Web Server 架构浅谈-Threadpool-based Multiple Threaded Achitecture
接上一节http://blog.csdn.net/pennyliang/archive/2010/10/10/5931272.aspx。
上节我们讲到了简单的多线程架构,这个架构可以做一些改进和优化:
首先,是优化线程创建的开销。操作系统默认的进程初始栈空间,32位操作系统为1M,64位操作系统为2M(不同操作系统版本可能会有差异)。那么并发10K的线程可能需要10G内存,这是不可想象的,因此可以自行设定栈的大小和溢出区,代码如下:
size_t size = max(10*PAGE_SIZE,PTHREAD_STACK_MIN);
void* base = get_from_penny_mmap(size);//从Mmap分配的虚拟内存中割一块
ret = pthread_attr_setstack(&tattr, base,size);
假定我们的线程大部分情况下只需要1个Page的栈空间,我们用mmap的方式分配到的虚拟内存做自定义线程栈,合计10个Page,另外9个Page看做是溢出区,如果线程的栈没有涨过1个Page,那么着9个Page只是虚拟页,不会调实际物理内存页,因此可以看做是无开销,万一溢出了,只是多一个调页过程。
其次,一个client通常是短连接的,即便是keep-alive的形式,每用户创建一个线程的代价还是太高,是否可以让线程的创建保持在一个常量呢?这就是线程池的思想,下面我们来看基于线程池的多线程架构。
基于线程池的多线程架构:
下图是线程池的架构,系统在刚创建时,创建有限个线程,这些线程的生死都是随着系统的创建和退出相联系,和用户访问无关。在获得链接请求后,将用户的请求看做是一个消息,将其插入到请求队列中,线程池的dispatch loop不断去将这个消息派发给一个闲置的线程进行处理,线程在处理完后进入等待队列,等待dispatch loop派发任务。
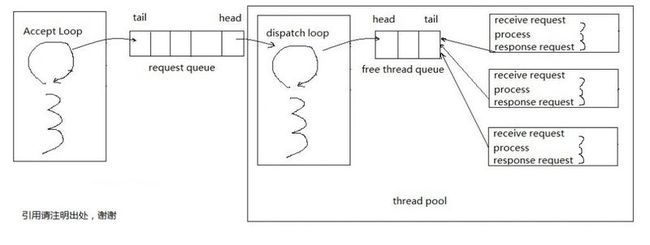
dispatch loop是可以去掉的,每个处理线程在处理完任务后,直接去request queue中取任务,但这样有几个缺点:1)对request的队头访问频繁;2)当线程池线程不够时无法自我感知已增加新线程。因此在每个处理线程之外,需要一个承担管理职责的线程。
在每个线程处理完任务后,进入一个等待信号的过程,可以采用挂起和spin的方式,前者会有上下文切换的开销,后者会出现循环空转的开销,dispatch在队头取得的线程等待信号,给予激活同时赋予请求的任务。在具体实现上还会有多种变化,这里不一一介绍,
基于线程池的多线程架构在并发线程的数量上大大减少,上下文切换相应减少;线程创建的数量与客户请求无关,创建成本减少;线程池的资源争用情况大大减少,资源饱和使用的程度大大加强,因此线程池在吞吐率(throughput,单位时间交互的数据量)上通常较高。但付出了排队的成本,使得响应时间会大大提高,这是线程池架构主要的问题。
我们日常生活中在银行办理业务,就可以看做是线程池模型的例子,排队机就是request queue,叫号系统就是dispatch loop,自动将到号的用户分配给一个空闲的客服,客服就是每个处理线程,客服在处理完业务后,按键进入闲状态,等待叫号系统安排。银行的这种设置显然是基于吞吐率考虑的,而不是响应时间考虑的,和简单多线程方式那种资源抢占式的无序相比,基于线程池的排队处理看上去更加优化。
下一篇博文参见:http://blog.csdn.net/pennyliang/archive/2010/10/14/5940666.aspx
申明:我写的博客欢迎转载,并可以用于任何场合,只要是对技术传播有益,我均无异议。
但不欢迎自行修改和不署名的转载。
因为有些内容我会用在一些教学等特殊场合,我不希望有人反馈给我,我的博客是抄袭别人的。希望大家在转载时务必注明作者,并全文转载,不要做任何修改,谢谢。
同时我会在举例中加一些特殊的记号,希望读者予以谅解,比如本文的get_from_penny_mmap。