Pinned Memory: portable, mapped, write-combined
1. Pinned memory
Before CUDA2.2: the benefits of pinned memory were realized only on the CPU thread (or, if using the driver API, the CUDA context) in which the memory was allocated. Pinned memory could only be copied to and from GPU; kernels could not access CPU memory directly, even if it was pinned.
CUDA2.2&later: introduce APIs that relax restrictions, like cudaHostAlloc()
l Portable: pinned buffers that are available to all GPUs
l Mapped: pinned buffers that are mapped into the CUDA address space, so, also be referred to as “zero-copy” buffers.
l Write-combined(WC): has higher PCIe copy performance and doesn’t have any effect on CPU caches(WC buffers are a separate HW resource). CPU-reading insures performance penalty, it’s best for “CPU produces (data) while GPU consumes”.
l These 3 features are completely orthogonal.
2. Portable
Before CUDA2.2: benefits of pinned memory could only be realized on the CUDA context that allocated it.
CUDA2.2&later: adapt to multi-GPU applications, available to all CUDA contexts.
This memory model, CPU and GPU have distinct memory that is accessible to one device or the other, but never the both. But “mapped” can!
3. Mapped
Two scenarios where CPU and GPU desires to share a buffer without explicit buffer allocations and copies (like “portable” does):
l On GPUs integrated into the motherboard, copies are superfluous because GPU-mem and CPU-mem are physically the same.
l On discrete GPUs running workloads that are transfer-bound, or for suitable workloads where GPU can overlap computation with kernel-originated PCIe transfers, higher performance may be achieved as well as obviating the need to allocate a GPU memory buffer (Able people should do more work?aha~).
4. WC
Quoting from Intel’s web site: “Writes to WC memory are not cached in the typical sense of the word cached. They are delayed in an internal buffer that is separate from L1 and L2 caches. The buffer is not snooped and thus does not provide data coherency.”
Writes to WC memory do not pollute the CPU cache, and it is not snooped during transfers across the PCIe bus.
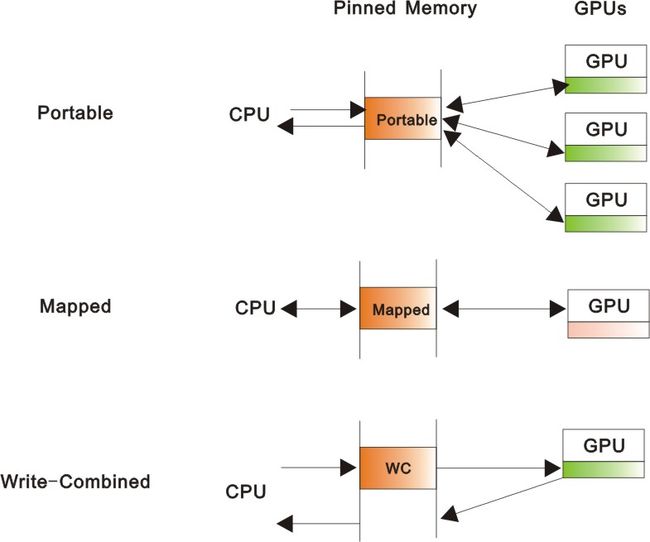
Figure 1 Features of Pinned Memory
I'm not sure about the "Write-Combined"...discussion welcomed~
5. Apply (Mapped)
//cudaSetDeviceFlags(), then u can use cudaHostGetDevicePointer(); and once this, all pinned allocations are mapped into CUDA’s 32-bit linear address space, regardless of whether the device pointer is needed.
cudaSetDeviceFlags(cudaDeviceMapHost)
flags = cudaHostAllocMapped;
cudaHostAlloc((void **)&a, bytes, flags);
cudaHostGetDevicePointer((void **)&d_a, (void *)a, 0);
kernel<<<>>>(d_a, nelem); //must coalesced, or performance penalty
cudaThreadSynchronize();
//when using pinned memory, always pay attention to the synchronize, or u may get unexpected results. Also, u can use cudaStreamSynchronize/ udaEventSynchronize.
More about pinned memory, please visit CUDA SDK/C/src/simpleZeroCopy or http://www.hpctech.com/