MIT-BEVFusion系列七--量化4 calibrate 标定与敏感层禁用(较重要)
目录
-
-
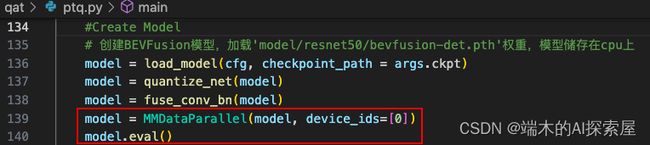
- 一、设置数据并行和评估模式
- 二、加速校准计算
- 三、校准模型
-
- 3.1 收集统计数据
-
- 3.1.1 禁用量化模式,启用校准模式
- 3.1.2 收集统计数据
-
- _input_quantizer
- _weight_quantizer
- 3.1.3 启用量化模式,禁用校准模式
- 3.2 计算最大值
-
- 对 calib.HistogramCalibrator 计算最大值
- 对 calib.MaxCalibrator 计算最大值
- 四、对敏感层的不进行量化
- 五、融合 lidar backbone 中的 ReLU
-
- 当前模块属于 SparseSequential 并且第一个子模块属于 SparseConvolution
- 当前模块属于SparseBasicBlock
- 储存 PTQ 操作之后的 BEVFusion 模型
- 总结:
-
本文书接上回,替换层、conv与bn融合后,就要开启标定了。
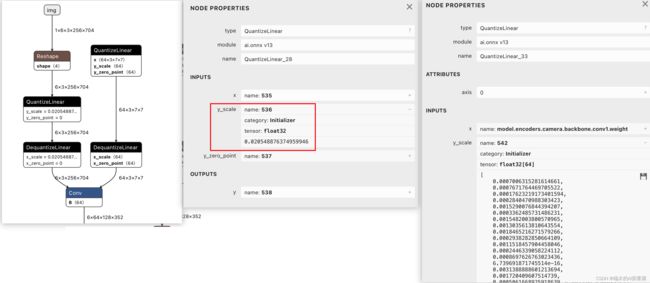
标定这个步骤的结果,就是得到如下图onnx中qdq节点中的scale数值。
一、设置数据并行和评估模式
二、加速校准计算


这里主要找到所有 _input_quantizer 和 _weight_quantizer,将 _input_quantizer 中的_calibrator._torch_hist 设置为 True,之后在校准时会使用 pytorch 进行直方图计算,如果使用默认值 False 的话,就会使用 numpy 来计算直方图。这里不会对 _weight_quantizer 进行修改,是因为 _weight_quantizer._calibrator 属于 calib.MaxCalibrator这个类。
三、校准模型

校准模型分为两个部分:
- 收集统计数据
- 计算绝对最大值
3.1 收集统计数据
- 收集的功能,封装在函数collect_stats中。

3.1.1 禁用量化模式,启用校准模式
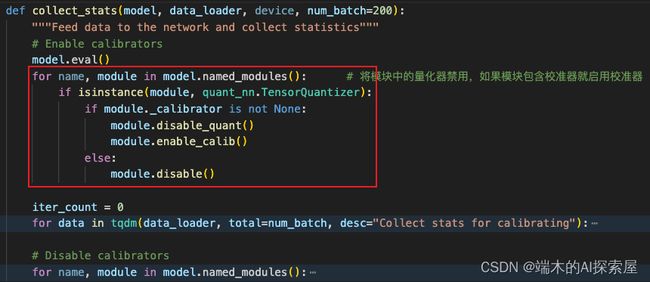
将模型切换到评估模式后,遍历模型中所有的子模块去寻找是否属于TensorQuantizer的子类。其实就是找量化层中的 _input_quantizer 和 _weight_quantizer,如果找到 _input_quantizer 和 _weight_quantizer,就将禁用量化模式(module.disable_quant),启用校准模式(module.enable_calib);

禁用量化模式就是将量化器中的 _if_quant 设置为 False。

启用校准模式就是将量化器中的 _if_calib 设置为 True。

这样在之后的 forward 中,就不会对数据进行量化操作,并且会收集数据用于校准。
3.1.2 收集统计数据
- 其实就是执行了模型的前向,因为
quantizer中的collect开关打开了,前向的过程已经不是输入数据,得到result这么简单了。而是输入数据,每个quantizer都会收集流转到这里的数据的动态范围。

_input_quantizer
-
通常
_input_quantizer创建时使用per-tensor加histogram的方式。即每个激活的量化器使用直方图的方式收集数据,最终计算出一个scale。 -
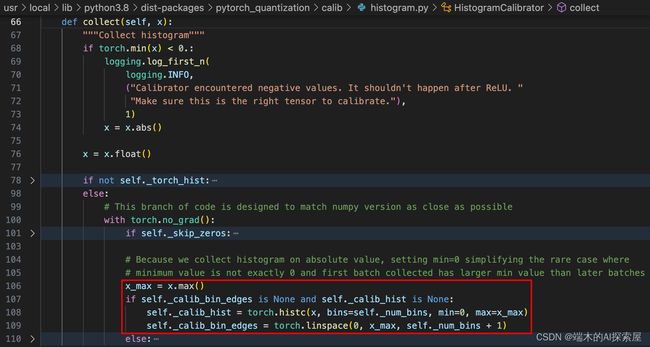
第一次使用模块中的
_input_quantizer收集数据时,量化器的校准器中并没有存储统计数据,即_calib_hist和_calib_bin_edges为None,在进行统计数据收集时,直接将统计结果赋值给_calib_hist,然后为_calib_bin_edges设置成一个长度为 2049 的张量,将0到输入数据x.max() 划分为 2049 个值。- 其含义为 2048 个 bin 的 2049 个边界,即直方图的边界。
-
这里的 self._num_bins 为 2048 是因为在初始化校准器时,默认设置的数值为 2048,是 tensorrt 默认设置的统计直方图时的 bin 的个数。
- 除了第一次收集数据时会从零创建直方图,后续收集数据会更新第一次创建的直方图。
- 更新直方图的最大值:
amax - 更新直方图的边界的数值:
_calib_bin_edges - 更新直方图的 bin 的个数:
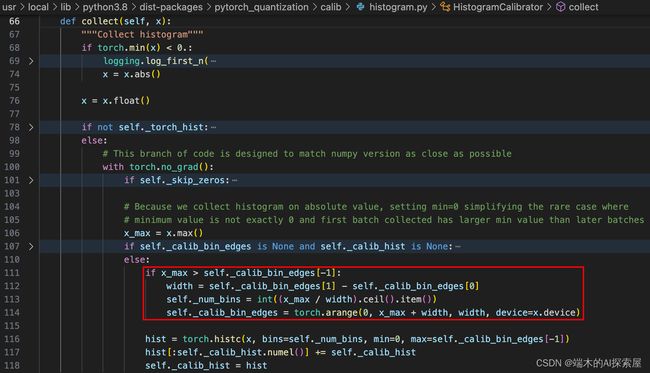
_num_bins - 111行判断当前数据的最大值与上一个统计的直方图的最大值哪个大。
- 113行在保证bins的
width没有变化的情况下计算出新的bins的数量。114行计算出边界。主要是 116-117 行代码,需要再原始的直方图 bin 的数值上,将前一次与本次的直方图数值进行累加。 - 如果这个模块中的
_input_quantizer收集过数据,会先判断当前数据的最大值是否超过直方图的最大范围,超过了的话就会维持之前每个 bin 的区间,去扩充 bin 的数量到可以包容到现在数据的最大值。

之后会将之前统计的结果与当前统计的结果相加保存到 _calib_hist 中。
_weight_quantizer
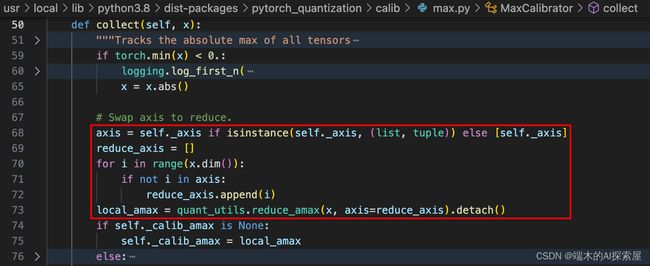
使用模块中的 _weight_quantizer 收集数据时,先根据指定 axis 找出局部最大值。
- 通常对于2d卷积的权重来说,因为形状通常是[O,I,KH,KW]的,并且采用
PER_CHANNEL的方式,所以通常指定axis为0,即最终计算得到O个(输出通道数量个)scale。
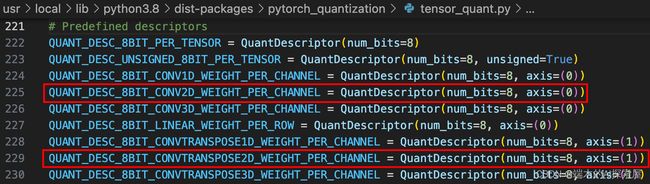

这个是对于 torch.nn 中一些常用的 module 的 weight 的量化描述器的配置,这里主要会使用针对 Conv2D 和 ConvTranspose2D 的量化描述器,针对 SparseConv 的量化描述器是自定义的,主要区别就是 axis 不同,这里值为4,通常对于SparseConv的权重,这个维度也是输出的维度,在之后统计 amax 时会根据这个 axis 来统计最大值。

这里就会遍历出了指定 axis 之外的所有维度,找出每个维度的最大值,这样最后就可以将其余维度的最大值保存在指定 axis 中,最后的形状会变成 [1, 1, 1, 1, ori]。

训练好的模型,权重是固定的。
_calib_amax用来储存权重最大值。
如果第一次使用 _weight_quantizer 的 _calibrator 来统计数据,即使用 dataloader 中的第一组数据放入 model 中进行前向,此时self._calib_amax是None(74行)那么会将局部最大值赋值给 _calib_amax(75行)。
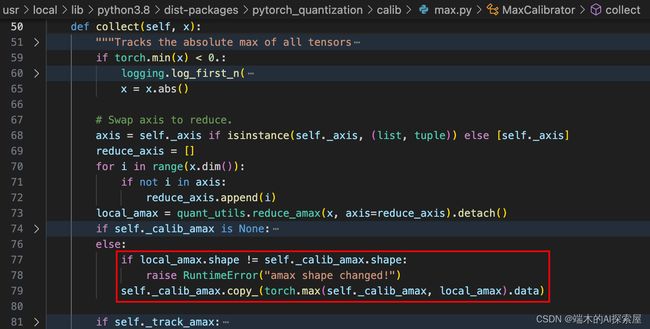
如果 _calib_amax 已经存在数值,那么会从 local_amax 和 _calib_amax 中简单判断下获取最大值,并保存到 _calib_amax 中,正常情况下因为模型权重是固定的,一般不会发生变化。
3.1.3 启用量化模式,禁用校准模式
收集好数据后,以卷积为例,对于输入数据,每个quantizer都记录到了一个直方图_calib_hist,而对于权重来说,都记录到了_calib_amax 。
此时关闭calib开关(364行),开启quan开关(363行)。
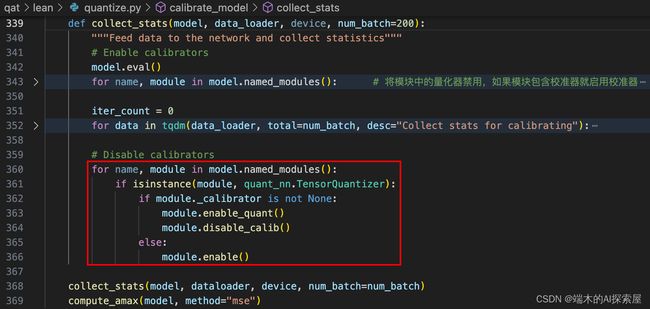
3.2 计算最大值
对 calib.HistogramCalibrator 计算最大值

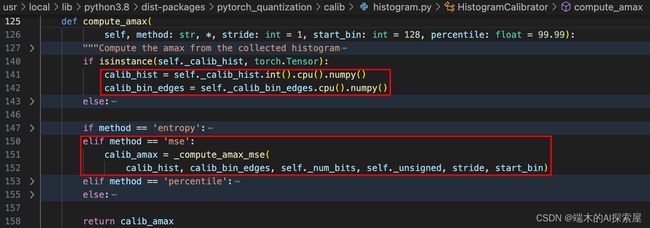
369 行 ,收集好数据后,开始计算amax,这里指定了方法是mse。
最终是在327行或者330行,调用自己的load_calib_amax去计算。
这里其实本质就是通过 quantizer 中的校准器来计算最大值,调用 _calibrator 中的 compute_amax 函数。
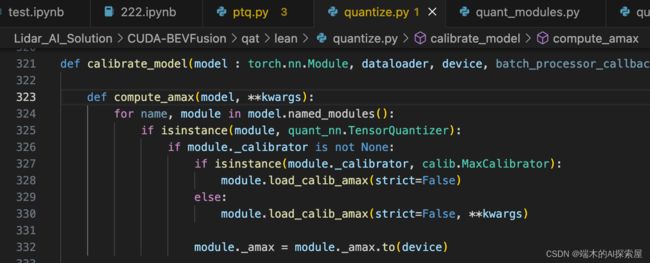
对于输入数据的统计来看,主要是走330行这个分支,调用直方图校准器的load_calib_amax方法
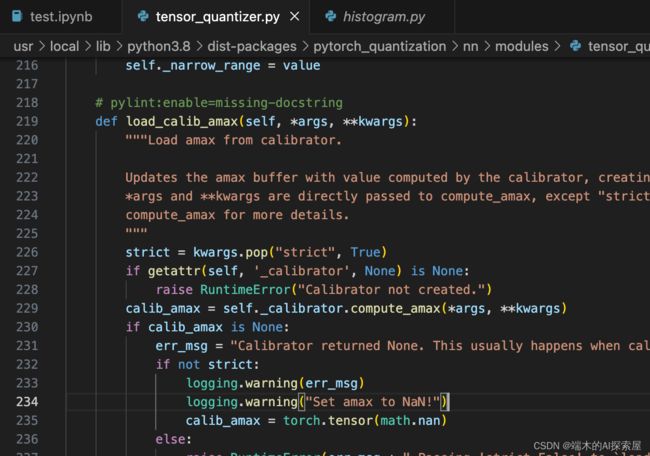
load_calib_amax方法内会调用self._calibrator.compute_amax
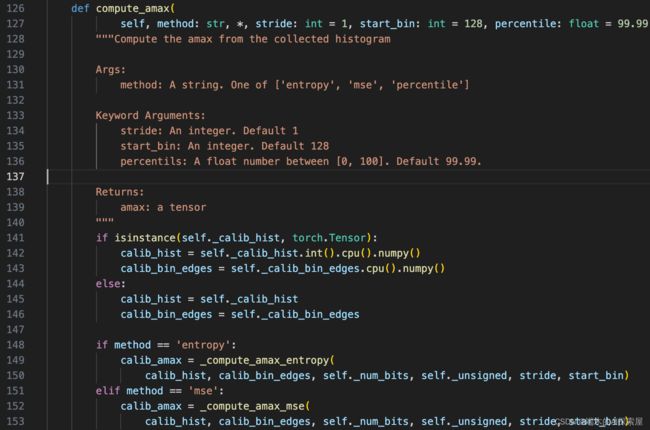
142 行得到直方图校准器中的直方图calib_hist,143行拿到bins的边界
HistogramCalibrator(num_bits=8 axis=None unsigned=False calib_bin_edges=tensor([0.0000e+00, 1.2891e-03, 2.5781e-03, ..., 2.6374e+00, 2.6387e+00,
2.6400e+00]) calib_hist=tensor([ 0., 0., 0., ..., 0., 0., 8679.], device='cuda:0'))
151行,走mse的分支,调用_compute_amax_mse,大概作用就是我们统计了所有训练集数据的分布,用直方图表示calib_hist表示,但我们最终需要的是从直方图中选取一个合适的最大值来作为输入数据的最大值,再去计算scale。
如何评价是否合适,就是选取多个候选值,分别把他们当成最大值,用mse的方式评估每个候选值的重投影误差,冲投影误差最小的作为真正选取的最大值。

264行,转换为 tensor
选用 mse (mean squared error) 进行数据校准。先将之前的统计数据与直方图边界转换为 tensor 和 float 类型,再通过边界计算每个 bin 的中点位置centers(266行)。
centers我们就是把centers中的值,作为标定的最大值calib_amax的候选值。
之后271行,就通过循环计算,从 128 到 2048,遍历第 128 之后的所有 bin,将当前 bin 的 center 作为 amax,在274行做fake_tensor_quant。
fake_tensor_quant中,大于amax的值都会作为异常值,大于 amax 的值在经过量化计算之后会被 clamp 操作根据最大最小值进行截断,这样原始数据大于 amax 的数值都会被设置为 127,在 dq 操作之后还原为与 amax 相近的数值。
之后计算 mse 的公式如下:
M S E = 1 n ∑ i = 128 2048 ( f a k e − o r i ) 2 ∗ w MSE = \frac{1}{n}\sum_{i=128}^{2048}(fake - ori)^2*w MSE=n1i=128∑2048(fake−ori)2∗w
276行,会根据 qdq 的结果与原始的数据计算它们之间的 mse,这里还会乘以一个权重 count 表示每个 bin 范围中的数据量,最终结果保存在 mses 中,当前 bin 的索引存储在 arguments 中。
在遍历完所有 bin 之后,挑选最小的 mse 数值对应的索引,并将对应的 bin 的 center 作为一个校准阈值。
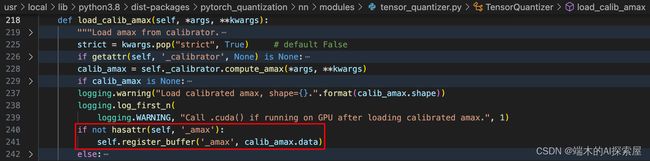
如果当前 _input_quantizer 不存在 _amax 这个属性的话,就在该模块中添加一个 buffer,buffer['_amax'] 中存储着 `calib_amax.data```。这个最大值是作用于整个张量的。

337行,最后将 _amax 移到设备上。
对 calib.MaxCalibrator 计算最大值
权重数据的_weight_quantizer通常用MaxCalibrator。
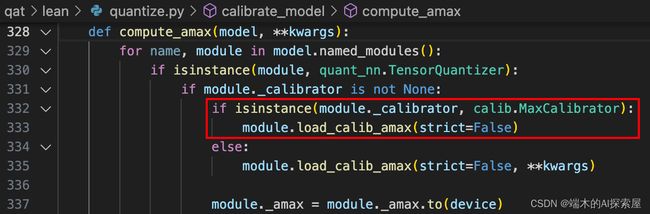
调用compute_amax

因为权重是固定的,amax就是标定的_calib_amax

_weight_quantizer 的最大值就是之前根据校准数据收集到的最大值,是根据每个通道来提取的最大值。
此时,对于input、weight来说,都有了_amax 属性,但是qdq节点要用的是scale属性。
这个是在导onnx的时候,quant开关会打开,会自己计算的。
首先会走346行
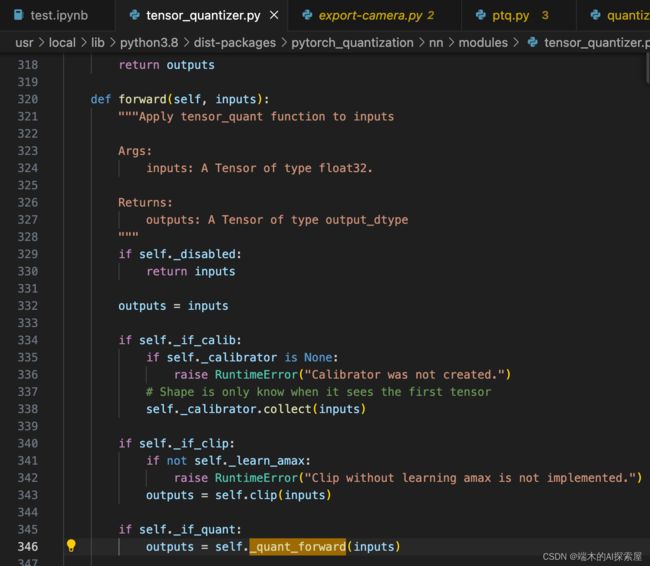
然后导出onnx时,通常会开启pytorch自己的fake_quant,代码里会走314行。

在这里就能看到scale时如何计算的了。

四、对敏感层的不进行量化
这里猜测是根据试验和指标,总结出哪些层量化误差会很大,因此直接禁用了这些层的量化。

![]()
这里对 lidar backbone 的第一层稀疏卷积和 decoder 中的 SECONDFPN 的第一个二维卷积取消量化操作。
-
147 行执行前后对比
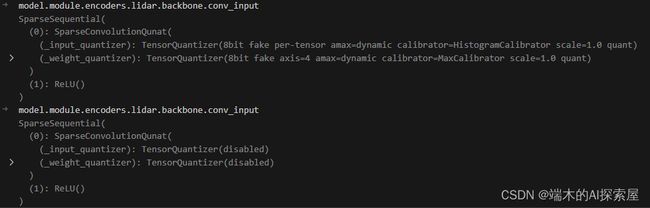
-
148 行执行前后对比
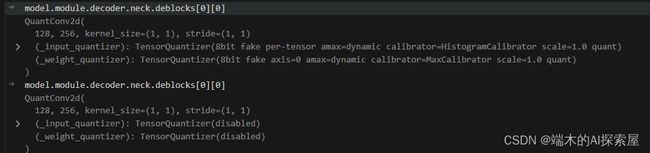
五、融合 lidar backbone 中的 ReLU
![]()
主要是将模块中的 SparseConvolutionQuant 与 ReLU 进行融合。
当前模块属于 SparseSequential 并且第一个子模块属于 SparseConvolution
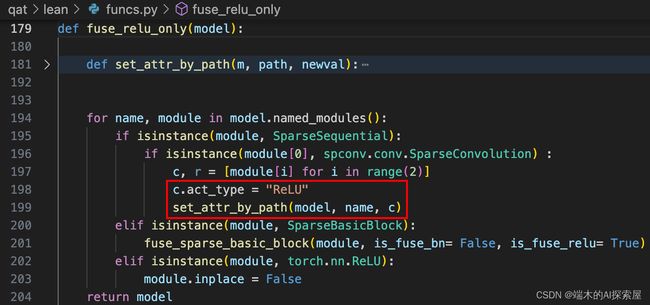
-
198-199 代码逻辑,因为稀疏卷积和 bn 已经融合过了,所以此时
SparseSequential内只有稀疏卷积SparseConvolutionQunat和ReLU两个层。 -
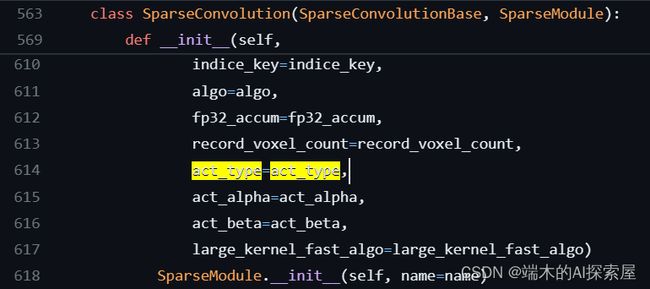
将量化的稀疏卷积模块的 act_type 属性设置为 “ReLU”
-
原始稀疏卷积就有
act_type这个属性。SparseConvolution 中可以设置参数,直接达到融合的效果。https://github.com/traveller59/spconv/blob/125a194d895b1bc3ad6ff907bc72641548397b32/spconv/pytorch/conv.py#L337
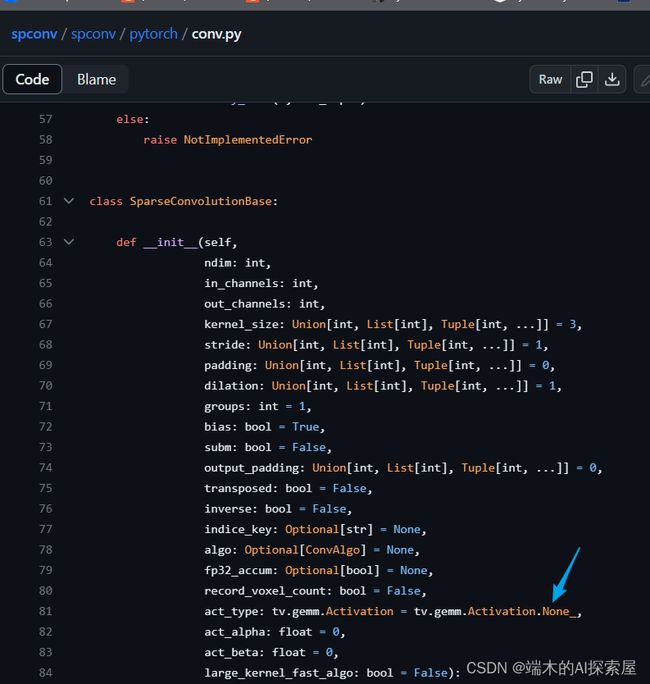
-
稀疏卷积的卷积操作调用
_conv_forward
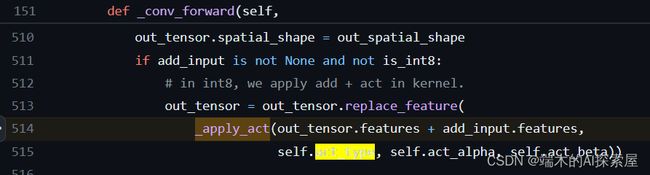
_conv_forward会调用_apply_act。其中 F 是 nn 的 function

-
-
过程
- 第一次递归
set_attr_by_path(model, name, c)- model:
SparseEncoder- 11Explain_Quantization2/6resnet.ipynb
- name:
'conv_input' - c:
- model:
- 第一次递归
SparseConvolutionQunat(
(_input_quantizer): TensorQuantizer(disabled)
(_weight_quantizer): TensorQuantizer(disabled)
)
- return 调用`set_attr_by_array(m, path.split("."))`
- m:`SparseEncoder`
- path:`'conv_input'`
- 执行`set_attr_by_array(parent, arr)`
- parent:`SparseEncoder`
- arr:`['conv_input']`
-
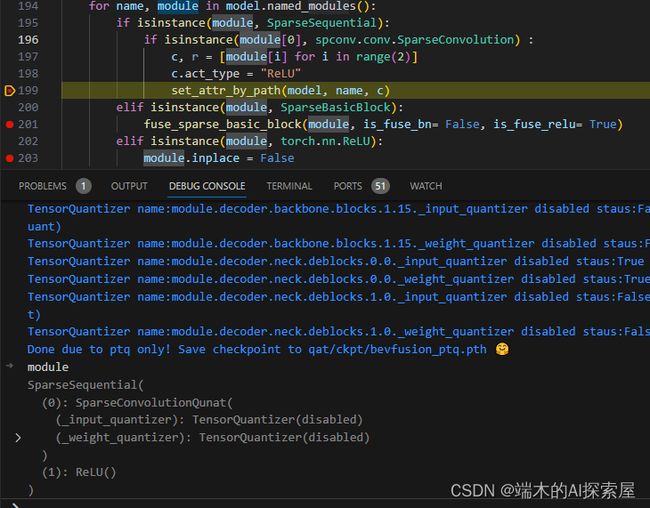
修改前后对比
-
最原始:

-
conv与bn融合后
-
conv与ReLU融合后

-
-
结果
- 使用了setattr()将
conv_input从SparseSequential替换为SparseConvolutionQuant SparseConvolutionQuant中act_type属性设置为"ReLU"- 原先的
ReLU()层被取消。但是inpalce属性仍会设置为False
- 使用了setattr()将
当前模块属于SparseBasicBlock
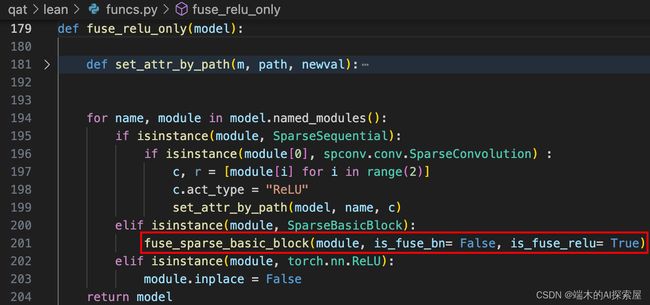
- 会调用如下函数
fuse_sparse_basic_block
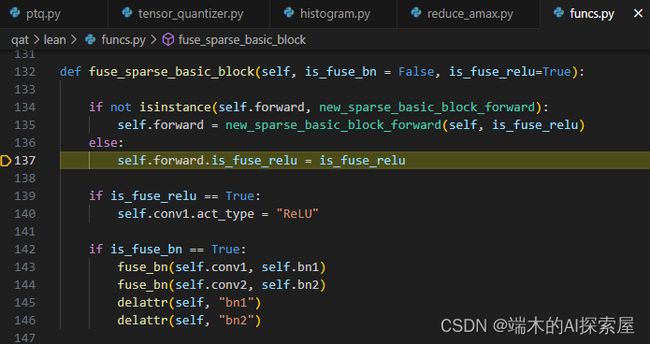
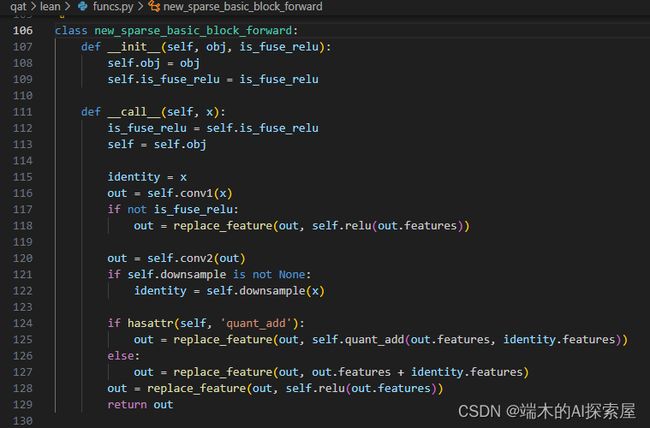
new_sparse_basic_block_forward

最原始的SparseBasicBlock的forward
-
将替换后的
new_sparse_basic_block_forward的初始化的is_fuse_relu属性置为True。- 这么做,等到
new_sparse_basic_block_forward的forward时就不会执行ReLU操作

- 这么做,等到
-
block 中的第一个 SparseConvolutionQuant 的 act_type 属性设置为 “ReLU”
- ps:forward是在融合bn时替换的。
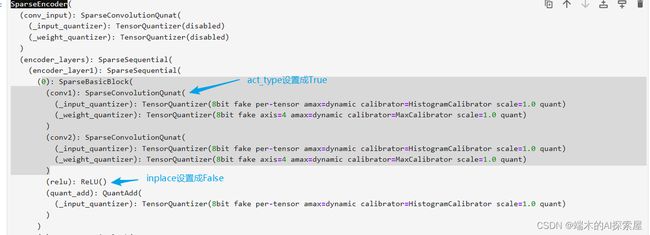
- ps:forward是在融合bn时替换的。
-
原先的ReLU()设置为False
储存 PTQ 操作之后的 BEVFusion 模型

PTQ 量化之后的模型储存为 qat/ckpt/bevfusion_ptq.pth。
总结:
-
在默认的 _DEFAULT_QUANT_MAP 中添加了 ConvTranspose2d 的量化模块,并为所有在 _DEFAULT_QUANT_MAP 中的量化模块设置输入量化器的描述器,主要是设置校准方法为 histogram。
-
生成训练数据的 dataset和 dataloader加载模型和预训练权重。标定时使用
data_loader_train训练数据标定。 -
对模型进行量化,主要对 lidar.backbone、camera、fuser、decoder 进行了量化
- 对 lidar.backbone 进行量化需要自定义一个针对稀疏卷积的量化模块 SparseConvolutionQuant,与原生的稀疏卷积模块的区别在于添加了对输入和权重的量化描述器(QuantDescriptor),输入的校准方法为 histogram,权重的量化维度设为 4,前向操作中会先对输入和权重通过对应的量化器进行前向,然后进行原生的稀疏卷积模块的前向。
- 先将 lidar.backbone 中的所有 spconv.SubMConv3d 和 spconv.SparseConv3d 模块替换为 SparseConvolutionQuant 模块,并将原来模块中的所有属性赋值到这个量化模块中,之后通过前面提到输入和权重的量化描述器创建输入与权重的量化器。
- lidar.backbone 中的所有 SparseBasicBlock 模块中添加了自定义的 QuantAdd 模块,用于替换原来的残差操作,主要是对输入使用相同的输入量化器,用于保证输入具有相同的精度,防止出现 reformat 的情况。
- forward替换为new_sparse_basic_block_forward。方便后续融合bn与relu。
- 对 camera 中的 backbone (Resnet50)、neck (FPN) 和 vtransform (Downsample) 进行了量化。
- 遍历 camera.backbone 中的所有子模块,如果当前模块属于的类的对象在 _DEFAULT_QUANT_MAP 的 orig_mod 中,那么就会将这个模块替换为相应的量化模块,主要是将 nn.Conv2d 替换为 quant_nn.QuantConv2d。
- 对 camera.backbone 中的 Bottleneck 模块中的残差结构也需要对精度对齐,其中包含了具有 Downsample 模块时进行加法和不具有 Downsample 模块时进行加法这两种情况。Resnet50 中的 4 个层,分别包含 3、4、6、3 个 Bottleneck 模块。
- 对 camera.neck 量化的话也是遍历所有子模块,将其中的 nn.Conv2d 替换为了 quant_nn.QuantConv2d,然后在 camera.neck 中添加了两个属性用于存储 QuantConcat,并替换了整个模块的 forward 函数,最主要的区别就是将原来的 Concat 操作替换为了 QuantConcat 操作。
- 对 camera.vtransform 量化就是对其中的 dtransform 和 depthnet 这两个模块进行量化,具体来说就是将其中的 nn.Conv2d 模块替换为 quant_nn.QuantConv2d 模块。
- 最后手动对 camera.backbone 的 3 个输出在 camera.neck 中进行拼接时的量化器设置为相同的。
- 对 model.fuser 的量化是将其中的 nn.Conv2d 替换为 quant_nn.QuantConv2d。
- 对 model.decoder 的量化时将其中的 nn.Conv2d 替换为 quant_nn.QuantConv2d,nn.ConvTranspose2d 替换为 quant_nn.QuantConvTranspose2d。
-
对 lidar.backbone 应用 SparseConvolution 与 bn 融合的操作,权重shape维度变化。
-
模型进入eval()模式,使用训练集进行calibrate操作。
-
敏感层分析没有在这里做,但是结论是需要将
model.module.encoders.lidar.backbone.conv_input与model.module.decoder.neck.deblocks[0][0]禁用量化。 -
最后融合conv-relu
通常会使用闭包特性来实现递归操作。
def quantize_sparseconv_module(model):
def replace_module(module, prefix=""):
for name in module._modules:
submodule = module._modules[name]
submodule_name = name if prefix == "" else prefix + "." + name
replace_module(submodule, submodule_name)
if isinstance(submodule, spconv.SubMConv3d) or isinstance(submodule, spconv.SparseConv3d):
module._modules[name] = transfer_spconv_to_quantization(submodule, SparseConvolutionQunat)
replace_module(model)