数据结构——排序算法总结
排序(Sorting)就是将一组对象按照规定的次序重新排列的过程,排序往往是为检索而服务的,它是数据处理中一种很重要也很常用的运算。例如我们日常学习中的查字典或者书籍的目录,这些都事先为我们排好序,因此大大降低了我们的检索时间,提高工作效率。
排序可分为两大类:
内部排序(Internal Sorting):待排序的记录全部存放在计算机内存中进行的排序过程;
外部排序(External Sorting):待排序的记录数量很大,内存不能存储全部记录,需要对外存进行访问的排序过程。
外部排序自己现阶段还没有接触和学习,因此这里我们只研究内部排序的集中算法,希望能和大家互相学习共同进步。
内部排序的中比较常见的有四种算法,下面我们分别对各种算法常见的算法进行学习。思维导图如下:

一、插入排序
基本思想:在一个已经排好序的序列中,将未被排序的元素按照原先序列的排序规则插入到序列中的指定位置。
常用举例:直接插入排序
直接插入排序(Straight Insertion Sorting)是一种简单的排序算法,他的基本思想是依次将每个记录插入到一个已经排好序的有序表中去,从而得到一个新的、记录增加1的有序表。具体过程如下:
初始序列:{45 38 66 90 88 10 25 }
第一步对前两个数进行排序,把38插入到45之前,得到新的序列{45 38 66 90 88 10 25}
第二步对前三个数进行排序,把66插入到有序序列{45 38}的合适位置,即{45 38 66 90 88 10 25}
以后的步骤是在都是在以上基础上的一个递归过程知道最后一个数25插入到合适的位置得到最终序列{10 25 38 45 66 88 90}
算法描述:
<span style="font-family:KaiTi_GB2312;font-size:18px;">void StraightInsertSort(List R,int n)
//对顺序表R进行直接插入排序
{
int i, j;
for (i=2;i<=n;i++)//n为表长,从第二个记录起进行插入
{
R[0] = R[i];//第i个记录复制为岗哨
j = i - 1;
while (R[0].key<R[j].key)//与岗哨比较,直至键值不大于岗哨值
{
R[j +1]=R[j];//将第j个记录赋值给第j+1个记录
j--;
}
R[j + 1] = R[0];//将第i个记录插入的序列中
}
}</span>
二、交换排序
基本思想:比较两个记录的键值大小,如果两个记录键值的大小出现逆序,则交换这两个记录,这样将键值较小的记录向序列前部移动,键值较大的记录向序列后部移动,最终将得到有序序列。
常用举例:冒泡排序、快速排序
(1)冒泡排序
冒泡排序法(Bubble Sorting)首先将第一个记录的键值和第二个记录的键值进行比较,若为逆序则将这两个记录交换,然后继续比较第二个和第三个记录的键值。以此类推,直到完成第n-1个记录和第n个记录的键值比较交换为止。这时便完成了第一趟气泡,其结果是将最大的记录移到最后一位。然后第二次气泡跟第一次类似,其结果是将第二大的记录移到倒数第二位。重复以上过程,直到整个排序过程终止得到最终有序序列。
初始序列:{45 38 66 90 88 10 25}
第一趟起泡:
第一步比较45跟38的大小,38<45所以45与38交换{38 45 66 90 88 10 25}
第二步比较45与66的大小,45<66因此不用交换位置{3845 66 90 88 10 25}
第三步比较66与90的大小,66<90不用交换{38 4566 90 88 10 25}
第四步比较90与88的大小,90>88一次交换位置{38 45 66 88 90 10 25}
第五步{38 45 66 88 10 90 25}
第六步{38 45 66 88 10 25 90}
此时第一趟起泡完成,90为最大数,移到最后的位置,以后起泡过程跟第一趟起泡完全相同。
第一趟起泡后{38 45 66 88 10 2590}
第二趟起泡后{38 45 66 10 25 88 90}
第三趟起泡后{38 45 10 25 66 88 90}
第四趟起泡后{38 10 25 45 66 88 90}
第五趟起泡后{10 25 38 45 66 88 90}
第六趟起泡后{10 25 38 45 66 88 90}
第七趟起泡后{10 25 38 45 66 88 90}
排序完成!
算法描述:
<span style="font-family:KaiTi_GB2312;font-size:18px;"> void BubbletSort(List R,int n)
{
int i, j,temp,endsort;
for (i=1;i<=n-1;i++)
{
endsort = 0;
for (j = 1; j <= n - i - 1; j++)
{
if (R[j].key>R[j+1].key)//若为逆序则交换记录
{
temp = R[j];
R[j] = R[j + 1];
R[j + 1] = temp;
endsort = 1;
}
}
if (endsort == 0) break;
}
}</span>
(2)快速排序
快速排序(Quick Sorting)是对冒泡排序的一种改进。它的基本思想是在n个记录中取某一个记录的键值为标准,通常取第一个记录键值为基准,通过一趟排序将待排序的记录分为小于等于这个键值和大于这个键值的两个独立的部分,这时前面部分的记录键值均比后面的记录键值小,然后对这两部分分别按照这种方法排序,直到获得整个有序序列。
初始序列:{45 38 66 90 88 10 25}
第一步取第一个数45为标准,然后从序列末尾开始向标准数一端查找,找到第一个小于标准数的数,与标准数互换位置。即从25开始找,25<45所以互换位置得到{25 38 66 90 88 1045}
第二步从上一步与标准数互换的数25开始向标准数一端查找,找到第一个大于标准数的数,然后与标准数互换位置。从上一步的25开始向标准数45一端即向右找到第一个大于45的数为66,然后两个数互换位置得到{25 384590 88 1066}
第三步继续从上一步与标准数互换的数66开始,向标准数45一端查找,找到第一个小于标准数的数,然后与标准数互换位置。即从上一步66开始向45一端查找,找到第一个小于标准数45的数为10,互换位置得到{25 381090 8845 66}
第四部还是从上一步中与标准数互换的数10开始,向标准数45一端查找,找到第一个大于标准数的数为90,互换位置得到{25 38 1045 88 90 66}
第五步同样从90向45一端查找,找到第一个小于标准数45的数,然后互换位置。但是这里从90一直到45的位置都没有找到比标准数45小的数,这时便完成了第一趟排序。比较规律可简化为左小右大,即标准数在左边就找小于标准数的数与之交换,标准数在右边就找大于标准数的数与之交换。
完成第一趟排序之后得到序列为{25 38 1045 88 90 66},此时整个序列被分为两部分45之前的值均小于等于45,45之后的均大于45。后面的排序过程分别对这两部分序列按照上面步骤进行排序,以此类推,直到得到最终有序序列为止。
算法描述:
<span style="font-family:KaiTi_GB2312;font-size:18px;"> //第一趟快速排序算法
int QuickPartition(List R,int low,int hign)
{
x=R[low]//赋初值,标准数
while (low < hign)
{
while ((low <hign) && (R[hign].key>=x.key )) hign--;
R[low]=R[hign];//自尾端进行比较,将比x小的记录移到低端
while ((low <hign) && (R[low].key<=x.key )) low++;
R[hign]=R[low];//自首端进行比较,将比x大的记录移到高端
}
R[low]=x;//第一趟排序结束,将x移到其最终位置
return low ;
}</span>
三、选择排序
基本思想:每次在n-i+1(i=1,2,3……,n-1)个记录中选取键值最小的记录作为有序序列的第i个记录。
常用举例:直接选择排序、堆排序。
(1)直接选择排序
直接选择排序(Selection Sorting)的基本思想是在第i次选择操作中,通过n-i次键值比较,从n-i+1个记录中选出最小的记录,并和第i(1<=i<=n-1)个记录交换。
初始序列:{45 38 66 90 88 10 25}
第一步共有7个数,所以n=7,首先另i=1这时候需要通过6次键值比较,从7个记录中选出最小记录,并和第1个记录交换得到{10 38 66 90 8845 25}
第二步另i=2,这时候我们需要通过六次比较,从剩余6个记录中选出最小记录,并和第2个记录交换得到{1025 66 90 88 45 38}
第三步i=3,从剩余的5个记录中找到最小记录,并和第3个记录交换得到{10 2538 90 88 45 66}
第四步i=4,从剩余的4个记录中找到最小记录,并和第4个记录交换得到{10 25 3845 88 90 66}
第五步i=5,从剩余的3个记录中找到最小记录,并和第5个记录交换得到{10 25 38 456690 88}
第六步i=6,从剩余的2个记录中找到最小记录,并和第6个记录交换得到{10 25 38 456688 90}
此时得到最终有序数列。
算法描述:
<span style="font-family:KaiTi_GB2312;font-size:18px;"> void SelectSort(List R,int n)
{
int min, i, j;
for(i=1;i<=n-1;i++)//每次循环选择出最小一个键值
{
min=i;//假设第i个记录键值最小
for(j=i+1;j<=n;j++)
{
if(R[j].key<R[min].key) min =j;//记录下键值最小记录的下标
if(min!=i) swap(R[min],R[i]);//将最小键值记录和第i个记录交换
}
}
}</span>
(2)堆排序
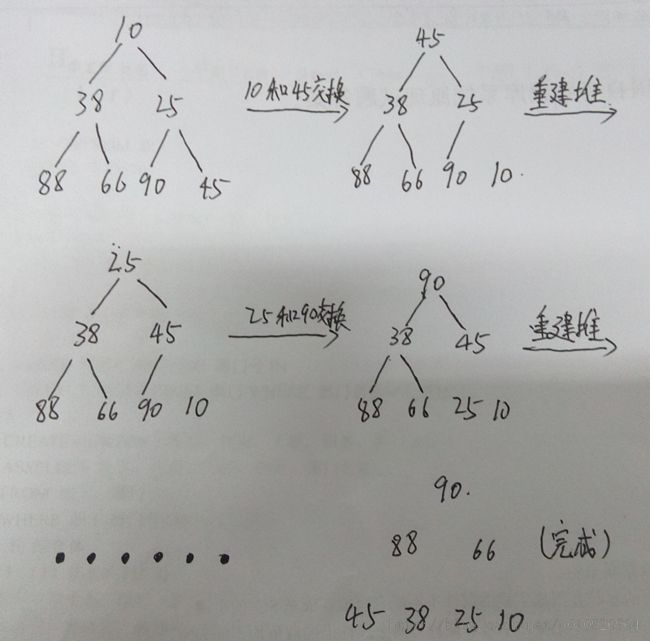
堆排序(Heap Sorting)是利用堆的数据结构所设计的一种排序算法,可利用数组的特点快速定位指定索引的元素。堆分为最大堆和最小堆,最大堆中的任一节点的值都不小于它的两个孩子的值(若存在孩子的话);最小堆则任一节点的值都不大于它的两个孩子的值。
以最小堆排序为例,首先要把初始序列建成一个最小堆,然后输出堆顶元素后需要重建堆。具体过程如下:
初始序列:{45 38 66 90 88 10 25}
建堆及排序如图:
算法描述:
<span style="font-family:KaiTi_GB2312;font-size:18px;">void Sift(List R,int k,int m)
{
int i, j, x;
List t;
i = k; j = 2 * i;
x = R[k].key;
t = R[k];
while (j<=m)
{
if ((j < m) && (R[j].key > R[j + 1].key))
j++;//若存在右子树且右子树的关键字小,则沿右分支筛选
if (x < R[j].key) break;//筛选完毕
else
{
R[i] = R[j];
i = j;
j = 2 * i;
}
R[i] = t;//填入适当位置
}
}
//堆排序算法
void HeapSort(List R)
{
int i;
for (i = n / 2; i >= 1; i--)
Shit(R, i, n);//从第n/2个记录开始进行筛选建堆
for (i=n;i>=2;i--)
{
swap(R[1], R[i]);//将堆顶记录和堆中最后一个记录互换
Sift(R, 1, i - 1);//调整R[1]使R[1],……,R[i-1]变成堆
}
}</span>
四、归并排序
基本思想:将两个或两个以上的有序表结合成一个新的有序表,合并方法是比较个子序列的第一个记录的键值,最小的一个就是排序后序列的第一个记录纸。取出这个记录,继续比较各子序列现有的第一个记录的键值,便可找出排序后的第二个记录。以此类推,最终得到有序序列。
常见举例:二路归并排序。
二路归并排序是将两个有序表结合成一个有序表,基本思想是假设序列中有n个记录,可看成是n个有序的子序列,每个序列的长度为1.首先将每相邻的两个记录合并,得到n/2(向上取整)个较大的有序序列,每个子序列包含2个记录,再将上述子序列两两合并,得到(n/2)/2(向上取整)个有序序列,如此反复,知道得到最终有序序列为止。
初始序列:[45] [38] [66] [90] [88] [10] [25]
一次归并后:[38 45] [66 90] [10 88] [25]
二次归并后:[38 45 66 90] [10 25 88]
三次归并后:[10 25 38 45 66 88 90]
最终得到的有序序列为:{10 25 38 45 66 88 90}
时间空间复杂度

以上我们共介绍了四类排序算法:插入、交换、选择和归并排序,重点介绍了六个内部排序算法:直接插入排序、冒泡排序、快速排序、直接选择排序、堆排序和归并排序。这几种都是我们常用的排序算法,我们不能单纯的评价那种算法的优劣而是要根据实际情况选择合适的算法来提高工作效率。我只是根据书中的内容加上自己的理解给大家介绍了这几种排序算法,有不足之处还请大家批评指正。