从模型到前端,你应该知道的LLM生态系统指南
LLM在在2023年发展的风生水起,一个围绕LLM的庞大生态系统正在形成,本文通过介绍这个生态系统的核心组成部分,来详细整理LLM的发展。
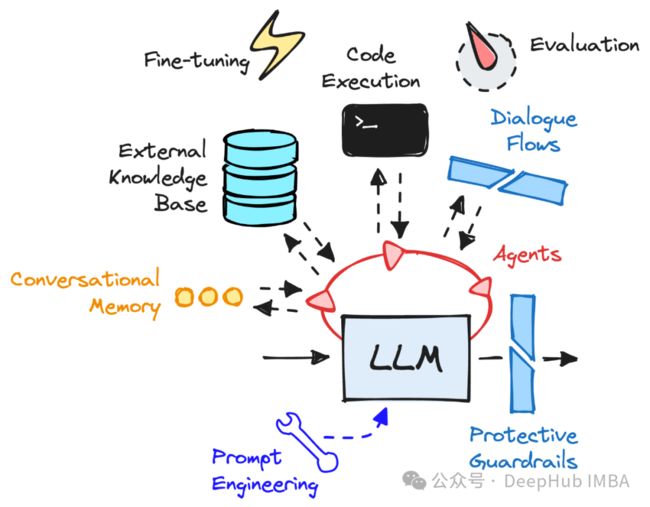
模型-核心组件
大型语言模型(llm)是人工智能应用程序背后的原材料。这些模型最初被预先训练来预测句子中的下一个单词。这种“不那么明显”的特性是,人们可以进行微调来让下游的程序以遵循指示,下游的任务可能是是回答问题、进行对话和推理。
这些模型都具有(非常)大的参数数量。最小的模型大约有15亿个参数,而一些较大的模型(如Falcon)大约有1800亿个参数。
GPT-4是Chat-GPT(付费版本)背后的LLM,据传有大约1.4万亿个参数。
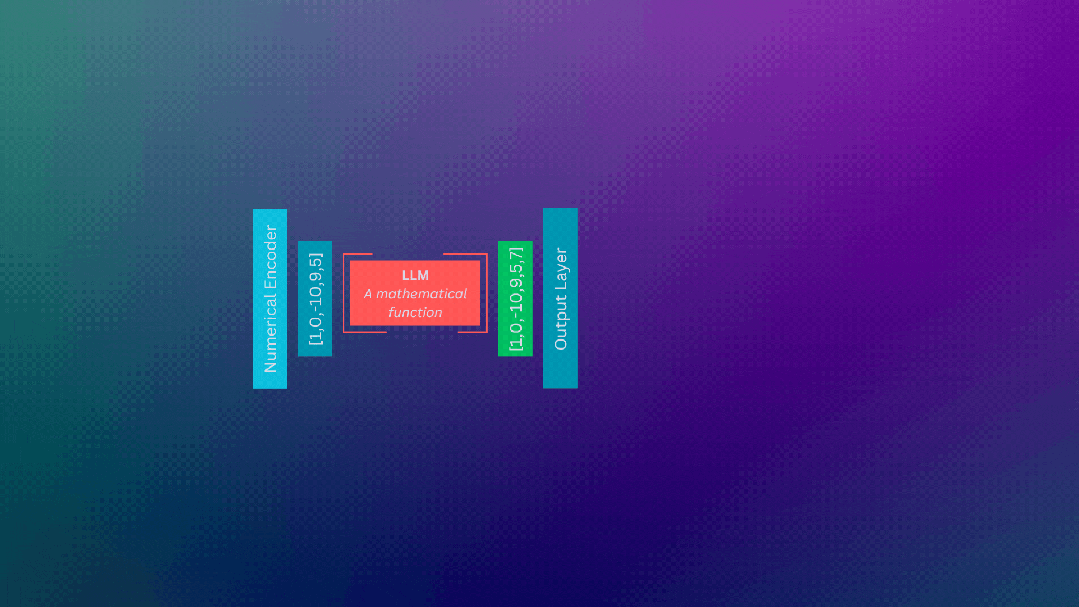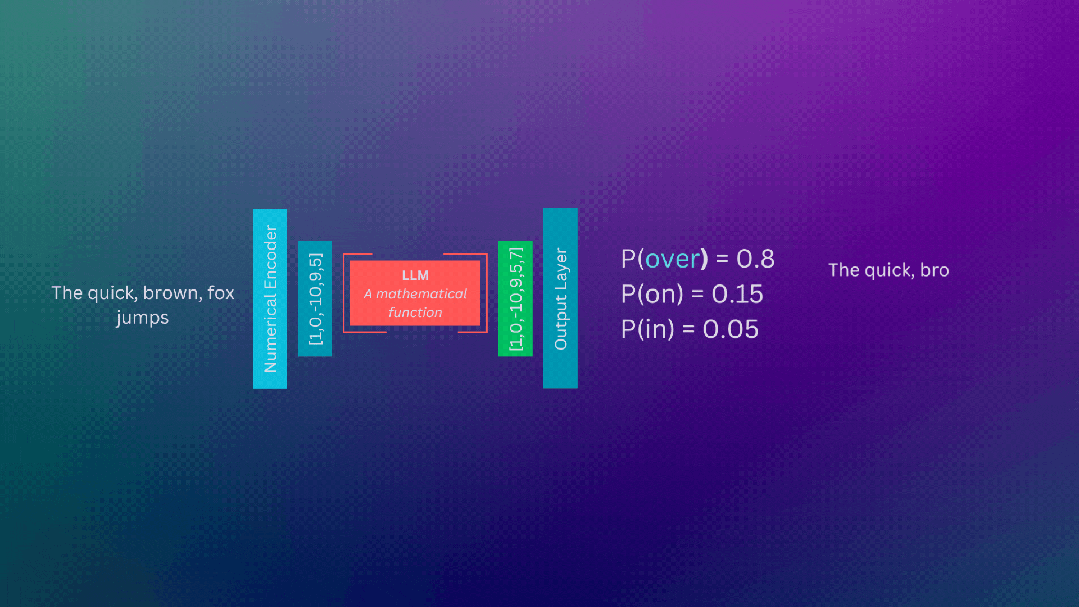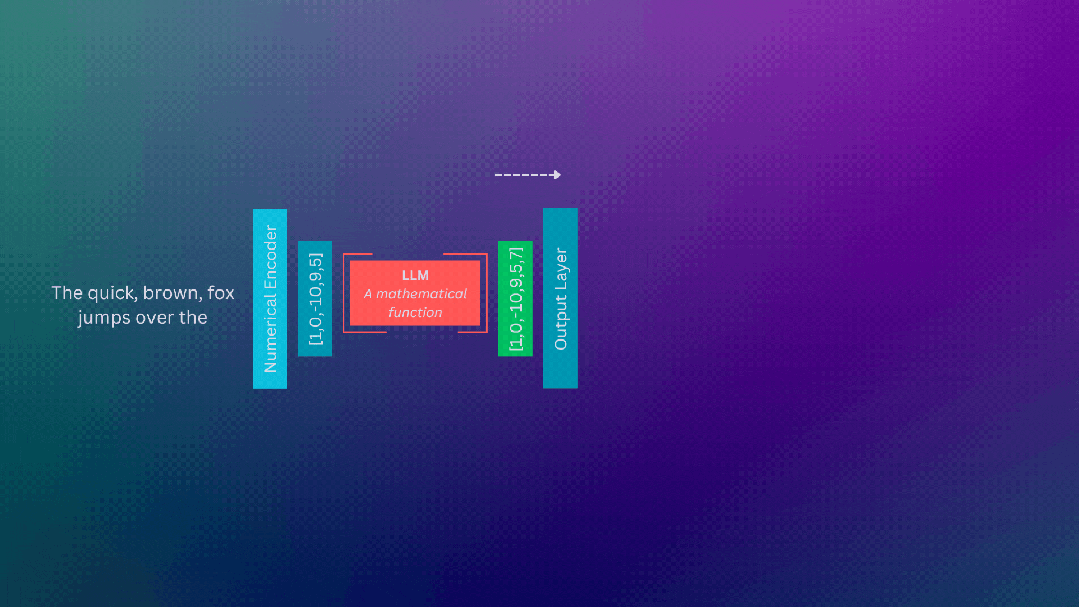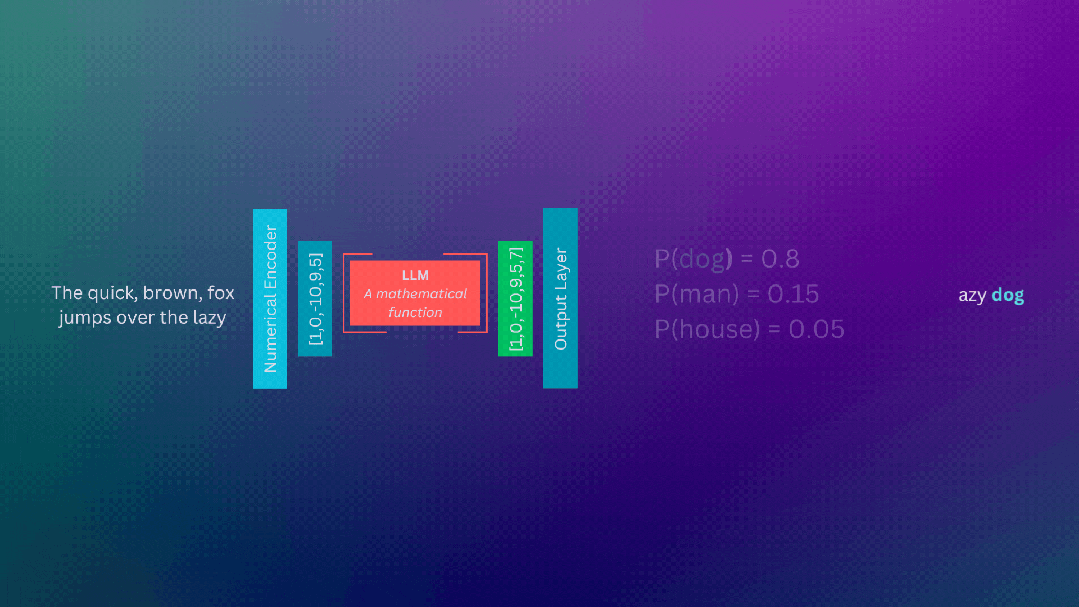
计算基础设施
LLM只是带有大量参数的模型。当我们在LLM上执行推理时,执行的是数学运算,LLM的庞大规模意味着需要执行许多这些数学运算!
执行这些操作需要专门的gpu(图形处理单元)。gpu擅长并行执行数学运算,这是实现使用llm所需运算的有效方式。
合适的gpu很难买到;消费级的GPU也不一定能够良好的适应LLM的推理工作,所以就需要Runpod, UbiOps等计算平台,甚至云平台,租用gpu来运行的LLM工作。
Hugging Face
之所以要提到Hugging Face是因为它提供了大量的LLM实用程序,并且基本上所有的开源程序都能在那里找到。
除了Hugging Face平台以外,它还提供了很多库来简化我们的操作
AutoTrain:可以使用AutoTrain平台作为对模型进行微调的无代码解决方案。它管理计算基础设施,以每小时计算租用GPU进行训练
Leaderboards:Open LLM排行榜将基础模型的性能与基准进行比较。而聊天机器人竞技场比较模型作为聊天机器人的性能。我们可以通过排名来了解业界发展的趋势或者选择合适的模型。
Datasets:通过hugs Face访问数据集可以将其用作数据存储库。如果你正在寻找数据来评估或微调你的LLM,可以从这里开始。
Spaces:空间可以让演示快速启动并与客户一起运行。这是我们放Demo的好地方
Python api:这些服务位于它们的api后面,可以通过编程方式访问。Hugging Face代码库是开源的,可以在GitHub上获得。
Hugging Face它是开源LLM开发的核心——对任何工程师来说都是无价的资源。
LLM服务
可用的专有LLM服务的数量似乎每月都在增长,比如OpenAI、Anthropic和Mistral AI。专有服务可以让你你轻松开发LLM应用程序。
我们不需要任何模型或基础设施,会节省很多的基础设计建设费用,但是提供商对其模型的更新甚至公司政策的改变会对应用产生很大的影响,还有就是数据安全的问题也需要考虑
推理服务
推理服务器只适用于在开源基础llm上进行开发的情况,
创建专有的推理服务可以有效地在llm上运行推理,提高了模型吞吐量。vLLM就是一个很好的例子;它使吞吐量最大化。在构建计划扩展的应用程序时,效率意味着节省成本!
许多LLM应用程序开发框架最初被设计为与OpenAI API一起工作。所以集成您的开源LLM可能具有挑战性。而推理服务器可以通过提供与OpenAI API相同的API来解决这个问题。
应用程序开发
LangChain、LlamaIndex、Haystack和AutoGen等框架都属于这一类。它们都有一个共同点:提供函数和类,帮助llm驱动的应用程序构建组件。例如,如果希望开发聊天机器人,可以利用LlamaIndex中的聊天包装器。如果你想构建多代理工作流,你可以选择AutoGen的GroupChat。这些框架本质上是即插即用的。
前端-用户界面
前端或UI对于任何llm驱动的应用程序来说都是锦上添花;这通常是一些聊天界面。
并非所有应用程序都需要聊天界面前端;GitHub copilot就是一个很好的例子;它只是直接集成到交互式开发环境中。
Chainlit可以很好地与应用程序开发框架集成,是可定制的,并且可以使用多模态模型。Streamlit 也是很不错的选择。
总结
今天是大年三十,对于我们来说,今天是农历年的最后一天,所以本文整理了LLM的完整生态,这个LLM生态系统正在迅速发展,本文中概述的原则是目前LLM应用的基本系统组件,即使出现了更多的技术,这些基本组件也都不会过时。
https://avoid.overfit.cn/post/e320df1e77624fbbb6f84c5b5c2dc351
作者:John Adeojo