Cache Lab:Part B【分块算法】
任务描述
要求在trans.c中编写一个转置函数,从而导致尽可能少的miss。缓存的参数是 (s = 5, E = 1, b = 5)。三种测试用例的矩阵大小分别为:
• 32 × 32 (M = 32, N = 32)
• 64 × 64 (M = 64, N = 64)
• 61 × 67 (M = 61, N = 67)
规定:仅使用12个局部变量,不能使用递归,不能修改A数组(可任意修改B数组),不允许使用malloc。
提示:你的代码只需要针对这三种情况是正确的,并且你可以针对这三种情况进行专门优化。特别是,你的函数完全可以显式检查输入大小并实现针对每种情况优化的单独代码。
分析
对三种测试用例分别进行设计。
下图是32*32数组的分块情况,每一个小格代表一个block(由前提条件b=5,得出一个块是32字节,由于是int数组,所以一个block能存8个元素)

上面是16个大块。
转置时依次扫描大块1~16,将块内元素转置后放在数组B对应的位置。可以发现,除了对角块,其余都是没有冲突未命中的。
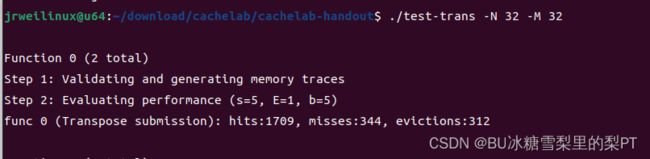
32 × 32 (M = 32, N = 32)
baseline:上述简单分块法
现象:m=344,而满分是m<300
修改思路:对角线的优化
int i, j, k, q, tmp;
if (M == 32 && N == 32)
{
for (k = 0; k < 4; k++)
{
for (q = 0; q < 4; q++)
{
for (i = 0; i < 8; i++)
{
for (j = 0; j < 8; j++)
{
tmp = A[k * 8 + i][q * 8 + j];
B[q * 8 + j][k * 8 + i] = tmp;
}
}
}
}
}
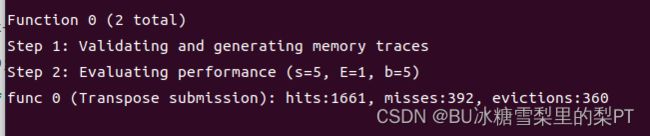
尝试优化1:给对角线上的块再次细分块
现象:更差 (m=392)
int i, j, k, q, i2, j2, k2, q2, tmp;
if (M == 32 && N == 32)
{
for (k = 0; k < 4; k++)
{
for (q = 0; q < 4; q++)
{
if (k == q)
{
for (k2 = 0; k2 < 2; k2++)
{
for (q2 = 0; q2 < 2; q2++)
{
for (i2 = 0; i2 < 4; i2++)
{
for (j2 = 0; j2 < 4; j2++)
{
tmp = A[k * 8 + k2 * 4 + i2][q * 8 + q2 * 4 + j2];
B[q * 8 + q2 * 4 + j2][k * 8 + k2 * 4 + i2] = tmp;
}
}
}
}
}
else
{
for (i = 0; i < 8; i++)
{
for (j = 0; j < 8; j++)
{
tmp = A[k * 8 + i][q * 8 + j];
B[q * 8 + j][k * 8 + i] = tmp;
}
}
}
}
}
}
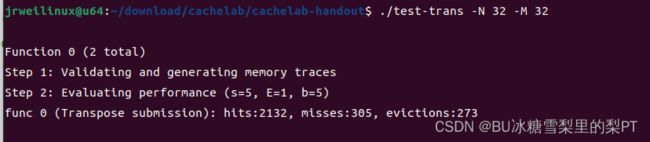
尝试优化2:对角块依次错位
具体来说,转置完的1号大块存在6号大块,6号存在11号,11号存在16号。16号进行普通转置。
现象:变好,m=305(满分300,你在卡我:(
int i, j, k, q, tmp;
if (M == 32 && N == 32)
{
for (k = 0; k < 4; k++)
{
for (q = 0; q < 4; q++)
{
if (k == q && k != 3)
{
for (i = 0; i < 8; i++)
{
for (j = 0; j < 8; j++)
{
tmp = A[k * 8 + i][q * 8 + j];
B[q * 8 + 8 + j][k * 8 + 8 + i] = tmp;
}
}
for (i = 0; i < 8; i++)
{
for (j = 0; j < 8; j++)
{
tmp = B[k * 8 + i + 8][q * 8 + j + 8];
B[k * 8 + i][q * 8 + j] = tmp;
}
}
}
else
{
for (i = 0; i < 8; i++)
{
for (j = 0; j < 8; j++)
{
tmp = A[k * 8 + i][q * 8 + j];
B[q * 8 + j][k * 8 + i] = tmp;
}
}
}
}
}
}
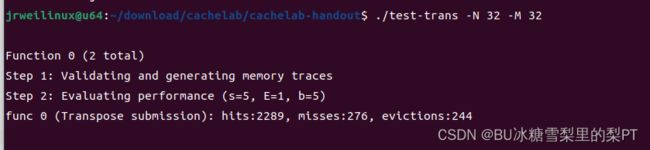
尝试优化3:对角块两两交换
具体来说,A的1号转置完成后存到B的6号,A的6号转置完存到B的1号去。然后,B的1号和6号交换。11号和16号同理。
现象:m=276,成功。
int i, j, k, q, tmp;
if (M == 32 && N == 32)
{
for (k = 0; k < 4; k++)
{
for (q = 0; q < 4; q++)
{
if (k == q && k % 2 == 0)
{
for (i = 0; i < 8; i++)
{
for (j = 0; j < 8; j++)
{
tmp = A[k * 8 + i][q * 8 + j];
B[q * 8 + 8 + j][k * 8 + 8 + i] = tmp;
}
}
}
else if (k == q && k % 2 == 1)
{
for (i = 0; i < 8; i++)
{
for (j = 0; j < 8; j++)
{
tmp = A[k * 8 + i][q * 8 + j];
B[q * 8 - 8 + j][k * 8 - 8 + i] = tmp;
}
}
for (i = 0; i < 8; i++)
{
for (j = 0; j < 8; j++)
{
tmp = B[k * 8 + i][q * 8 + j];
B[k * 8 + i][q * 8 + j] = B[k * 8 - 8 + i][q * 8 - 8 + j];
B[k * 8 - 8 + i][q * 8 - 8 + j] = tmp;
}
}
}
else
{
for (i = 0; i < 8; i++)
{
for (j = 0; j < 8; j++)
{
tmp = A[k * 8 + i][q * 8 + j];
B[q * 8 + j][k * 8 + i] = tmp;
}
}
}
}
}
}
64 × 64 (M = 64, N = 64)
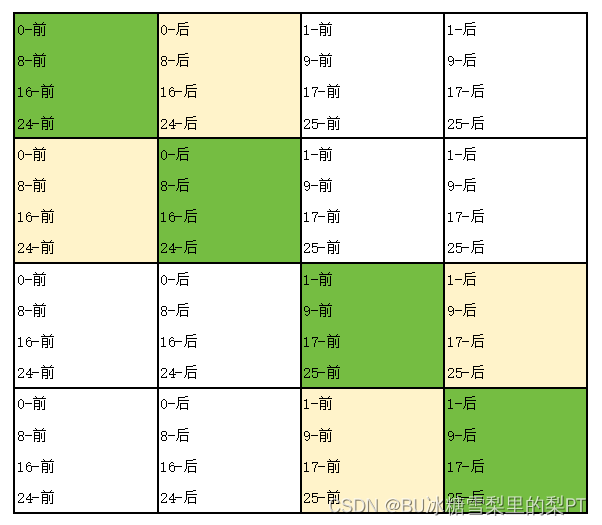
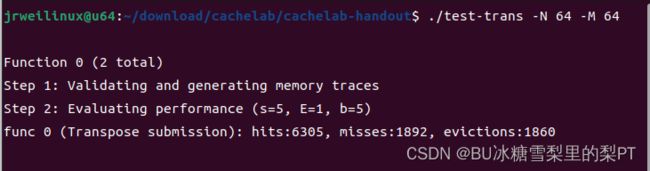
baseline:每块16元素(4*4)
现象:m=1892(满分1300)
尝试优化1:对角线
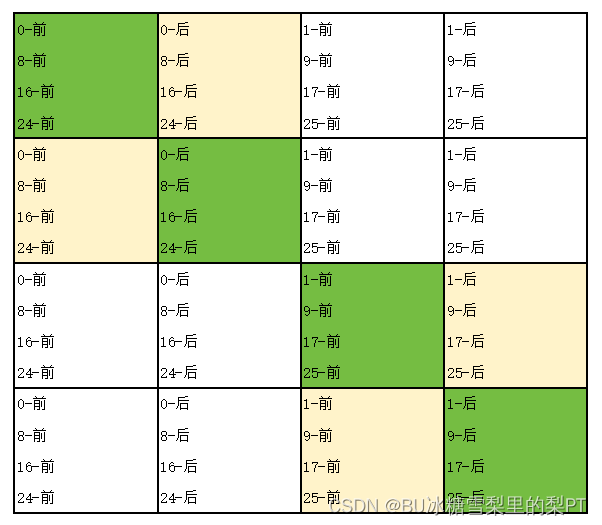
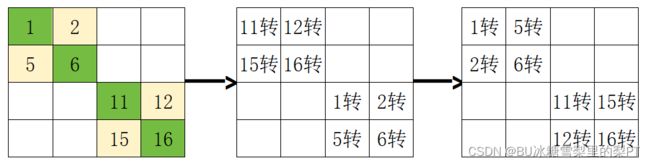
未标号的大块就是按照默认方法来转置。
现象:m=1588
{
if (M == 64 && N == 64)
{
for (k = 0; k < 16; k++)
{
for (q = 0; q < 16; q++)
{
if ((k % 2 == 0 && k == q - 1) || (q % 2 == 0 && q == k - 1))
{
if (k % 4 == 0 || k % 4 == 1)
{//往下存
for (int i = 0; i < 4; i++)
{
for (int j = 0; j < 4; j++)
{
// 注意此处仅ij反,kq不反
tmp = A[k * 4 + i][q * 4 + j];
B[k * 4 + 8 + j][q * 4 + 8 + i] = tmp;
}
}
}
else
{//往上存
for (int i = 0; i < 4; i++)
{
for (int j = 0; j < 4; j++)
{
tmp = A[k * 4 + i][q * 4 + j];
B[k * 4 - 8 + j][q * 4 - 8 + i] = tmp;
}
}
}
}
else
{
for (i = 0; i < 4; i++)
{
for (j = 0; j < 4; j++)
{
tmp = A[k * 4 + i][q * 4 + j];
B[q * 4 + j][k * 4 + i] = tmp;
}
}
}
// 交换
if (k == q && k % 4 == 3)
{
for (i = 0; i < 4; i++)
{
for (j = 0; j < 4; j++)
{
tmp = B[k * 4 + i][q * 4 - 4 + j];
B[k * 4 + i][q * 4 - 4 + j] = B[k * 4 - 12 + i][q * 4 - 8 + j];
B[k * 4 - 12 + i][q * 4 - 8 + j] = tmp;
}
}
for (i = 0; i < 4; i++)
{
for (j = 0; j < 4; j++)
{
tmp = B[k * 4 - 4 + i][q * 4 + j];
B[k * 4 - 4 + i][q * 4 + j] = B[k * 4 - 8 + i][q * 4 - 12 + j];
B[k * 4 - 8 + i][q * 4 - 12 + j] = tmp;
}
}
}
}
}
}