107、Repaint123: Fast and High-quality One Image to 3D Generation with Progressive Controllable 2D Re
简介
github官网

两阶段3D生成。第一阶段使用3D Gaussian Splatting 生成粗糙的三维表示,第二阶段使用 Diffusion Repainting 优化细节。

目前的方法采用SDS损失,导致纹理不一致,质地差。
实现流程
总流程。

粗化阶段,采用3D Gaussian Splatting作为DreamGaussian的表示,学习通过SDS损耗优化的粗化几何和纹理。
细化阶段,将粗糙模型转换为网格表示,然后进行纹理细化
细化阶段。
Multi-view Consistent Images Generation
图生3D的一个最大问题是在重叠区域进行像素级对齐,同时保持参考视图和新视图之间的语义级和纹理级一致性。论文采用逐步用参考纹理重新绘制遮挡区域。
首先,获取参考视图图像和相邻的新视图图像之间的重叠和遮挡。
然后,通过DDIM反演将粗糙的新视图图像反演为确定性的中间噪声潜在表示,并注入参考视图中间噪声潜在表示(参考HiFi-123)。在这个过程中,反演保留了遮挡中粗糙的3D一致颜色信息,而注意注入则补充了一致的高频细节。
重复迭代上述过程,进行相邻和谐和像素级对齐,最后双向旋转相机,并逐步将此重绘过程从参考视图应用到所有视图。因此,可以无缝地重新绘制遮挡,同时具有短期一致性(重叠对齐和邻居和谐)和长期一致性(语义和纹理的后视一致性)。
获取占用掩膜
为了使用渲染图像 I n I_n In 和深度图 D n D_n Dn 在新视图中获得遮挡掩码 M n M_n Mn,给定一个带有 I r I_r Ir 和 D r D_r Dr 的重绘参考视图,首先通过缩放 V r V_r Vr 的相机光线和深度值 D r D_r Dr ,将视图 V r V_r Vr 中的2D像素反向投影到3D点 P r P_r Pr 中。然后,从 P r P_r Pr 和目标视角 V n V_n Vn 中渲染深度图 D n ′ D_n' Dn′。两个新视图深度图( D n D_n Dn 和 D n ′ D'_ n Dn′)之间深度值不同的区域是遮挡掩模 M n M_n Mn 中的遮挡区域。
DDIM 反演过程
为了保持重叠区域的纹理,对新视图图像 I I I 进行DDIM反演,得到确定性的中间噪声潜在表示 x i n v x^{inv} xinv,可以对输入图像进行反向去噪(重绘),从而忠实地重建输入图像。
利用深度重绘
利用中间噪声潜在表示 x i n v x^{inv} xinv,可以在每个去噪步骤中替换去噪潜点中的重叠部分,在协调遮挡区域的同时强制重叠区域保持不变
![]()
其中 x t − 1 r e v ∼ N ( μ ϕ ( x t , t ) , ∑ ϕ ( x t , t ) ) x^{rev}_{t-1} \sim N(\mu_\phi(x_t,t),\sum_\phi(x_t,t)) xt−1rev∼N(μϕ(xt,t),∑ϕ(xt,t))是时间步长 t 的去噪潜函数,使用ControlNet对粗深度图施加额外的几何约束,以确保图像的几何一致性。
文本注入
为了减轻后视图的累积纹理偏差,采用了一种mutual self-attention mechanism,在每个去噪步骤中将参考注意特征注入新视图重绘过程。
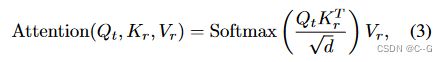
其中 Q t Q_t Qt 是从空间特征投影出来的新视图 query特征。这增强了纹理细节的传递,提高了新视图图像的一致性
360°重绘掩膜
逐步采样在顺时针和逆时针增量之间交替的新相机视图。为了确保两个方向交界处的一致性,从两个方向中选择最近的摄像机视图(如第一张图中红色摄像机所示)来计算遮挡蒙版并在新视图中重新绘制纹理。
![]()
其中 M r M_r Mr 和 M r ’ M_{r’} Mr’ 分别为两个参考视图得到的遮挡掩码,M 为最终掩码。
Image Quality Enhancement
在增加的角度上累积的纹理退化会导致多视图图像质量恶化,重叠和遮挡区域都有退化,如下图,当前一个视图是倾斜视图时,它会导致纹理贴图的低分辨率更新,从而导致从前视图呈现时的高失真,论文提出一种可见度感知的自适应重绘过程,根据这些区域之前的最佳视角来细化不同强度的重叠区域。对于遮挡区域,由于缺乏文本提示来执行无分类器引导,它们的质量有限,这对于高质量图像生成的扩散模型至关重要。为了提高整体质量,采用CLIP编码器(如第一张图所示)对参考图像进行编码并投影到图像提示中进行引导。

可见度感知的自适应重绘过程
重叠区域的最佳细化强度是至关重要的,因为强度过大会产生不忠实的结果,而强度不足会限制质量的提高。为了选择合适的细化强度,将去噪强度与可见度图 V 相关联(类似于trimap的概念)。
获取可见度图
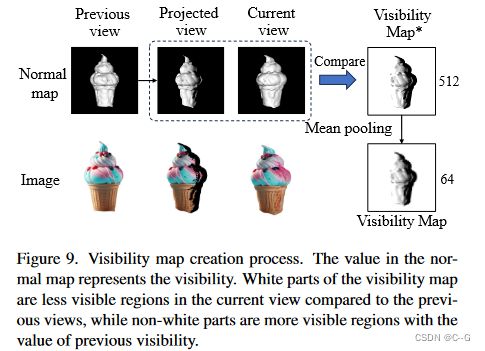
将 previous 法线贴图反向投影到3D点上,然后基于这些3D点渲染新视图中的法线贴图,即投影视图(projected view) 中的法线贴图,如上图,将新视图法线图与新视图投影法线图进行比较,可以得到一个高分辨率的可见度图,将投影法线图的值分配给新视图中可见度提高的区域(上图中可见度图的非白色部分),以便进一步细化,并将值1分配给其他区域(上图中可见度图的白色部分)以保存。最终的可见度图通过从512x512分辨率降采样到64x64分辨率得到,便于后续在潜在空间中重新绘制掩码生成。
对于遮挡区域,将 V 中的值设置为0。对于重叠区域,设置V值为1,表明这些区域不需要细化。对于 V 中的剩余区域,将值设为 c o s θ ∗ cos\ θ* cos θ∗ ,根据可见性图自适应地重新绘制重叠区域,以实现真实度和真实性之间的权衡。具体来说,如上图所示,将重新绘制视为一个类似于补充详细信息的超分辨率过程。根据正交投影定理,它断言碎片的投影分辨率与 c o s θ cos\ θ cos θ 成正比,可以假设重绘强度等于 ( 1 − c o s θ ∗ ) (1−cos\ θ∗) (1−cos θ∗)。在每个去噪步骤中,根据当前时间步长,将软可见性映射二值化到硬重绘蒙版,用上图中的绿框“时间步长感知二值化”表示。

式中, M t M_t Mt 为自适应重绘蒙版,i、j 为碎片在可见度图 V 中的二维位置,T 为扩散模型的总时间步数。

将可见性映射转换为时间步长依赖的重绘掩码。根据可见度与重绘强度的比例关系,在可见度图中选择可见度值不超过 1 - t/ T 的区域即可得到重绘区域(上图中的黑色区域),其中t表示训练时的最大时间步长(一般为1000),t 表示当前重绘时间步长。如上图所示,降低去噪时间步长扩大了重绘区域,表明根据先前的可见性进行了逐步细化。
文本提示
先前的图像到3d方法通常使用文本反转,优化速度极慢(几个小时),并且由于学习到的令牌数量有限,提供的纹理信息有限。其他调优技术,如Dreambooth,需要长时间的优化,并且倾向于过度拟合参考视图。此外,从标题模型中提取文本时,视觉语言歧义是一个常见的问题。为了解决这些问题,采用 IP-Adapter 将参考图像编码并投影到16个令牌的图像提示符中,这些令牌在预训练的文本到图像扩散模型中被输入到一个有效且轻量级的 cross-attention 适配器中。这为扩散模型执行无分类器指导以提高质量提供了视觉条件。
实验
Implementation Details
逐步将视点增加40度,并选择在30步内反转渲染图像。所有实验方法均采用Stable diffusion 1.5


