NanoProfiler - 适合生产环境的性能监控类库 之 实践ELK篇
上期回顾
上一期:NanoProfiler - 适合生产环境的性能监控类库 之 大数据篇
上次介绍了NanoProfiler的大数据分析理念,一晃已经时隔一年多了,真是罪过! 有朋友问到何时开源的问题,这里先简单说明一下。因为是单位的项目,虽然单位的目标肯定是要开源的,但是,毕竟不像个人项目那么自由。一方面要保证代码本身的质量,另一方面也要剥离对单位其他框架类库的依赖,一忙起来就拖延日久了,我只能说尽力尽快推动这个事情!不过,Nuget package一直在Nuget.org,可以免费使用的。想尝试的朋友无需太多顾虑。另外,单位的项目中已经大面积使用已经有近两年了,所以,性能和稳定性是有保障的。
这一期,我们就来结合elasticsearch,logstash,kibana手把手实践一把。
示例代码
附件包含完整的示例代码和logstash配置文件:http://files.cnblogs.com/files/teddyma/nanoprofiler_demo.zip
此示例代码演示了之前几期介绍中提到的NanoProfiler的绝大多数功能,包括DB和WCF profiling的演示和基于Unity的AOP。示例中包含了两个简单的HTTP Handler,分别演示了在同步和异步情形下,NanoProfiler一致的使用体验。
示例代码可以使用VS2012,2013或2015打开,并且直接编译和运行。直接运行默认会在浏览器访问AsyncHandler.ashx,可以看到简单的demo数据输出。点击View Profiling Results,或者直接访问/nanoprofiler/view,可以看到最近的100个请求的profiling结果。NanoProfiler的Profiling Storage默认是基于slf4net写profiling结果的,本示例中通过slf4net.log4net,将profiling结果记录到App_Data目录中的文本文件。
示例代码用到了SQL Express 2012 LocalDB,如果运行时报SQL connection错误,请确保安装了LocalDB:http://www.microsoft.com/en-US/download/details.aspx?id=29062
关于NanoProfiler基本功能的使用请参见之前几期博客文章的介绍,这里重点介绍一下实践中结合数据的收集和分析工具elasticsearch,logstash,kibana如何对profiling的结果进行分析。
下载和安装 elasticsearch,logstash,kibana
最新版本的elasticsearch,logstash对windows已经有了很好的支持,只需要JRE7+,下载后的默认配置,即使在windows下都可直接运行。比起两年前可幸福多了,记得以前在虚拟机的ubuntu里安装鼓捣半天。
首先,安装elasticsearch,从官网下载zip包:https://download.elastic.co/elasticsearch/elasticsearch/elasticsearch-1.7.1.zip
解压到某个本地目录。执行bin\elasticsearch.bat,elasticsearch就已经运行了。太简单了,不是?
接着,安装logstash,同样从官网下载zip包:https://download.elastic.co/logstash/logstash/logstash-1.5.4.zip
解压到某个本地目录。这就已经算安装完了,不是逗你!
最后,从官网下载kibana(这里使用kibana v3,因为v3是纯静态页面的,随便一个web服务器就能运行,另外,真的对kibana4的新UI无爱,还是喜欢3的UI):https://download.elastic.co/kibana/kibana/kibana-3.1.2.zip
解压到某个本地目录,host到IIS里,例如:我用的URL是:http://localhost:8080/k3/
在浏览器中访问http://localhost:8080/k3/,因为没有使用80端口,它可能会显示一个Connection Failed错误信息,提示你该怎么fix。如果你没看到错误信息,可以跳过本节下面的内容。
要fix这个问题,我们只需要在elasticsearch安装目录的config/elasticsearch.yml文件结尾添加一行:
http.cors.enabled: true
然后,停掉elasticsearch,再重新运行bin/elasticsearch.bat
在浏览器中重新访问http://localhost:8080/k3/,可以看到,这次没有错误信息了!(注意,不要直接按F5,要去掉刚才有错误信息页面地址里的#connectionFailed部分)
至此,elasticsearch,logstash,kibana全部安装完毕了!
使用logstash导入profiling结果到elasticsearch
回到我们的示例程序,在浏览器中再刷新几次对AsyncHandler.ashx的访问(只是为了多点profiling数据),然后,在App_Data目录,应该能看到profiling log文件。打开log文件,我们看到,里面的每一行是一个json。这一节,我们的目的是,将log文件里的json,通过logstash导入elasticsearch。
我们需要定义一个logstash的conf文件,别忘了改里面的路径到你本机的正确目录,关于logstash的具体使用帮助,可以参考官方文档:https://www.elastic.co/guide/en/logstash/current/advanced-pipeline.html
profiling.conf
input {
file {
codec => "json"
path => [ "C:/Users/teddy/git/nanoprofiler_demo/Demos/NanoProfiler.Demos.SimpleDemo/App_Data/*.log" ]
sincedb_path => "C:/Users/teddy/git/nanoprofiler_demo/Demos/NanoProfiler.Demos.SimpleDemo/App_Data/sincedb.profiling-logs"
sincedb_write_interval => 5
start_position => "beginning"
discover_interval => 5
}
}
filter
{
# Use started as @timestamp field
date {
match => [ "started", "ISO8601" ]
timezone => "UTC"
target => "@timestamp"
}
}
output {
elasticsearch {
protocol => "http"
host => "localhost"
document_id => "%{id}"
index => "logstash-profiling-log-%{+YYYY.MM.dd}"
workers => 1
}
}接下来就可以让logstash执行了,在cmd里cd到logstash的安装目录,执行:bin/logstash -f profiling.conf
在浏览器中访问http://localhost:9200/_search,可以看到,我们的profiling数据已经被成功导入elasticsearch。
用kibana显示elasticsearch里数据
下面,我们可以尝试用kibana来显示elasticsearch里的profiling结果了。
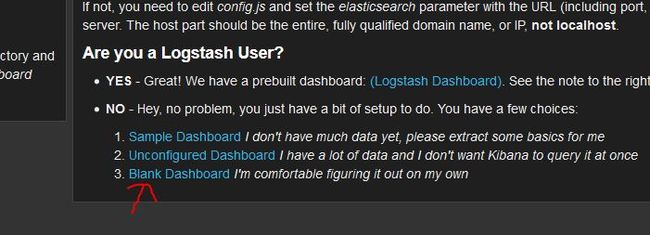
首先,在kibana3的首页,点击创建一个新的空dashboard。
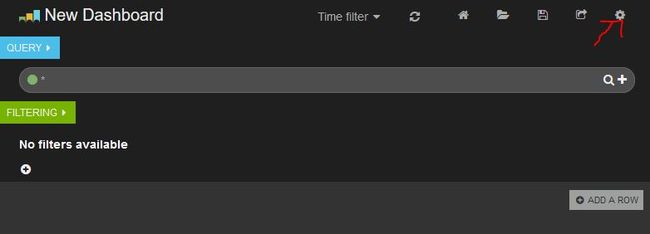
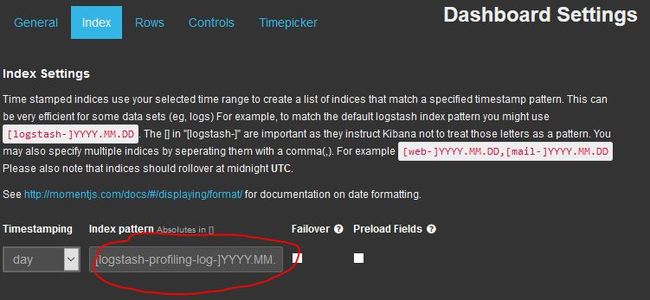
点击右上角的设置按钮,在弹出的窗口点击index tab,如下图输入我们上面的profiling.conf里指定的输出到elasticsearch的index名称,然后点击save保存。
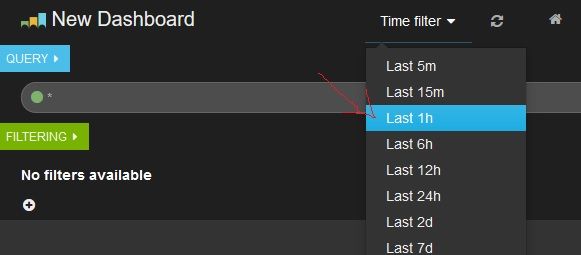
回到dashboard,选择Time Picker为最近一小时。
接下来我们要在dashboard上新建议个row,点击dashboard右下角的Add a row,然后在弹出页面点击Create a row,然后点击save保存。
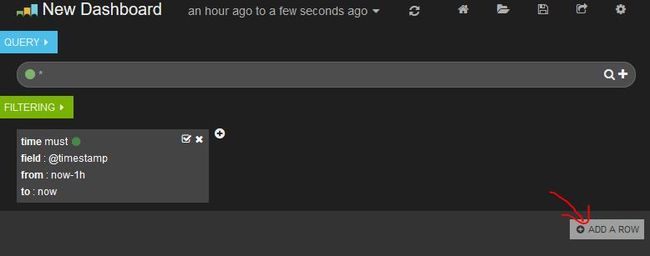
这时,屏幕上或多出一个row,鼠标移动台左边的屏幕边缘,点击+按钮,选择Panel Type为Table,其他不用填,直接点击save保存。这时,我们已经能看到添加的Table Panel里面显示我们的profiling数据了,不过,这个panel窄了点,我们可以像windows窗口一样,把他拖大一点。
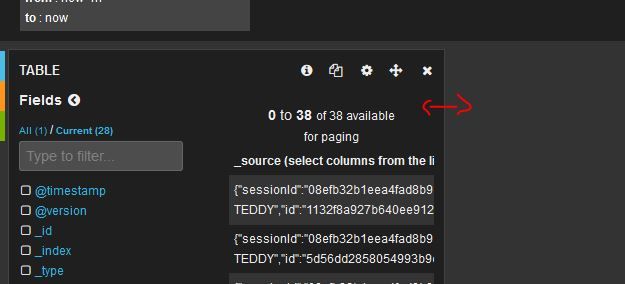
接下来,我们可以对profiling数据,做更多的filter,比如,我想看看所有的DB profiling结果。
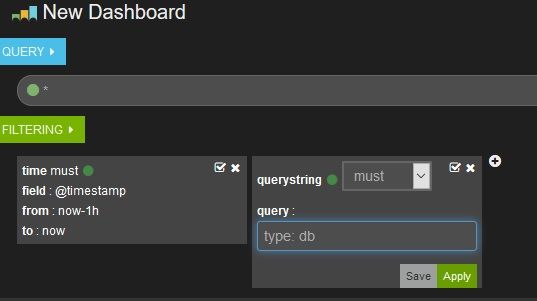
当然,你也可以再点击左边的屏幕边缘的+按钮,添加kibana提供的各种其他酷酷的panel。
如果,你现在刷新几下示例代码中的AsyncHandler.ashx页面,回到dashboard,稍等2-3秒,点击页面上方的刷新按钮,就能看到,daskboard里显示的profiling数据自动增加了。因为logstash是实时监控log文件变更的。:)
后面您就自己玩会儿?我去歇歇了!