CV大(混合)模型之GLIP代码,原理解析
众所周知,随着NLP类的大模型问世,以chatgpt为代表,后续各大大厂相继出现自己的大模型,如百度的“文心一言”,华为的“盘古”,科大讯飞的“星火”,阿里的“通义千问”,商汤的“日日新”等,同样在CV领域也随之出现一系列包含检测,分割类的大模型,也称之为cv混合模型,在分割中现阶段较经典的有SAM,Faster SAM等。检测方面主要以CLIP,GLIP,DINO,Grounding DINO为代表,原理和方式大同小异,主要采用以Vit Transformer的视觉模型和Bert的语言模型进行组合,交互。接下来我将基于经典的GLIP模型代码,原理进行分解。
GLIP原理解析:
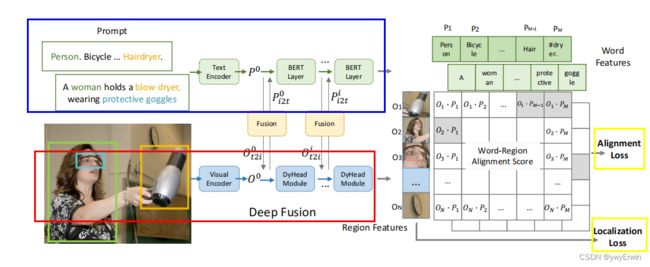
以文献中的流程图示例解析,cv混合模型分为两部分,一部分是基于NLP模型对提示词的编码并获取提示词相应的特征(语义信息),这里的提示词可以是单个的英文单词,也可以是一整段话语,NLP模型采用主流的bert。另一部分是采用视觉模型对图片特征的提取,这里的视觉模型采用vit transformer,对图片完成编码后,进而与经过bert模型编码的提示词特征进行多层的特征融合(fusion),经过交互后的文本特征Pm与视觉特征On通过对比损失函数进行拟合,单张图片基于和Faster Rcnn相似的操作,将每个像素点作为anchor的中心点,设计1:1,1:2和2:1三种形式的锚框,从而对所有锚框的特征与所有提示词的特征进行相似性对比分析,对锚框的位置采用CIOU和GIOU类似的坐标拟合方式。
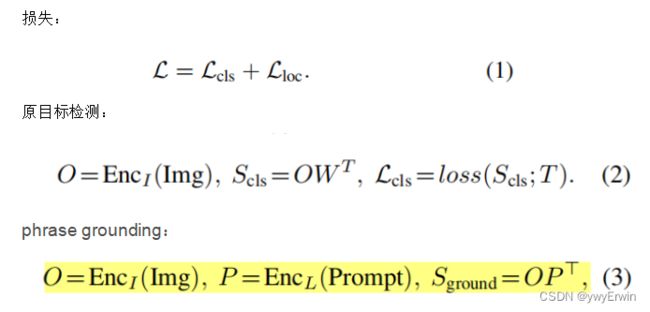
注意,从上式可以看到对于原始的目标检测方式,如公式(2),通过模型获取图片特征O,进而通过与权重矩阵W做点积得到S(cls)为输出logit结果,最后再与真实标签及坐标T(NxC)做损失函数进行拟合;
对于混合模型,如公式(3),一方面基于视觉模型获取图片特征O,另一方面基于nlp模型获取文本特征P,再将文本特征与图片特征对应的区域做匹配得分S(ground),因为在提示词中,由于有以下多种原因造成模型输出的特征维度大于真实目标维度,使得S(ground)(NxM)的维度大于T(NxC)的维度。如:1)一个短语基于模型分词器被分为多个词,如: “traffic light”可以为“traffic ”和“light”;2)单个的词可以拆分为多个,如:“toothbrush” 可以被分为“tooth#”和 “#brush”; 3)添加的一些词及符号,如:“Detect:”, ","等。为了使S(ground)的维度与T的维度相一致,需要将T转换为T'(NxM),即所有句子,短语被分词后将单个的词作为一个目标进行拟合。且一个短语中的所有子词都与该对应图像区域为正匹配,如“traffic light”中的“traffic”和“light”都与对应的图像区域为正匹配。其他所有添加的词及符合为负匹配。在推理的过程中将每个被切分的词的概率的平均值作为该短语对应的区域得分,如“traffic light”,推理时将“traffic ”和“light”在该区域的平均得分作为其联合的目标得分。原文内容如下图所示:


GLIP训练流程
GLIP 数据加载
首先将所有数据图片,文本对封装在datasets里,制作成一个可以在每张显卡批量读取的数据发生器,datasets里包含有opencv读取的图片张量,targets(为每个base anchor对应的label,及对应的提示词),以及每张图片对应的索引。其在源码中示例流程顺序如下:

其中文本的编码采用基于bert预训练模型,示例如下,其中cfg.MODEL.LANGUAGE_BACKBONE.TOKENIZER_TYPE为配置文件中的”bert“,即加载bert预训练模型对文本进行分词,再基于已经预先构建好的词典对词序进行数字转化。
extra_args['tokenizer'] = AutoTokenizer.from_pretrained(cfg.MODEL.LANGUAGE_BACKBONE.TOKENIZER_TYPE)本文章分析基于CoCoGrounding数据格式的读取封装进行展示,
class CocoGrounding(torchvision.datasets.CocoDetection):
def __init__(self,
img_folder,
ann_file,
transforms,
return_masks,
return_tokens,
is_train=False,
tokenizer=None,
disable_shuffle=False,
add_detection_prompt=False,
one_hot=False,
disable_clip_to_image=False,
no_minus_one_for_one_hot=False,
separation_tokens=" ",
few_shot=0,
no_mask_for_od=False,
override_category=None,
use_caption_prompt=False,
caption_prompt=None,
max_query_len=256,
special_safeguard_for_coco_grounding=False,
random_sample_negative=-1,
**kwargs
):
super(CocoGrounding, self).__init__(img_folder, ann_file)
self.ids = sorted(self.ids)
ids = []
for img_id in self.ids:
if isinstance(img_id, str):
ann_ids = self.coco.getAnnIds(imgIds=[img_id], iscrowd=None)
else:
ann_ids = self.coco.getAnnIds(imgIds=img_id, iscrowd=None)
anno = self.coco.loadAnns(ann_ids)
if has_valid_annotation(anno):
ids.append(img_id)
self.ids = ids
if few_shot:
ids = []
# cats_freq = [few_shot]*len(self.coco.cats.keys())
cats_freq = [few_shot]*max(list(self.coco.cats.keys()))
for img_id in self.ids:
if isinstance(img_id, str):
ann_ids = self.coco.getAnnIds(imgIds=[img_id], iscrowd=None)
else:
ann_ids = self.coco.getAnnIds(imgIds=img_id, iscrowd=None)
anno = self.coco.loadAnns(ann_ids)
cat = set([ann['category_id'] for ann in anno]) #set/tuple corresponde to instance/image level
is_needed = sum([cats_freq[c-1]>0 for c in cat])
if is_needed:
ids.append(img_id)
for c in cat:
cats_freq[c-1] -= 1
# print(cat, cats_freq)
self.ids = ids
self.json_category_id_to_contiguous_id = {
v: i + 1 for i, v in enumerate(self.coco.getCatIds())
}
self.contiguous_category_id_to_json_id = {
v: k for k, v in self.json_category_id_to_contiguous_id.items()
}
if override_category is not None:
self.coco.dataset["categories"] = override_category
self.use_caption_prompt = use_caption_prompt
self.caption_prompt = caption_prompt
self.special_safeguard_for_coco_grounding = special_safeguard_for_coco_grounding
self.random_sample_negative = random_sample_negative
self.ind_to_class = self.categories(no_background=False) ## 获取对应的类别名称
self.id_to_img_map = {k: v for k, v in enumerate(self.ids)}
self._transforms = transforms ## 图像增强
self.max_query_len = max_query_len ## 词编码长度
self.prepare = ConvertCocoPolysToMask(False, return_tokens, tokenizer=tokenizer, max_query_len=max_query_len) ## 对label进行编码,图片,标签存入字典
self.tokenizer = tokenizer ## 提示词编码
self.is_train = is_train
self.ind_to_class = self.categories(no_background=False)
self.disable_shuffle = disable_shuffle
self.add_detection_prompt = add_detection_prompt
self.one_hot = one_hot
self.no_minus_one_for_one_hot = no_minus_one_for_one_hot
self.disable_clip_to_image = disable_clip_to_image
self.separation_tokens = separation_tokens
self.no_mask_for_od = no_mask_for_od
self.return_masks = return_masks
def categories(self, no_background=True):
categories = self.coco.dataset["categories"]
label_list = {}
## 获取coco数据集类别,保存至 label_list
for index, i in enumerate(categories):
# assert(index + 1 == i["id"])
if not no_background or (i["name"] != "__background__" and i['id'] != 0):
label_list[self.json_category_id_to_contiguous_id[i["id"]]] = i["name"]
return label_list
## 获取标签对应的框
def get_box_mask(self, rect, img_size, mode="poly"):
assert mode=="poly", "Only support poly mask right now!"
x1, y1, x2, y2 = rect[0], rect[1], rect[2], rect[3]
return [[x1, y1, x1, y2, x2, y2, x2, y1]]
## 数据迭代器
def __getitem__(self, idx):
## 每一张图片的类别,box;target包含box,图像宽高,标签
img, tgt = super(CocoGrounding, self).__getitem__(idx)
image_id = self.ids[idx]
tgt = [obj for obj in tgt if obj["iscrowd"] == 0]
boxes = [obj["bbox"] for obj in tgt]
boxes = torch.as_tensor(boxes).reshape(-1, 4) # guard against no boxes
target = BoxList(boxes, img.size, mode="xywh").convert("xyxy")
classes = [obj["category_id"] for obj in tgt] ## 类别id
classes = [self.json_category_id_to_contiguous_id[c] for c in classes]
classes = torch.tensor(classes)
target.add_field("labels", classes)
if self.return_masks:
masks = []
is_box_mask = []
for obj, bbox in zip(tgt, target.bbox):
if "segmentation" in obj:
masks.append(obj["segmentation"])
is_box_mask.append(0)
else:
masks.append(self.get_box_mask(bbox, img.size, mode="poly"))
is_box_mask.append(1)
masks = SegmentationMask(masks, img.size, mode="poly")
is_box_mask = torch.tensor(is_box_mask)
target.add_field("masks", masks)
target.add_field("is_box_mask", is_box_mask)
if not self.disable_clip_to_image:
target = target.clip_to_image(remove_empty=True)
if self.special_safeguard_for_coco_grounding:
# Intended for LVIS
assert(not self.use_caption_prompt)
original_box_num = len(target)
target, positive_caption_length = check_for_positive_overflow(target, self.ind_to_class, self.tokenizer, self.max_query_len-2) # leave some space for the special tokens
if len(target) < original_box_num:
print("WARNING: removed {} boxes due to positive caption overflow".format(original_box_num - len(target)))
annotations, caption, greenlight_span_for_masked_lm_objective, label_to_positions = convert_object_detection_to_grounding_optimized_for_od(
target=target,
image_id=image_id,
ind_to_class=self.ind_to_class,
disable_shuffle=self.disable_shuffle,
add_detection_prompt=False,
add_detection_prompt_advanced=False,
random_sample_negative=self.random_sample_negative,
control_probabilities=(0.0, 0.0, 1.0, 0.0), # always try to add a lot of negatives
restricted_negative_list=None,
separation_tokens=self.separation_tokens,
max_num_labels=-1,
positive_caption_length=positive_caption_length,
tokenizer=self.tokenizer,
max_seq_length=self.max_query_len-2
)
else:
# Intended for COCO / ODinW
## annotations:包含图片对应的label,提示词tokens位置,caption为标签label;greenlight_span_for_masked_lm_objective:为提示词对应的位置
# print('self.use_caption_prompt', self.use_caption_prompt)
annotations, caption, greenlight_span_for_masked_lm_objective = convert_od_to_grounding_simple(
target=target, # 目标
image_id=image_id, # 图片索引,唯一
ind_to_class=self.ind_to_class, # 类别名称
disable_shuffle=self.disable_shuffle,
add_detection_prompt=self.add_detection_prompt, # false
separation_tokens=self.separation_tokens, ## 提示词之间的分割符
caption_prompt=self.caption_prompt if self.use_caption_prompt else None, ## true
)
anno = {"image_id": image_id, "annotations": annotations, "caption": caption}
anno["greenlight_span_for_masked_lm_objective"] = greenlight_span_for_masked_lm_objective
if self.no_mask_for_od:
anno["greenlight_span_for_masked_lm_objective"].append((-1, -1, -1))
## img, anno就是对应的target,target包含很多(box,labels,caption,image_id, tokens_positive, size, positive_map, greenlight_map, positive_map_for_od_labels, original_od_label)
img, anno = self.prepare(img, anno, box_format="xyxy") ## 将提示词编码,图片,box,标签,提示词编码
# img.save("image_save/11.jpg")
# print("image--", img)
# print("anno--", anno)
# for equivalence check
if self.one_hot:
logging.info("using one hot for equivalence check.")
one_hot_map = torch.zeros_like(anno["positive_map"], dtype=torch.float)
text_mask = torch.zeros(anno["positive_map"].shape[1], dtype=torch.int64)
# create one hot mapping
for ii, cls in enumerate(classes):
if self.no_minus_one_for_one_hot:
one_hot_map[ii, cls] = 1.0
else:
one_hot_map[ii, cls - 1] = 1.0
if self.no_minus_one_for_one_hot:
text_mask[:] = 1
else:
text_mask[:len(self.ind_to_class)] = 1
anno["positive_map"] = one_hot_map
anno["text_mask"] = text_mask
if self._transforms is not None:
img, target = self._transforms(img, target)
# add additional property
for ann in anno:
target.add_field(ann, anno[ann])
sanity_check_target_after_processing(target)
# print('idx', idx)
# print('target...', target)
## target集成了很多信息结果
return img, target, idx原理细节可以看代码展示部分,主要通过调用 def __getitem__(self, idx) 函数将每张图片的信息(包括anchor,label,prompt)根据每张图片的idx进行迭代,idx表示每张图片的索引(唯一), 将所有的目标信息封装在target中,target里包含两部分内容,一部分是有单张图片idx所包含的box和box对应的标签label,图片size,另一部分包含文本经bert模型进行的分词,词编码转换为数字,token的位置,positive_map(不同类别的token对应位置,如:cell phone. dog. 对应的positive_map为: [[[0, 10]], [[12, 15]]],[0,10]为prompt对应的索引位置),greenlight_map以及文本掩码 text_mask。
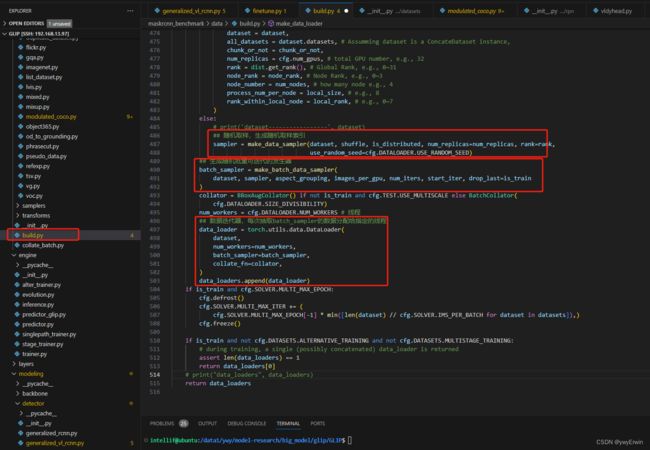
和yolo,SSD等小模型一样,对图片tensor及对应的label,box封装成dataset后,进而基于索引随机生成批量图片,构成数据发生器,因为一次将所有数据存入显卡中,显存易爆,所以需要批量的数据进行训练,通过设置线程数及分布式显卡,即可进行数据的批量读取,源码中采用ddp形式的分布式。
GLIP模型框架解析:
GLIP模型主要由两部分组成,源码中通过GeneralizedVLRCNN函数融合了bert和vit transformer及VLDHead三部分模型框架,对vit transformer和bert的主干网络backbone以下图所示代码展示,对backbone和language_backbone中的swint.py,bert_model.py的前向推理forward函数进行查看,这儿对模型细节部分先跳过。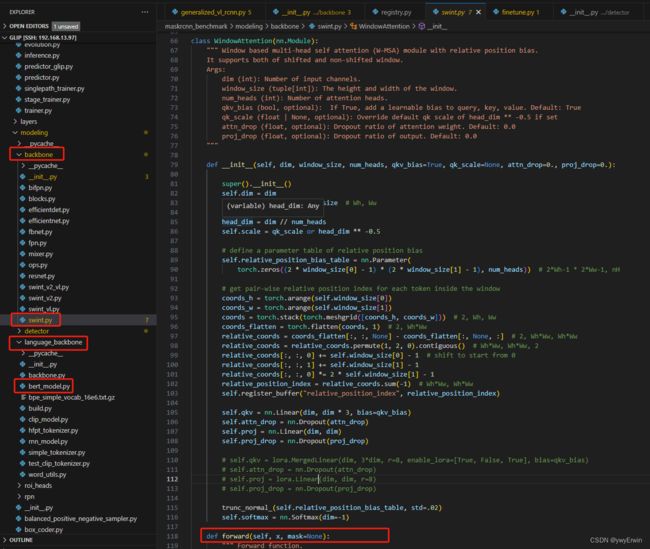
在GeneralizedVLRCNN函数中,通过self.tokenizer.batch_encode_plus API将文本/提示词编码成固定长度的数字映射值,提示词超出的做裁剪,不足的做填充,并获取文本转换的数字特征及关注度。
通过language_dict_features = self.language_backbone(tokenizer_input)获取基于文本转换的数值经过bert模型后的特征向量;通过visual_features = self.backbone(images.tensors)获取图像特征向量,进一步将图像特征和文本特征通过VLDHead检测头后进行融合并输出融合后对应的特征。
tokenized = self.tokenizer.batch_encode_plus(captions,
max_length=self.cfg.MODEL.LANGUAGE_BACKBONE.MAX_QUERY_LEN,
padding='max_length' if self.cfg.MODEL.LANGUAGE_BACKBONE.PAD_MAX else "longest",
return_special_tokens_mask=True,
return_tensors='pt',
truncation=True).to(device)
input_ids = tokenized.input_ids
# 获取一个字典 数字特征和关注度
tokenizer_input = {"input_ids": input_ids,
attention_mask": tokenized.attention_mask}
# print("tokenizer_input----------------", tokenizer_input)基于self.head函数获取图像特征和文本特征经过交互fusion后的图像及文本特征信息,
proj_tokens, contrastive_logits, dot_product_logits, mlm_logits, shallow_img_emb_feats, fused_visual_features = self.head(features,
language_dict_features,
embedding,
swint_feature_c4
) ### 经过检测头,获得框的特征信息,token编码信息基于anchors = self.anchor_generator(images, features)函数获取每张图片中生成的base anchor,即每个特征像素点都会生成三个anchor,比例为1:1,1:2,2:1,代码如下所示。

对生成的anchor box特征和对应的文本特征通过self.loss_evaluator = make_atss_loss_evaluator(cfg, box_coder)函数,进行对比损失的计算
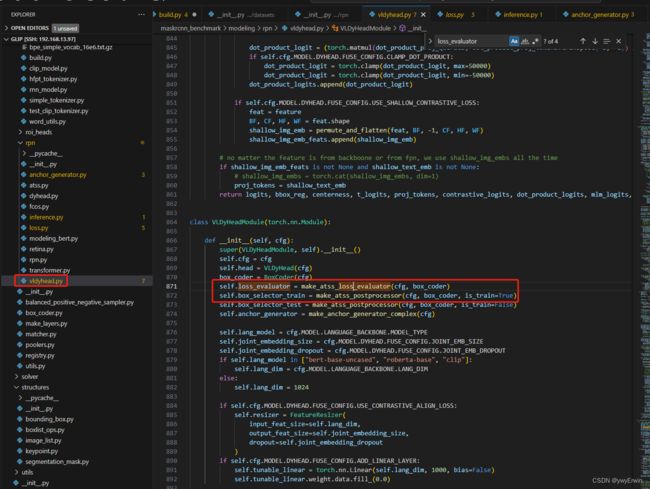

对比损失函数的定义如下(摘自某博文),

GeneralizedVLRCNN对联合模型的函数封装展示(对整个框架的运行流程可以查看以下代码即注释部分):
class GeneralizedVLRCNN(nn.Module):
"""
Main class for Generalized R-CNN. Currently supports boxes and masks.
It consists of three main parts:
- backbone
- rpn
- heads: takes the features + the proposals from the RPN and computes
detections / masks from it.
"""
def __init__(self, cfg):
super(GeneralizedVLRCNN, self).__init__()
self.cfg = cfg
# visual encoder
self.backbone = build_backbone(cfg)
# language encoder
if cfg.MODEL.LANGUAGE_BACKBONE.TOKENIZER_TYPE == "clip": ## 有clip和bert
# self.tokenizer = build_tokenizer("clip")
from transformers import CLIPTokenizerFast
if cfg.MODEL.DYHEAD.FUSE_CONFIG.MLM_LOSS:
print("Reuse token 'ðŁĴij' (token_id = 49404) for mask token!")
self.tokenizer = CLIPTokenizerFast.from_pretrained("openai/clip-vit-base-patch32",
from_slow=True, mask_token='ðŁĴij')
else: ## 需要下载openai/clip-vit-base-patch32
self.tokenizer = CLIPTokenizerFast.from_pretrained("openai/clip-vit-base-patch32",
from_slow=True)
else: ## 标记器(tokenizer)是用来对文本进行预处理的一个工具 cfg.MODEL.LANGUAGE_BACKBONE.TOKENIZER_TYPE: bert-base-uncased
print("cfg.MODEL.LANGUAGE_BACKBONE.TOKENIZER_TYPE--------", cfg.MODEL.LANGUAGE_BACKBONE.TOKENIZER_TYPE)
self.tokenizer = AutoTokenizer.from_pretrained(cfg.MODEL.LANGUAGE_BACKBONE.TOKENIZER_TYPE)
self.tokenizer_vocab = self.tokenizer.get_vocab()
self.tokenizer_vocab_ids = [item for key, item in self.tokenizer_vocab.items()]
self.language_backbone = build_language_backbone(cfg)
self.rpn = build_rpn(cfg)
self.roi_heads = build_roi_heads(cfg)
self.DEBUG = cfg.MODEL.DEBUG
self.freeze_backbone = cfg.MODEL.BACKBONE.FREEZE
self.freeze_fpn = cfg.MODEL.FPN.FREEZE
self.freeze_rpn = cfg.MODEL.RPN.FREEZE
self.add_linear_layer = cfg.MODEL.DYHEAD.FUSE_CONFIG.ADD_LINEAR_LAYER
self.force_boxes = cfg.MODEL.RPN.FORCE_BOXES
if cfg.MODEL.LINEAR_PROB:
assert cfg.MODEL.BACKBONE.FREEZE, "For linear probing, backbone should be frozen!"
if hasattr(self.backbone, 'fpn'):
assert cfg.MODEL.FPN.FREEZE, "For linear probing, FPN should be frozen!"
self.linear_prob = cfg.MODEL.LINEAR_PROB
self.freeze_cls_logits = cfg.MODEL.DYHEAD.FUSE_CONFIG.USE_DOT_PRODUCT_TOKEN_LOSS
if cfg.MODEL.DYHEAD.FUSE_CONFIG.USE_DOT_PRODUCT_TOKEN_LOSS:
# disable cls_logits
if hasattr(self.rpn.head, 'cls_logits'):
for p in self.rpn.head.cls_logits.parameters():
p.requires_grad = False
self.freeze_language_backbone = self.cfg.MODEL.LANGUAGE_BACKBONE.FREEZE
if self.cfg.MODEL.LANGUAGE_BACKBONE.FREEZE:
for p in self.language_backbone.parameters():
p.requires_grad = False
self.use_mlm_loss = cfg.MODEL.DYHEAD.FUSE_CONFIG.MLM_LOSS
self.mlm_loss_for_only_positives = cfg.MODEL.DYHEAD.FUSE_CONFIG.MLM_LOSS_FOR_ONLY_POSITIVES
if self.cfg.GLIPKNOW.KNOWLEDGE_FILE:
from maskrcnn_benchmark.data.datasets.tsv import load_from_yaml_file
self.class_name_to_knowledge = load_from_yaml_file(self.cfg.GLIPKNOW.KNOWLEDGE_FILE)
self.class_name_list = sorted([k for k in self.class_name_to_knowledge])
def forward(self,
images,
targets=None,
captions=None,
positive_map=None,
greenlight_map=None):
"""
Arguments:
images (list[Tensor] or ImageList): images to be processed
targets (list[BoxList]): ground-truth boxes present in the image (optional)
mask_black_list: batch x 256, indicates whether or not a certain token is maskable or not
Returns:
result (list[BoxList] or dict[Tensor]): the output from the model.
During training, it returns a dict[Tensor] which contains the losses.
During testing, it returns list[BoxList] contains additional fields
like `scores`, `labels` and `mask` (for Mask R-CNN models).
"""
if self.training and targets is None:
raise ValueError("In training mode, targets should be passed")
# print("images---------------------", images)
# print("type________________images", type(images))
images = to_image_list(images)
# batch_size = images.tensors.shape[0]
device = images.tensors.device
if self.cfg.GLIPKNOW.PARALLEL_LANGUAGE_INPUT:
language_dict_features, positive_map = self._forward_language_parallel(
captions=captions, targets=targets, device=device,
positive_map=positive_map)
else:
# language embedding
language_dict_features = {}
if captions is not None:
print("captions---------------------------------------------", captions)
#print(captions[0])
## 将 label 编码成数字
tokenized = self.tokenizer.batch_encode_plus(captions,
max_length=self.cfg.MODEL.LANGUAGE_BACKBONE.MAX_QUERY_LEN,
padding='max_length' if self.cfg.MODEL.LANGUAGE_BACKBONE.PAD_MAX else "longest",
return_special_tokens_mask=True,
return_tensors='pt',
truncation=True).to(device)
if self.use_mlm_loss: ## 没有采用ml loss
if not self.mlm_loss_for_only_positives:
greenlight_map = None
input_ids, mlm_labels = random_word(
input_ids=tokenized.input_ids,
mask_token_id=self.tokenizer.mask_token_id,
vocabs=self.tokenizer_vocab_ids,
padding_token_id=self.tokenizer.pad_token_id,
greenlight_map=greenlight_map)
else:
input_ids = tokenized.input_ids
mlm_labels = None
# 获取一个字典 数字特征和关注度
tokenizer_input = {"input_ids": input_ids,
"attention_mask": tokenized.attention_mask}
# print("tokenizer_input----------------", tokenizer_input)
if self.cfg.MODEL.LANGUAGE_BACKBONE.FREEZE:
with torch.no_grad():
language_dict_features = self.language_backbone(tokenizer_input)
else:
## 获得nlp模型对每个token编码后的特征
language_dict_features = self.language_backbone(tokenizer_input)
# ONE HOT
if self.cfg.DATASETS.ONE_HOT:
new_masks = torch.zeros_like(language_dict_features['masks'],
device=language_dict_features['masks'].device)
new_masks[:, :self.cfg.MODEL.DYHEAD.NUM_CLASSES] = 1
language_dict_features['masks'] = new_masks
# MASK ALL SPECIAL TOKENS
if self.cfg.MODEL.LANGUAGE_BACKBONE.MASK_SPECIAL:
language_dict_features["masks"] = 1 - tokenized.special_tokens_mask
language_dict_features["mlm_labels"] = mlm_labels
# visual embedding
swint_feature_c4 = None
if 'vl' in self.cfg.MODEL.SWINT.VERSION:
# the backbone only updates the "hidden" field in language_dict_features
inputs = {"img": images.tensors, "lang": language_dict_features}
visual_features, language_dict_features, swint_feature_c4 = self.backbone(inputs)
else:
## 获得图片特征
visual_features = self.backbone(images.tensors)
# rpn force boxes
if targets:
targets = [target.to(device)
for target in targets if target is not None]
if self.force_boxes:
proposals = []
for t in targets:
tb = t.copy_with_fields(["labels"])
tb.add_field("scores", torch.ones(tb.bbox.shape[0], dtype=torch.bool, device=tb.bbox.device))
proposals.append(tb)
if self.cfg.MODEL.RPN.RETURN_FUSED_FEATURES:
_, proposal_losses, fused_visual_features = self.rpn(
images, visual_features, targets, language_dict_features,
positive_map, captions, swint_feature_c4)
elif self.training:
null_loss = 0
for key, param in self.rpn.named_parameters():
null_loss += 0.0 * param.sum()
proposal_losses = {('rpn_null_loss', null_loss)}
else:
## 将图片特征,文字特征,目标进行rpn融合( VLDyHeadModule检测头),包含检测头,获得最后结果, 主要用到了positive_map
proposals, proposal_losses, fused_visual_features = self.rpn(images, visual_features, targets, language_dict_features, positive_map,
captions, swint_feature_c4)
if self.roi_heads:
if self.cfg.MODEL.ROI_MASK_HEAD.PREDICTOR.startswith("VL"):
if self.training:
# "Only support VL mask head right now!!"
assert len(targets) == 1 and len(targets[0]) == len(positive_map), "shape match assert for mask head!!"
# Not necessary but as a safe guard:
# use the binary 0/1 positive map to replace the normalized positive map
targets[0].add_field("positive_map", positive_map)
# TODO: make sure that this use of language_dict_features is correct!! Its content should be changed in self.rpn
if self.cfg.MODEL.RPN.RETURN_FUSED_FEATURES:
x, result, detector_losses = self.roi_heads(
fused_visual_features, proposals, targets,
language_dict_features=language_dict_features,
positive_map_label_to_token=positive_map if not self.training else None
)
else:
x, result, detector_losses = self.roi_heads(
visual_features, proposals, targets,
language_dict_features=language_dict_features,
positive_map_label_to_token=positive_map if not self.training else None
)
else:
# RPN-only models don't have roi_heads
x = visual_features
result = proposals
detector_losses = {}
if self.training:
losses = {}
losses.update(detector_losses)
losses.update(proposal_losses)
return losses
return resultGLIP模型推理流程:
GLIP模型的推理主要借助from maskrcnn_benchmark.engine.predictor_glip import GLIPDemo 中的GLIPDemo.run_on_web_image(image, caption, conf)函数,其中image为PIL读取的RGB图像(需要转成BGR)和caption提示词,conf对比的相似度阈值,源码展示如下
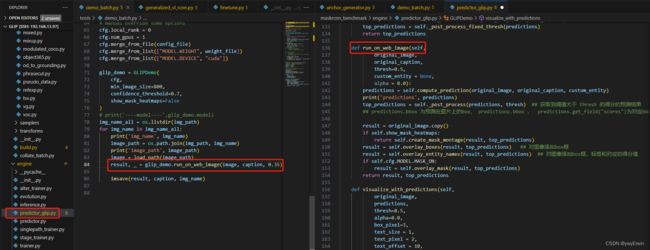
具体的细节可以看下面推理代码注释部分
def compute_prediction(self, original_image, original_caption, custom_entity = None):
# image
image = self.transforms(original_image)
image_list = to_image_list(image, self.cfg.DATALOADER.SIZE_DIVISIBILITY)
image_list = image_list.to(self.device)
# caption
## 对提示词进行一个编码
print('original_caption', original_caption)
tokenized = self.tokenizer([original_caption], return_tensors="pt") ## tokenized {'input_ids': tensor([[ 101, 3526, 3042, 1012, 3899, 1012, 102]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1]])}
if custom_entity is None:
tokens_positive = self.run_ner(original_caption) ## 获取提示词位置 eg. cell phone. dog. : [[[0, 10]], [[12, 15]]]
print('tokenized', tokenized)
# process positive map 表示在256维的token位置上,提示词所对应位置的长度,并将其归一化 (表示对提示词编码后的特征)
positive_map = create_positive_map(tokenized, tokens_positive) ## eg. 一个提示词 positive_map.size(): [1, 256],如果两个提示词则为:[2, 256]
print('positive_map.size', positive_map.size())
# print('positive_map----------------', positive_map)
# print('type_positive_map', type(positive_map))
if self.cfg.MODEL.RPN_ARCHITECTURE == "VLDYHEAD":
plus = 1
else:
plus = 0
## positive_map_label_to_token ???
positive_map_label_to_token = create_positive_map_label_to_token_from_positive_map(positive_map, plus=plus) ## 正样本 提示词索引及位置 positive_map_label_to_token: {1: [1, 2]}
print('positive_map_label_to_token', positive_map_label_to_token) ## 返回的是对应提示词对应的索引位置 positive_map_label_to_token {1: [1, 2], 2: [4]}
self.plus = plus
self.positive_map_label_to_token = positive_map_label_to_token
tic = timeit.time.perf_counter()
# compute predictions
with torch.no_grad():
## 传入三个参数,图片信息,原始提示词,提示词编码的位置
predictions = self.model(image_list, captions=[original_caption], positive_map=positive_map_label_to_token)
predictions = [o.to(self.cpu_device) for o in predictions]
print("inference time per image: {}".format(timeit.time.perf_counter() - tic))
# always single image is passed at a time
prediction = predictions[0]
# reshape prediction (a BoxList) into the original image size
height, width = original_image.shape[:-1]
prediction = prediction.resize((width, height))
if prediction.has_field("mask"):
# if we have masks, paste the masks in the right position
# in the image, as defined by the bounding boxes
masks = prediction.get_field("mask")
# always single image is passed at a time
masks = self.masker([masks], [prediction])[0]
prediction.add_field("mask", masks)
return prediction