剪映上线5秒“AI克隆音色”,我体验了一下
昨天,我登录我的剪映,无意中看到一个新功能。
“克隆音色”
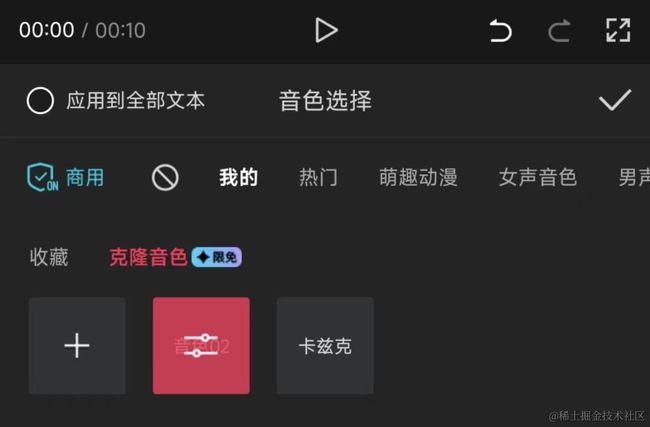
当你添加文本时,在“文本朗读”那个功能中,点击“我的”tab,就能看到这个功能了。
我问了下剪映的朋友,他们说,目前还在小规模测试中,大概只有10%的人能拿到这个功能的体验资格。月底可能会全量上线。
坦率讲,当我看到这个功能的那一刻,其实是心头一慌的。
不是为我自己而慌,毕竟我又不做产品。
我慌的是:AI声音这个赛道的创业者。
不管是过去的移动互联网时代,还是现在的AI时代,都有一个很灵魂拷问的问题是:
“当BAT/OpenAI,来下场干你的业务,你该怎么办”
尤记得去年11月OpenAI在召开开发者大会的时候,发布了一堆东西,直接全工具All in One。
也是在那一天,N多AI初创公司宣布进入死亡倒计时。
附我的GPT网站 http://ai.wydxda.ltd/
现在,当剪映这种巨头下场,把手伸到了AI,那,阁下该如何应对?
回过头来,说一下剪映这个AI音色克隆的使用和效果。
目前只有APP端有,路径就是我上面说的添加文本时,就能在“文本朗读”那个功能中。
不过我实在不习惯用APP,一直都是用的电脑端。就舔着老脸去找剪映的朋友化缘去了。
在过了几个小时之后。

于是,我就打开了我的剪映。
嘿嘿。
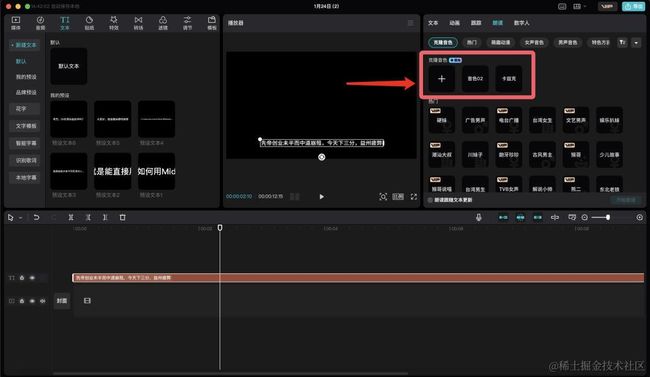
那两个声音,是我之前在手机上已经先克隆好的。
正常克隆声音,只需要点击那个+号。
在弹出的弹窗上,把他们给出的文案用你的声音读一遍,就OK了。

这步操作可能会跟大家想象的不太一样。
剪映的音色克隆,只能克隆自己声音的,而不能像一些现在市面上的开源项目一样,上传一段音频后,就能把那个人的声音克隆出来。
原因其实非常简单,隐私与风险。
你肯定不希望自己的声音漫天飞对吧,剪映的音色克隆对素材的需求量又非常低,5s基本就够了,如果放开的话,那真的随便复制。
出现这种情况,最开心的不是你我他,而是骗子。很容易就是你奶奶你妈妈的声音满天飞,然后跟你说:儿子哎,奶奶想买个LV,给奶奶打个2w块钱助力我一个老年梦好不。
所以剪映的这个方式也挺有意思的,必须是你用录制的方式,念出文本上的随机的话,还不能念错。
用这种方式,来证明你是你。
大概画5到10秒录制完成以后,你的声音就会出现在“我的”tab下面了。
在我体验过的5s数据音色克隆的项目中,目前剪映这个基本是最好的。
毕竟这玩意,看的还是底层声音大模型的质量,这个5s的录音数据,相当于一个小的prompt,来给这个声音大模型做一个提示。而剪映的这个声音大模型,确实有点东西,音色基本一致,在情感、断句上,有一点平,但是问题也不大。
熟悉豆包的朋友估计都能看出来,剪映这个AI音色克隆,跟豆包那个克隆,背后的大模型应该是一摸一样的。
但是豆包的用户体量肯定没法跟剪映比,豆包更像是技术的试验田,实验成熟之后,开始给剪映这种超级产品赋能。
一上来,就是个成熟度极高的王炸。
对于剪映来说,核心目的当然是为创作者提供体验最好的产品,理论上,现在市面上80%的AI工具,都是跟剪映的产品定位完全契合。
现在只是一个AI音色克隆。
那如果类似heygen的5分钟视频生成数字人,AI数字人定制剪映也做进去了呢?
如果D-ID那种照片说话剪映也做进去了呢?
如果AI唱歌剪映也做进去了呢?
如果…
一将功成万骨枯。
工作流的影响是巨大的,迁移成本极高。试问,在效果差不多的情况下,谁还去用别家的音色克隆产品?剪映的生态、粘性、用户体验、产品成熟度实在太恐怖了。
不过他们毕竟体量在这,要照顾大众需求,所以一定不会做的非常专业,那卷专业方向的可能还跟他们暂时碰不到一块,比如出门问问的魔音工坊,在情绪表达和可控性上能碾压剪映,用户群里也是更为专业的配音或自媒体从业者。
但是,AI创业公司,如果也想做AI声音这块的大众需求,那可能就日子不太好过了。
毕竟跟你竞争的,不是同咖位的竞品,而是剪映这样的巨兽。除非避开它的发力方向,或者直接在技术上把剪映拉开代差,那还有得一战。
要不然,就可能像被OpenAI锤懵的一些AI初创公司一样,陷入慢性死亡…