1. 网页快照乱码解决方法
修改nutch\cached.jsp,
将content = new String(bean.getContent(details))
修改为content = new String(bean.getContent(details),"utf-8")

在画红框的地方加上UTF-8即可
以下内容参考:http://blog.csdn.net/xiaomage_cn/archive/2010/07/13/5731112.aspx进行总结
如果改为UTF-8后如果为gb2312、gbk等页面将会出现乱码
然后还有一些文章是对Metadata修改parseDate的contentmeta来实现获取正确的编码方式,这个思路是非常正确的,但是还是有一点问题,仍然会存在一些gb2312的页面出现乱码,下面对网页快照乱码进行最终的一个简单的解决办法:
修改cache.jsp如下:

上面画红框的是修改后的内容
蓝框是原始内容
ParseData ParseData = bean.getParseData(details);
String content = null;
String contentType = ParseData.getMeta(Metadata.CONTENT_TYPE);
if (contentType.startsWith("text/html")) {
// FIXME : it's better to emit the original 'byte' sequence
// with 'charset' set to the value of 'CharEncoding',
// but I don't know how to emit 'byte sequence' in JSP.
// out.getOutputStream().write(bean.getContent(details)) may work,
// but I'm not sure.
String encoding = ParseData.getMeta("CharEncodingForConversion");
if (encoding != null) {
try {
content = new String(bean.getContent(details), encoding);
}
catch (UnsupportedEncodingException e) {
// fallback to windows-1252
content = new String(bean.getContent(details), "windows-1252");
}
}
else
content = new String(bean.getContent(details),"GBK");
}
2. 网页快照图片、链接等内容不对[h1]
修改nutch\cached.jsp,

将这里的url改成域名
下面是修改好的代码:
<%
//通过url截取url域名
String urlnew = details.getValue("url");
int httplen = urlnew.indexOf(':')+3;
String b=urlnew.substring(httplen);
int domainlen=b.indexOf("/");
String domain=urlnew.substring(0,domainlen+httplen);
%>
<base href="<%=domain%>">
只需要将上面的代码替换为下面的代码即可
3. nutch网页快照无法查看
点击搜索到的网页快照后,报如下错误
Display of this content was administratively prohibited by the webmaster.
You may visit the original page instead:
http://forum.laopdr.gov.la/forums/list.page.
是因为在页面中有:
<meta http-equiv="pragma" content="no-cache">
<meta http-equiv="cache-control" content="no-cache">
这2行代码
去掉后就可以了
4. Nutch抓取动态页面
在nutch/conf/crawl-urlfilter.txt中,修改

将
-[?*!@=] //表示过滤包含指定字符的URL
修改为:
-[~]
或者注释掉
#-[?*!@=]
5. Nutch 爬取动态内容去重复
比如index.jsp是入口页:
<a href="11.jsp?id=1">11_1</a>
<br>
<a href="11.jsp?id=3">11_3</a>
<br>
<a href="11.jsp?id=4">11_4</a>
<br>
<a href="11.jsp?id=5">11_5</a>
<br>
<a href="11.jsp?id=2">11_2</a>
其中11.jsp中,针对id参数:
<%
String id=request.getParameter("id");
if(id.equals("1")){
out.println("1111111111111");
}
%>
当id为1时,11.jsp是一种内容
当id为其他值时,11.jsp是一种内容
所以11.jsp只有上述2种内容
当爬取时,会将index.jsp中的5个链接全部爬取
但是其中id为2-5的内容是一样的,所以只取2的(排序后的结果)
所以在爬取后只有id=1和id=2的2种动态页面结果
所以nutch在生成索引时就只生成id=1的和id=2的这2个文档(document),
把其他(3-5)的重复的就给去掉,不生成文档
6. 改变摘要长度
在nutch的web项目的/classes/nutch-site.xml中,加入如下内容:
<property>
<name>searcher.summary.length</name>
<value>50</value>//默认为20
<description>
The total number of terms to display in a hit summary.
</description>
</property>
加入内容后,重启tomcat,我们在浏览器中搜索信息,会发现摘要的内容变长了。

红色框位置标注的就是摘要内容
7. 将本地urls复制到hadoop中出现错误解决方法
当执行下列语句报如下错误时:
[nutch@jdodrc bin]$ ./hadoop dfs -copyFromLocal /home/nutch/nutch-1.2/urls urls
copyFromLocal: java.io.IOException: File /user/nutch/urls/jdodrc could only be replicated to 0 nodes, instead of 1
报如上错误可知道node节点那里是0,是配置上出现了问题
那么我们下面用jps查一下进程状态:
首先查看namenode:
[nutch@jdodrc bin]$ jps
8758 NameNode
13554 Jps
9401 SecondaryNameNode
8984 JobTracker
这说明namenode是正确的,没有问题
下面我们看datanode
[nutch@jdodrc conf]$ jps
21898 Jps
这里只有 一个,说明没有启动起来
然后我仔细检查了一下问题,发现是我只配置了namenode的内容,而没有配置datanode的内容
所以把namenode节点的文件copy到datanode中重新启动则正常了,那么具体有哪些文件呢?
$NUTCH_HOME/bin/ hadoop-env.sh
$NUTCH_HOME /conf/ core-site.xml
$NUTCH_HOME /conf/ hdfs-site.xml
$NUTCH_HOME /conf/ mapred-site.xml
$NUTCH_HOME /conf/ masters
$NUTCH_HOME /conf/ slaves
将namenode节点中的这些配置好的内容copy到datanode节点就ok了
那么我们首先把hadoop的filesystem清空,重新配置一遍
[nutch@jdodrc ~]$ cd filesystem/
[nutch@jdodrc filesystem]$ dir
hadooptmp name
[nutch@jdodrc filesystem]$ rm -rf *
[nutch@jdodrc filesystem]$ dir
[nutch@jdodrc filesystem]$ cd ..
[nutch@jdodrc ~]$ cd nutch-1.2/
[nutch@jdodrc nutch-1.2]$ cd bin
[nutch@jdodrc bin]$ ./hadoop namenode –format //首先格式化
[nutch@jdodrc bin]$ ./start-all.sh //启动所有机器,下面是启动的信息
starting namenode, logging to /home/nutch/nutch-1.2/bin/../logs/hadoop-nutch-namenode-jdodrc.out
hadoop2: starting datanode, logging to /home/nutch/nutch-1.2/bin/../logs/hadoop-nutch-datanode-jdodrc.out
hadoop1: starting secondarynamenode, logging to /home/nutch/nutch-1.2/bin/../logs/hadoop-nutch-secondarynamenode-jdodrc.out
starting jobtracker, logging to /home/nutch/nutch-1.2/bin/../logs/hadoop-nutch-jobtracker-jdodrc.out
hadoop2: starting tasktracker, logging to /home/nutch/nutch-1.2/bin/../logs/hadoop-nutch-tasktracker-jdodrc.out
[nutch@jdodrc bin]$ jps //查看进程
14854 SecondaryNameNode
14933 JobTracker
15034 Jps
14671 NameNode
[nutch@jdodrc bin]$ ./hadoop dfs -copyFromLocal /home/nutch/nutch-1.2/urls urls [h2]
[nutch@jdodrc bin]$ ./nutch crawl urls -dir data -depth 3 -topN 10 //爬行
crawl started in: data
rootUrlDir = urls
threads = 10
depth = 3
indexer=lucene
topN = 10
…………………….
8. 用luke 查询hdfs的索引
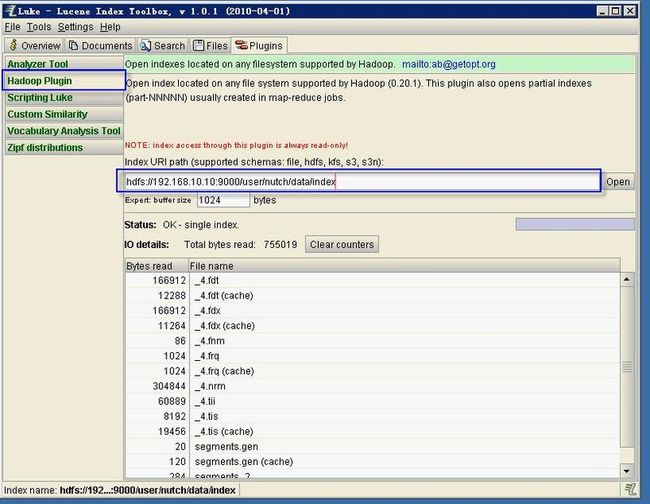
打开luke后,我们点击plugins插件这里,然后点击Hadoop Plugin,也就是左侧的那个标签,
打开后我们在hdfs的地址处输入你的hdfs的具体地址:
hdfs://192.168.10.10:9000/user/nutch/data/index
这个地址一定要注意,一定要是索引的具体地址,少一层也不行
比如我们hdfs的地址为hdfs://192.168.10.10:9000
然后hdfs下的索引地址是user/nutch/data/index,我们就必须去详细到index这个路径下,否则会找不到索引,这点一定要注意
9. namenode ID冲突导致HDFS不能启动
当你已经格式化一次namenode后,然后再重新格式化一次,然后你会发现会出现namenodeId冲突这个错误。
我们首先通过hadoop的控制台看一下我们的活动节点状态:
http://namenode Ip:50070
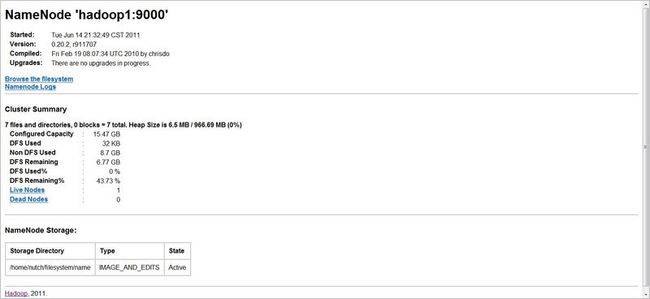
在livenode会有1个活动的节点
当错误时,下面是没有活动节点的:

看live nodes是0
然后,我们去datanode的日志里面日分析一下,日志在logs里面,日志名称为:hadoop-nutch-datanode-hadoop2.log
hadoop-nutch-datanode-(hadoop2是主机名称)
在日志中发现了这么一个错误:
2011-06-14 21:43:02,972 ERROR datanode.DataNode - java.io.IOException: Incompatible namespaceIDs in /home/nutch/filesystem/data: namenode namespaceID = 634109186; datanode namespaceID = 1464037194
at org.apache.hadoop.hdfs.server.datanode.DataStorage.doTransition(DataStorage.java:233)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:148)
at org.apache.hadoop.hdfs.server.datanode.DataNode.startDataNode(DataNode.java:298)
at org.apache.hadoop.hdfs.server.datanode.DataNode.<init>(DataNode.java:216)
at org.apache.hadoop.hdfs.server.datanode.DataNode.makeInstance(DataNode.java:1283)
at org.apache.hadoop.hdfs.server.datanode.DataNode.instantiateDataNode(DataNode.java:1238)
at org.apache.hadoop.hdfs.server.datanode.DataNode.createDataNode(DataNode.java:1246)
at org.apache.hadoop.hdfs.server.datanode.DataNode.main(DataNode.java:1368)
我们可以看到
namenode namespaceID = 634109186; datanode namespaceID = 1464037194
这里告诉我们namenode 的namespaceId和我们的datanode 的namesapceId不一致,
Datanode namespaceId是旧的,而namenode namesapceID是新格式化的,所以我们需要去修改一下版本号
找到<dfs.data.dir>/current/VERSION
dfs.data.dir 这个配置在hdfs-site.xml里面,这个是我的current路径
/home/nutch/filesystem/name/current
然后我把打开VERSION文件
#Tue Jun 14 21:38:02 CST 2011
namespaceID=634109186
cTime=0
storageType=NAME_NODE
layoutVersion=-18
然后我们把namespaceId修改为datanode的namespaceId 1464037194 就好了
修改之前需要停止hadoop服务,修改之后不要在重新格式化namenode ,否则namespaceId又会重新生成,我们直接start-all.sh开始节点就ok了
10. Hadoop 报copyFromLocal : No route to host 解决方法
当报这个错误的时候 no route to host ,只要关闭各个节点的防火墙即可
system-config-firewall
11. Hadoop dfs 命令
Hadoop dfs 这个命令后面加参数就是对于HDFS的操作,和linux操作系统的命令很类似,例如:
Hadoop dfs –ls 就是查看/usr/root目录下的内容,默认如果不填路径这就是当前用户路径
Hadoop dfs –rmr xxx就是删除目录,还有很多命令看看就很容易上手
Hadoop dfsadmin –report 这个命令可以全局的查看DataNode的情况。
Hadoop job 后面增加参数是对于当前运行的Job的操作,例如list,kill等
Hadoop balancer就是前面提到的均衡磁盘负载的命令。
12. Hadoop 报Unrecognized option: -dfs错误解决方法
Unrecognized option: -dfs
Could not create the Java virtual machine.

在网上找了找,没有发现解决方法,后来仔细一看,原来是自己的后面的参数输入错了,应该是dfs,没有-,所以无法识别-dfs,低级错误啊,大家一定要注意。
13. 网络原因造成nutch无法抓取报错的解决方法
fetch of http://www.sina.com.cn/ failed with: java.net.UnknownHostException:
2011-07-11 00:13:06,836 INFO api.RobotRulesParser - Couldn't get robots.txt for http://guba.eastmoney.com/look,huangjin,9614962.html: java.net.UnknownHostException: guba.eastmoney.com
2011-07-11 00:13:06,837 ERROR http.Http - java.net.UnknownHostException: guba.eastmoney.com
如果发现上面的错误后,我们查一下我们爬下来的内容
[nutch@nutch10 bin]$ ./nutch readdb data/crawldb -stats
CrawlDb statistics start: data/crawldb
Statistics for CrawlDb: data/crawldb
TOTAL urls: 1
retry 1: 1
min score: 1.0
avg score: 1.0
max score: 1.0
status 1 (db_unfetched): 1
我们如果爬取了很多url,但是所有都失败了
那么我尝试ping www.baidu.com(外网)
一般来说报了上面的问题都是网络的问题,如果ping 不通,我们调整一下网络,然后就ping通后就可以爬取了
14. Hadoop调整更大的jvm堆
在conf下找到mapred-site.xml文件,在文件中加入内容:
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx1024m</value>
</property>
Value这里是指最大的jvm内存大小 1024就是1g
当执行nutch 集群抓取时,报出了如下错误:
attempt_201107142322_0030_m_000000_2: Exception in thread "FetcherThread"
java.lang.OutOfMemoryError: Java heap space
Exception in thread "main" java.io.IOException: Job failed!
at org.apache.hadoop.mapred.JobClient.runJob(JobClient.java:1252)
at org.apache.nutch.fetcher.Fetcher.fetch(Fetcher.java:1107)
at org.apache.nutch.crawl.Crawl.main(Crawl.java:133)
java heap space就是堆内存空间不足了,而fetcher.java 的1107就是job提交操作,所以我们修改一下hadoop的堆内存大小就可以解决这个问题了
15. db.ignore.external.links
db.ignore.external.links 是否忽略外链
16. fetch中的一些名词解释
crawlDelay 间隔时间
minCrawlDelay 最小间隔时间
maxThreads 最大线程数
redirecting 重定向
17. nutch报的抓取错误
fetcher.Fetcher - fetch of http://t.qq.com/MR_JIANZHOU failed with: java.net.UnknownHostException: t.qq.com
fetcher.Fetcher - fetch of http://news.sohu.com/20050401/n224967814.shtml failed with: java.net.SocketTimeoutException: connect timed out
fetch of http://news.sohu.com/20070622/n250718750.shtml failed with: java.net.SocketTimeoutException: Read timed out
http.Http - java.net.UnknownHostException: hongwei6567.blog.sohu.com
fetch of http://fund.eastmoney.com/f10/jjgg_550004_1.html failed with: java.net.SocketTimeoutException: Read timed out
Error : DFS browser expects a distributed Filesystem
路径错误
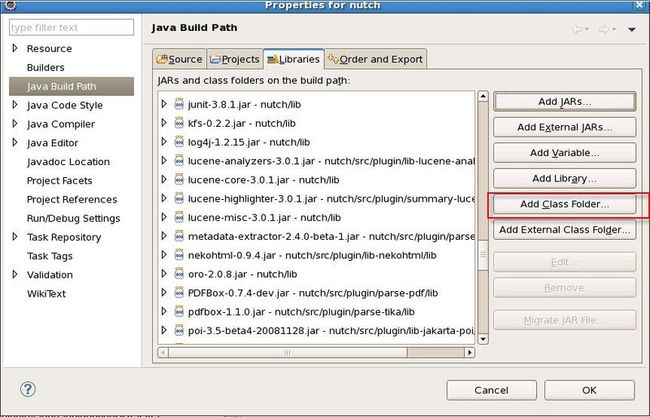
18. eclipse下开发nutch 的注意事项
1. 定义一个“Default ouput folder” ,名称任意。注意不能选bin文件夹,因为如果选了bin文件夹做为Default output folder 编译时会清空该文件夹,bin下的其他文件会被删掉,导致其他问题。

2. 在“Add Class Folder” 中选择 conf 文件夹
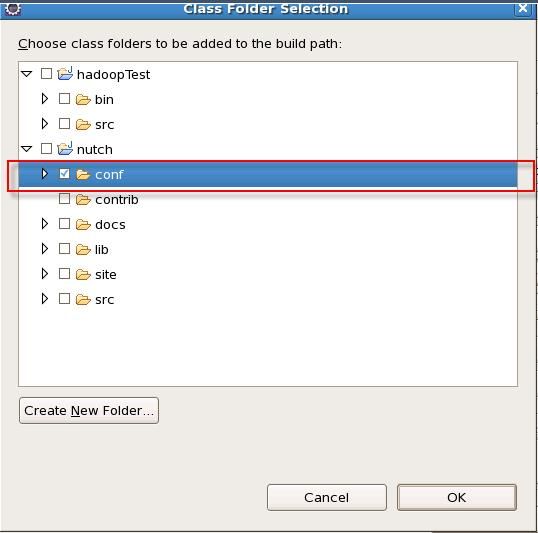
3. 修改D:\nutch-1.2\conf下的nutch-default.xml的plugin.folders,默认为plugins,修改为
./src/plugin
<property>
<name>plugin.folders</name>
<value>./src/plugin</value>
<description>Directories where nutch plugins are located. Each
element may be a relative or absolute path. If absolute, it is used
as is. If relative, it is searched for on the classpath.</description>
</property>
19. eclipse下nutch启动报错解决方法
当启动时,报了如下错误时:
crawl started in: /usr/file/nutch
rootUrlDir = urls
threads = 10
depth = 2
indexer=lucene
topN = 10
Injector: starting at 2011-09-28 11:49:29
Injector: crawlDb: /usr/file/nutch/crawldb
Injector: urlDir: urls
Injector: Converting injected urls to crawl db entries.
Exception in thread "main" java.io.IOException: Job failed!
at org.apache.hadoop.mapred.JobClient.runJob(JobClient.java:1252)
at org.apache.nutch.crawl.Injector.inject(Injector.java:217)
at org.apache.nutch.crawl.Crawl.main(Crawl.java:124)
请检查nutch-default.xml的plugin.folders是否修改为./src/plugin,默认为plugins,
修改后启动正常
20. linux 下运行可执行的jar
java -jar xxxx.jar
21. hadoop安全模式
我今天在删除hdsf文件内容时,报了如下错误:
rmr: org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot delete /user/nutch/urls. Name node is in safe mode.
那么如何解决这个问题呢?离开安全模式
bin/hadoop dfsadmin -safemode leave
执行上面的程序后,会提示:
Safe mode is OFF
这样就是安全模式已经关闭,也就是离开了安全模式,那么则可以对HDFS内容进行删除了。
那么什么情况会进去安全模式(safe mode)呢?
NameNode在启动的时候首先进入安全模式,如果datanode丢失的block达到一定的比例(1-dfs.safemode.threshold.pct),则系统会一直处于安全模式状态即只读状态。
dfs.safemode.threshold.pct(缺省值0.999f)表示HDFS启动的时候,如果DataNode上报的block个数达到了元数据记录的block个数的0.999倍才可以离开安全模式,否则一直是这种只读模式。如果设为1则HDFS永远是处于SafeMode。
下面这行摘录自NameNode启动时的日志(block上报比例1达到了阀值0.9990)
用户对于安全模式的操作方法如下:
用户可以通过dfsadmin -safemode value 来操作安全模式,参数value的说明如下:
enter - 进入安全模式
leave - 强制NameNode离开安全模式
get - 返回安全模式是否开启的信息
wait - 等待,一直到安全模式结束。
22. 配置crawl-urlfilter.txt错误的解决方法
当运行爬取时,在控制台报了如下错误:
Injector: Converting injected urls to crawl db entries.
Exception in thread "main" java.io.IOException: Job failed!
at org.apache.hadoop.mapred.JobClient.runJob(JobClient.java:1252)
at org.apache.nutch.crawl.Injector.inject(Injector.java:217)
at org.apache.nutch.crawl.Crawl.main(Crawl.java:124)
然后在日志中报了如下错误:
2011-12-21 17:31:16,882 ERROR api.RegexURLFilterBase - Invalid first character: http://www.baidu.com/
2011-12-21 17:31:16,884 WARN mapred.LocalJobRunner - job_local_0001
java.lang.RuntimeException: Error in configuring object
at org.apache.hadoop.util.ReflectionUtils.setJobConf(ReflectionUtils.java:93)
at org.apache.hadoop.util.ReflectionUtils.setConf(ReflectionUtils.java:64)
at org.apache.hadoop.util.ReflectionUtils.newInstance(ReflectionUtils.java:117)
at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:354)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:307)
at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:177)
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:39)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25)
at java.lang.reflect.Method.invoke(Method.java:597)
at org.apache.hadoop.util.ReflectionUtils.setJobConf(ReflectionUtils.java:88)
... 5 more
这是因为我在配置crawl-filter.txt的抓取策略配置失败了
#+^http://([a-z0-9]*\.)*MY.DOMAIN.NAME/
我们可以注意到上面的抓取策略的配置,少了+^(这个是增加策略),我们修改为如下的内容:
#+^http://([a-z0-9]*\.)*MY.DOMAIN.NAME/
+^http://([a-z0-9]*\.)*baidu.com/
这样配置后就解决了
23. Nutch1.3/1.4启动报错Job failed!解决方法
24. Injector: Converting injected urls to crawl db entries.
25. Exception in thread "main" java.io.IOException: Job failed!
26. at org.apache.hadoop.mapred.JobClient.runJob(JobClient.java:1252)
27. at org.apache.nutch.crawl.Injector.inject(Injector.java:217)
28. at org.apache.nutch.crawl.Crawl.run(Crawl.java:126)
29. at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:65)
30. at org.apache.nutch.crawl.Crawl.main(Crawl.java:54)
解决方法如下,因为是没有加入插件,所以才报了如上错误:
在nutch-defult.xml中,查找plugin.folders
修改内容为:
./src/plugin
plugin主要是和src下的plugin对应
<!-- plugin properties -->
<property>
<name>plugin.folders</name>
<value>./src/plugin</value>
<description>Directories where nutch plugins are located. Each
element may be a relative or absolute path. If absolute, it is used
as is. If relative, it is searched for on the classpath.</description>
</property>
31. Nutch1.3/1.4爬取报 No URLs to fetch - check your seed list and URL filters问题解决方法
当配置好了策略文件和入口文件时:
regex-urlfilter.txt策略文件
入口文件是放在urls里面的
然后配置http.agent.name这个属性的value值
<property>
<name>http.agent.name</name>
<value>jdodrc</value>
<description>HTTP 'User-Agent' request header. MUST NOT be empty -
please set this to a single word uniquely related to your organization.
NOTE: You should also check other related properties:
http.robots.agents
http.agent.description
http.agent.url
http.agent.email
http.agent.version
and set their values appropriately.
</description>
</property>
Value不可以为空,否则会报出
No URLs to fetch - check your seed list and URL filters
而且这个必须是在nutch-defult.xml中配置,不能在nutch-site.xml中配置(这里和1.2以前不一样),只有配置在nutch-defult.xml中才可以生效。
还需要修改regex-urlfilter.tx文件中
# skip URLs containing certain characters as probable queries, etc.
#-[?*!@=]
-[~]
支持动态爬取
32. Solr报org.apache.solr.common.SolrException: ERROR:unknown field 'content' 解决方法
当运行nutch1.4时,建立索引报了如下错误:
org.apache.solr.common.SolrException: ERROR:unknown field 'content' ,是因为没有配置content项,那么我们需要在schema.xml文件中配置上:
<field name="content" type="text" stored="true" indexed="true"/>
即可,那么我们在哪里配置呢?
在我们配置solr的solr/home路径下的conf中,找到schema.xml配置上
下面举个例子:
我们配置solr时,配置了
<Environment name="solr/home" type="java.lang.String" value="D:/file/apache-solr-3.4.0/example/solr" override="true" />
该项
那么我们要需要配置schema.xml就在:
D:/file/apache-solr-3.4.0/example/solr/conf/下
schema.xml文件如果是用nutch1.3以上爬取的话,可以在nutch下的conf目录下的schema.xml文件直接copy过去
然后我们配置好后,生成的索引在
D:/file/apache-solr-3.4.0/example/solr/data/index下
33. 配置solr的tomcat6环境
我们首先下载solr
http://www.apache.org/dyn/closer.cgi/lucene/solr/
从上面的网址选择地址进行下载
下载后解压文件
然后我们在tomcat下的conf目录下
创建Catalina\localhost目录(如果存在就不用创建)
然后我们创建solr.xml文件
在里面加入如下语句:
<Context docBase="D:/file/apache-solr-3.4.0/dist/apache-solr-3.4.0.war" reloadable="true" debug="0" privileged="true" allowLinking="true" crossContext="true">
<Environment name="solr/home" type="java.lang.String" value="D:/file/apache-solr-3.4.0/example/solr" override="true" />
<!--
<Valve className="org.apache.catalina.valves.RemoteAddrValve" allow="127.0.0.1,localhost,192.168.0.127"/>
-->
</Context>
doBase是放solr的web文件的位置
Environment中是solr的索引位置和配置文件等位置
如果需要控制访问权限则可以配置:
<Valve className="org.apache.catalina.valves.RemoteAddrValve" allow="127.0.0.1,localhost,192.168.0.127"/>
如果不是来自配置的IP则被拦截会显示403
34. Luke 与lucene的版本问题
如果在使用luke查看索引时,报出了如下错误:
Unknown format version: -11
那么则是luke的lucene版本低于了索引的lucene版本,所以需要更新luke,luke的下载地址:
http://code.google.com/p/luke/downloads/list
35. solr3.4添加IK3.2.8中文分词
首先需要配置solr环境,查看33项
如果solr启动成功后,然后到solr/home下(在solr.xml中配置的)
<Context docBase="D:/file/apache-solr-3.4.0/dist/apache-solr-3.4.0.war" reloadable="true" debug="0" privileged="true" allowLinking="true" crossContext="true">
<Environment name="solr/home" type="java.lang.String" value="D:/file/apache-solr-3.4.0/example/solr" override="true" />
<!--
<Valve className="org.apache.catalina.valves.RemoteAddrValve" allow="127.0.0.1,localhost,192.168.0.127"/>
-->
</Context>
找到conf目录,然后打开schema.xml
<fieldType name="text" class="solr.TextField"
positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.solr.IKTokenizerFactory" isMaxWordLength="false"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="stopwords.txt"/>
<filter class="solr.WordDelimiterFilterFactory"
generateWordParts="1" generateNumberParts="1"
catenateWords="1" catenateNumbers="1" catenateAll="0"
splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EnglishPorterFilterFactory"
protected="protwords.txt"/>
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.solr.IKTokenizerFactory" isMaxWordLength="true"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
上面标红位置就是添加的IK分词对于SOLR的支持类
这里配置好后,我们需要把IK分词的JAR包COPY到tomcat下的webapps/solr/WEB-INF/lib下(tomcat下webapps下的solr是从docBase中释放出来的)
添加好后,我们启动后就可以用中文分词了
如果需要自己定义词库的话,那么我们需要在solr/WEB-INF下创建一个classes文件夹,然后放入
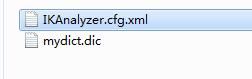
这2个文件
IKAnalyzer.cfg.xml文件是添加字库文件的
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典-->
<entry key="ext_dict">/mydict.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典
<entry key="ext_stopwords">/ext_stopword.dic</entry>
-->
</properties>
如果有多个词库,那么这里如下配置,以逗号分开,依次类推:
<entry key="ext_dict">/mydict.dic, /mydict1.dic </entry>
mydict.dic是词库文件
谨记
mydict.dic和IKAnalyzer.cfg.xml在web项目下,必须放在WEB-INF/classes下面,否则系统会检查不到,而且词库文件和IKAnalyzer.cfg.xml最好在同一目录下
36. solr地址无法索引报错解决方法
当nutch 执行完抓取后,建立 solr索引时,报了如下错误:
java.io.IOException: Job failed!
SolrDeleteDuplicates: starting at 2012-01-06 14:00:33
SolrDeleteDuplicates: Solr url: e:\crawl\local\local1
java.net.MalformedURLException: unknown protocol: e
at java.net.URL.<init>(URL.java:574)
at java.net.URL.<init>(URL.java:464)
at java.net.URL.<init>(URL.java:413)
at org.apache.solr.client.solrj.impl.CommonsHttpSolrServer.<init>(CommonsHttpSolrServer.java:156)
at org.apache.nutch.indexer.solr.SolrUtils.getCommonsHttpSolrServer(SolrUtils.java:53)
at org.apache.nutch.indexer.solr.SolrDeleteDuplicates$SolrInputFormat.getSplits(SolrDeleteDuplicates.java:190)
at org.apache.hadoop.mapred.JobClient.writeOldSplits(JobClient.java:810)
at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:781)
at org.apache.hadoop.mapred.JobClient.submitJob(JobClient.java:730)
at org.apache.hadoop.mapred.JobClient.runJob(JobClient.java:1249)
at org.apache.nutch.indexer.solr.SolrDeleteDuplicates.dedup(SolrDeleteDuplicates.java:373)
at org.apache.nutch.indexer.solr.SolrDeleteDuplicates.dedup(SolrDeleteDuplicates.java:353)
at com.jdodrc.crawl.Crawl.run(Crawl.java:159)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:65)
at com.jdodrc.crawl.MutilCrawlThread.run(MutilCrawl.java:139)
at java.util.concurrent.ThreadPoolExecutor$Worker.runTask(ThreadPoolExecutor.java:885)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:907)
at java.lang.Thread.run(Thread.java:619)
日志提示:
SolrDeleteDuplicates: Solr url: e:\crawl\local\local1
这里提示了solr url是e:\crawl\local\local1,是错误的,所以我们配置上正确的solr地址即可,如:
37. Cywin本地镜像下载
http://inst.eecs.berkeley.edu/~instcd/iso//cygwin-release-20061108.iso
38. solr 报404 missing core name in path解决方法
当打开solr/admin后,页面报了:
404 missing core name in path
我们查看 一下tomcat启动日志
报了如下错误:
严重: java.lang.RuntimeException: Can't find resource 'solrconfig.xml' in classpath or 'D:/file/tomcat_solr/solr/./conf/', cwd=/usr/file/tomcat_solr/bin
找不到” solrconfig.xml”文件,但是我去找了,发现存在,那么我们就去
Tomcat 下/conf/Catalina/localhost/solr.xml中看一下solr/home的配置是否正确,
查看一下,这里的value内容不正确,改为正确的启动正常后可以访问;
<Environment name="solr/home" type="java.lang.String" value="/usr/file/tomcat_solr/solr" override="true" />