异步编程,到底有什么用?
关键词:高性能、架构设计、异步思想、场景落地
文章导读

场景切入
先来看一个日常生活快递寄件场景,从寄件人(寄件)到收件人(收件),全流程如下
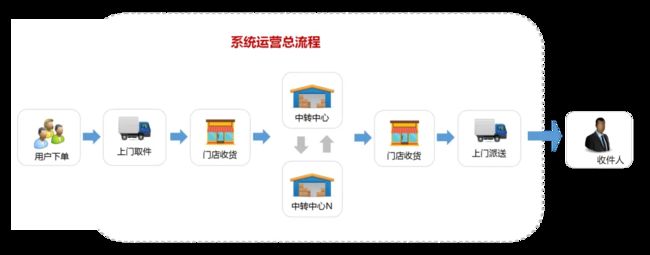
当你准备寄送一个包裹时,通常你可以有两种寄件方式:
方案一、你亲自前往快递服务点,填写寄件单、交付包裹、等待工作人员处理,最后得到一张寄送单据。你必须在服务点等待直到所有步骤都完成。这个过程是同步的。
方案二、你可以选择在线预约快递上门取件服务,填写相关信息后,你的请求就被提交给系统。此时,你可以继续进行其他事情,而不需要等待快递员到达。系统会在后台异步处理你的请求,安排合适的快递员前来取件。这样,你就可以在等待的过程中做其他事情,无需阻塞在快递服务点。
这种寄件方式提高了效率,让用户可以更加灵活地安排自己的时间。在后台系统中,快递公司可以通过合理的任务调度,处理多个异步请求,提高寄件服务的整体吞吐量。这种方式类似于在后端异步处理任务,而用户无需等待任务完成,可以继续进行其他操作,提高了整个寄件过程的并发性和响应性。这个过程就是异步。
同步和异步
我们通过这个例子抽象出同步模型和异步模型:
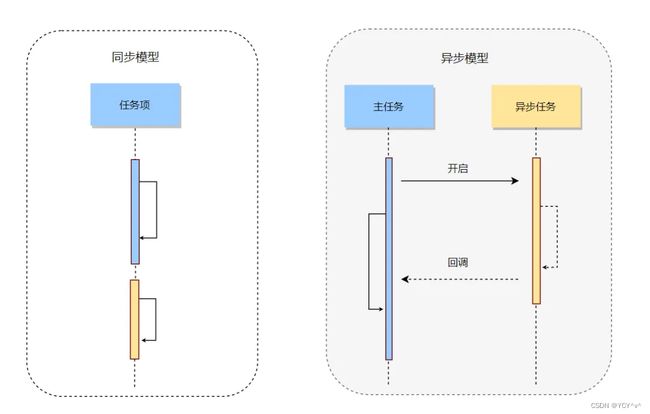
小结
同步模型:一个任务做完做下一个任务,阻塞
异步模型:做当前任务,只需要开启而不需要关心另一个任务如何执行,非阻塞
设计理念
有了上边的模型,对于同步和异步的概念就有了初步的认识。事实上,在架构设计中,异步思想是指通过异步处理来提高系统的性能、可伸缩性和响应速度。
以下是SpringColud微服务架构的基本套件:
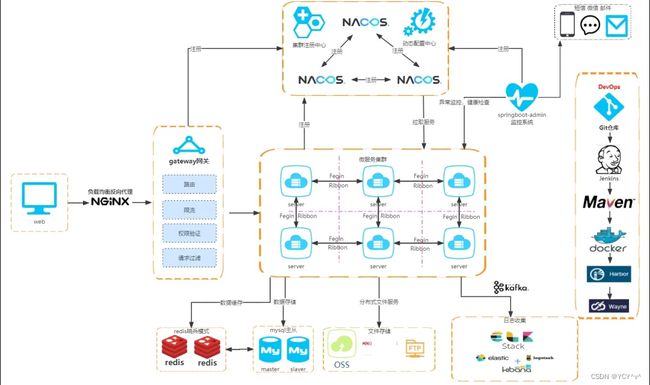
在架构设计中,异步思想可以应用在多个方面。常见的异步实践包括:
-
消息队列:通过消息队列实现异步通信,将消息发送到队列中,然后由消费者异步地处理这些消息。这种方式可以实现解耦和削峰填谷的效果。
-
事件驱动:系统中的各个组件通过事件进行通信,当事件发生时,系统中的其他组件可以异步地响应这些事件,从而实现松耦合和高内聚。
-
非阻塞I/O:在网络编程中,采用非阻塞I/O可以使系统在等待I/O操作完成的同时继续处理其他任务,提高系统的并发能力和吞吐量。
......
场景应用
接下来,我们针对实际项目中的异步设计逐个探究。可能做不到面面俱到,但是可以为真实的场景中的方案设计打开思路。
场景一、基于异步非阻塞模型的业务网关Spring Cloud Gateway
Spring Cloud Gateway基于Project Reactor反应式编程和WebFlux框架,通过路由、过滤器、事件等机制实现了灵活的网关服务。它适用于构建微服务架构中的业务网关,具有高性能、可扩展性和丰富的功能。
官网地址:https://spring.io/projects/spring-cloud-gateway/
性能比较
对 Zuul/Spring Cloud Gateway 的一些性能分析可以参考 Spring Cloud Gateway 作者 Spencer Gibb 提供的项目:https://github.com/spencergibb/spring-cloud-gateway-bench。

摘自SpringCloud GateWay作者spencergibb 提供的一个压测报告
总的来说,Gateway在处理IO密集型请求场景下有着更大的优势。原因是:随着Spring 5 推出的WebFlux,它是完全异步且非阻塞的,底层也是基于Netty实现的。我们分别对Reactor模型和Netty做一个简单介绍。
基于Reactor的反应式编程:
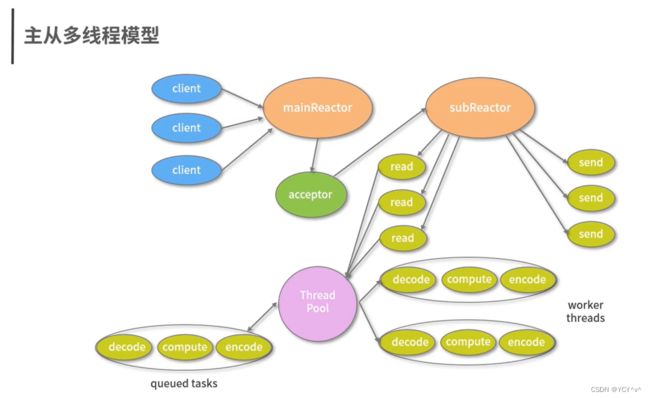
其中:mainReactor主要负责连接处理(不参与数据处理),而subReactor负责数据的读取(不参与连接). 不再是单线程模型那样,接收请求和处理数据都是在一个Reactor下进行。
WebFlux框架:
核心主要是基于NIO的Netty框架,原理说明如下:
组件关系:
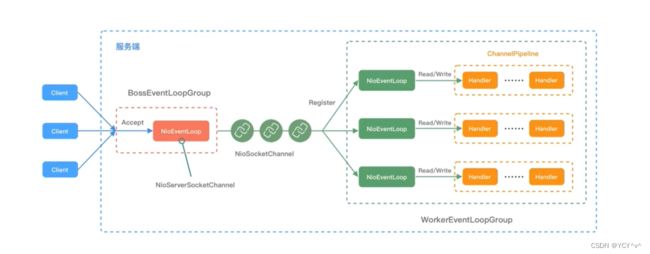
概念说明:
Bootstrap(启动引导类):可用于连接远端服务器,只绑定一个 EventLoopGroup ( Boss) ServerBootStrap 用于服务端启动绑定本地端口,绑定两个 EventLoopGroup (Worker)
channel(通道):是网络通信的载体,提供了基本的API用于网络I/0 操作如register、bind、connect、read、write、flush 等Netty自己实现的 Channel是以JDK NIO Channel为基础的。
Handler(处理器):处理输入输出数据的逻辑组件。它负责实际处理数据的业务逻辑
EventLoop(事件循环):是 Netty 中处理所有事件的线程,负责处理连接的生命周期中发生的各种事件。
Pipeline(管道):包含了一个 Channel 的处理器链。通过 Pipeline 可以将多个处理器按顺序组织起来,形成一个处理流程。
每个服务器中都会有一个 Boss(老板),会有一群做事情的WorkerBoss(员工) 会不停地接收新的连接,将连接分配给一个个 Worker 处理连接
执行过程:
每个服务器中都会有一个 Boss(老板),会有一群做事情的WorkerBoss(员工) 会不停地接收新的连接,将连接分配给一个个 Worker 处理连接
执行过程:
Netty 执行过程:
启动引导(Bootstrap):创建并配置一个新的 Netty 应用。设置线程模型、Channel 类型、处理器等。
创建 EventLoopGroup:创建 EventLoopGroup 对象,它包含一个或多个 EventLoop,用于处理连接的生命周期中发生的各种事件。
配置 Channel:配置 Channel 类型、处理器等,并将 Channel 注册到 EventLoop 中。
创建 ChannelPipeline:每个 Channel 都有一个与之关联的 ChannelPipeline,用于管理和执行所有的 ChannelHandler。
添加 ChannelHandler:将业务逻辑处理器添加到 ChannelPipeline 中,形成处理链。
绑定端口:调用 bind 方法将 Channel 绑定到指定的端口,开始监听客户端的连接。
接收连接:当有客户端连接请求到达时,EventLoop 将会通知 ChannelPipeline 中的第一个 ChannelHandler,从而开始处理连接。
数据读写:当有数据读写事件发生时,ChannelPipeline 中的处理器链将被触发,依次处理数据。
关闭连接:当连接关闭时,Netty 会释放相关的资源,包括关闭连接、关闭 EventLoopGroup 等。
关于SpringCloud GateWay的使用,请自行查阅官网。这里只介绍如何体现NIO异步非阻塞原理的。
场景二、基于消息队列-数据同步
场景分析:
比如:商城首页菜单树。一般这种场景我们允许在一定时间数据不一致性。那么就可以使用定时任务+消息队列。如每隔5分钟同步一次,达到数据最终一致。
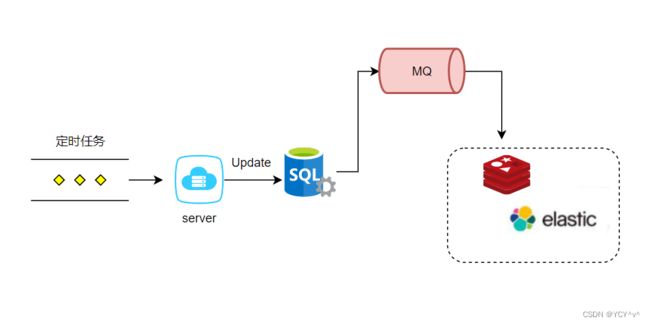
注意事项:
这种数据同步方案主要适用于数据实时性要求不高的场景,因为:定时任务处理存在一定时间间隔,会有同步延时。同时在时间窗口期数据可能发生变更。还有就是数据最终一致性的保证,主要取决于MQ的可靠性。
场景三、基于消息队列-数据交互
场景分析:
三方平台交互,上游系统(A)的数据和下游系统(B)的数据进行接口规范转化。此处可能涉及到很多业务转到同一个平台或者不同平台。而我们接口转化的功能是一致的。当然你可以使用Feign直接调用。但是流量增加、网络阻塞时可能会出现调用失败,导致未能成功送达下游。因此我们可以这样设计:
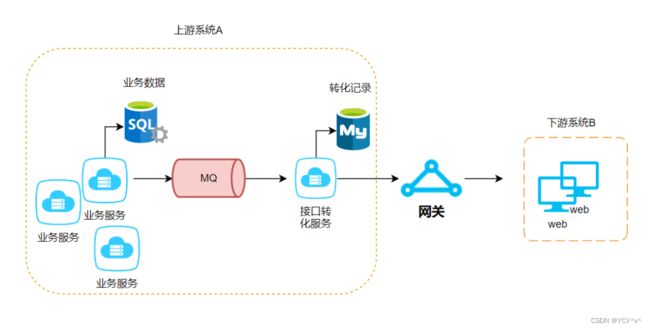
注意事项:
这种异步设计一方面为了系统内部服务之间解耦,另一方面起到了削峰填谷的作用。但是引入消息队列和转化服务,增加了系统的复杂性。因为链路较长,出现问题时排查起来比较困难。因此要在数据库中尽可能存留记录明细,方便审查。另外,也可能出现消息积压等问题。当然这是消息队列存在的共性问题。
场景四、基于消息队列-短信功能
场景分析:日常我们会遇到很多这种发短信的情况。比如:
手机订购流量套餐,发短信提醒生效日期
快递达到指定地点,短信同步收件信息
银行转账成功,提醒交易明细
上班扫码刷地铁,通知扣费情况
会员注册满一年,会在前一个月发短信到期提醒。
......
那么对于短信场景,我们如何设计呢?
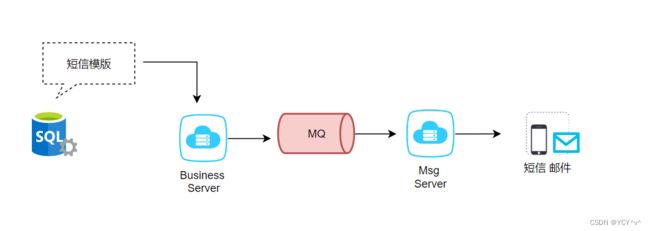
注意事项:这种异步设计一方面为了将发送短信的功能独立出来。
场景五、基于消息队列-日志采集
场景分析:
在业务系统中,一般我们会进行日志采集和可视化展示。ELK 是由 Elasticsearch、Logstash 和 Kibana 组成的一套日志管理和分析解决方案。结合 Kafka 使用时,通常用于搭建一个高效的日志处理系统。
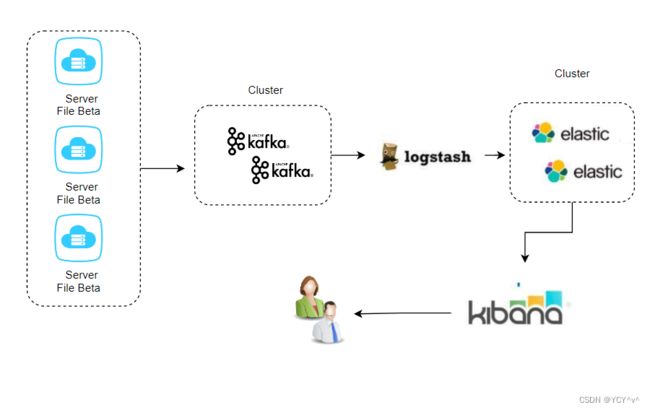
ELK 工作流程并结合 Kafka 的工作流程描述:
-
生产者发送日志到 Kafka:
-
应用程序或系统生成日志,并通过 Kafka 生产者发送日志消息到 Kafka 集群。
-
Kafka 主题(Topic)通常用于组织和分类不同类型的日志数据。
-
-
Logstash 消费 Kafka 中的日志:
-
Logstash 作为 Kafka 消费者,通过 Kafka Input 插件订阅一个或多个 Kafka 主题。
-
Logstash 接收到 Kafka 中的日志消息后,可以进行多种操作,如解析日志、添加字段、过滤、转换格式等。
-
-
Logstash 处理日志并发送到 Elasticsearch:
-
Logstash 通过 Elasticsearch Output 插件将处理后的日志数据发送到 Elasticsearch 集群。
-
Logstash 可以将日志数据根据配置的索引模式(Index Pattern)划分到不同的索引中,以便更好地管理和查询。
-
-
Elasticsearch 存储和索引日志数据:
-
Elasticsearch 接收 Logstash 发送过来的日志数据,并将其存储在分布式索引中。
-
Elasticsearch 提供了强大的全文搜索和分析功能,支持对大量的日志数据进行高效的查询和分析。
-
-
Kibana 可视化和查询:
-
Kibana 作为 Elasticsearch 的前端界面,提供了丰富的可视化工具和查询界面。
-
用户可以使用 Kibana 创建仪表板、图表,执行复杂的查询,实时监控日志数据等。
-
整个工作流程如下:
注意事项:
-
Kafka 作为消息队列中介,实现了解耦,使生产者与消费者之间的依赖性降低。
-
Logstash 提供了灵活的数据处理能力,可以根据具体需求进行配置,包括过滤、解析、字段添加等操作。
-
Elasticsearch 提供了高效的全文搜索和分析功能,以及分布式存储,适用于处理大量的日志数据。
-
Kibana 提供了直观的可视化工具,帮助用户更好地理解和分析日志数据。
整个 ELK + Kafka 的架构可以帮助实现高效的日志收集、处理和可视化,适用于大规模分布式系统中的日志管理。
场景六、基于CompletableFuture 异步多线程批处理任务
当使用多线程和 CompletableFuture 来执行批处理任务时,可以通过将任务分成多个子任务,并使用 CompletableFuture 来异步执行这些子任务。主要思想如下:
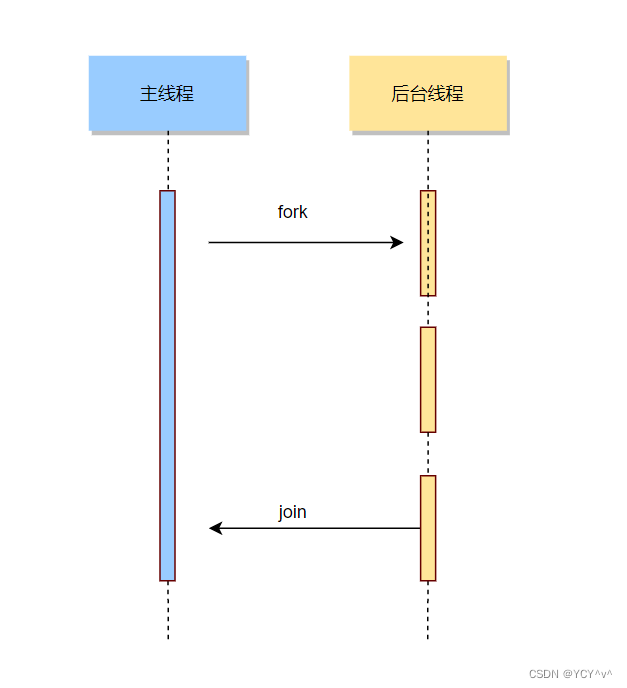
假设我们有一个批处理任务,需要对一组数据进行处理:

以上我们模拟了一组数据,然后将数据分成多个批次,每个批次使用 CompletableFuture 异步执行。CompletableFuture.allOf 用于等待所有子任务完成。
在这个示例中,主要体现了以下异步的思想和操作:
-
CompletableFuture 异步执行: 使用
CompletableFuture.runAsync方法,将任务异步提交给CompletableFuture,该任务会在一个线程池中异步执行。这允许程序继续执行而不必等待子任务完成。

总结
异步设计在处理并发和提高系统性能方面具有优势,但也带来了一些可能的问题。以上提供的场景和方案仅供参考。使用过程中应当根据业务特征合理选择具体方案。
优势:
并发性和响应性: 异步设计可以提高系统的并发性和响应性,允许系统在等待某些操作完成的同时继续执行其他操作,从而更有效地利用资源。
性能提升: 异步操作允许系统并发地执行多个任务,减少了等待时间,提高了系统的性能。尤其在 I/O 密集型任务中,异步操作能够更充分地利用 CPU。
可伸缩性: 异步设计有助于构建可伸缩的系统,能够更好地处理大量并发请求,适应系统负载的变化。
降低资源占用: 异步操作可以减少线程或进程的创建和销毁开销,从而降低系统资源的占用。
可能产生的问题:
数据一致性: 异步操作可能导致数据一致性的问题,特别是在涉及到多个异步任务的场景。需要采取额外的手段,如事务或事件溯源,来保障数据的一致性。
幂等性: 异步操作的重试机制可能引入幂等性问题。如果一个操作不是幂等的,重试可能导致不正确的结果。需要确保异步操作是幂等的,或者采用幂等性保障措施。
消息丢失: 在消息传递的异步系统中,由于网络故障或系统故障,消息可能会丢失。需要实施消息确认、重试和持久化等机制,以防止消息丢失。
异步调用链的复杂性: 复杂的异步调用链可能使代码难以理解和维护,需要谨慎设计和文档化。
文章摘自:https://mp.weixin.qq.com/s/JIbfgF16eiuqFs-P7CBxSw