗口被计算,且一个新的窗口被创建。用.
下面的代码展示了如何使用滚动窗口:
处理时间:窗口分配器由类TumblingProcessingTimeWindows提供,需要调用它的静态方法.of()。
事件时间:窗口分配器由类TumblingEventTimeWindows提供,用法与滚动处理时间窗口完全一致。
滚动计数窗口只需要传入一个长整型的参数size,表示窗口的大小。
stream.keyBy(...) .countWindow(10)我们定义了一个长度为10的滚动计数窗口,当窗口中元素数量达到10的时候,就会触发计算执行并关闭窗口。
java:
DataStream input = ...;
// 滚动 event-time 窗口
input
.keyBy()
.window(TumblingEventTimeWindows.of(Time.seconds(5))) //这里.of()方法需要传入一个Time类型的参数size,表示滚动窗口的大小,我们这里创建了一个长度为5秒的滚动窗口。
.();
// 滚动 processing-time 窗口
input
.keyBy()
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.();
// 长度为一天的滚动 event-time 窗口, 偏移量为 -8 小时。
input
.keyBy()
.window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8)))
.(); scala:
val input: DataStream[T] = ...
// 滚动 event-time 窗口 事件时间窗口
input
.keyBy()
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.()
// 滚动 processing-time 窗口 处理时间窗口
input
.keyBy()
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.()
// 长度为一天的滚动 event-time 窗口,偏移量为 -8 小时。一个重要的 offset 用例是根据 UTC-0 调整窗口的时差。
input
.keyBy()
.window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8)))
.() (2).滑动窗口(Sliding Windows)
与滚动窗口类似,窗口大小通过window size参数设置。滑动窗口需要一个额外的滑动距离(window slide)参数来控制生成新的窗口的频率。因此,slide小于窗口大小,滑动窗口允许窗口重叠。这种情况下,一个元素可能会被分发到多个窗口。
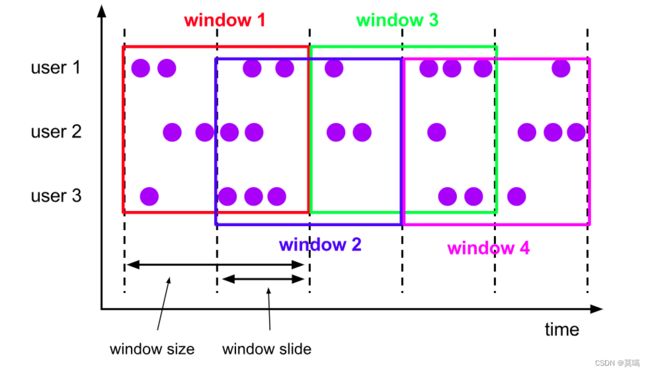
处理时间:窗口分配器由类SlidingProcessingTimeWindows提供,同样需要调用它的静态方法.of()。第一个参数为长度,第二个参数为步长。
事件事件:窗口分配器由类SlidingEventTimeWindows提供,用法与滑动处理时间窗口完全一致。
与滚动计数窗口类似,不过需要在.countWindow()调用时传入两个参数:size和slide,前者表示窗口大小,后者表示滑动步长。
stream.keyBy(...) .countWindow(10,3)我们定义了一个长度为10、滑动步长为3的滑动计数窗口。每个窗口统计10个数据,每隔3个数据就统计输出一次结果。
java:
DataStream input = ...;
// 滑动 event-time 窗口
input
.keyBy()
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.();
// 滑动 processing-time 窗口
input
.keyBy()
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.();
// 滑动 processing-time 窗口,偏移量为 -8 小时
input
.keyBy()
.window(SlidingProcessingTimeWindows.of(Time.hours(12), Time.hours(1), Time.hours(-8)))
.(); scala:
val input: DataStream[T] = ...
// 滑动 event-time 窗口
input
.keyBy()
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.()
// 滑动 processing-time 窗口
input
.keyBy()
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.()
// 滑动 processing-time 窗口,偏移量为 -8 小时
input
.keyBy()
.window(SlidingProcessingTimeWindows.of(Time.hours(12), Time.hours(1), Time.hours(-8)))
.() (3).会话窗口(Session Windows)
与滚动和滑动窗口不同,会话窗口不会互相重叠,且没有固定的开始或者结束时间。会话窗口在一段时间没有收到数据之后会关闭。当超出不活跃的时间段,当前的会话就会关闭,且将下来的数据分发到新的会话窗口。
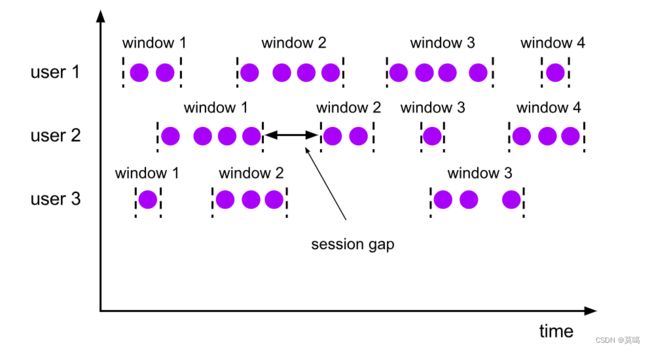
处理时间:窗口分配器由类ProcessingTimeSessionWindows提供,需要调用它的静态方法.withGap()或者.withDynamicGap()。
这里.withGap()方法需要传入一个Time类型的参数size,表示会话的超时时间,也就是最小间隔session gap。我们这里创建了静态会话超时时间为10秒的会话窗口。
另外,还可以调用withDynamicGap()方法定义session gap的动态提取逻辑。
事件时间:窗口分配器由类EventTimeSessionWindows提供,用法与处理时间会话窗口完全一致。
java:
DataStream input = ...;
// 设置了固定间隔的 event-time 会话窗口
input
.keyBy()
.window(EventTimeSessionWindows.withGap(Time.minutes(10)))
.();
// 设置了动态间隔的 event-time 会话窗口
input
.keyBy()
.window(EventTimeSessionWindows.withDynamicGap((element) -> {
// 决定并返回会话间隔
}))
.();
// 设置了固定间隔的 processing-time session 窗口
input
.keyBy()
.window(ProcessingTimeSessionWindows.withGap(Time.minutes(10)))
.();
// 设置了动态间隔的 processing-time 会话窗口
input
.keyBy()
.window(ProcessingTimeSessionWindows.withDynamicGap((element) -> {
// 决定并返回会话间隔
}))
.(); scala:
val input: DataStream[T] = ...
// 设置了固定间隔的 event-time 会话窗口
input
.keyBy()
.window(EventTimeSessionWindows.withGap(Time.minutes(10)))
.()
// 设置了动态间隔的 event-time 会话窗口
input
.keyBy()
.window(EventTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor[String] {
override def extract(element: String): Long = {
// 决定并返回会话间隔
}
}))
.()
// 设置了固定间隔的 processing-time 会话窗口
input
.keyBy()
.window(ProcessingTimeSessionWindows.withGap(Time.minutes(10)))
.()
// 设置了动态间隔的 processing-time 会话窗口
input
.keyBy()
.window(DynamicProcessingTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor[String] {
override def extract(element: String): Long = {
// 决定并返回会话间隔
}
}))
.() 固定间隔可以使用 Time.milliseconds(x)、Time.seconds(x)、Time.minutes(x) 等来设置。
动态间隔可以通过实现 SessionWindowTimeGapExtractor 接口来指定。
会话窗口并没有固定的开始或结束时间,所以它的计算方法与滑动窗口和滚动窗口不同。在 Flink 内部,会话窗口的算子会为每一条数据创建一个窗口, 然后将距离不超过预设间隔的窗口合并。 想要让窗口可以被合并,可以使用:
ReduceFunction、AggregateFunction或ProcessWindowFunction。
(4).全局窗口(Global Windows)
将拥有相同key的所有数据分发到一个全局窗口。这种窗口时没有结束的时候,默认时不会做触发计算的。如果希望它能对数据进行计算处理,还需要自定义“触发器” (Trigger)。

全局窗口是计数窗口的底层实现,一般在需要自定义窗口时使用。它的定义同样是直接调用.window(),分配器由GlobalWindows类提供。
stream.keyBy(...) .window(GlobalWindows.create());需要注意使用全局窗口,必须自行定义触发器才能实现窗口计算,否则起不到任何作用。
java:
DataStream input = ...;
input
.keyBy()
.window(GlobalWindows.create())
.(); scala:
val input: DataStream[T] = ...
input
.keyBy()
.window(GlobalWindows.create())
.() 窗口函数(Window Functions)
指定窗口分配器之后,我们如何计算每个窗口中的数据,这就是window function的职责。
窗口函数定义了要对窗口中收集的数据做的计算操作,根据处理的方式可以分为两类:增量聚合函数和全窗口函数。
增量聚合函数
窗口将数据收集起来,最基本的处理操作当然就是进行聚合。我们可以每来一个数据就在之前结果上聚合一次,这就是“增量聚合”。
1.ReduceFunction(归约函数)
指定两条输入数据如何合并起来产生一条输出数据,输入和输出的数据类型必须相同。
归约函数(Reduction Function)是一种将一系列值归约成一个值的函数。在函数式编程中,归约函数通常用于对一个列表的所有元素进行操作,并将结果累积起来。常见的归约函数包括sum、reduce、all、any等。这些函数的思想是将某个操作连续应用到序列的元素上,累加之前的结果,最终归约成一个值。
java:
DataStream> input = ...;
input
.keyBy()
.window()
.reduce(new ReduceFunction>() {
public Tuple2 reduce(Tuple2 v1, Tuple2 v2) {
return new Tuple2<>(v1.f0, v1.f1 + v2.f1);
}
}); scala:
val input: DataStream[(String, Long)] = ...
input
.keyBy()
.window()
.reduce { (v1, v2) => (v1._1, v1._2 + v2._2) } 2.AggregateFunction(聚合函数)
AggregateFunction可以看作是ReduceFunction的通用版本,这里有三种类型:输入类型(IN)、累加器类型(ACC)和输出类型(OUT)。
输入类型IN就是输入流中元素的数据类型;
累加器类型ACC则是我们进行聚合的中间状态类型;
而输出类型当然就是最终计算结果的类型了。
接口中有四个方法:
- createAccumulator():创建一个累加器,这就是为聚合创建了一个初始状态,每个聚合任务只会调用一次。
- add():将输入的元素添加到累加器中。
- getResult():从累加器中提取聚合的输出结果。
- merge():合并两个累加器,并将合并后的状态作为一个累加器返回。
java:
/**
* The accumulator is used to keep a running sum and a count. The {@code getResult} method
* computes the average.
*/
private static class AverageAggregate
implements AggregateFunction, Tuple2, Double> {
@Override
public Tuple2 createAccumulator() {
return new Tuple2<>(0L, 0L);
}
@Override
public Tuple2 add(Tuple2 value, Tuple2 accumulator) {
return new Tuple2<>(accumulator.f0 + value.f1, accumulator.f1 + 1L);
}
@Override
public Double getResult(Tuple2 accumulator) {
return ((double) accumulator.f0) / accumulator.f1;
}
@Override
public Tuple2 merge(Tuple2 a, Tuple2 b) {
return new Tuple2<>(a.f0 + b.f0, a.f1 + b.f1);
}
}
DataStream> input = ...;
input
.keyBy()
.window()
.aggregate(new AverageAggregate()); sacla:
/**
* The accumulator is used to keep a running sum and a count. The [getResult] method
* computes the average.
*/
class AverageAggregate extends AggregateFunction[(String, Long), (Long, Long), Double] {
override def createAccumulator() = (0L, 0L)
override def add(value: (String, Long), accumulator: (Long, Long)) =
(accumulator._1 + value._2, accumulator._2 + 1L)
override def getResult(accumulator: (Long, Long)) = accumulator._1 / accumulator._2
override def merge(a: (Long, Long), b: (Long, Long)) =
(a._1 + b._1, a._2 + b._2)
}
val input: DataStream[(String, Long)] = ...
input
.keyBy()
.window()
.aggregate(new AverageAggregate) 3.ProcessWindowFunction(全窗口函数)
窗口函数有三种:
ReduceFunction、AggregateFunction或ProcessWindowFunction。 前两者执行起来更高效,因为 Flink 可以在每条数据到达窗口后 进行增量聚合(incrementally aggregate)。
而
ProcessWindowFunction会得到能够遍历当前窗口内所有数据的Iterable,以及关于这个窗口的 meta-information。
使用
ProcessWindowFunction的窗口转换操作没有其他两种函数高效,因为 Flink 在窗口触发前必须缓存里面的所有数据。ProcessWindowFunction可以与ReduceFunction或
AggregateFunction合并来提高效率。 这样做既可以增量聚合窗口内的数据,又可以从ProcessWindowFunction接收窗口的 metadata。
ProcessWindowFunction 有能获取包含窗口内所有元素的 Iterable, 以及用来获取时间和状态信息的 Context 对象,比其他窗口函数更加灵活。 ProcessWindowFunction 的灵活性是以性能和资源消耗为代价的, 因为窗口中的数据无法被增量聚合,而需要在窗口触发前缓存所有数据。
java:
DataStream> input = ...;
input
.keyBy(t -> t.f0)
.window(TumblingEventTimeWindows.of(Time.minutes(5)))
.process(new MyProcessWindowFunction());
/* ... */
public class MyProcessWindowFunction
extends ProcessWindowFunction, String, String, TimeWindow> {
@Override
public void process(String key, Context context, Iterable> input, Collector out) {
long count = 0;
for (Tuple2 in: input) {
count++;
}
out.collect("Window: " + context.window() + "count: " + count);
}
} scala:
val input: DataStream[(String, Long)] = ...
input
.keyBy(_._1)
.window(TumblingEventTimeWindows.of(Time.minutes(5)))
.process(new MyProcessWindowFunction())
/* ... */
class MyProcessWindowFunction extends ProcessWindowFunction[(String, Long), String, String, TimeWindow] {
def process(key: String, context: Context, input: Iterable[(String, Long)], out: Collector[String]) = {
var count = 0L
for (in <- input) {
count = count + 1
}
out.collect(s"Window ${context.window} count: $count")
}
}增量聚合的 ProcessWindowFunction
ProcessWindowFunction可以与ReduceFunction或AggregateFunction搭配使用, 使其能够在数据到达窗口的时候进行增量聚合。当窗口关闭时,ProcessWindowFunction将会得到聚合的结果。 这样它就可以增量聚合窗口的元素并且从 ProcessWindowFunction` 中获得窗口的元数据。你也可以对过时的
WindowFunction使用增量聚合。
ReduceFunction 增量聚合
返回窗口中的最小元素和窗口的开始时间
java:
DataStream input = ...;
input
.keyBy()
.window()
.reduce(new MyReduceFunction(), new MyProcessWindowFunction());
// Function definitions
private static class MyReduceFunction implements ReduceFunction {
public SensorReading reduce(SensorReading r1, SensorReading r2) {
return r1.value() > r2.value() ? r2 : r1;
}
}
private static class MyProcessWindowFunction
extends ProcessWindowFunction, String, TimeWindow> {
public void process(String key,
Context context,
Iterable minReadings,
Collector> out) {
SensorReading min = minReadings.iterator().next();
out.collect(new Tuple2(context.window().getStart(), min));
}
} scala:
val input: DataStream[SensorReading] = ...
input
.keyBy()
.window()
.reduce(
(r1: SensorReading, r2: SensorReading) => { if (r1.value > r2.value) r2 else r1 },
( key: String,
context: ProcessWindowFunction[_, _, _, TimeWindow]#Context,
minReadings: Iterable[SensorReading],
out: Collector[(Long, SensorReading)] ) =>
{
val min = minReadings.iterator.next()
out.collect((context.window.getStart, min))
}
) AggregateFunction 增量聚合
计算平均值并与窗口对应的 key 一同输出
java:
DataStream> input = ...;
input
.keyBy()
.window()
.aggregate(new AverageAggregate(), new MyProcessWindowFunction());
// Function definitions
/**
* The accumulator is used to keep a running sum and a count. The {@code getResult} method
* computes the average.
*/
private static class AverageAggregate
implements AggregateFunction, Tuple2, Double> {
@Override
public Tuple2 createAccumulator() {
return new Tuple2<>(0L, 0L);
}
@Override
public Tuple2 add(Tuple2 value, Tuple2 accumulator) {
return new Tuple2<>(accumulator.f0 + value.f1, accumulator.f1 + 1L);
}
@Override
public Double getResult(Tuple2 accumulator) {
return ((double) accumulator.f0) / accumulator.f1;
}
@Override
public Tuple2 merge(Tuple2 a, Tuple2 b) {
return new Tuple2<>(a.f0 + b.f0, a.f1 + b.f1);
}
}
private static class MyProcessWindowFunction
extends ProcessWindowFunction, String, TimeWindow> {
public void process(String key,
Context context,
Iterable averages,
Collector> out) {
Double average = averages.iterator().next();
out.collect(new Tuple2<>(key, average));
}
} sacla:
val input: DataStream[(String, Long)] = ...
input
.keyBy()
.window()
.aggregate(new AverageAggregate(), new MyProcessWindowFunction())
// Function definitions
/**
* The accumulator is used to keep a running sum and a count. The [getResult] method
* computes the average.
*/
class AverageAggregate extends AggregateFunction[(String, Long), (Long, Long), Double] {
override def createAccumulator() = (0L, 0L)
override def add(value: (String, Long), accumulator: (Long, Long)) =
(accumulator._1 + value._2, accumulator._2 + 1L)
override def getResult(accumulator: (Long, Long)) = accumulator._1 / accumulator._2
override def merge(a: (Long, Long), b: (Long, Long)) =
(a._1 + b._1, a._2 + b._2)
}
class MyProcessWindowFunction extends ProcessWindowFunction[Double, (String, Double), String, TimeWindow] {
def process(key: String, context: Context, averages: Iterable[Double], out: Collector[(String, Double)]) = {
val average = averages.iterator.next()
out.collect((key, average))
}
}