Scala入门到精通——第二十九节 Scala数据库编程
本节主要内容
- Scala Maven工程的创建
- Scala JDBC方式访问MySQL
- Slick简介
- Slick数据库编程实战
- SQL与Slick相互转换
本课程在多数内容是在官方教程上修改而来的,官方给的例子是H2数据库上的,经过本人改造,用在MySQL数据库上,官方教程地址:http://slick.typesafe.com/doc/2.1.0/sql-to-slick.html
1. Scala Maven工程的创建
本节的工程项目采用的是Maven Project,在POM.xml文件中添加下面两个依赖就可以使用scala进行JDBC方式及Slick框架操作MySQL数据库:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.18</version>
</dependency>
<dependency>
<groupId>com.typesafe.slick</groupId>
<artifactId>slick_2.11</artifactId>
<version>2.1.0</version>
</dependency>scala IDE for eclipse 中创建scala Maven项目的方式如下:
在Eclispe 中点击” File->new->other”,如下图
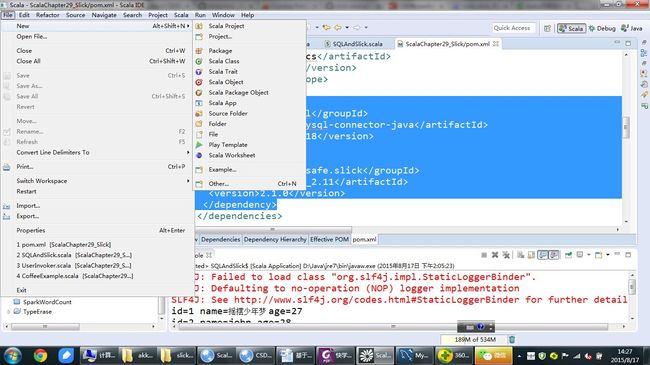
输入Maven可以看到Maven Project:

直接next,得到
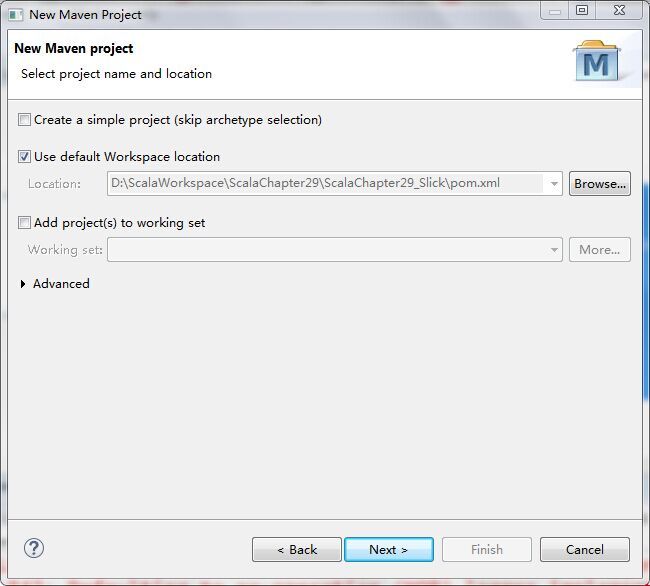
再点击next,在filter中输入scala得到:
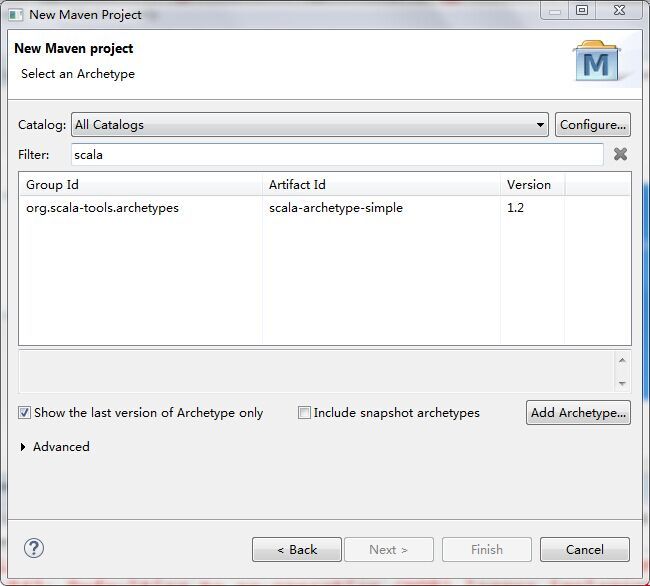
选中,然后next输入相应的groupId等,直接finish即可。创建完项目将上述依赖添加到pom.xml文件当中,这样就完成了scala maven Project的创建。
2. Scala JDBC方式访问MySQL
下面给出的是scala采用JDBC访问MySQL的代码示例
package cn.scala.xtwy.jdbc
import java.sql.{ Connection, DriverManager }
object ScalaJdbcConnectSelect extends App {
// 访问本地MySQL服务器,通过3306端口访问mysql数据库
val url = "jdbc:mysql://localhost:3306/mysql"
//驱动名称
val driver = "com.mysql.jdbc.Driver"
//用户名
val username = "root"
//密码
val password = "123"
//初始化数据连接
var connection: Connection = _
try {
//注册Driver
Class.forName(driver)
//得到连接
connection = DriverManager.getConnection(url, username, password)
val statement = connection.createStatement
//执行查询语句,并返回结果
val rs = statement.executeQuery("SELECT host, user FROM user")
//打印返回结果
while (rs.next) {
val host = rs.getString("host")
val user = rs.getString("user")
println("host = %s, user = %s".format(host, user))
}
} catch {
case e: Exception => e.printStackTrace
}
//关闭连接,释放资源
connection.close
}3. Slick简介
在前一小节中我们演示了如何通过JDBC进行数据库访问,同样在Scala中也可以利用JAVA中的ORM框架如Hibernate、IBatis等进行数据库的操纵,但它们都是Java风格的数据库操纵方式,Scala语言中也有着自己的ORM框架,目前比较流行的框架包括:
1、Slick (typesafe公司开发)
2、Squeryl
3、Anorm
4、ScalaActiveRecord (基于Squeryl之上)
5、circumflex-orm
6、activate-framework(Scala版的Hibernate)本节课程要讲的便是Slick框架,它是Scala语言创建者所成立的公司TypeSafe所开发的一个Scala风格的开源数据库操纵框架,它目前支持下面几种主流的数据:
DB2 (via slick-extensions)
Derby/JavaDB
H2
HSQLDB/HyperSQL
Microsoft Access
Microsoft SQL Server (via slick-extensions)
MySQL
Oracle (via slick-extensions)
PostgreSQL
SQLite当然它也支持其它数据,只不过功能可能还不完善。在Slick中,可以像访问Scala自身的集合一样对数据库进行操作,它具有如下几个特点:
1 数据库的访问采用Scala风格:
//下面给出的是数据查询操作
class Coffees(tag: Tag) extends Table[(String, Double)](tag, "COFFEES") {
def name = column[String]("COF_NAME", O.PrimaryKey)
def price = column[Double]("PRICE")
def * = (name, price)
}
val coffees = TableQuery[Coffees]
//下面给出的数据访问API
// Query that only returns the "name" column
coffees.map(_.name)
// Query that does a "where price < 10.0" coffees.filter(_.price < 10.0) 从上面的代码可以看到,Slick访问数据库就跟Scala操纵自身的集合一样.
2 Slick数据操纵是类型安全的
// The result of "select PRICE from COFFEES" is a Seq of Double
// because of the type safe column definitions
val coffeeNames: Seq[Double] = coffees.map(_.price).list
// Query builders are type safe:
coffees.filter(_.price < 10.0)
// Using a string in the filter would result in a compilation error3 支持链式操作
// Create a query for coffee names with a price less than 10, sorted by name coffees.filter(_.price < 10.0).sortBy(_.name).map(_.name) // The generated SQL is equivalent to: // select name from COFFEES where PRICE < 10.0 order by NAME4. Slick 数据库编程实战
下面的代码演示了Slick如何创建数据库表、如何进行数据插入操作及如何进行数据的查询操作(以MySQL为例):
package cn.scala.xtwy
//导入MySQL相关方法
import scala.slick.driver.MySQLDriver.simple._
object UseInvoker extends App {
// 定义一个Test表
//表中包含两列,分别是id,name
class Test(tag: Tag) extends Table[(Int, String)](tag, "Test") {
def k = column[Int]("id", O.PrimaryKey)
def v = column[String]("name")
// Every table needs a * projection with the same type as the table's type parameter
//每个Table中都应该有*方法,它的类型必须与前面定义的类型参数(Int, String)一致
def * = (k, v)
}
//创建TableQuery对象(这里调用的是TableQuery的apply方法
//没有显式地调用new
val ts = TableQuery[Test]
//forURL注册MySQL驱动器,传入URL,用户名及密码
//方法回返的是一个DatabaseDef对象,然后再调用withSession方法
Database.forURL("jdbc:mysql://localhost:3306/slick", "root","123",
driver = "com.mysql.jdbc.Driver") withSession {
//定义一个隐式值
//implicit session: MySQLDriverbackend.Session
//后续方法中当做隐式参数传递
implicit session =>
// 创建Test表
//create方法中带有一个隐式参数
//def create(implicit session: JdbcBackend.SessionDef): Unit
ts.ddl.create
//插入数据
//def insertAll(values: U*)(implicit session: JdbcBackend.SessionDef): MultiInsertResult
ts.insertAll(1 -> "a", 2 -> "b", 3 -> "c", 4 -> "d", 5 -> "e")
//数据库查询(这里返回所有数据)
ts.foreach { x => println("k="+x._1+" v="+x._2) }
//这里查询返回所有主鍵 <3的
ts.filter { _.k <3 }.foreach { x => println("k="+x._1+" v="+x._2) }
}
//模式匹配方式
ts.foreach { case(id,name) => println("id="+id+" name="+name) }
}下面我们再给一个更为复杂的例子来演示Slick中是如何进行数据的入库与查询操作的:
package cn.scala.xtwy
import scala.slick.driver.MySQLDriver.simple._
object CoffeeExample extends App {
// Definition of the SUPPLIERS table
//定义Suppliers表
class Suppliers(tag: Tag) extends Table[(Int, String, String, String, String, String)](tag, "SUPPLIERS") {
def id = column[Int]("SUP_ID", O.PrimaryKey) // This is the primary key column
def name = column[String]("SUP_NAME")
def street = column[String]("STREET")
def city = column[String]("CITY")
def state = column[String]("STATE")
def zip = column[String]("ZIP")
// Every table needs a * projection with the same type as the table's type parameter
def * = (id, name, street, city, state, zip)
}
val suppliers = TableQuery[Suppliers]
// Definition of the COFFEES table
//定义Coffees表
class Coffees(tag: Tag) extends Table[(String, Int, Double, Int, Int)](tag, "COFFEES") {
def name = column[String]("COF_NAME", O.PrimaryKey)
def supID = column[Int]("SUP_ID")
def price = column[Double]("PRICE")
def sales = column[Int]("SALES")
def total = column[Int]("TOTAL")
def * = (name, supID, price, sales, total)
// A reified foreign key relation that
//can be navigated to create a join
//外鍵定义,它使得supID域中的值关联到suppliers中的id
//从而保证表中数据的正确性
//它定义的其实是一个n:1的关系,
//即一个Coffees对应只有一个Suppliers,
//而一个Suppliers可以对应多个Coffees
def supplier = foreignKey("SUP_FK", supID, suppliers)(_.id)
}
val coffees = TableQuery[Coffees]
Database.forURL("jdbc:mysql://localhost:3306/slick", "root", "123",
driver = "com.mysql.jdbc.Driver") withSession {
implicit session =>
// Create the tables, including primary and foreign keys
//按顺序创建表
(suppliers.ddl ++ coffees.ddl).create
// Insert some suppliers
//插入操作,集合的方式
suppliers += (101, "Acme, Inc.", "99 Market Street", "Groundsville", "CA", "95199")
suppliers += (49, "Superior Coffee", "1 Party Place", "Mendocino", "CA", "95460")
suppliers += (150, "The High Ground", "100 Coffee Lane", "Meadows", "CA", "93966")
// Insert some coffees (using JDBC's batch insert feature, if supported by the DB)
//批量插入操作,集合方式
coffees ++= Seq(
("Colombian", 101, 7.99, 0, 0),
("French_Roast", 49, 8.99, 0, 0),
("Espresso", 150, 9.99, 0, 0),
("Colombian_Decaf", 101, 8.99, 0, 0),
("French_Roast_Decaf", 49, 9.99, 0, 0))
//返回表中所有数据,相当于SELECT * FROM COFFEES
coffees foreach {
case (name, supID, price, sales, total) =>
println(" " + name + "\t" + supID + "\t" + price + "\t" + sales + "\t" + total)
}
//返回表中所有数据,只不过这次是直接让数据库帮我们进行转换
val q1 = for (c <- coffees)
yield LiteralColumn(" ") ++ c.name ++ "\t" ++ c.supID.asColumnOf[String] ++
"\t" ++ c.price.asColumnOf[String] ++ "\t" ++ c.sales.asColumnOf[String] ++
"\t" ++ c.total.asColumnOf[String]
// The first string constant needs to be lifted manually to a LiteralColumn
// so that the proper ++ operator is found
q1 foreach println
//联合查询
//采用===进行比较操作,而非==操作符,用于进行值比较
//同样的还有!=值不等比较符
//甚至其它比较操作符与scala是一致的 <, <=, >=, >
val q2 = for {
c <- coffees if c.price < 9.0
s <- suppliers if s.id === c.supID
} yield (c.name, s.name)
}
5. SQL与Slick相互转换
package cn.scala.xtwy
import scala.slick.driver.MySQLDriver.simple._
import scala.slick.jdbc.StaticQuery.interpolation
import scala.slick.jdbc.GetResult
object SQLAndSlick extends App {
type Person = (Int, String, Int, Int)
class People(tag: Tag) extends Table[Person](tag, "PERSON") {
def id = column[Int]("ID", O.PrimaryKey)
def name = column[String]("NAME")
def age = column[Int]("AGE")
def addressId = column[Int]("ADDRESS_ID")
def * = (id, name, age, addressId)
def address = foreignKey("ADDRESS", addressId, addresses)(_.id)
}
lazy val people = TableQuery[People]
type Address = (Int, String, String)
class Addresses(tag: Tag) extends Table[Address](tag, "ADDRESS") {
def id = column[Int]("ID", O.PrimaryKey)
def street = column[String]("STREET")
def city = column[String]("CITY")
def * = (id, street, city)
}
lazy val addresses = TableQuery[Addresses]
val dbUrl = "jdbc:mysql://localhost:3306/slick"
val jdbcDriver = "com.mysql.jdbc.Driver"
val user = "root"
val password = "123"
val db = Database.forURL(dbUrl, user, password, driver = jdbcDriver)
db.withSession { implicit session =>
(people.ddl ++ addresses.ddl).create
//插入address数据
addresses += (23, "文一西路", "浙江省杭州市")
addresses += (41, "紫荆花路", "浙江省杭州市")
//插入people数据
people += (1, "摇摆少年梦", 27, 23)
people += (2, "john", 28, 41)
people += (3, "stephen", 28, 23)
//下面两条语句是等同的(获取固定几个字段)
val query = sql"select ID, NAME, AGE from PERSON".as[(Int, String, Int)]
query.list.foreach(x => println("id=" + x._1 + " name=" + x._2 + " age=" + x._3))
val query2 = people.map(p => (p.id, p.name, p.age))
query2.list.foreach(x => println("id=" + x._1 + " name=" + x._2 + " age=" + x._3))
//下面两条语句是等同的(Where语句)
val query3 = sql"select * from PERSON where AGE >= 18 AND NAME = '摇摆少年梦'".as[Person]
query3.list.foreach(x => println("id=" + x._1 + " name=" + x._2 + " age=" + x._3))
val query4 = people.filter(p => p.age >= 18 && p.name === "摇摆少年梦")
query4.list.foreach(x => println("id=" + x._1 + " name=" + x._2 + " age=" + x._3))
//orderBy
sql"select * from PERSON order by AGE asc, NAME".as[Person].list
people.sortBy(p => (p.age.asc, p.name)).list
//max
sql"select max(AGE) from PERSON".as[Option[Int]].first
people.map(_.age).max
//隐式join
sql""" select P.NAME, A.CITY from PERSON P, ADDRESS A where P.ADDRESS_ID = a.id """.as[(String, String)].list
people.flatMap(p =>
addresses.filter(a => p.addressId === a.id)
.map(a => (p.name, a.city))).run
// or equivalent for-expression:
(for (
p <- people;
a <- addresses if p.addressId === a.id
) yield (p.name, a.city)).run
//join操作
sql"""select P.NAME, A.CITY from PERSON P join ADDRESS A on P.ADDRESS_ID = a.id """.as[(String, String)].list
(people join addresses on (_.addressId === _.id))
.map{ case (p, a) => (p.name, a.city) }.run
}
}上面列出的只是Slick与SQL的部分转换,还有诸如:Update、Delete等操作可以参见:http://slick.typesafe.com/doc/2.1.0/sql-to-slick.html
添加公众微信号,可以了解更多最新Spark、Scala相关技术资讯
