MapReduce原理
我们为什么要关注 MapReduce?
1 .什么是MapReduce?
MapReduce 是由Google公司的Jeffrey Dean 和 Sanjay Ghemawat 开发的一个针对大规模群组中的海量数据处理的分布式编程模型。MapReduce实现了两个功能。Map把一个函数应用于集合中的所有成员,然后返回一个基于这个处理的结果集。而Reduce是把从两个或更多个Map中,通过多个线程,进程或者独立系统并行执行处理的结果集进行分类和归纳。Map() 和 Reduce() 两个函数可能会并行运行,即使不是在同一的系统的同一时刻。
Google 用MapReduce来索引每个抓取过来的Web页面。它取代了2004开始试探的最初索引算法,它已经证明在处理大量和非结构化数据集时更有效。用不同程序设计语言实现了多个MapReduce,包括 Java, C++, Python, Perl, Ruby和C, 其它语言。在某些范例里,如Lisp或者Python, Map() 和Reduce()已经集成到语言自身的结构里面。通常,这些函数可能会如下定义:
List2 map(Functor1, List1);
Object reduce(Functor2, List2);
Map()函数把大数据集进行分解操作到两个或更多的小“桶”。而一个“桶”则是包含松散定义的逻辑记录或者文本行的集合。每个线程,处理器或者系统在独立的“桶”上执行Map()函数,去计算基于每个逻辑记录处理的一系列中间值。合并的结果值就会如同是单个Map()函数在单个“桶”上完全一致。Map()函数的通常形式是:
map(function, list) {
foreach element in list {
v = function(element)
intermediateResult.add(v)
}
} // map
Reduce()函数把从内存,磁盘或者网络介质提取过来的一个或多个中间结果列表,对列表中的每个元素逐一执行一个函数。完成操作的最终结果是通过对所有运行reduce()操作的处理结果进行分类和解释。Reduce()函数的通常形式是:
reduce(function, list, init) {
result = init
foreach value in list {
result = function(result, value)
}
outputResult.add(result)
}
MapReduce的实现把业务逻辑从多个处理逻辑中分离出来了,map()和reduce()函数跨越多个系统,通过共享池和部分RPC的形式来达到彼此之间的同步和通信。这里的业务逻辑是由用户自定义的函数子实现,并且这些函数子只能用在逻辑记录处理的工作上,而不用关心多个处理操作的问题。这样一旦MapReduce框架就位,就能通过大量的处理器快速的转变为应用系统的并行处理。因为开发人员可以把精力花在写函数子上面了。MapReduce簇可以通过替换函数子和提供新的数据源来重新使用,而无需每次都对整个应用进行编译,测试和部署。
2 .实现MapReduce
MapReduce()的目的是为了大型集群的系统能在大数据集上进行并行工作。
图1显示了一个运行在一个主系统上的主程序,协调其它实例进行map()或者reduce()操作,然后从每个reduce操作中收集结果。
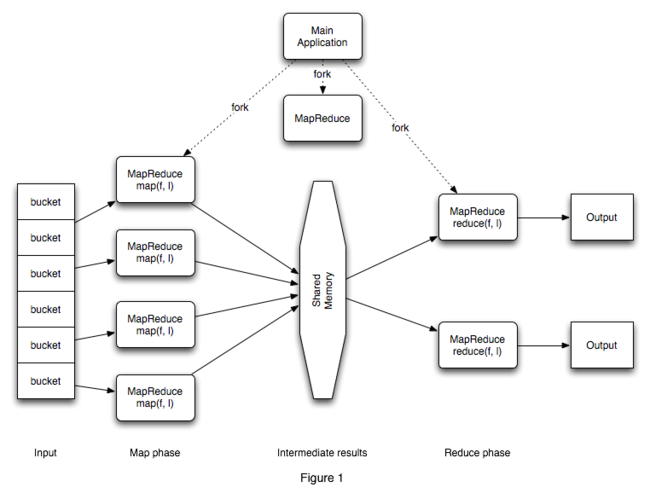
【图 1】
主应用程序负责把基础的数据集分解到“桶”中。桶的最佳大小依赖于应用,结点的数量和可用的I/O带宽。这些“桶”通常存储在磁盘,但有必要也可能分散到主存中,这依赖于具体的应用。“桶”将作为map()函数的输入。
主应用程序也负责调度和分散几个MapReduce的核心备份,除了控制者给空闲的处理器或线程分配了调整map()和reduce()任务之外,它们是完全相致的。控制者会持续跟踪每个map()和reduce()任务的状态,并且可以作为map()和reduce()任务之间路由中间结果的管道。每个map() 任务处理器完全指派给“桶”,然后产生一个存到共享存储区域的中间结果集。共享存储可以设计成分布缓存,磁盘或其它设备等形式。当一个新的中间结果写入共享存储区域后,任务就向控制者发出通知,并提供指向其共享存储位置的句柄。
当新的中间结果可用时,控制者分配reduce()任务。这个任务通过应用独立的中间键值来实现排序,使相同的数据能聚集在一起,以提供更快的检索。大块的结果集可以进行外部排序,reduce()任务遍历整个排序的数据,把每个唯一的键和分类的结果传递到用户的reduce() 函数子进行处理。
通过map()和reduce()实例终端的处理,当所有的“桶”都用完,然后全部的reduce()任务就通知控制者,以说明它们的结果已经产生了。控制者就向主应用程序发出检索这个结果的信号。主应用程序可能就直接操作这些结果,或者重新分配到不同的MapReduce控制者和任务进行进一步的处理,
显示情况下MapReduce的实现可能通常分配给控制者,map()和reduce()任务分配给单独的系统。Google操作模型是基于跨越大量的廉价硬件设备上组成的集群或者白盒子上面部署MapReduce应用。为了处理它自己的桶的需要,每个白盒子都有本地存储装置,一个合理数量的私有内存(2到4GB RAM)和至少两个处理内核。白盒子是可互相交换的,主应用程序可能把集群中的任何机器指派为控制者,而这个机器就把map()和reduce()任务分派给其它连接的白盒子。
3 .基于Java 的MapReduce 实现
Google的环境是为它自己的需求定制和适应它们的操作环境。比如,为了它的MapReduce实现更好的执行这种类型的操作,使其更优化,Google使用了专有的文件系统用来存储文件。相反,企业应用系统都是建立在Java或类似的技术上面的,它们依赖于已有的文件系统,通信协议和应用栈。
一个基于Java的MapReduce实现应该考虑到已存在的数据存储设备,将来部署到的结构里面支持那种协议,有哪些内部API和支持部署那种第三方产品(开源的或商业的)。图2显示了通常的架构是如何通过映射到已有的、健壮的Java开源架构来实现的。

【图 2】
这个架构采用了已有的工具,比如Terracotta和Mule,它们经常出现在很多企业系统的组织里面。已物理或虚拟系统形成存在的白盒子通过有效简单的配置和部署,设计成MapReduce群组中的一部分。为了效率,一个很大的系统可以分解到几个虚拟机器上,如果需要可以分配更多的结点。可以根据容量的问题和处理器的有效利用赖决定是否在群集中使用物理“白盒子”,虚拟机或者它们两者的结合。
Terracotta 集群技术是map()和reduce()任务之间共享数据的很好选择,因为它把map()和reduce()之间的通信过程,包括共享文件或者使用RPC调用已初始处理结构都做了抽象。
从前面章节的描述知道,Map()和reduce()任务是在同一个核心应用中实现的。用来共享中间结构集的数据结构可以保持在内存的数据结构中,通过Terracotta透明的共享交换。
由跨域集群的MapReduce产生的进程内通信问题,自从Terracotta运行时掌管着这些共享数据结构后就不存在了。不同于实现一个复杂的信号系统,所有的map()任务需要标记内存中的中间结构集,然后reduce()任务就直接提取它们。
控制者和主应用程序都会在同时处在等待状态一段时间,即使是MapReduce集群有大量可用的并行处理能力。这两个组件之间以及当归并完成后的reduce()任务和控制者之间,都是通过Mule的ESB传递信号的。通过这种方式,为了其它应用的处理,输出结构可以排到队列,或者像前面章节讲的一样,为了其他MapReduced的处理,一个Mule服务对象(or UMO)可以把这些输出结果分解到“桶”中。
通过主流的企业应用协议或者完全的原始TCP/IP Sockets,Mule支持在内存中进行同步和异步的数据传输. Mule可以用于在同一台机器执行的应用系统,跨域不同的数据中心或者在完全不同地方且被程序员分开标识的本地终端结点互相传递输出结构集。其它基于Java的实现可以通过Hadoop, 是一个用于运行应用程序在大型集群的廉价硬件设备上的框架, 它是基于lucene框架。Hadoop是一个开源,点对点,通用的MapReduce实现。
4. 结论
不管使用什么技术,索引大量非结构化数据是一件很艰难的任务。应用传统的算法和启发式方法很难维护,因为随着时间的推移,系统的性能下降使系统变得难以控制。RDBMS 能有效的用于索引和检索大量的结构化数据集合,但不适合用于非结构化的数据。MapReduce为并行系统的数据处理,提供了一个简单,优雅的解决方案,优势有:
l 归并成本
l 程序员的高产出,因为用并行的代码独立实现了业务逻辑
l 比传统RDBMS技术更好的性能和更优的结果。
l 使用Java企业框架和开发人员都熟悉的已有的技术和工具更易部署
用MapReduce, Google有令人印象深刻的跟踪记录,而且每天出现的工具都能轻易的融入到这个体系中。在企业级的应用系统中,如果你准备开始一个快速,简单的任务,例如根据IP地址分析请求的拥堵模型到你的web集群中,或者类似的东西。一个这样的练习将会很大程度上提高你对关键系统面临的问题和挑战的认识,MapReduce则就是为这些而准备的。
英文原址: http://www.theserverside.com/tt/knowledgecenter-tc/knowledgecenter-tc.tss?l=MapReduce