工作流系统之三十七 自由流的实现(续)
工作流系统的自由流实现了不按照流程预定义的轨迹流转,即需要在节点之间任意的跳转。上一篇自由流的实现主要说明了跳转规律,如果是单节点间的跳转,只要有当前的节点,以及跳转到的节点,就ok了。但是当当前节点和任意跳转到的节点之间有分支并发线路后,就不是简单的跳转了,当分支套分支,分支主干等之间的跳转就更复杂了。

如果是这种串行路由,就很简单了。

但是这样的多路分支,分支嵌套分支的,就很复杂了。
因此在实现的时候,必需找出,当前节点到跳转到的节点之间的轨迹线路。又因为分支之间是可以嵌套的,所以必需用递归来遍历这之间的轨迹。
由当前节点开始,查找这个节点的动作结果节点是否为跳转到的节点,如果是,则找到之间的轨迹,返回。
如果不是,则将当前这个节点的动作结果节点作为当前节点,继续调用这个函数,查找,直到找到后退出。
因为流程定义的轨迹,可以是循环的轨迹,即一个节点的动作结果可以返回到前面的节点,如:
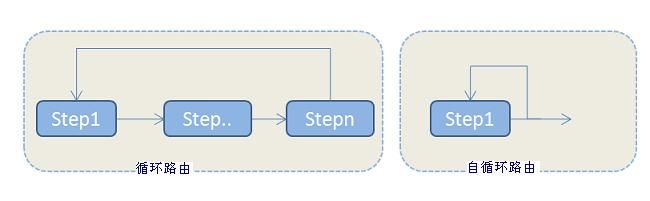
当返回到前面的节点时,用递归调用的话,就永远也退不出循环了。因此,将处理过的节点放到traceNodeList中,每次调用递归函数前,均判断一下,此节点是否在traceNodeList中,如果在,就不用处理了。不在的继续处理。
eworkflow自定义工作流系统有.net版和java版,两个版本的实现过程完全一样,只是一个是c#语言的一个是java语言的。
c#的递归函数:
private ArrayList getJoinsAndSplitsBwteenStep(WorkflowDescriptor wd,IDictionary orgNodeMap,ResultDescriptor theResult,ArrayList traceNodeList)
{
ArrayList tagList = new ArrayList();
string nodeType =(System.String)orgNodeMap["node_type"];
AbstractDescriptor node = (AbstractDescriptor)orgNodeMap["node"];
ArrayList results = new ArrayList();
if (nodeType.Equals("join"))
{
JoinDescriptor join = (JoinDescriptor)node;
results.Add(join.Result);
}
if (nodeType.Equals("split"))
{
SplitDescriptor split = (SplitDescriptor)node;
results.AddRange(split.Results);
}
if (nodeType.Equals("subflow"))
{
SubflowDescriptor subflow = (SubflowDescriptor)node;
results.Add(subflow.unconditionalResult);
results.AddRange(subflow.conditionalResults);
}
if (nodeType.Equals("step"))
{
StepDescriptor step = (StepDescriptor)node;
ArrayList actions = step.actions;
for (IEnumerator iter = actions.GetEnumerator();iter.MoveNext();)
{
ActionDescriptor action =(ActionDescriptor)iter.Current;
ResultDescriptor result = action.UnconditionalResult;
results.Add(result);
results.AddRange(action.ConditionalResults);
}
}
bool bFind=false;
for (IEnumerator it = results.GetEnumerator();it.MoveNext();)
{
ResultDescriptor result = (ResultDescriptor)it.Current;
if (result.Id==theResult.Id)
{//找到跳转到的节点,退出
bFind = true;
break;
}
}
if (bFind) return tagList;
//将当前处理节点 存入traceNodeList中
traceNodeList.Add(node);
for (IEnumerator iterator = results.GetEnumerator();iterator.MoveNext();)
{
ResultDescriptor resultDesc = (ResultDescriptor)iterator.Current;
int joinid = resultDesc.join;
int splitid = resultDesc.Split;
int stepid = resultDesc.Step;
int subflowid = resultDesc.subflow;
int traceid = 0;
IDictionary orgMap = new Hashtable();//记录节点信息
if (joinid>0)
{
IDictionary m = new Hashtable();
m["join"] = joinid;//new Integer(joinid);
tagList.Add(m);
JoinDescriptor join = wd.getJoin(joinid);
orgMap["node_type"] = "join";
orgMap["node"] = join;
traceid = joinid;
}
if (splitid>0)
{
SplitDescriptor split = wd.getSplit(splitid);
orgMap["node_type"] = "split";
orgMap["node"] = split;
IDictionary m = new Hashtable();
m["split"] = splitid;// new Integer(splitid));
for (int i=0;i<split.Results.Count;i++)
{
tagList.Add(m);
}
traceid = splitid;
}
if (stepid>0)
{
StepDescriptor step = wd.getStep(stepid);
orgMap["node_type"] = "step";
orgMap["node"] = step;
traceid = stepid;
}
if (subflowid>0)
{
SubflowDescriptor subflow = wd.getSubflow(subflowid);
orgMap["node_type"] = "subflow";
orgMap["node"] = subflow;
traceid = subflowid;
}
//判断 关联到的节点 是否处理过
bool inTrace = false;
for (IEnumerator itrace=traceNodeList.GetEnumerator();itrace.MoveNext();)
{
AbstractDescriptor trace = (AbstractDescriptor)itrace.Current;
if (trace.Id==traceid)
{//已经处理过的了
inTrace = true;
break;
}
}
if (!inTrace)
tagList.AddRange(getJoinsAndSplitsBwteenStep(wd,orgMap,theResult,traceNodeList));
}
return tagList;
java的递归函数:
private List getJoinsAndSplitsBwteenStep(WorkflowDescriptor wd,Map orgNodeMap,ResultDescriptor theResult,List traceNodeList) throws WorkflowException{
List tagList =new ArrayList();
String nodeType =(String)orgNodeMap.get("node_type");
AbstractDescriptor node = (AbstractDescriptor)orgNodeMap.get("node");
List results = new ArrayList();
if (nodeType.equals("join")){
JoinDescriptor join = (JoinDescriptor)node;
results.add(join.getResult());
}
if (nodeType.equals("split")){
SplitDescriptor split = (SplitDescriptor)node;
results.addAll(split.getResults());
}
if (nodeType.equals("subflow")){
SubflowDescriptor subflow = (SubflowDescriptor)node;
results.add(subflow.getUnconditionalResult());
results.addAll(subflow.getConditionalResults());
}
if (nodeType.equals("step")){
StepDescriptor step = (StepDescriptor)node;
List actions = step.getActions();
for (Iterator iter = actions.iterator();iter.hasNext();){
ActionDescriptor action =(ActionDescriptor)iter.next();
ResultDescriptor result = action.getUnconditionalResult();
results.add(result);
results.addAll(action.getConditionalResults());
}
}
boolean bFind=false;
for (Iterator it = results.iterator();it.hasNext();){
ResultDescriptor result = (ResultDescriptor)it.next();
if (result.getId()==theResult.getId()){//找到跳转到的节点,退出
bFind = true;
break;
//return tagList;
}
}
if (bFind) return tagList;
//将当前处理节点 存入traceNodeList中
traceNodeList.add(node);
for (Iterator iterator = results.iterator();iterator.hasNext();){
ResultDescriptor resultDesc = (ResultDescriptor)iterator.next();
int joinid = resultDesc.getJoin();
int splitid = resultDesc.getSplit();
int stepid = resultDesc.getStep();
int subflowid = resultDesc.getSubflow();
int traceid = 0;
Map orgMap = new HashMap();//记录节点信息
if (joinid>0){
Map m = new HashMap();
m.put("join", new Integer(joinid));
tagList.add(m);
JoinDescriptor join = wd.getJoin(joinid);
orgMap.put("node_type", "join");
orgMap.put("node", join);
traceid = joinid;
}
if (splitid>0){
SplitDescriptor split = wd.getSplit(splitid);
orgMap.put("node_type", "split");
orgMap.put("node", split);
Map m = new HashMap();
m.put("split", new Integer(splitid));
//tagList.add(m);
for (int i=0;i<split.getResults().size();i++){
tagList.add(m);
}
traceid = splitid;
}
if (stepid>0){
StepDescriptor step = wd.getStep(stepid);
orgMap.put("node_type", "step");
orgMap.put("node", step);
traceid = stepid;
}
if (subflowid>0){
SubflowDescriptor subflow = wd.getSubflow(subflowid);
orgMap.put("node_type", "subflow");
orgMap.put("node", subflow);
traceid = subflowid;
}
//判断 关联到的节点 是否处理过
boolean inTrace = false;
for (Iterator itrace=traceNodeList.iterator();itrace.hasNext();){
AbstractDescriptor trace = (AbstractDescriptor)itrace.next();
if (trace.getId()==traceid){//已经处理过的了
inTrace = true;
break;
}
}
if (!inTrace)
tagList.addAll(getJoinsAndSplitsBwteenStep(wd,orgMap,theResult,traceNodeList));
}
return tagList;
}