解密SVM系列(五):matlab下libsvm的简单使用
本节简单介绍一下libsvm的使用方法。关于libsvm似乎曾经使用过,那个时候主要用libsvm进行简单的人脸识别实验。当时还翻译过关于libsvm里面的matlab英文文档
那么现在最新版本的libsvm为3.2.0,下载地址如下:
http://www.csie.ntu.edu.tw/~cjlin/libsvm/
下载下来的libsvm其实包含好多个平台的工具箱软件,c++,matlab,java,python都有。他们的函数使用方法是一样的。
那么在下载完以后,点击里面的matlab下平台,直接在点击里面的make.m函数就可以了。正常情况下如果你的matlab含有编译平台的话直接就可以运行了,如果没有,还需要选择一个平台 mex -setup 。小提醒一下,这个编译过程不要在c盘下使用,也就是libsvm先不要放在c盘,涉及到权限,机器不让编译。编译完后在matlab的设置路径中添加进去编译的文件夹及其内容,那么就可以使用了。正常编译的过程是这样的:

在上面的人脸识别实验中曾经介绍过里面的主要函数,这里为了放在一块,把那里的拿过来吧:
目前版LIBSVM(3.2.0)在matlab下编译完后只有四个函数,libsvmread,Libsvmwrite,svmtrain(matlab自带的工具箱中有一个同名的函数),svmpredict。
(1)libsvmread主要用于读取数据
这里的数据是非matlab下的.mat数据,比如说是.txt,.data等等,这个时候需要使用libsvmread函数进行转化为matlab可识别数据,比如自带的数据是heart_scale数据,那么导入到matlab有两种方式,一种使用libsvmread函数,在matlab下直接libsvmread(heart_scale);第二种方式为点击matlab的‘导入数据’按钮,然后导向heart_scale所在位置,直接选择就可以了。个人感觉第二种方式超级棒,无论对于什么数据,比如你在哪个数据库下下载的数据,如何把它变成matlab下数据呢?因为有的数据libsvmread读取不管用,但是‘导入数据’后就可以变成matlab下数据。
(2)libsvmwrite写函数,就是把已知数据存起来
使用方式为:libsvmwrite(‘filename’,label_vector, instance_matrix);
label_vector是标签,instance_matrix为数据矩阵(注意这个数据必须是稀疏矩阵,就是里面的数据不包含没用的数据(比如很多0),有这样的数据应该去掉再存)。
(3)svmtrain训练函数,训练数据产生模型的
一般直接使用为:model=svmtrain(label,data,cmd); label为标签,data为训练数据(数据有讲究,每一行为一个样本的所有数据,列数代表的是样本的个数),每一个样本都要对应一个标签(分类问题的话一般为二分类问题,也就是每一个样本对应一个标签)。cmd为相应的命令集合,都有哪些命令呢?很多,-v,-t,-g,-c,等等,不同的参数代表的含义不同,比如对于分类问题,这里-t就表示选择的核函数类型,-t=0时线性核。-t=1多项式核,-t=2,径向基函数(高斯),-t=3,sigmod核函数,新版出了个-t=4,预计算核(还不会用);-g为核函数的参数系数,-c为惩罚因子系数,-v为交叉验证的数,默认为5,这个参数在svmtrain写出来使用与不写出来不使用的时候,model出来的东西不一样,不写的时候,model为一个结构体,是一个模型,可以带到svmpredict中直接使用,写出来的时候,出来的是一个训练模型的准确率,为一个数值。一般情况下就这几个参数重要些,还有好多其他参数,可以自己参考网上比较全的,因为下面的这种方法的人脸识别就用到这么几个参数,其他的就不写了。
(3)svmpredict训练函数,使用训练的模型去预测来的数据类型。
使用方式为:
[predicted_label,accuracy,decision_values/prob_estimates]= svmpredict(testing_label_vector,testing_instance_matrix,model,’libsvm_options’)
或者:
[predicted_label]=svmpredict(testing_label_vector,testing_instance_matrix, model, ‘libsvm_options’)
第一种方式中,输出为三个参数,预测的类型,准确率,评估值(非分类问题用着),输入为测试类型(这个可与可无,如果没有,那么预测的准确率accuracy就没有意义了,如果有,那么就可以通过这个值与预测出来的那个类型值相比较得出准确率accuracy,但是要说明一点的是,无论这个值有没有,在使用的时候都得加上,即使没有,也要随便加上一个类型值,反正你也不管它对不对,这是函数使用所规定的的),再就是输入数据值,最后是参数值(这里的参数值只有两种选择,-p和-b参数),曾经遇到一个这样的问题,比如说我在训练函数中规定了-g参数为0.1,那么在预测的时候是不是也要规定这个参数呢?当你规定了以后,程序反而错误,提醒没有svmpredict的-g参数,原因是在svmtrain后会出现一个model,而在svmpredict中你已经用了这个model,而这个model中就已经包含了你所有的训练参数了,所以svmpredict中没有这个参数,那么对于的libsvm_options就是-p和-b参数了。对于函数的输出,两种方式调用的方法不一样,第一种调用把所有需要的数据都调用出来了,二第二种调用,只调用了predicted_label预测的类型,这里我们可以看到,在单纯的分类预测模型中,其实第二种方式更好一些吧,既简单有实用。
致此,四个函数在分类问题中的介绍大概如此,当然还有很多可以优化的细节就不详细说了,比如可以再使用那些参数的时候,你如果不规定参数的话,所有的-参数都是使用默认的,默认的就可能不是最好的吧,这样就涉及到如何去优化这个参数了。
使用就介绍到这里吧,下面实战一下,样本集选择前面使用的200个非线性样本集,函数如下:
%%
% * libsvm 工具箱简单使用
%
%% 加载数据
% * 最终data格式:m*n,m样本数,n维度
% * label:m*1 标签为-1与1这两类
clc
clear
close all
data = load('data_test1.mat');
data = data.data';
%选择训练样本个数
num_train = 80;
%构造随机选择序列
choose = randperm(length(data));
train_data = data(choose(1:num_train),:);
gscatter(train_data(:,1),train_data(:,2),train_data(:,3));
label_train = train_data(:,end);
test_data = data(choose(num_train+1:end),:);
label_test = test_data(:,end);
predict = zeros(length(test_data),1);
%% ----训练模型并预测分类
model = svmtrain(label_train,train_data(:,1:end-1),'-t 2');
% -t = 2 选择径向基函数核
true_num = 0;
for i = 1:length(test_data)
% 作为预测,svmpredict第一个参数随便给个就可以
predict(i) = svmpredict(1,test_data(i,1:end-1),model);
end
%% 显示结果
figure;
index1 = find(predict==1);
data1 = (test_data(index1,:))'; plot(data1(1,:),data1(2,:),'or');
hold on
index2 = find(predict==-1);
data2 = (test_data(index2,:))'; plot(data2(1,:),data2(2,:),'*'); hold on indexw = find(predict~=(label_test)); dataw = (test_data(indexw,:))';
plot(dataw(1,:),dataw(2,:),'+g','LineWidth',3);
accuracy = length(find(predict==label_test))/length(test_data);
title(['predict the testing data and the accuracy is :',num2str(accuracy)]);
可以看到,关于svm的部分就那么一点,其他的都是辅助吧,那么一个结果如下:
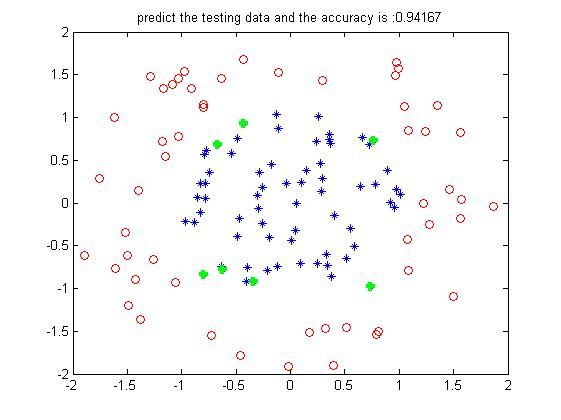
数据人为设置了一些重叠,这个结果算是非常好了。当然对于libsvm函数,里面还有许多细节,像参数选择等等,不同的参数结果是不一样的,这就待你去探究了。
至此SVM系列文章就到这里吧,感谢能看到这里的朋友~_~。