首先,我先大概介绍一下jpetstore的整体架构,spring的这个版本主要使用了struts+spring+ibatis的框架组合,
而在MVC层的框架,这个版本又同时提供了两个实现版本,一个是struts,一个是spring 自带的web框架,
而数据库持久层使用的是ibatis框架,这个框架是一个SQL映射框架,轻量级而且使用非常容易,基本上会
使用JDBC的朋友看一两个小时就会使用了。
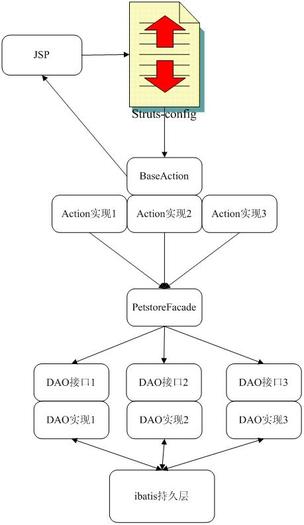
下图是该应用的一个简略架构图,没有什么好的工具,就大概画了一个,虽然比较简单,不过也基本可以
概括应用的整体框架了,首先是JSP请求,通过struts-config.xml(这里只是根据struts来画的,spring其实也差不多),
请求转到相应的Action中,可以看到,这里有一个BaseAction,是所有Action实现的父类,这个类的作用稍后再讲,
然后就是每个Action通过PetStoreFacade的对象调用后台DAO对象,从而通过ibatis进行数据的持久操作,
这里使用了门面(Facade)模式,隔离了前台与后台耦合度,而PetStoreFacade就是这个门面。结合下图,
相信大家对整个jpetstore会有个大概的了解。
好了,大概的结构讲了下,接下来我们就从代码入手,在这里考虑到struts大家比较熟悉,因此,
本文是以struts版本来讲,同时声明,本文并不会一段段代码详细讲述,而只是提供一个学习的参考,
大概讲解一下流程,让大家不再茫然不知从哪开始,好了,废话也不多说了。
既然是WEB应用,那当然首先从配置文件看起,那就非web.xml莫属了,打开WEB-INF目录下的web.xml,
我们挑出目前我们应该关注的配置代码:
代码
<servlet>
<servlet-name>petstore</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
<load-on-startup>2</load-on-startup>
</servlet>
<servlet>
<servlet-name>action</servlet-name>
<servlet-class>org.apache.struts.action.ActionServlet</servlet-class>
<load-on-startup>3</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>petstore</servlet-name>
<!--
<servlet-name>action</servlet-name>
-->
<url-pattern>*.do</url-pattern>
</servlet-mapping>
在这里可看到两个servlet设置,以及一个servlet mapping,第一个petstore的servlet是用于spring web框架的,
而第二个action的servlet就是用于struts的,而这个版本的mapping默认的是使用spring web,可以看到,<servlet-name>action</servlet-name>这一行是被注释掉了,我们要使用struts的话,那就把这个注释去掉,
改为注释掉<servlet-name>petstore</servlet-name>,好了,如此注释以后,整个应用就会以struts的框架运行。
(这些配置是什么意思?如果你还搞不懂的话,建议你先去学学基础再来研究应用吧)
接下来我们可以打开strutc-config.xml文件,这里就是struts的默认配置文件,在这里可以看到struts的相关配置信息。
好了,接下来我们就以一个请求来讲述基本的请求流程,以search为例,生成项目,再启动,
成功之后进入应用的首页,我们终于可以看到久违的鹦鹉界面了,激动吧,呵呵,在界面的右上角,
有一个Search文本框,我们就以这个Search为例子来讲解,输入一个关键字cat,然后点search,
结果出来了,这个过程的内部是如何运作的呢?
我们用鼠标右键点击页面,然后选择属性,我们看到显示的地址可能是:
http://localhost:8080/shop/searchProducts.do;jsessionid=E2D01E327B82D068FEE9D073CA33A2A3
这个地址就是我们刚才点击查询时提交的地址了,我们看到searchProducts.do这个字符串,
我们之前在web.xml里面的设置大家还记得吗?
<servlet-mapping>
<!--
<servlet-name>petstore</servlet-name>
-->
<servlet-name>action</servlet-name>
<url-pattern>*.do</url-pattern>
</servlet-mapping>
代表着所有以.do为结尾的请求,都将被名叫action的servlet处理,也就是通过struts-config配置进行处理,那我们就去struts-config.xml里面看看,打开struts-config.xml文件,ctrl+F弹出查询界面,输入searchProducts,我们就可查到
<action path="/shop/searchProducts" type="org.springframework.samples.jpetstore.web.
struts.SearchProductsAction" name="emptyForm" scope="session" validate="false">
<forward name="success" path="/WEB-INF/jsp/struts/SearchProducts.jsp"/>
</action>
根据以上配置,我们可以得知,刚才我们的提交将会被SearchProductsAction处理,而该action的form是emptyForm,查找emptyForm这个别名,我们可以找到它指向一个BaseActionForm,打开这个form我们可以看到,里面只有两个validate方法和一个addErrorIfStringEmpty方法,没有任何的属性,那就是说search这个提交并没有把我们输入的关键字保存在form里面,打开SearchProductsAction,我们看到execute方法里的第一句就是
String keyword = request.getParameter("keyword");
也就是说我们输入的关键字是以参数的形式传入到request里面,参数名字为“keyword”,我们打开IncludeTop.jsp,这个文件在WEB-INF/jsp/struts目录下。
注意了,jsp目录下分别有spring以及struts两个目录,这两个目录就是分别对应两个web框架的,我们使用的是struts所以jsp代码就到struts目录里面,为什么打开IncludeTop.jsp呢,我们可以看到,无论我们进入哪个页面,search那个文本框都存在,也就是说,这个文本框是被当作一个模板插入到所有页面当中去的,我们随便打开一个页面,就可以看到页面开头都是:
<%@ include file="IncludeTop.jsp" %>
这句就是把IncludeTop.jsp当作页面头部包含进来,所以凡是包含这个头页面的页面,他们的头部都是一样的,这也是我们在开发中常用的一种方式,统一界面的一种方式,我们也可以看到在这些文件尾部也有类似的代码,如:
<%@ include file="IncludeBottom.jsp" %>
其作用也是一样。打开IncludeTop.jsp后,我们看到其中有一段代码:
<form action="<c:url value="/shop/searchProducts.do"/>" method="post">
<input type="hidden" name="search" value="true"/>
<input name="keyword" size="14"/> <input border="0" src="../images/search.gif"
type="image" name="search"/>
</form>
这段代码就是我们search文本框以及提交链接的代码,在这里就不做详细介绍了。
好了,接下来我们再看看这个action的后续代码
if (keyword != null) {
if (!StringUtils.hasLength(keyword)) {
request.setAttribute("message", "Please enter a keyword to search for,
then press the search button.");
return mapping.findForward("failure");
}
PagedListHolder productList = new PagedListHolder(getPetStore().
searchProductList(keyword.toLowerCase()));
productList.setPageSize(4);
request.getSession().setAttribute("SearchProductsAction_productList", productList);
request.setAttribute("productList", productList);
return mapping.findForward("success");
}
这里第一句就是判断keyword是否为空,不为空就执行其中的代码,我们search的时候这个keyword肯定是不为空的,
那就是说这段if包含的代码就是我们search的处理代码了,有的人也许会说,如果我不输入关键字而直接点search呢,
这keyword不就是为空了吗?我想这个你在此处加个断点,再运行一下就知道了,虽然你没有输入,
但是keyword一样不是null,它将是一个空字符串,而不是空对象。我们看到if里面还包含有一个if,
这里就是判断keyword是否为空字符串了,StringUtils.hasLength()方式是一个工具类,
用来判断keyword是否为空字符串,如果是空字符串就返回false,而这句判断当返回false时,
因为前面有个感叹号,所以值为false就执行被if所包含的语句,里面的代码就是保存一个错误信息,然后return mapping.findForward("failure");,这句的意思就不再解释了。
现在假设我们正确输入keyword,那么程序将不会执行if语句中的代码,直接向下执行,我们看到
PagedListHolder productList = new PagedListHolder(getPetStore().
searchProductList(keyword.toLowerCase()));
这句代码,PagedListHolder是spring提供的一个用来保存查询结构类,通常用来进行分页处理,
因此我们可以知道
getPetStore().searchProductList(keyword.toLowerCase())
这一句就是用来查询,并返回查询结果的。getPetStore()这个方法是继承自BaseAction的,它将获得一个PetStoreFacade的实现,我们打开BaseAction的代码,可以看到如下代码
public void setServlet(ActionServlet actionServlet) {
super.setServlet(actionServlet);
if (actionServlet != null) {
ServletContext servletContext = actionServlet.getServletContext();
WebApplicationContext wac = WebApplicationContextUtils.getRequiredWebApplicationContext(servletContext);
this.petStore = (PetStoreFacade) wac.getBean("petStore");
}
}
这句代码里面最重要的一句就是
WebApplicationContext wac = WebApplicationContextUtils.
getRequiredWebApplicationContext(servletContext);
这句代码的作用就是获取一个WebApplicationContext对象wac,在这里我们只需要知道这个对象的作用,而不对其进行深入研究,通过这个对象,我们可以根据spring的配置文件,获得相应的Bean,下面这句就是用来获取相应bean的语句:
this.petStore = (PetStoreFacade) wac.getBean("petStore");
petStore这个就是bean的id,这个petStore的bean具体是哪个类呢?我们打开applicationContext.xml,可以找到以下配置代码
<bean id="petStore" class="org.springframework.samples.jpetstore.domain.logic.PetStoreImpl">
<property name="accountDao" ref="accountDao"/>
<property name="categoryDao" ref="categoryDao"/>
<property name="productDao" ref="productDao"/>
<property name="itemDao" ref="itemDao"/>
<property name="orderDao" ref="orderDao"/>
</bean>
从这里可以看到,petStoreFacade的具体类就是PetStoreImpl,而这个类当中,分别通过spring IOC注入了几个DAO的bean,这几个DAO的配置可以在dataAccessContext-local.xml文件里面找到,我们打开PetStoreImpl这个实现类,我们看到类里有一个searchProductList方法,这个方法就是我们在Action当中调用的方法
return this.productDao.searchProductList(keywords);
从这句代码可以看出,这个方法是通过调用productDao的searchProductList方法来获得结果的,
productDao这个DAO从上面的配置文件可以看出,是通过IOC容器进行注入的,我们打开dataAccessContext-local.xml文件,可以看到
<bean id="productDao" class="org.springframework.samples.jpetstore.dao.ibatis
.SqlMapProductDao">
<property name="sqlMapClient" ref="sqlMapClient"/>
</bean>
这句配置代表了productDao的实现类就是SqlMapProductDao,同时这个类包含有一个sqlMapClient的属性对象,这个对象也是通过ioc注入的,再在这个配置文件里,我们可以找到如下一段代码
<bean id="sqlMapClient" class="org.springframework.orm.ibatis.SqlMapClientFactoryBean">
<property name="configLocation" value="WEB-INF/sql-map-config.xml"/>
<property name="dataSource" ref="dataSource"/>
</bean>
这段代码就是sqlMapClient这个bean的配置,这里的实现是SqlMapClientFactoryBean,它是spring专门为ibatis框架提供的一个支持,通过这个对象就可以很好的集成ibatis框架,具体的介绍可以通过spring官方文档或者是其他一些教程获得,在这里就不多做介绍。
好了,接下来我们知道了,实际查询数据是通过DAO的实现类SqlMapProductDao进行的,而SqlMapProductDao当中就是通过了ibatis进行数据的查询,从而返回结果,这里也就不多做介绍了,大家可以通过ibatis的教程获得ibatis的使用方法,非常的简单,search操作从前台到后台的大概流程就介绍到这里了。
在这个参考文章中,我并没有对具体技术做过多的讲解,那是因为本文只是作为一个研究jpetstore的参考,提供一个可供参考的研究流程,主要是为了那些想开始研究jpetstore但是又不知道从哪开始或者是不知道如何进行研究的新人朋友们而准备的,如果具体的讲解每一部分,那我想将不仅仅是一篇文章就可以完成的事情,因为这里涉及到struts,spring,ibatis等具体的框架技术,每一个框架基本都可以写成一本书,用一篇文章来讲就不太实际了,而且我个人更倾向于遇到不理解的地方的时候,多使用google来搜索,这样能够进一步加深自己对问题的理解。
好了,关于jpetstore源码研究入门的文章就写到这里结束了,由于本人技术和文笔有限,有错漏或者表达不当的地方请不要介意,欢迎各位朋友来指正。