LINUX DDR驱动知识(转)
一、DDR原理
DDR 内存 既然叫做双倍速率SDRAM(Dual date rate SDRSM),就是说是SDRAM的升级换代产品。从技术上分析,DDR SDRAM最重要的改变是在界面数据传输上,其在时钟信号上升缘与下降缘时各传输一次数据,这使得DDR的数据传输速率为传统SDRAM的两倍。那么大家就应该知道了,我们所说的DDR400,DDR333,DDR266,他们的工作频率其实仅为那些数值的一半,也就是说DDR400工作频率为200MHz。
FSB与内存频率的关系
首先请大家看看表一:FSB(Front Side Bus:前端总线)和内存比率与内存实际运行频率的关系。
| FSB/MEM比率 |
实际运行频率 |
| 1/01 |
200MHz |
| 1/02 |
100MHz |
| 2/03 |
133MHz |
| 3/04 |
150MHz |
| 3/05 |
120MHz |
| 5/06 |
166MHz |
| 7/10 |
140MHz |
| 9/10 |
180MHz |
对于大多数玩家来说,FSB和内存同步,即1:1(DFI 用1/01表示)是使性能最佳的选择。而其他的设置都是异步的。同步后,内存的实际运行频率是FSBx2,所以,DDR400的内存和200MHz的FSB正好同步。如果你的FSB为240MHz,则同步后,内存的实际运行频率为240MHz x 2 = 480MHz。

表2更详尽列出了FSB与不同速度的DDR内存之间正确的设置关系
强烈建议采用1:1的FSB与内存同步的设置,这样可以完全发挥内存带宽的优势。
Command Per Clock(CPC)
可选的设置:Auto,Enable(1T),Disable(2T)。
Command Per Clock(CPC:指令比率,也有翻译为: 首命令延迟 ),一般还被描述为DRAM Command Rate、CMD Rate等。由于目前的DDR内存的寻址,先要进行P-Bank的选择(通过DIMM上CS片选信号进行),然后才是L-Bank/行激活与列地址的选择。这个参数的含义就是指在P-Bank选择完之后多少时间可以发出具体的寻址的L-Bank/行激活命令,单位是时钟周期。
显然,也是越短越好。但当随着主板上内存模组的增多,控制芯片组的负载也随之增加,过短的命令间隔可能会影响稳定性。因此当你的内存插得很多而出现不太稳定的时间,才需要将此参数调长。目前的大部分主板都会自动设置这个参数。
该参数的默认值为Disable(2T),如果玩家的内存质量很好,则可以将其设置为Enable(1T)。
CAS Latency Control(tCL)
可选的设置:Auto,1,1.5,2,2.5,3,3.5,4,4.5。
一般我们在查阅内存的时序参数时,如“3-4-4-8”这一类的数字序列,上述数字序列分别对应的参数是“CL-tRCD-tRP-tRAS”。这个3就是第1个参数,即CL参数。
CAS Latency Control(也被描述为tCL、CL、CAS Latency Time、CAS Timing Delay),CAS latency是“ 内存读写操作前列地址控制器的潜伏时间 ”。 CAS控制从接受一个指令到执行指令之间的时间 。因为CAS主要控制十六进制的地址,或者说是内存矩阵中的列地址,所以它是最为重要的参数,在稳定的前提下应该尽可能设低。
内存是根据行和列寻址的,当请求触发后,最初是tRAS(Activeto Precharge Delay),预充电后,内存才真正开始初始化RAS。一旦tRAS激活后,RAS(Row Address Strobe )开始进行需要数据的寻址。首先是行地址,然后初始化tRCD,周期结束,接着通过CAS访问所需数据的精确十六进制地址。期间从CAS开始到CAS结束就是CAS延迟。所以CAS是找到数据的最后一个步骤,也是内存参数中最重要的。
这个参数控制内存接收到一条数据读取指令后要等待多少个时钟周期才实际执行该指令。同时该参数也决定了在一次内存突发传送过程中完成第一部分传送所需要的时钟周期数。这个参数越小,则内存的速度越快。必须注意部分内存不能运行在较低的延迟,可能会丢失数据,因此在提醒大家把CAS延迟设为2或2.5的同时,如果不稳定就只有进一步提高它了。而且提高延迟能使内存运行在更高的频率,所以需要对内存超频时,应该试着提高CAS延迟。
该参数对内存性能的影响最大,在保证系统稳定性的前提下,CAS值越低,则会导致更快的内存读写操作。CL值为2为会获得最佳的性能,而CL值为3可以提高系统的稳定性。注意,WinbondBH-5/6芯片可能无法设为3。
RAS# to CAS# Delay(tRCD)
可选的设置:Auto,0,1,2,3,4,5,6,7。
该值就是“3-4-4-8”内存时序参数中的第2个参数,即第1个4。RAS# to CAS# Delay(也被描述为:tRCD、RAS to CAS Delay、Active to CMD),表示" 行寻址到列寻址延迟时间",数值越小,性能越好。对内存进行读、写或刷新操作时,需要在这两种脉冲信号之间插入延迟时钟周期。在JEDEC规范中,它是排在第二的参数,降低此延时,可以提高系统性能。建议该值设置为3或2,但如果该值设置太低,同样会导致系统不稳定。该值为4时,系统将处于最稳定的状态,而该值为5,则太保守。
如果你的内存的超频性能不佳,则可将此值设为内存的默认值或尝试提高tRCD值。
Min RAS# Active Timing(tRAS)
可选的设置:Auto,00,01,02,03,04,05,06,07,08,09,10,11,12,13,14,15。
该值就是该值就是“3-4-4-8”内存时序参数中的最后一个参数,即8。Min RAS# Active Time (也被描述为:tRAS、Active to Precharge Delay、Row Active Time、Precharge Wait State、Row Active Delay、Row Precharge Delay、RAS Active Time),表示“ 内存行有效至预充电的最短周期 ”,调整这个参数需要结合具体情况而定,一般我们最好设在5-10之间。这个参数要根据实际情况而定,并不是说越大或越小就越好。
如果tRAS的周期太长,系统会因为无谓的等待而降低性能。降低tRAS周期,则会导致已被激活的行地址会更早的进入非激活状态。如果tRAS的周期太短,则可能因缺乏足够的时间而无法完成数据的突发传输,这样会引发丢失数据或损坏数据。该值一般设定为CAS latency + tRCD + 2个时钟周期。如果你的CAS latency的值为2,tRCD的值为3,则最佳的tRAS值应该设置为7个时钟周期。为提高系统性能,应尽可能降低tRAS的值,但如果发生内存错误或系统死机,则应该增大tRAS的值。
如果使用DFI的主板,则tRAS值建议使用00,或者5-10之间的值。
Row Precharge Timing(tRP)
可选的设置:Auto,0,1,2,3,4,5,6,7。
该值就是“3-4-4-8”内存时序参数中的第3个参数,即第2个4。Row Precharge Timing (也被描述为:tRP、RAS Precharge、Precharge to active),表示 " 内存行地址控制器预充电时间 ",预充电参数越小则内存读写速度就越快。
tRP用来设定在另一行能被激活之前,RAS需要的充电时间。tRP参数设置太长会导致所有的行激活延迟过长,设为2可以减少预充电时间,从而更快地激活下一行。然而,想要把tRP设为2对大多数内存都是个很高的要求,可能会造成行激活之前的数据丢失,内存控制器不能顺利地完成读写操作。对于桌面计算机来说,推荐预充电参数的值设定为2个时钟周期,这是最佳的设置。如果比此值低,则会因为每次激活相邻紧接着的bank将需要1个时钟周期,这将影响DDR内存的读写性能,从而降低性能。只有在tRP值为2而出现系统不稳定的情况下,将此值设定为3个时钟周期。
如果使用DFI的主板,则tRP值建议2-5之间的值。值为2将获取最高的性能,该值为4将在超频时获取最佳的稳定性,同样的而该值为5,则太保守。大部分内存都无法使用2的值,需要超频才可以达到该参数。
Row Cycle Time(tRC)
可选的设置:Auto,7-22,步幅值1。
Row Cycle Time(tRC、RC),表示“ SDRAM行周期时间 ”,它是 包括行单元预充电到激活在内的整个过程所需要的最小的时钟周期数 。
其计算公式是:
row cycle time (tRC) = minimum row active time(tRAS) + row precharge time(tRP)。
因此,设置该参数之前,你应该明白你的tRAS值和tRP值是多少。如果tRC的时间过长,会因在完成整个时钟周期后激活新的地址而等待无谓的延时,而降低性能。然后一旦该值设置过小,在被激活的行单元被充分充电之前,新的周期就可以被初始化。
在这种情况下,仍会导致数据丢失和损坏。因此,最好根据tRC = tRAS + tRP进行设置,如果你的内存模块的tRAS值是7个时钟周期,而tRP的值为4个时钟周期,则理想的tRC的值应当设置为11个时钟周期。
Row Refresh Cycle Time(tRFC)
可选的设置:Auto,9-24,步幅值1。
Row Refresh Cycle Time(tRFC、RFC),表示 “ SDRAM行刷新周期时间 ”,它是行单元刷新所需要的时钟周期数。该值也表示向相同的bank中的另一个行单元两次发送刷新指令(即:REF指令)之间的时间间隔。tRFC值越小越好,它比tRC的值要稍高一些。
如果使用DFI的主板,通常tRFC的值不能达到9,而10为最佳设置,17-19是内存超频建议值。建议从17开始依次递减来测试该值。大多数稳定值为tRC加上2-4个时钟周期。
Row to Row Delay(RAS to RAS delay)(tRRD)
可选的设置:Auto, 0-7,每级以1的步幅递增。
Row to Row Delay,也被称为RAS to RAS delay (tRRD),表示" 行单元到行单元的延时 "。该值也表示向相同的bank中的同一个行单元两次发送激活指令(即:REF指令)之间的时间间隔。tRRD值越小越好。
延迟越低,表示下一个bank能更快地被激活,进行读写操作。然而,由于需要一定量的数据,太短的延迟会引起连续数据膨胀。于桌面计算机来说,推荐tRRD值设定为2个时钟周期,这是最佳的设置,此时的数据膨胀可以忽视。如果比此值低,则会因为每次激活相邻紧接着的bank将需要1个时钟周期,这将影响DDR内存的读写性能,从而降低性能。只有在tRRD值为2而出现系统不稳定的情况下,将此值设定为3个时钟周期。
如果使用DFI的主板,则tRRD值为00是最佳性能参数,4超频内存时能达到最高的频率。通常2是最合适的值,00看上去很奇怪,但有人也能稳定运行在00-260MHz。
Write Recovery Time(tWR)
可选的设置:Auto,2,3。
Write Recovery Time (tWD),表示“ 写恢复延时 ”。该值说明在一个激活的bank中完成有效的写操作及预充电前,必须等待多少个时钟周期。这段必须的时钟周期用来确保在预充电发生前,写缓冲中的数据可以被写进内存单元中。同样的,过低的tWD虽然提高了系统性能,但可能导致数据还未被正确写入到内存单元中,就发生了预充电操作,会导致数据的丢失及损坏。
如果你使用的是DDR200和266的内存,建议将tWR值设为2;如果使用DDR333或DDR400,则将tWD值设为3。如果使用DFI的主板,则tWR值建议为2。
Write to Read Delay(tWTR)
可选的设置:Auto,1,2。
Write to Read Delay (tWTR),表示“ 读到写延时 ”。三星公司称其为“TCDLR (last data in to read command)”,即最后的数据进入读指令。它设定向DDR内存模块中的同一个单元中,在最后一次有效的写操作和下一次读操作之间必须等待的时钟周期。
tWTR值为2在高时钟频率的情况下,降低了读性能,但提高了系统稳定性。这种情况下,也使得内存芯片运行于高速度下。换句话说,增加tWTR值,可以让内容模块运行于比其默认速度更快的速度下。如果使用DDR266或DDR333,则将tWTR值设为1;如果使用DDR400,则也可试着将tWTR的值设为1,如果系统不稳定,则改为2。
Refresh Period(tREF)
可选的设置:Auto, 0032-4708,其步进值非固定。
Refresh Period (tREF),表示“ 刷新周期 ”。 它指内存模块的刷新周期 。
先请看不同的参数在相同的内存下所对应的刷新周期(单位:微秒,即:一百万分之一秒)。?号在这里表示该刷新周期尚无对应的准确数据。
1552= 100mhz(?.??s)
2064= 133mhz(?.??s)
2592= 166mhz(?.??s)
3120= 200mhz(?.??s)
---------------------
3632= 100mhz(?.??s)
4128= 133mhz(?.??s)
4672= 166mhz(?.??s)
0064= 200mhz(?.??s)
---------------------
0776= 100mhz(?.??s)
1032= 133mhz(?.??s)
1296= 166mhz(?.??s)
1560= 200mhz(?.??s)
---------------------
1816= 100mhz(?.??s)
2064= 133mhz(?.??s)
2336= 166mhz(?.??s)
0032= 200mhz(?.??s)
---------------------
0388= 100mhz(15.6us)
0516= 133mhz(15.6us)
0648= 166mhz(15.6us)
0780= 200mhz(15.6us)
---------------------
0908= 100mhz(7.8us)
1032= 133mhz(7.8us)
1168= 166mhz(7.8us)
0016= 200mhz(7.8us)
---------------------
1536= 100mhz(3.9us)
2048= 133mhz(3.9us)
2560= 166mhz(3.9us)
3072= 200mhz(3.9us)
---------------------
3684= 100mhz(1.95us)
4196= 133mhz(1.95us)
4708= 166mhz(1.95us)
0128= 200mhz(1.95us)
如果采用Auto选项,主板BIOS将会查询内存上的一个很小的、名为“SPD”(Serial Presence Detect )的芯片。SPD存储了内存条的各种相关工作参数等信息,系统会自动根据SPD中的数据中最保守的设置来确定内存的运行参数。如过要追求最优的性能,则需手动设置刷新周期的参数。一般说来,15.6us适用于基于128兆位内存芯片的内存(即单颗容量为16MB的内存),而7.8us适用于基于256兆位内存芯片的内存(即单颗容量为32MB的内存)。注意,如果tREF刷新周期设置不当,将会导致内存单元丢失其数据。
另外根据其他的资料显示,内存存储每一个bit,都需要定期的刷新来充电。不及时充电会导致数据的丢失。DRAM实际上就是电容器,最小的存储单位是bit。阵列中的每个bit都能被随机地访问。但如果不充电,数据只能保存很短的时间。因此我们必须每隔15.6us就刷新一行。每次刷新时数据就被重写一次。正是这个原因DRAM也被称为非永久性存储器。一般通过同步的RAS-only的刷新方法(行刷新),每行每行的依次刷新。早期的EDO内存每刷新一行耗费15.6us的时间。因此一个2Kb的内存每列的刷新时间为15.6?s x2048行=32ms。
如果使用DFI的主板,tREF和tRAS一样,不是一个精确的数值。通常15.6us和3.9us都能稳定运行,1.95us会降低内存带宽。很多玩家发现,如果内存质量优良,当tREF刷新周期设置为3120=200mhz(?.??s)时,会得到最佳的性能/稳定性比。
Write CAS# Latency(tWCL)
可选的设置:Auto,1-8
Write CAS Latency (tWCL),表示“ 写指令到行地址控制器延时 ”。SDRAM内存是随机访问的,这意味着内存控制器可以把数据写入任意的物理地址,大多数情况下,数据通常写入距离当前列地址最近的页面。tWCL表示写入的延迟,除了DDRII,一般可以设为1T,这个参数和大家熟悉的tCL(CAS-Latency)是相对的,tCL表示读的延迟。
DRAM Bank Interleave
可选的设置:Enable, Disable
DRAM Bank Interleave,表示“ DRAM Bank交错 ”。这个设置用来控制是否启用内存交错式(interleave)模式。Interleave模式允许内存bank改变刷新和访问周期。一个bank在刷新的同时另一个bank可能正在访问。最近的实验表明,由于所有的内存bank的刷新周期都是交叉排列的,这样会产生一种流水线效应。
虽然interleave模式只有在不同bank提出连续的的寻址请求时才会起作用,如果处于同一bank,数据处理时和不开启interleave一样。CPU必须等待第一个数据处理结束和内存bank的刷新,这样才能发送另一个地址。目前所有的内存都支持interleave模式,在可能的情况下我们建议打开此项功能。
对于DFI主板来说,任何情况下该设置都应该是Enable,可以增大内存的带宽。Disable对将减少内存的带宽,但使系统更加稳定。
DQS Skew Control
可选的设置:Auto,Increase Skew,Decrease Skew
DQS Skew Control,表示“ DQS时间差控制 ”。稳定的电压可以使内存达到更高的频率,电压浮动会引起较大的时间差(skew),加强控制力可以减少skew,但相应的DQS(数据控制信号)上升和下降的边缘会出现电压过高或过低。一个额外的问题是高频信号会引起追踪延迟。DDR内存的解决方法是通过简单数据选通脉冲来增加时钟推进。
DDRII引进了更先进的技术:双向的微分I/O缓存器来组成DQS。微分表示用一个简单脉冲信号和一个参考点来测量信号,而并非信号之间相互比较。理论上提升和下降信号应该是完全对成的,但事实并非如此。时钟和数据的失谐就产生了DQ-DQS skew。
如下图所示。

对于DFI主板来说,建议设置为Increase Skew可以提升性能,而Decrease Skew在牺牲一定性能的情况下,可以增加稳定性。
DQS Skew Value
可选的设置:Auto,0-255,步进值为1。
当我们开启了DQS skew control后,该选项用来设定增加或减少的数值。这个参数对系统的影响并不很敏感。 对于DFI主板来说,开启"Increase Skew"选项后,可以将该值设为50-255之间的值。值越大,表示速度越快。
DRAM Drive Strength
可选的设置:Auto,1-8,步进值为1。
DRAM Drive Strength(也被称为:driving strength),表示“ DRAM驱动强度 ”。这个参数用来控制内存数据总线的信号强度,数值越高代表信号强度越高,增加信号强度可以提高超频的稳定性。但是并非信号强度高就一定好,三星的TCCD内存芯片在低强度信号下性能更佳。
如果设为Auto,系统通常会设定为一个较低的值。对使用TCCD的芯片而言,表现会好一些。但是其他的内存芯片就并非如此了,根据在DFI NF4主板上调试和测试的结果,1、3、5 、7都是性能较弱的参数,其中1是最弱的。2、4、6、8是正常的设置,8提供了最强的信号强度。TCCD建议参数为3、5或7,其他芯片的内存建议设为6或8。
DFI用户建议设置:TCCD建议参数为3、5、7,其他芯片的内存建议设为6或8。
DRAM Data Drive Strength
可选的设置:Auto,1-4,步进值为1。
DRAM Data Drive Strength表示“ DRAM数据驱动强 度”。这个参数决定内存数据总线的信号强度,数值越高代表信号强度越高。它主要用于处理高负荷的内存读取时,增加DRAM的驾驭能力。因此,如果你的系统内存的读取负荷很高,则应将该值设置为高(Hi/High)。它有助于对内存数据总线超频。但如果你并没有超频,提升内存数据线的信号强度,可以提高超频后速度的稳定性。此外,提升内存数据总线的信号强度并不能增强SDRAM DIMM的性能。因此,除非你内存有很高的读取负荷或试图超频DIMM,建议设置DRAM Data Drive Strength的值为低(Lo/Low)。
要处理大负荷的数据流时,需要提高内存的驾驭能力,你可以设为Hi或者High。超频时,调高此项参数可以提高稳定性。此外,这个参数对内存性能几乎没什么影响。所以,除非超频,一般用户建议设为Lo/Low。
DFI用户建议设置:普通用户建议使用level 1或3,如果开启了CPC,可能任何高于1的参数都会不稳定。部分用户开启CPC后能运行在3。更多的人关闭CPC后2-4都能够稳定运行。当然最理想的参数是开启CPC后设为level4。
Strength Max Async Latency
可选的设置:Auto,0-15,步进值为1。
Strength Max Async Latency目前还没能找到任何关于此项参数的说明,不知道其功能。感觉网友的经验,在进行Everest的LatencyTest时,可以看出一些差别。在我的BH-6上,参数从8ns到7ns在Latency Test的测试结果中有1ns的区别。从7ns调低6ns后,测试结果又减少了2ns。
DFI主板建议设置:BIOS中的默认值为7ns,建议大家在5-10之间调节。6ns对内存的要求就比较高了,建议使用BH-5和UTT芯片的用户可以尝试一下,但对TCCD不适用。7ns的要求低一些,UTT和BH-5设为7n比较适合超频。8ns对UTT和BH-5就是小菜一碟,8ns时TCCD通常能稳定运行在DDR600,如果想超频到DDR640就必须设为9ns甚至更高了。
Read Preamble Time
可选的设置:Auto,2.0-9.5,步进值为0.5。
Read Preamble Time这个参数表示DQS(数据控制信号)返回后,DQS又被开启时的时间间隔。Samsung早期的显存资料显示,这个参数是用以提升性能的。DQS信号是双向的,无论从图形控制器到DDR SGRAM还是从DDR SGRAM到图形控制器都起作用。
DFI主板建议设置:BIOS中的该值设置为Auto时,实际上此时执行的是默认值5.0。建议大家在4.0-7.0之间调节,该值越小越好。
Idle Cycle Limit
可选的设置:Auto,0-256,无固定步进值。
Idle Cycle Limit这个参数表示“ 空闲周期限制” 。这个参数指定强制关闭一个也打开的内存页面之前的memclock数值,也就是读取一个内存页面之前,强制对该页面进行重充电操作所允许的最大时间。
DFI主板建议设置:BIOS中的该值设置为Auto时,实际上此时执行的是默认值256。质量好的内存可以尝试16-32,华邦(WINBOND)BH-5颗粒的产品能稳定运行在16。Idle Cycle Limit值越低越好。
Dynamic Counter
可选的设置:Auto, Enable, Disable。
Dynamic Counter这个参数表示“ 动态计数器 ”。这个参数指定开启还是关闭动态空闲周期计数器。如果选择开启(Enable),则会每次进入内存页表(Page Table)就强制根据页面冲突和页面错误(conflict/page miss:PC/PM)之间通信量的比率而动态调整Idle Cycle Limit的值。这个参数和前一个Idle Cycle Limit是密切相关的,启用后会屏蔽掉当前的Idle Cycle Limit,并且根据冲突的发生来动态调节。
DFI主板建议设置:BIOS中的该值设置为Auto和关闭和一样的。打开该设置可能会提升性能,而关闭该设置,可以使系统的更稳定。
R/W Queue Bypass
可选的设置:Auto,2x,4x,8x,16x。
R/W Queue Bypass表示“ 读/写队列忽略 ”。这个参数指定在优化器被重写及DCI (设备控制接口:Device Control Interface)最后一次的操作被选定前,忽略操作DCI的读/写队列的时间。这个参数和前一个Idle Cycle Limit是相类似,只是优化器影响内存中的读/写队列。
DFI主板建议设置:BIOS中的该值默认为16x。如果你的系统稳定,则保留该值。但如果不稳定,或者要超频,就只有降低到8x甚至更低的4x或2x。该值越大,则说明系统性能越强,该值越小,则会是系统越稳定。
Bypass Max
可选的设置:Auto, 0x-7x, 步进值为1。
Bypass Max表示“ 最大忽略时间 ”。这个参数表示优化器选择否决之前,最后进入DCQ(Dependence Chain Queue)的可以被优化器忽略的时间。仔细研究后,我觉得这个参数会影响内存到CPU内存控制器的连接。
DFI主板建议设置:BIOS中的该值默认为7x。建议4x或7x,两者都提供了很好的性能及稳定性。如果你的系统稳定,则保留该值。但如果不稳定,或者要超频,就只有降低到8x甚至更低的4x或2x。该值越大,则说明系统性能越强,该值越小,则会是系统越稳定。
32 Byte Granulation
可选的设置:Auto,Disable (8burst),Enable(4burst)。
32 Byte Granulation表示" 32位颗粒化 "。当该参数设置为关闭(Disable)时,就可以选择突发计数器,并在32位的数据存取的情况下,最优化数据总线带宽。因此该参数关闭后可以达到最佳性能的目的。
DFI主板建议设置:绝大多数情况下,建议选择Disable(8burst)选项。开启Enable (4burst)可以使系统更稳定一些。
第三部分 超强的内存芯片
上述参数的设置不可能适用于每位用户。不同的内存芯片的电压、参数都不同,所以超频能力也不一样。下面给出超频能力很强的一些内存芯片,建议大家在选购时多加以留意。
·Winbond(华邦)系列颗粒::BH-5、CH-5、BH-6、CH-6 、UTT;
·Hynix(现代)系列颗粒:D43、D5;
·Micron(镁光)系列颗粒:-5B C、-5B G;
·Infineon(英飞凌)系列颗粒:B5、BT-6、BT-5、CE-5、BE-5;
·Samsung(三星)系列颗粒:TCB3、TCCC、TCC4、TCC5、TCCD。
二:DDR操作
1 相关原理
DDR3内部相当于存储表格,和表格的检索相似,需要先指定
行地址(row),再指定列地址(column),这样就可以准确的找到需要的单元格。对于DDR3内存,单元格称为基本存储单元(也就是每次能从该DDR3芯片读取的最小数据),存储表格称为逻辑bank(DDR3内存芯片都是8个bank,也就是说有8个这样的存储表格)
所以寻址的流程是先指定bank地址,再指定行地址(row),最后指列地址(column)来确定基本存储单元,每个基本存储单元的大小等于该DDR3芯片的数据线位宽,也就是每次能从单个DDR3芯片读取的最小数据长度
2 地址线和内存容量分析
由上文可知要寻址DDR3芯片的基本存储单元需要指定3个地址:
bank地址,行地址(row),列地址(column)
下面以三星MT41J1G4,MT41J512M8,MT41J256M16进行分析
MT41J1G4 – 128 Meg x 4 x 8 banks
MT41J512M8 – 64 Meg x 8 x 8 banks
MT41J256M16 – 32 Meg x 16 x 8 banks
三个型号的容量都是一样,仅仅只是数据线位宽不一样,从上述扩展命名可以分析DDR3芯片的地址线数量,数据线位宽,整体容量
比如:
MT41J256M16 - 32 Meg x 16 x 8 banks
单个DDR3芯片内部有8个banks因此有3根bank地址线BA0,BA1,BA2
每个bank大小是32M*16 bit = 64MB
有16根数据线即基本存储单元是16bit
每个bank有32M个基本存储单元,总共有32M*8=256M个地址
从datasheet分析有15bit row地址和10bit column地址。但是芯片只提供了15根地址线,不够25根。
其实原因是行地址线RA0-RA14和列地址线CA0-CA9地址线分时共用(反正是先取行地址再取列地址)所以只需要15根地址线就可以
每个bank总共有2^15 * 2^10 = 32M个基本存储单元
然后每个基本单元的大小是16bit所以总大小是32M*16bit*8 = 4Gbit
MT41J512M8 – 64 Meg x 8 x 8 banks
单个DDR3芯片内部有8个banks因此有3根bank地址线BA0,BA1,BA2
每个bank大小是64M*8bit = 64MB
有8根数据线即基本存储单元是8bit
每个bank有64M个基本存储单元,总共有64M*8=512M个地址
从datasheet分析有16bit row地址和10bit column地址。但是芯片只提供了16根地址线,不够26根。
原因也是行地址线RA0-RA15和列地址线CA0-CA9地址线分时共用
所以只需要16根地址线就可以
每个bank总共有2^16* 2^10 = 64M个基本存储单元
然后每个基本单元的大小是8bit所以总大小是64M * 8bit*8 = 4Gbit
MT41J1G4 – 128 Meg x 4 x 8 banks
单个DDR3芯片内部有8个banks
每个bank大小是128M* 4bit = 64MB
有4根数据线即基本存储单元是4bit
每个bank有128M个基本存储单元,总共是128M*8=1G个的地址
从datasheet分析有16bit row地址和11bit column地址
由于行地址线RA0-RA15和列地址线CA0-CA9,CA11地址线分时共用
所以只需要16根地址线就可以
每个bank总共有2^16* 2^11 = 128M个基本存储单元
然后每个基本单元的大小是4bit所以总大小是128M *4bit*8 = 4Gbit
注意DDR3芯片的PAGESIZE = 2^column * 数据线位宽/8
由此可知
MT41J1G4 – 128 Meg x 4 x 8 banks
PAGESIZE = 2^11 * 4/8 = 1KB
MT41J512M8 – 64 Meg x 8 x 8 banks
PAGESIZE = 2^10 * 8/8 = 1KB
MT41J256M16 – 32 Meg x 16 x 8 banks
PAGESIZE = 2^10 * 16/8 = 2KB
3 DDR3控制器16bit/32bit概念
这儿所说的16bit/32bit指的是整个内存控制器以多长为单位进行存储,而不是单个DDR3芯片的基本存储单元
32bit表示内存控制器以32bit为单位访问内存,即给定一个内存地址。内存芯片会给内存控制器 32bit的数据到数据线上,当然该32bit数据可能不来自同一个DDR3芯片上,16bit与此类似
下面分析用两个16bit的DDR3内存如何拼成32bit的DDR3
第一片16bit DDR3的BA0,BA1,BA2连接CPU的BA0, BA1, BA2
第二片16bit DDR3 的BA0,BA1,BA2连接CPU 的BA0, BA1, BA2
第一片16bit DDR3的A0~A13连接CPU的A0~A13
第二片16bit DDR3的A0~A13连接CPU的A0~A13
第一片16bit DDR3的D0~D15连接CPU的D0~D15
第二片16bit DDR3的D0~D15连接CPU的D16~D31
分析下该实例。
bank地址线是3bit所以单个16bit DDR3内部有8个bank.
行地址(row)A0~A13共14bit说明每个bank有2^14行
列地址(column)A0~A9共10bit说明每个bank有2^10列
每个bank大小是2^14 * 2^10 * 16 = 16M * 16bit = 32MB
每个bank有16M个基本存储单元,总共有16M*8=128M个地址
单个芯片总大小是 32MB * 8 = 256MB
从前面的连线可知两块16bit DDR3的BA0~BA2和D0~D14是并行连接到内存控制器,所以内存控制器认为只有一块内存,访问的时候按照BA0~BA2和A0~A13给出地址。两块16bit DDR3都收到了该地址,给出的反应是要么将给定地址上的2个字节读到数据线上,要么是将数据线上的两个字节写入到指定的地址。
此时内存控制认为自己成功的访问的了一块32bit的内存,
所以内存控制器每给出一个地址,将访问4个字节的数据,读取/写入。这4字节数据对应到内存控制器的D0~D31,又分别被连接到两片DDR3芯片的D0~D15,这样32bit就被拆成了两个16bit分别去访问单个DDR3芯片的基本存储单元。
注意:尽管DDR3芯片识别的地址只有128M个,但由于内存控制器每访问一个内存地址,将访问4个字节数据,所以对于内存控制器来说,能访问的内存大小仍是512M,只不过在内存控制器将地址传给DDR3芯片时,低两位被忽略,也就是说DDR3芯片识别的地址只有128M个。
比如内存控制器访问地址0x00000000,0x00000001,0x00000002,0x00000003,但对DDR3来说,都是访问地址0x00000000。
4 内存映射的概念
上文中的内存寻址主要讲的是内存控制器如何去访问DDR3芯片基本存储单元
本文中的内存映射主要讲的是如何将内存控制器管理的DDR3芯片地址空间映射到SOC芯片为DDR3预留的地址范围。比如基于ARM的SOC芯片,DDR3的预留地址一般都是0x80000000,如果没有使用内存映射,SOC去访问0x80000000地址时会造成整个系统崩溃,因为访问的地址并不存在实际的内存
DDR3控制器有两种映射模式:非交织映射和交织映射(interlave).
交织映射,即双通道内存技术,当访问在控制器A上进行时,控制器B为下一次访问做准备,数据访问在两个控制器上交替进行,从而提高DDR吞吐率。支持128byte,256byte,512byte的交织模式。如果要使用交织模式,要保证有两个内存控制器以及两个内存控制器有对称的物理内存(即两块内存大小一致;在各自的控制器上的地址映射一致)
非交织映射,即两个内存控制器的内存映射在各自的映射范围内线性递增。对于只存在1个内存控制器或者只使用1个内存控制器时则只能使用非交织的线性映射模式。
5 内存映射具体介绍
下面以DM385和DM8168来介绍内存映射
DM385有1个DDR控制器EMIF0支持JEDEC标准的DDR2,DDR3芯片.
当然DM385只能使用非交织映射模式
数据总线支持16bit和32bit.
DM385有4个内存映射寄存器,所以最多可以映射4段地址空间
DMM_LISA_MAP__0, DMM_LISA_MAP__1,
DMM_LISA_MAP__2, DMM_LISA_MAP__3
下图是该寄存器的具体介绍

SYS_ADDR: 映射到SOC系统上的物理地址,
比如需要映射到0x8000000则SYS_ADDR = 80
SYS_SIZE: 映射的内存大小,讲的是主要给系统映射了多大的内存
SDRC_INTL: 是否使用交织模式,以及使用何种交织模式映射
SDRC_MAP: 交织映射则为3,否则为1或者2
SDRC_ADDR:内存控制器的高位地址即没有映射前他的内存地址
一般都是从0x00000000开始
下面是我们DM385板卡的内存映射
#define DDR3_DMM_LISA_MAP__0 0x00
#define DDR3_DMM_LISA_MAP__1 0x00
#define DDR3_DMM_LISA_MAP__3 0x80400100
#define DDR3_DMM_LISA_MAP__4 0xB0400110
使用了两个映射寄存器,所以主要映射了两段地址空间

从上图可以看出来
第一段映射是将EMIF0的0x00000000映射到SOC系统地址0x8000000上,映射长度为256MB
第二段映射是将EMIF0的0x10000000映射到SOC系统地址0xB000000上,映射长度为256MB
下图是访问模式,线性访问物理地址

由于DM385只有一个内存控制器EMIF0所以只能非交织映射
当然对于上述映射方式可以变为如下映射
#define DDR3_DMM_LISA_MAP__0 0x00
#define DDR3_DMM_LISA_MAP__1 0x00
#define DDR3_DMM_LISA_MAP__3 0x00
#define DDR3_DMM_LISA_MAP__4 0x80500100
将EMIF0的0x00000000映射到SOC系统地址0x80000000,映射长度是512MB
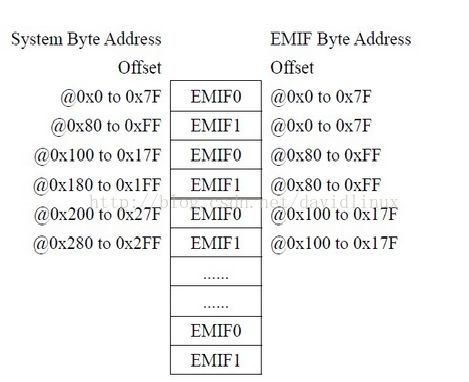
6 DM8168内存映射
2个DDR控制器EMIF0和EMIF1,支持JEDEC标准的DDR2,DDR3芯片
DM8168支持非交织模式映射和交织模式映射
数据总线支持16bit和32bit.
DM8168有4个内存映射寄存器,所以最多可以映射4段地址空间
下面是我们DM8168板卡的内存映射
#define DDR3_DMM_LISA_MAP__0 0x00
#define DDR3_DMM_LISA_MAP__1 0x00
#define DDR3_DMM_LISA_MAP__3 0x80640300
#define DDR3_DMM_LISA_MAP__4 0xC0640320
使用了两个映射寄存器,所以主要映射了两段地址空间

从上图可知
第一段映射是将EMIF0和EMIF1的0x0000000交织映射到SOC系统的0x80000000,对于系统来说了总共映射了1GB的大小,从EMIF0映射了512MB,EMIF1映射了512MB
第二段映射是将EMIF0和EMIF1的0x2000000交织映射到SOC系统的0xC0000000,对于系统来说了总共映射了1GB的大小,从EMIF0映射了512MB,EMIF1映射了512MB
下图是访问模式,交织访问物理地址,128字节交替映射,在交织访问模式下,系统送出的物理地址在两个内存控制器上交替访问
当然也可以使用如下非交织映射
#define DDR3_DMM_LISA_MAP__0 0x00
#define DDR3_DMM_LISA_MAP__1 0x00
#define DDR3_DMM_LISA_MAP__3 0x80600100
#define DDR3_DMM_LISA_MAP__4 0xC0600200
将EMIF0的0x00000000映射到SOC系统地址0x80000000,映射长度是1GB
将EMIF1的0x00000000映射到SOC系统地址0xC0000000,映射长度是1GB
使用下图的线性访问模式

7 DDR3引脚描述
4bit和8bit位宽芯片一般采用78球FBGA封装
16bit位宽芯片一般采用96球FBGA封装
下列信号方向都是针对DDR3芯片来说的
A0-A9,A10/AP,A11,A12/BC#,A13,A14 input
地址输入信号,行地址线和列地址线分时使用
A10/AP 表示PRECHARGE命令期间对某个bank预充电auto-precharge
A10为低则有BA[0,2]来决定哪个bank进行auto-precharge,A10为高电平表示对所有bank进行auto-precharge
BA0,BA1,BA2 input
bank地址输入信号,三个bank地址线表明该DDR3内部有8个bank
LOAD MODE命令期间定义DDR3芯片使用哪个模式(MR0,MR1,MR2)
CK,CK# input
差分时钟输入,所有控制和地址输入信号在CK上升沿和CK#的下降沿交叉处被采样,输出数据选通(DQS,DQS#)参考CK和CK#的交叉点
CKE input
时钟使能信号,高电平有效,CKE为低电平时提供PRECHARGE POWN-DOWN和SELF REFRESH操作(对所有bank里行有效)
CS# input
片选使能信号当CS#为高的时候,所有的命令被屏蔽,CS#提供了多RANK系统的RANK选择功能,CS#是命令代码的一部分
DM(mask) input
数据输入屏蔽,每8bit数据对应一个DM信号,在写期间,当伴随输入数据的DM信号被采样为高的时候,这8bit的输入数据视为无效。
DM信号相当于就是掩码控制位,该信号在读操作时没有用:比如在读32bit数据,但只需要8bit数据,在软件里将高24bit置0就行,有没有DM信号都关系不大,但执行写操作时,如果没有DM信号,可能程序只需要写8bit数据,但是物理连接是32bit到DDR3,只要WR信号有效,32bit数据就全部写到DDR3里边去了,高24bit数据就被覆盖了,有了DM信号它对应的8bit数据就会被忽略,这样就不会覆盖其他数据了
对于4bit位宽DDR3,两个芯片共用一个DM信号,对于8bit位宽DDR3芯片一个芯片占用一个DM信号,对于16bit位宽DDR3芯片则需要2个DM信号
虽然DM仅作为输入脚,但是,DM负载被设计成与DQ和DQS脚负载相匹配。DM的参考是VREFCA。DM可选作为TDQS
ODT input
片上终端使能。ODT使能(高)和禁止(低)片内终端电阻。在正常操作使能的时候,ODT仅对下面的管脚有效:DQ[15:0],DQS,DQS#和DM。如果通过LOAD MODE命令禁止,ODT输入被忽略
RAS#,CAS#,WE# input
命令输入,这三个信号,连同CS#用来定义一个命令
RESET# input
复位,低有效,参考是VSS
DQ0-DQ7/ DQ0-DQ15 I/O
数据输入/输出。双向数据
DQS,DQS# I/O
数据选通。读时是输出,边缘与读出的数据对齐。写时是输入,中心与写数据对齐。
DQS是DDR中的重要功能,它的功能主要用来在一个时钟周期内准确的区分出每个传输周期,并便于接收方准确接收数据。每8bit数据都有一个DQS信号线,它是双向的,在写入时它用来传送由内存控制器发来的DQS信号,读取时,则由芯片生成DQS向内存控制器发送。完全可以说,它就是数据的同步信号。
在读取时,DQS与数据信号同时生成(也是在CK与CK#的交叉点)。而DDR内存中的CL也就是从CAS发出到DQS生成的间隔,DQS生成时,芯片内部的预取已经完毕了,由于预取的原因,实际的数据传出可能会提前于DQS发生(数据提前于DQS传出)。
DQS在读取时与数据同步传输
而在接收方,一切必须保证同步接收,不能有偏差。这样在写入时,芯片不再自己生成DQS,而以发送方传来的DQS为基准,并相应延后一定的时间,在DQS的中部为数据周期的选取分割点(在读取时分割点就是上下沿),从这里分隔开两个传输周期。这样做的好处是,由于各数据信号都会有一个逻辑电平保持周期,即使发送时不同步,在DQS上下沿时都处于保持周期中,此时数据接收触发的准确性无疑是最高的。
TDQS,TDQS# output
终端数据选通。当TDQS使能时,DM禁止,TDQS和TDDS提供终端电阻。
VDD
电源电压,1.5V+/-0.075V
VDDQ
DQ电源,1.5V+/-0.075V。为了降低噪声,在芯片上进行了隔离
VREFCA
数据的参考电压。VREFDQ在所有时刻(除了自刷新)都必须保持规定的电压
VSS
地
VSSQ
DQ地,为了降低噪声,在芯片上进行了隔离
ZQ
输出驱动校准的外部参考。这个脚应该连接240ohm电阻到VSSQ