A/B Test 流程、思路、心得
一、基本概念:
1)分流单元(Unit of Diversion)
分流单元是决定用户是否参与实验(分配到对照组或实验组)的基准。常见的分流单元包括:
用户ID(User ID):基于用户的唯一标识进行分流。
Cookie:基于用户的浏览器cookie进行分流。
事件触发(如页面浏览):每次事件发生时重新进行分流。
选择分流单元的依据通常取决于用户一致性、伦理考量以及指标的变化性。【当测试变量是涉及网站ui等,用户可以查觉到的,强调用户的一致性时,用user id, cookie;当测试变量是用户不能觉察到的,用pageview】
2)分析单元(Unit of Analysis)
分析单元是用来计算关键指标(如转化率)的基础单元。例如,如果指标是点击率(CTR),那么分析单元可能是页面浏览(Page View)。通常指指标(metric)的分母。
3)不变量指标(Invariant Metrics)
不变量指标是那些你期望在实验的对照组和实验组之间保持不变的指标。这些指标用于验证实验的有效性,确保实验的基础设置是公平和一致的。
4)评估指标(Evaluation Metrics)
评估指标是用来评价实验效果的指标,它们直接反映了实验变量(即你所测试的变化)的效果。
5)显著性水平(Significance Level):第一类错误α:当原假设为真的时候,我们却拒绝的概率,弃真错误;对于A/B测试,犯这个错误代表新策略没有收益,我们却认为有收益,然后上线的错误
6)统计功效(Statistical Power)【1-β】:第二类错误β:当原假设为假的时候(备择假设为真),我们却接受原假设的概率,取伪错误;直观上理解,AB两组即使有差异,也不一定能被你观测出来,必须保证一定的条件(比如样本要充足)才能使你观测出统计量之间的差异;而统计功效就是当AB两组实际有差异时,能被我们检测出来差异的概率。
7)效应量(Minimum Detectable Effect):你希望检测到的最小重要变化的大小。效应量较大的变化更容易被检测到。
8)样本量:确保有足够的测试参与者来得出有效的结论。样本量太小可能无法检测到重要的效应,而样本量过大则可能导致不必要的资源浪费。一般是由α,β,Minimum Detectable Effect和Baseline conversion rate(p)决定计算的。
9)持续时间和时间段:测试应该持续足够长的时间以收集充分的数据,并考虑季节性和其他外部因素的影响。
10)基本检查或合理性检查(Sanity checks)
在AB测试中是一系列初步检查,旨在确认实验的基础设置是否正确,数据是否合理,以及实验过程是否没有明显的错误。这些检查通常包括验证实验组和对照组的随机分配是否公平,核实关键不变量指标在两组间是否保持一致,以及确认数据的完整性和一致性。Sanity checks是数据分析的重要第一步,确保实验结果的有效性和可靠性。
二、实验设计流程:
1)确定实验策略和策略目标
2)确定Unit of Diversion
3)进行指标选择,包括nvariant Metrics和Evaluation Metrics。确定每个指标的定义和Dmin
4)确定这些指标在策略上线之前的平时表现如何,即baseline values,基线值。这些数据应该是从日常数据中聚合得到的(日均),进行缩放数据(Scaling)。
5)根据上述baseline估计标准差。公式:
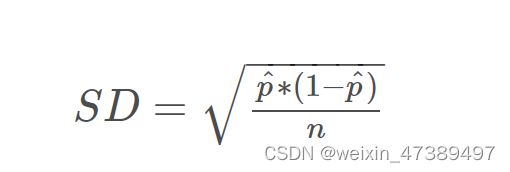
6)确定实验要达到的significant level(α)和Statistical Power(1-β),根据公式:

计算得出所需样本量,如果有多个evaluate metrics,取最大的n。
7)根据之前的每日数据,确定要划分给实验的百分比,从而确定实验周期。
三、得到数据后的分析
1)清洗数据,nan值
2)用不变指标进行Sanity checks,具体公式:

以上是计数变量的公式,p取0.5

以上是概率metrics的差异检验公式。
3)对测试变量的统计显著性检验,公式同2)一样,但需要加一个Dmin的检测,需要确保Dmin在confidence interval外面才是业务显著性。
4)二次检验-符号检验:具体就是把每天实验组和对照组指标大小相减,得出success(指和数据得出结果相反的;例:metric1数据得出实验组比对照组大,success就是metric1实验组比对照组小的个数。

p<0.05,通过检验,反之,不通过。
四、补充内容:
分流单元与分析单元不一致时的影响
相关性增加变异性:当分流单元和分析单元不一致时,分析单元之间的相关性增加。例如,如果分流单元是用户ID,而分析单元是单次页面访问(如点击率),那么同一个用户的多次访问之间可能存在相关性。一些用户可能倾向于更频繁地点击,而其他用户可能更少点击。这种行为模式的重复会导致每次页面访问之间的随机性减少,增加了整体的变异性。
难以使用标准的二项分布估计:在这种情况下,单次事件的结果(如点击与否)不再是简单的二项试验,因为这些事件不是独立的。因此,传统的使用二项分布估计标准差的方法(如sqrt(p(1-p)/n )不再适用。
解决方法
AA测试:通过多组对照组(AA测试)来估计实验的随机性。在多组对照组中,所有组都不应该有任何变化。通过比较这些组的指标,可以估计出在没有实际实验影响时指标的自然波动。
Bootstrap方法:Bootstrap是一种强大的统计工具,用于通过从现有数据样本中重复抽样来估计某个统计量(如均值、中位数、方差)的分布。在分流单元与分析单元不一致的情况下,Bootstrap可以用来估计实验指标的变异性,因为它不依赖于简单的分布假设。
泊松分布的考虑:在某些情况下,实验结果可能更接近泊松分布,尤其是在事件发生次数(如页面点击)被视为计数数据时。泊松分布在处理稀有事件或计数数据时非常有用,但它的参数估计可能比二项分布更复杂。
好的参考:https://www.kaggle.com/code/tammyrotem/ab-tests-with-python/notebook
深入学习AB测试(一)-AB Testing With Python[项目实战] - 知乎