关于传值与传引用的讨论
效率问题
对于用户自定义的类型来说,传引用一般要比传值高效。传引用不需要经过对象过程,在《Effective C++》中作者举了个例子:
class Base
{
pubilc:
Base();
~Base();
private:
std::string b1;
std::string b2;
}
class Derive : public Base
{
public:
Derive();
~Derive();
private:
std :: string d1;
std ::string d2;
}此刻我们拥有一个派生类对象derive 。对derive传值的结果是共需要进行六次的构造函数的调用:对象本身的构造函数,对象内部数据成员string的构造,对象基类部分的构造函数,对象基类数据成员string的构造。同样的,待对象生命结束后,还要经历6次析构函数的调用。而传引用则不用进过如此多的构造与析构,甚至一次都不用。
对内置类型来说,传值的效率往往要高于传引用。内置类型包括了int,float ,double,指针类型等等。看下面的程序:
void f(int i)
{
i = i + 1;
}
void g(int & i)
{
i = i + 1;
}
int main()
{
int i=10;
f(i);
g(i);
}当通过传值调用函数f()时,其汇编代码为:

当通过传引用调用函数g()时,其汇编代码为:
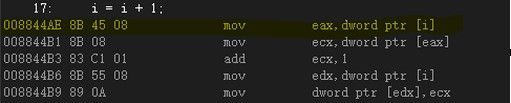
可以看到,传引用比传值多了一次寻址操作,这是因为引用的实现往往基于指针,因此传引用通常意味着真正传递的是指针。
总结:
- 对内置类型来说,通常传值更高效。
- 对用于自定义类型来所,传值要经历构造与析构过程,一般比较耗时。
对象的切割问题
传值有时会引起对象的切割问题。就上面所示的两个类,当我们定义如下函数并进行传值调用时:
void func(Base B)
{
...
}
int main()
{
Derive A;
func(A);
}编译器将调用Base类的复制构造函数来初始化B,初始化数据来源于A,但构造结果是个Base类对象:也就意味着A的特有部分的数据被切割掉了。在函数func中,B的行为是一个Base的行为而不是Derive的行为。
通过传引用,能够避免切割的问题:
void func(Base & B)
{
...
}
int main()
{
Derive A;
func(A);
}此时在函数func内,对象B实际类型为Derive,通俗地将,B就是A。若希望在func中使用到实参的特性,传引用能够保证这一点。
STL中的使用情况
如果你打开STL中的源码,你会发现容器的iterator都是通过传值形式传参。在《Effective C++》中指出,对于内置类型、STL 迭代器和 STL 仿函数,pass-by-value 也是可以的,一般没有性能损失。在 x86-64 上,对于只有一个 指针成员且没有自定义复制构造函数的类,传值是可以通过寄存器进行的,就像传递普通 int 和指针那样。如上所示,传值是可以比传引用快的没有,因为它少了一次解引用的操作。
(完)